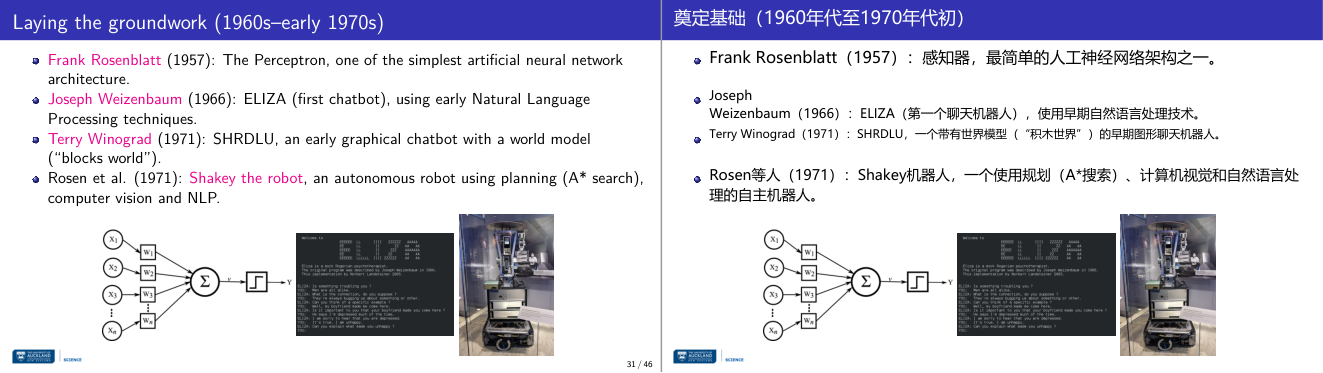
这一页讲的是人工智能的定义与直觉。主要任务是写下与 AI 相关的三个关键词,并思考 AI 的能力(capabilities)或工作原理(methods)。
这一页讲的是人工智能的定义与直觉。首先要求写下三个与 AI 相关的关键词,这些关键词可以从技术角度出发,例如机器学习(machine learning)、神经网络(neural networks)、自动化(automation)等。接着引导学生思考他们对 AI 的理解是基于它的能力(capabilities),例如预测、分类、生成内容等,还是基于它的工作原理(methods),例如算法、数据处理或模型训练。这种练习旨在帮助学生明确 AI 的核心概念和技术特点,同时为后续深入学习奠定基础。页面右侧提供了二维码,可以通过互动工具提交答案,增强课堂参与感。
第 4 / 46 页
这一页讲的是“AI or not AI”的互动投票环节,重点是通过评分讨论技术是否属于人工智能。
这一页讲的是“AI or not AI”的互动投票环节,参与者需要对10个技术案例进行评分,范围从0(强烈不同意)到5(强烈同意),以回答“这项技术是否可以被认为是人工智能”。这一环节的目的是探索判断人工智能的标准(criteria),并非寻找“正确答案”。评分结束后,大家会讨论导致分歧的原因。这种活动有助于理解人工智能的定义在不同人群中的主观性,以及技术与人工智能之间的界限如何被感知。比如,有些人可能认为简单的自动化系统不属于人工智能,而另一些人可能认为只要涉及机器学习或数据处理的技术都可以归类为人工智能。
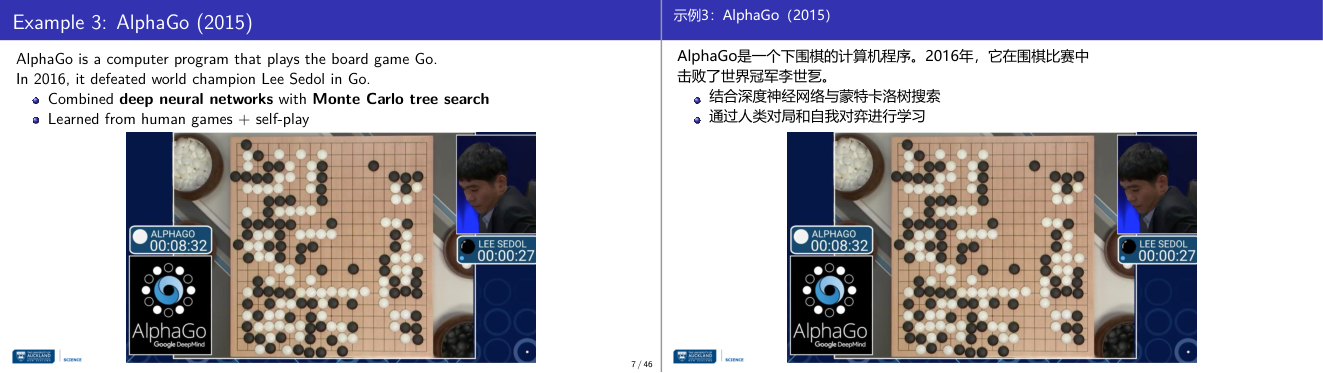
这一页讲的是 AlphaGo,这是一款由 Google DeepMind 开发的围棋程序。2016 年,AlphaGo 击败了围棋世界冠军李世乭,展示了人工智能在复杂棋类游戏中的强大能力。AlphaGo 的核心技术是结合了深度神经网络(deep neural networks)和蒙特卡洛树搜索(Monte Carlo tree search)。深度神经网络负责预测棋盘状态和最佳动作,而蒙特卡洛树搜索则通过模拟对弈来评估每一步的潜在结果,从而优化决策。此外,AlphaGo 的学习方式非常独特,它不仅从人类棋手的棋局中学习,还通过自我对弈(self-play)不断提高自己的水平。这种结合使得 AlphaGo 能够处理围棋中庞大的状态空间和复杂的策略选择。幻灯片中的图片展示了 AlphaGo 与李世乭对弈的场景,强调了人工智能在实际应用中的突破性成果。
这一页讲的是 AlphaGo——一个将深度神经网络(Deep Neural Networks)、蒙特卡洛树搜索(Monte Carlo Tree Search,MCTS)和强化学习(Reinforcement Learning,RL)三者融合的里程碑系统。围棋的搜索空间极大,棋盘状态数远超国际象棋,纯粹的暴力搜索(如 Deep Blue 用于国际象棋的方式)完全行不通。AlphaGo 的解法是:先用人类棋谱做监督学习训练策略网络(Policy Network),让系统学会"哪步棋走起来像高手";再通过自我对弈(self-play)做强化学习,让策略网络不断改进;同时训练价值网络(Value Network)来估计当前局面的胜率。在实际走棋时,用 MCTS 做树搜索,但每次展开节点时用神经网络来引导搜索方向(策略网络决定优先探索哪条分支)并评估叶节点的好坏(价值网络代替传统的随机模拟 rollout)。这样就把"广度优先"变成"聪明地优先探索有价值的方向"。2016 年 AlphaGo 4:1 战胜李世石,震惊了 AI 界。考试角度:这是"神经网络 + 树搜索 + 强化学习如何结合"的典型例题。常见考法是让你描述 AlphaGo 的组成部分及各自的作用,或者问"为什么 MCTS 单独不够?神经网络的引入解决了什么问题?"易错点是把 AlphaGo(结合人类数据+自我对弈)和 AlphaGo Zero(纯自我对弈、无人类数据)搞混,后者更彻底地依赖 RL,本页说的是原版 AlphaGo。
