第 1 / 37 页

这一页讲的是课程 COMPSCI 713 的主题,即 AI Fundamentals,重点介绍 Logic Neural Networks。
空格=播放/暂停当前页 · Tab=切换 简短/详细/深入 · 红色「深入」为重点页的深度讲解
这一页讲的是课程 COMPSCI 713 的主题,即 AI Fundamentals,重点介绍 Logic Neural Networks。
这一页讲的是课程 COMPSCI 713 的主题,主要研究人工智能基础知识,特别是 Logic Neural Networks(逻辑神经网络)。这一领域旨在将符号逻辑(Symbolic Logic)与神经网络(Neural Networks)结合,用于人工智能推理(AI Reasoning)。符号逻辑是传统人工智能的重要组成部分,擅长处理明确规则和逻辑推导,而神经网络则以处理复杂数据和学习模式见长。通过将两者结合,可以实现更强大的推理能力和数据处理能力。本页为课程的开篇,介绍了研究方向及其重要性。

这一页讲的是课程概览,主要介绍今天学习的内容,包括逻辑在 AI 中的重要性、符号逻辑回顾、神经网络工作原理、逻辑神经网络的需求及其可微逻辑的应用。
这一页讲的是课程概览,重点介绍今天的学习内容。首先,讨论为什么逻辑在 AI 中重要,逻辑能够帮助 AI 系统处理复杂的推理任务。接着,会回顾符号逻辑(symbolic logic),这是传统逻辑的基础,涉及逻辑表达式和推理规则。然后,介绍神经网络(neural networks)的工作原理,帮助理解它们如何处理数据和学习模式。之后,课程会探讨逻辑神经网络(Logic Neural Networks, LNNs)的需求,说明如何将逻辑与神经网络结合以增强推理能力。最后,会讲解可微逻辑(Differentiable Logic),即如何在 AI 中实现逻辑推理的可微性,使逻辑能够与机器学习模型无缝集成。这些内容构成了理解逻辑与 AI 结合的基础,为后续深入学习逻辑神经网络提供了框架。

这一页讲的是逻辑在 AI 中的重要性。传统 AI 面临模式识别强但缺乏推理能力的问题,而逻辑提供明确推理和可解释性。
这一页讲的是逻辑在人工智能(AI)中的重要性。传统 AI 的挑战包括深度学习模型擅长模式识别(pattern recognition),但缺乏推理能力(reasoning ability),并且 AI 无法解释其决策(explain its decisions),这被称为“黑箱问题”(black-box problem)。逻辑的引入可以解决这些问题:第一,逻辑提供明确的推理能力,例如“如果 A 导致 B,那么 B 必然为真”(If A → B, then B must be true);第二,逻辑增强了决策的可解释性(explainability),使我们能够理解 AI 为什么做出某个决策。这种能力对于构建可信赖的 AI 系统非常重要,例如在医疗诊断或自动驾驶领域,逻辑可以帮助解释系统的行为,从而提高用户的信任度。

这一页讲的是为什么在 AI 中需要逻辑。主要对比了神经网络的分类能力与逻辑推理的解释能力。
这一页讲的是为什么在 AI 中需要逻辑。幻灯片通过一个例子说明,神经网络(Convolutional Neural Network, CNN)可以识别一只猫,但无法解释为什么它是猫。而基于逻辑的 AI 则可以提供结构化的推理,例如“如果一个物体体型较小,有毛发,那么它很可能是猫”。左侧图示展示了 CNN 的分类过程,从输入图像到输出类别(猫或狗),强调它的强大分类能力,但缺乏解释性。右侧图片展示了逻辑推理的应用,通过明确的规则对物体进行分类。这一页的核心是强调逻辑在 AI 中的重要性,不仅可以帮助模型进行分类,还能提供可解释性,这对于复杂决策场景尤为重要。例如,在医疗诊断中,逻辑推理可以帮助医生理解 AI 的建议背后的原因。