第 8 / 46 页
这一页讲的是 NASA 的火星探测车 Curiosity 的特点与挑战。重点包括通信延迟下的自主性,以及在不确定条件下的规划、控制和感知能力。
这一页讲的是 NASA 于 2012 年发射的火星探测车 Curiosity,它是一辆汽车大小的移动科学实验室,降落在火星的 Gale Crater,用于导航和科学任务。Curiosity 的设计面临两个主要挑战:第一是通信延迟下的自主性(Autonomy under communication delays),由于地球与火星之间的距离,信号传输需要时间,探测车必须能够在没有实时指令的情况下自主完成任务;第二是规划、控制和感知在不确定条件下的能力(Planning, control, perception under uncertainty),例如应对火星地形的复杂性和环境的不确定性。图片展示了 Curiosity 在火星表面的实际工作场景,体现了它的设计复杂性和科学任务的重要性。一个例子是探测车需要分析地形数据,决定如何避开障碍物并选择最佳路径,同时完成岩石样本的采集和分析。这些能力不仅推动了火星研究,也为地球上的无人系统开发提供了重要启示。
这一页讲的是如何区分技术是否属于人工智能(AI)。列举了五种技术供讨论,包括 Slide rule、Pocket calculator、Alpha Go 等。
这一页讲的是如何判断某种技术是否可以被认为是人工智能(Artificial Intelligence)。幻灯片列出了五种技术:Slide rule(计算尺)、Pocket calculator(袖珍计算器)、Alpha Go(围棋人工智能程序)、Mars Rover Curiosity(火星探测器“好奇号”)以及 Smart factories(智能工厂)。这些技术代表了不同的复杂性和智能水平,目的是让参与者根据自己的理解,对这些技术是否属于人工智能进行评价。评价范围从“Strongly disagree”(完全不同意)到“Strongly agree”(完全同意)。通过这样的互动,可以帮助学生理解人工智能的定义和边界,例如 Alpha Go 是基于深度学习的典型 AI 应用,而计算尺和袖珍计算器则是传统工具,不涉及智能决策。二维码提供了参与互动的方式,展示了实时投票结果的可能性。这种讨论有助于加深对人工智能概念的理解,尤其是在技术分类和应用场景方面。
第 11 / 46 页
这一页讲的是 Amazon Go 的自助商店技术。主要包括通过机器学习实现的图像识别与追踪,以及基于传感器、模型和工程的“Just Walk Out”系统。
这一页讲的是 Amazon Go 的自助商店技术,它利用摄像头和计算机视觉(computer vision)实现无结账购物体验。首先,图像识别(image recognition)和追踪技术通过机器学习(machine learning)来分析顾客的行为,例如识别他们拿取的商品并实时更新购物清单。这种技术的核心是通过训练模型来处理大量视频数据,确保高精度的识别和追踪。其次,Amazon Go 的“Just Walk Out”系统是一个系统级的产品,结合了传感器(sensors)、机器学习模型(models)和工程技术(engineering),实现了无缝的购物体验。例如,当顾客离开商店时,系统会自动结算购物清单,无需人工干预。这种技术不仅提高了用户体验,还显著减少了排队结账的时间。通过这个案例,可以看到机器学习和计算机视觉在零售行业的创新应用,展示了技术如何改变传统商业模式。
这一页讲的是基于规则的聊天机器人(Rule-based chatbot),它是一种通过预定义的问答组合进行对话的程序,常见于FAQ场景。它的特点是不需要学习(No learning required),即不依赖机器学习算法,而是完全基于预设的逻辑规则和选项。虽然它的功能相对简单,但在狭窄领域内仍然可以模拟对话的感觉(“feel” conversational in narrow domains)。幻灯片中的图例展示了一个基于规则的聊天机器人示例:用户提出问题后,机器人会根据预设选项提供回复,例如“Order Status”“Cancel Order”等。如果用户输入的内容超出了预设范围,机器人会提示无法理解并要求用户选择具体选项。最终,当问题无法解决时,它会将用户转接至人工客服。这种设计适合处理结构化问题,例如订单查询、退货等,但不适合处理开放性或复杂的对话。通过这种方式,基于规则的聊天机器人可以快速响应用户需求,同时保持较低的技术复杂度。
第 14 / 46 页
这一页讲的是 ELIZA (1966) 聊天程序,它通过关键词识别和模式匹配模拟心理治疗师。重点包括表面流畅性和“像人类”与“理解”的差距。
这一页讲的是 ELIZA (1966),一个早期的聊天程序,用于模拟心理治疗师的对话。它的工作原理是通过关键词识别、模式匹配以及转换规则,根据输入的关键词或缺乏关键词生成回答。这是表面流畅性 (surface fluency) 的经典示例,展示了程序可以“听起来像人类”但并不真正理解对话内容的现象。幻灯片中的对话示例显示 ELIZA 根据用户输入的句子提取关键词并生成回应,例如用户提到“男朋友”,程序会根据关键词生成相关问题。这强调了“像人类”与“理解”之间的差距:虽然 ELIZA 的回答看似合理,但它并不具备真正的理解能力。这种技术的意义在于,它为后续自然语言处理和人工智能的发展奠定了基础,同时提醒我们在设计人机交互时需要关注真正的理解能力,而不仅仅是表面流畅性。
这一页讲的是如何判断某些技术是否可以被认为是人工智能(AI)。幻灯片列出了五种技术:Amazon Go、MYCIN(专家系统)、规则型聊天机器人(Rule-based chatbots)、ELIZA 和 ChatGPT。通过 Mentimeter 平台,观众可以对这些技术是否属于 AI 进行评分,从“强烈不同意”到“强烈同意”。这些技术涵盖了不同的 AI 应用领域,例如 Amazon Go 利用计算机视觉和传感器技术实现无人零售;MYCIN 是早期的专家系统,用于医疗诊断;规则型聊天机器人和 ELIZA 代表了简单的基于规则的对话系统;而 ChatGPT 则是现代基于深度学习的生成式 AI。这一页的目的是引导观众思考 AI 的定义和应用范围,并评估不同技术的智能化程度。
这一页讲的是构建 AI 分类法的分组任务。首先,要求小组成员列出 AI 的核心概念,例如规则(rules)、搜索(search)、学习(learning)、感知(perception)、规划(planning)等。其次,将这些核心概念归类为 3 到 6 个类别,类别名称由小组自行决定。最后,选择一种组织原则,可以基于能力(capability),如感知(perception)、语言(language)、决策决策(decision-making);基于方法(method),如符号(symbolic)、统计(statistical)、神经网络(neural);基于数据与反馈(data & feedback),如监督学习(supervised)、自监督学习(self-supervised)、强化学习(RL)、人工反馈(human feedback);或者使用二维图表,例如“学习(learning)”与“手工设计(hand-engineered)”的对比。最终交付成果包括一个简单图表和每个类别的一句话描述。这一任务旨在帮助学生理解 AI 分类的多维度视角及其应用。