这一页讲的是命题逻辑 (Propositional Logic),重点介绍逻辑运算符及其含义。主要包括否定 (Negation)、合取 (Conjunction)、析取 (Disjunction)、蕴含 (Implication) 和等价 (Equivalence)。
这一页讲的是命题逻辑 (Propositional Logic),它处理的是可以被判定为真或假的语句。命题逻辑使用逻辑运算符 (logical operators) 来构建复杂表达式。表格列出了五种主要逻辑运算符:第一行是否定 (Negation),符号为 ¬P,表示取反;第二行是合取 (Conjunction),符号为 P ∧ Q,表示当 P 和 Q 都为真时结果为真;第三行是析取 (Disjunction),符号为 P ∨ Q,表示当至少一个为真时结果为真;第四行是蕴含 (Implication),符号为 P → Q,表示如果 P 为真则 Q 必须为真;最后一行是等价 (Equivalence),符号为 P ↔ Q,表示 P 和 Q 同时为真或同时为假时结果为真。这些运算符是构建逻辑表达式的基础,广泛应用于计算机科学和数学推理中。例如,使用合取可以表示两个条件同时满足的情况,而蕴含可以用来表达条件关系。

这一页讲的是命题逻辑中的合取(Conjunction)及其真值表,强调只有两个命题都为真时,合取结果才为真。
这一页讲的是命题逻辑中的合取(Conjunction),即符号“∧”的逻辑运算。真值表显示了两个命题 P 和 Q 的不同组合及其合取结果 P ∧ Q:当且仅当 P 和 Q 都为真(True),合取结果才为真,否则为假(False)。例如,“It is raining AND I have an umbrella”只有在两个条件都满足时才为真。表中列出四种情况:P 和 Q 都为真时,P ∧ Q 为真;其他情况下,包括 P 或 Q 为假时,P ∧ Q 都为假。练习题则要求判断哪种情况符合逻辑规则,答案为 B,因为只有 P 和 Q 同时为真时,合取结果才为真。这种逻辑运算在计算机科学和数学中非常重要,用于构建复杂条件判断和逻辑推理。
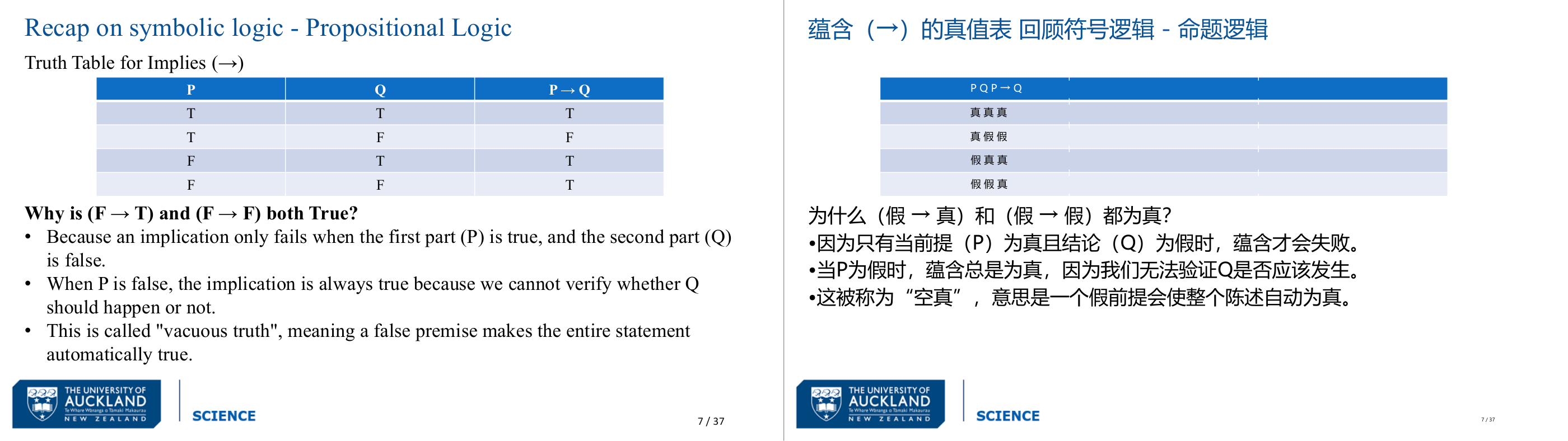
这一页讲的是命题逻辑中的蕴含关系 (Implication) 的真值表及其性质。主要讨论了为什么当 P 为假时,P → Q 总为真,以及“vacuous truth”的概念。