这一页讲的是"What"与"How"这对贯穿全课的核心分析框架。What 指的是目标/规格层面:我们希望系统实现什么行为、解决什么任务?How 指的是方法/实现层面:具体用哪种技术来实现?比如,"识别图像中的猫"是 What;用 CNN 还是 Transformer 去做是 How。这个区分非常重要,原因有三:第一,你可以独立评判一个系统是否成功(看 What 是否达成),而不必先讨论它用了哪种方法;第二,同一个 What 可以用多种 How 实现,比如同样是"下围棋",可以用纯符号搜索,也可以用 AlphaGo 的深度学习+MCTS;第三,"这是不是 AI"的争论往往是混淆了 What 和 How——有人认为凡是"学习"才叫 AI(偏 How),有人认为只要能完成人类级别的任务就算(偏 What)。这节课前面讨论的滑尺、计算器、ELIZA 之争,本质上都是在无意识地用不同的 What vs How 标准衡量。考试角度:这个框架本身不常单独出题,但它是理解后续内容(Agent 框架、符号 vs 神经 vs 统计的比较、评估 AI 系统)的思维工具。如果题目让你分析某个 AI 系统的设计,用这个框架来组织答案会显得有条理。
这一页讲的是人工智能的四种经典视角,这些视角帮助我们理解和讨论 AI 的目标与行为。第一种是 Acting humanly,即模仿人类行为,例如图灵测试,这种视角强调 AI 是否能够表现得像人类。第二种是 Thinking humanly,关注 AI 是否能够模拟人类认知过程,这是认知科学的核心问题。第三种是 Thinking rationally,强调 AI 是否能够基于逻辑推导出正确的结论,体现了理性思维的能力。最后是 Acting rationally,指 AI 是否能够选择最大化预期效用的行动,这通常是智能代理的目标。幻灯片还指出,在实践中,现代 AI 更注重优化性能,而非模仿人类行为。这些视角的提出有助于我们从不同角度分析 AI 的设计目标和实际表现,例如设计一个能够解决复杂问题的智能系统时,可以结合 Acting rationally 和 Thinking rationally 的原则。
这一页讲的是 AI 的四个经典定义视角,来自 Russell & Norvig 教材的经典框架,是期末常见考点。四个视角形成一个 2x2 矩阵:横轴是"思考"还是"行动",纵轴是"像人类"还是"理性"。第一,Acting humanly(像人类那样行动):以图灵测试(Turing Test,1950)为代表——如果一台机器的对话让人类无法分辨它是机器,就认为它具有智能。好处是有清晰的操作标准,缺点是中文屋(Chinese Room)思想实验说明:通过测试不等于真正理解。第二,Thinking humanly(像人类那样思考):认知科学路径,研究人类大脑如何工作并在计算机中复现,代表是 ACT-R 等认知模型。第三,Thinking rationally(理性地思考):形式逻辑路径,用一阶逻辑推导出正确结论,代表是定理证明器。问题是现实世界充满不确定性,并非所有问题都能形式化。第四,Acting rationally(理性地行动):现代主流观点,Agent 不必模仿人类思维,只需选择能最大化期望收益的行动,代表是强化学习和决策论。考试角度:非常高频,常见考法是"请解释 Turing Test 属于哪个视角,它的局限性是什么",或者让你把某个 AI 系统(如 MYCIN、AlphaGo、ELIZA)归类到四个视角中。易错点是把"Thinking rationally"和"Acting rationally"搞混——前者强调推理过程的形式正确性,后者只关心行动结果是否最优。
第 24 / 46 页
这一页讲的是 AI 作为理性智能体的抽象模型。主要内容包括智能体观察环境并采取行动,以及目标是最大化成功指标。举了分类器、聊天机器人和机器人作为例子。
这一页讲的是 AI 作为理性智能体(rational agents)的抽象模型。首先,智能体(agent)的核心定义是它会观察环境(observe an environment),然后根据观察采取行动(take actions)。它的目标是最大化某种成功指标,例如奖励(reward)、效用(utility)或准确性(accuracy)。接着,幻灯片列举了三个具体例子来说明这种抽象模型的应用:1. 分类器(Classifier),它的观察是特征(features),行动是输出标签(label);2. 聊天机器人(Chatbot),它的观察是对话上下文(conversation context),行动是生成下一个词或消息(next token/message);3. 机器人(Robot),它的观察是传感器数据(sensors),行动是执行运动指令(motor commands)。这些例子展示了智能体模型在不同领域的适用性,说明了如何将复杂系统简化为观察和行动的循环过程。这种抽象对于设计和理解 AI 系统非常重要,因为它提供了一种通用框架来分析和优化系统行为。
这一页讲的是 AI 的学习方式。主要包括从数据中学习(现代机器学习和深度学习)、手工设计的系统(逻辑、搜索、规划)以及模糊边界的混合系统。
这一页讲的是 AI 是否通过“学习”实现智能的问题。首先,学习是实现 AI 的主要途径之一,尤其是现代机器学习(ML)和深度学习(Deep Learning),它们通过从大量数据中提取规律来构建模型。其次,有些 AI 系统是通过手工设计的方式实现的,比如基于逻辑推理、搜索算法和规划技术的系统,这些方法依赖于明确的规则和预定义的结构。最后,现实中的许多 AI 产品是混合系统(Hybrid Systems),结合了学习和手工设计的元素,因此两者的界限在实际应用中变得模糊。例如,一个推荐系统可能既依赖于机器学习算法来预测用户偏好,也依赖于手工设计的规则来过滤不相关内容。这种结合使得 AI 更加灵活和有效。
第 26 / 46 页
这一页讲的是评估 AI 的三个关键层面:任务表现(Task performance)、鲁棒性(Robustness)和泛化能力(Generalization)。
这一页讲的是评估 AI 的三个重要层面。第一是任务表现(Task performance),即 AI 是否能够解决基准测试或实际任务,这是衡量其基本功能的核心标准。第二是鲁棒性(Robustness),关注 AI 在面对分布变化、噪声或对抗性输入时是否会失败,这反映了模型在复杂环境中的稳定性。第三是泛化能力(Generalization),即 AI 是否能在新领域或任务中表现良好,尤其是在额外数据有限的情况下。这些层面强调评估 AI 不仅仅依赖于“演示效果看起来不错”,而是需要深入理解其在真实场景中的表现及适应能力。例如,一个图像识别模型可能在训练集上表现很好,但如果它在不同光照条件或新类别下失败,就说明其鲁棒性和泛化能力不足。
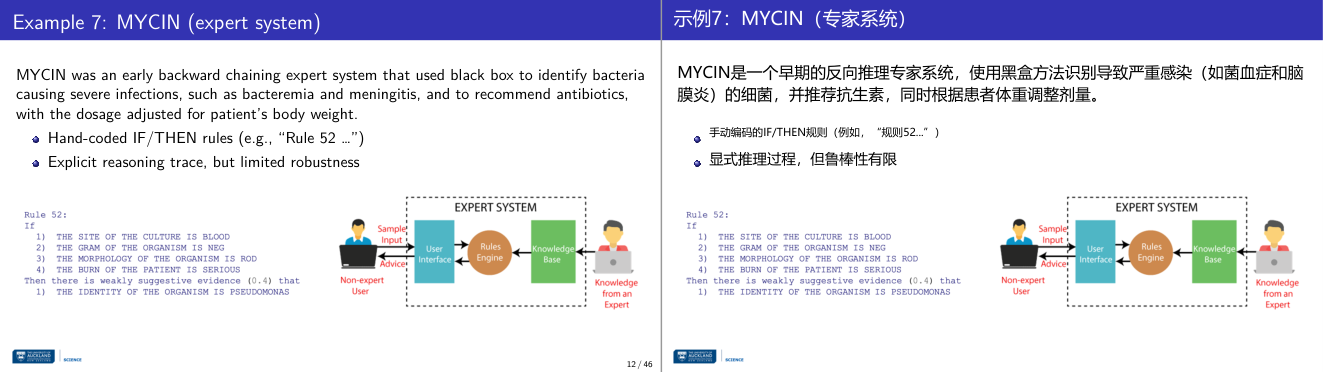
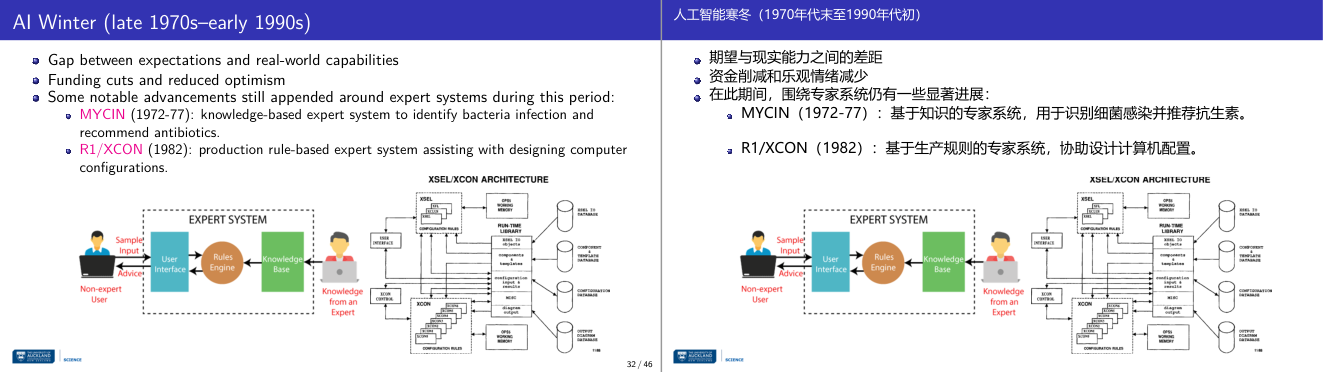
这一页讲的是 AI 冬天时期(1970年代末至1990年代初)的背景与进展。重点包括期望与现实的差距、资金削减,以及专家系统的进展如 MYCIN 和 R1/XCON。
这一页讲的是 AI 冬天时期(1970年代末至1990年代初)。这一阶段的人工智能发展遇到瓶颈,主要原因是技术能力未能达到早期的高期望,导致资金削减和行业乐观情绪下降。然而,这期间仍有一些重要进展,特别是在专家系统领域。MYCIN(1972-77)是一个知识驱动的专家系统,用于识别细菌感染并推荐抗生素治疗,展示了人工智能在医疗领域的潜力。而 R1/XCON(1982)是一个基于生产规则的专家系统,用于帮助设计计算机配置,体现了 AI 在工业应用中的价值。页面中的流程图展示了专家系统的架构:用户通过界面输入问题,规则引擎根据知识库中的信息进行推理,最终给出建议或解决方案。右侧的 XSEL/XCON 架构图进一步细化了专家系统的工作流程,包括用户界面、运行时库、配置规则和数据库的交互。这些系统的成功为后来人工智能的发展奠定了基础,尽管整体行业处于低谷期。
第 33 / 46 页
这一页讲的是1990至2000年代人工智能的关键进展,包括神经网络训练、棋类人工智能和社交机器人。
这一页讲的是1990至2000年代人工智能领域的几项重要突破。首先,Rumelhart, Hinton & Williams 在1985年提出了反向传播算法(backpropagation),用于训练多层神经网络。这一方法解决了复杂网络中权重更新的问题,是深度学习的基础。其次,IBM的Deep Blue在1997年击败了国际象棋冠军Gary Kasparov,展示了人工智能在棋类游戏中的强大计算能力。Deep Blue使用了暴力搜索树技术(brute force tree search),通过计算所有可能的棋步来选择最佳策略。最后,Cynthia Breazeal在2000年开发了Kismet,这是一种能够通过面部动作模拟人类情感的“社交机器人”(social robot)。这一技术展示了人工智能在人机交互和情感模拟领域的潜力。幻灯片中的两张图片分别展示了Deep Blue与Kasparov对弈的场景,以及Kismet机器人的外观,直观体现了这些技术的实际应用。
这一页讲的是生成式 AI 的成功案例及发展趋势。主要介绍了 OpenAI 的 GPT-3、DALL-E 和 ChatGPT 的特点,以及当前的多模态 AI、推理模型和 Agentic AI 等趋势。
这一页讲的是生成式 AI 的成功案例及其发展趋势。首先提到 OpenAI GPT-3,它是一个大型语言模型(LLM),基于 2017 年提出的 Transformer 深度学习架构,能够处理复杂的自然语言任务。其次是 OpenAI DALL-E,这是一种文本生成图像模型,结合了 Transformer 和变分自编码器(VAE)架构,能够根据文本描述生成高质量的图像。第三是 OpenAI ChatGPT,它基于 GPT-3 模型,专注于对话式交互,提升了用户体验。最后提到当前的 AI 发展趋势,包括多模态 AI(Multimodal AI),即能够同时处理文本、图像等多种数据类型;推理模型(Reasoning Models),强调逻辑推理能力;以及 Agentic AI,探索更自主、更智能的系统。这些技术和趋势推动了生成式 AI 的广泛应用,例如自动内容生成、智能助手和创意设计等领域。
第 36 / 46 页
这一页讲的是人工智能的三种主要方法及其融合。包括符号 AI、神经 AI 和统计 AI,各自有独特的特点和应用。
这一页讲的是人工智能的三种主要方法及其相互交织的关系。首先,符号 AI (Symbolic AI) 侧重于逻辑推理、搜索算法、规划以及知识表示,适用于结构化问题和明确规则的场景,例如专家系统。其次,神经 AI (Neural AI) 依赖于学习表示、神经网络以及基于梯度的学习方法,擅长处理复杂数据和模式识别,例如图像分类和语言处理。最后,统计 AI (Statistical AI) 以概率、推断和在不确定性下的决策为核心,广泛应用于预测和优化问题,例如贝叶斯网络和决策树。这三种方法在现代 AI 系统中通常被结合使用,以发挥各自的优势。例如,自动驾驶系统可能同时使用符号 AI 来规划路径,神经 AI 来识别行人和车辆,统计 AI 来处理环境中的不确定性。
这一页讲的是 AI 的三大历史传统——符号 AI(Symbolic AI)、神经 AI(Neural AI)和统计 AI(Statistical AI)——以及它们各自的特点。符号 AI 以逻辑、搜索、规划和知识表示为核心,典型代表是 MYCIN 专家系统和 A 搜索算法;它的优势是可解释性强、在清晰定义的问题上效果好,缺点是知识工程瓶颈——专家的知识很难全部手工编码,面对视觉、语言等高维复杂问题时会崩溃。神经 AI 以人工神经网络和表示学习为核心,从数据中自动学习特征,典型代表是深度卷积网络、Transformer;优势是处理感知任务能力强、可规模化,缺点是数据依赖大、可解释性差、失效模式难预测。统计 AI 以概率论、贝叶斯推断和决策论为基础,代表是朴素贝叶斯、隐马尔可夫模型、贝叶斯网络;优势是对不确定性有原则性的处理方式,缺点是精确推断在复杂模型中计算量爆炸。现代系统(包括 AlphaGo、大语言模型等)往往三者兼有:用神经网络做感知/表示,用搜索/规划做决策,用概率方法处理不确定性。考试角度:这是 713 课程框架性内容,常与后续各章节联系起来考,如"MYCIN 属于哪个传统?它的局限性如何用统计 AI 弥补?"。易错点是以为三者互斥,实际上现代 AI 是混合体。
第 37 / 46 页
这一页讲的是符号 AI (Symbolic AI) 的优势与局限性。优势包括明确的结构和可解释性,适用于清晰且简单的世界模型。局限性在于知识工程瓶颈以及在复杂现实中的脆弱性。
这一页讲的是符号 AI 的特点及其应用范围。优势方面,符号 AI 具有明确的结构,例如基于规则和逻辑的系统,这使得它具有良好的可解释性。它适用于处理清晰且规模较小的世界模型,例如定义明确的任务或问题。局限性方面,符号 AI 存在知识工程瓶颈,即构建和维护规则与逻辑的过程非常耗时且复杂。此外,它在处理复杂、多维度的现实环境时表现出脆弱性,例如在视觉和语言任务中,符号 AI难以应对数据的噪声和不确定性。举例来说,在一个简单的棋盘游戏中,符号 AI 能够通过规则和逻辑轻松推导出最佳策略,但在处理自然语言理解或图像识别时可能表现不佳。这些特点决定了符号 AI 的适用场景和局限性。
第 38 / 46 页
这一页讲的是神经网络 AI 的优势与局限性。优势包括从数据中学习特征和表现强大,局限性则在于对数据需求高且难以解释。
这一页讲的是神经网络 AI 的优势与局限性。优势方面,神经网络能够从数据中自动学习特征和表示(features/representations),这使得它在感知(perception)和语言处理(language)任务中表现出色,尤其是在规模扩展时效果显著。局限性方面,神经网络对数据需求量非常大(data hungry),这使得在实际应用中难以保证其结果的正确性。此外,神经网络的工作机制通常较难解释(difficult to interpret),其失败模式(failure modes)可能会令人意外。例如,在图像识别任务中,神经网络可能会因为训练数据中的偏差而出现错误分类。这些特点提醒我们在使用神经网络时要谨慎评估其适用性和潜在风险。
这一页讲的是生成式 AI 的定义、优势和风险。生成式模型通过学习数据模式生成新内容,优势包括流畅性和快速适应性,风险涉及幻觉、偏差和隐私泄露。
这一页讲的是生成式 AI(Generative AI)的核心定义、典型优势和风险。生成式模型通过学习数据中的模式来生成新的内容,包括文本、图像、音频和代码。其典型优势包括流畅性(fluency),例如生成自然语言文本;总结(summarization),如提取关键信息;起草(drafting)和代码辅助(coding assistance),帮助用户高效完成任务。此外,生成式 AI 还能通过提示(prompting)和工具增强(tool augmentation)快速适应不同需求。然而,生成式 AI 也存在一些典型风险,例如幻觉(hallucination),即生成虚假的或不准确的信息;偏差(bias),可能导致不公平的结果;隐私泄露(privacy leakage),涉及敏感信息的泄露;以及脆弱推理(brittle reasoning),在复杂逻辑问题上表现出不稳定性。这些特点使得生成式 AI 在实际应用中既充满潜力,也需要谨慎处理其局限性。
第 42 / 46 页
这一页讲的是模型(Model)与系统(System)的区别及其在 AI 部署中的作用。模型负责预测或生成内容,例如 LLM 和视觉模型;系统包括检索、工具、策略、监控、用户体验和备用逻辑。
这一页讲的是模型(Model)与系统(System)的区别,以及它们在实际 AI 部署中的作用。模型是核心的预测或生成组件,例如大语言模型(LLM)或视觉模型,它们负责完成特定的任务,比如生成文本或识别图像。而系统则是围绕模型构建的更广泛的支持框架,包括检索数据、工具集成、策略设定、监控机制、用户体验设计(UX)以及备用逻辑(fallback logic)。这一页还提到,理解模型与系统的区别有助于解释为什么像 ChatGPT 和 ELIZA 在演示中看起来类似,但在通用性和集成度上有巨大差异。例如,ChatGPT作为一个系统,包含复杂的用户交互设计和策略,而 ELIZA则主要是一个简单的模型。
这一页讲的是人工智能(AI)的关键总结。首先,AI需要通过多角度(multiple lenses)来理解,包括“做什么”和“怎么做”(what vs. how)、行动与思考(acting vs. thinking)、以及理性代理(rational agents)的概念。这种多角度分析帮助我们全面认识 AI 的功能和原理。其次,AI有多种传统(multiple traditions),如符号方法(symbolic)、统计方法(statistical)和神经网络(neural),现代系统通常将这些方法混合使用以增强效果。此外,技术的周期性变化(hype cycles),如“寒冬”(winters)和“浪潮”(surges),反映了人们的期望与实际方法、数据及计算能力之间的差距。最后,生成式 AI(Generative AI)虽然功能强大,但其评估必须包括对鲁棒性(robustness)和失败模式(failure modes)的分析。例如,在生成文本时,系统可能会输出不准确或有害的信息,因此需要设计更严格的评估标准。这些要点强调了理解和应用 AI 时的复杂性与重要性。
第 45 / 46 页
这一页讲的是 Symbolic Logic(符号逻辑)的概念及其在人工智能中的作用。主要内容包括符号逻辑是 Symbolic AI 的基础,利用形式规则和逻辑进行推理,以及它与数据驱动的机器学习的对比。