这一页讲的是命题逻辑 (Propositional Logic) 中的蕴含关系 (Implication) 的真值表。表格中列出了 P 和 Q 的四种可能组合,以及对应的 P → Q 的真值。可以看到,当 P 为真且 Q 为假时,P → Q 为假,而在其他情况下,P → Q 都为真。接着重点解释了为什么 (F → T) 和 (F → F) 都为真。这是因为蕴含关系只有在 P 为真且 Q 为假时才会失败,而当 P 为假时,我们无法验证 Q 是否应该发生,因此整个命题自动为真。这种情况被称为“vacuous truth”,即当前提为假时,整个命题被认为是自动成立的。举例来说,如果我们说“如果今天下雨,我会带伞”,但今天实际上没有下雨,那么这个命题仍然被认为是成立的,因为前提条件没有满足。
这一页讲的是 Implication(蕴含运算)的真值表,以及「vacuous truth(空真)」这个反直觉但极其重要的逻辑概念。蕴含 P → Q 的意思是「如果 P 为真,则 Q 必须为真」。真值表里最让人迷惑的两行是:P 为假时,无论 Q 是真还是假,P → Q 都为真。为什么?因为蕴含的唯一「失败」情形是 P 真而 Q 假——这才构成反例,证明规则被违反。当 P 本身就是假的,前提根本不成立,规则无法被「激活」,自然也无法被违反,所以结果默认为真。这叫做 vacuous truth,中文叫「空真」,意思是前提为假的蕴含语句没有任何内容上的约束,天然成立。直觉类比:「如果明天下雪,我请你吃饭」——今天不下雪,这句承诺根本没被触发,无所谓真假,逻辑上算作成立。考试怎么考:最高频的陷阱是给你一张真值表让你填 F → T 或 F → F,很多同学直觉上觉得这两行应该是假的,错误地写 F。记住:只有 T → F 才是假。另一个考法是把现实场景映射到真值表,例如「下雨路面没湿(T→F)」是唯一能推翻规则的情形,其余三行都是真。易错点:不要把 P → Q 理解成双向的,它不等价于 Q → P,这是考试里另一个常见陷阱。
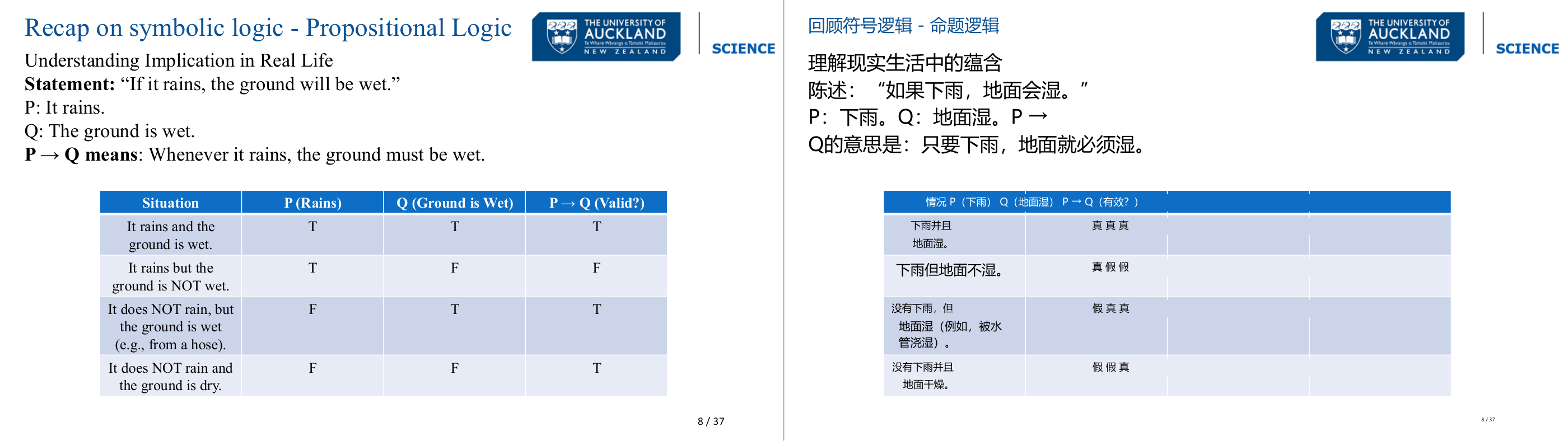
这一页讲的是命题逻辑中的蕴含关系 (Implication)。主要介绍 P → Q 的含义,并通过表格分析不同情况的逻辑有效性。
这一页讲的是命题逻辑 (Propositional Logic) 中的蕴含关系 (Implication)。P → Q 的含义是:如果 P 为真 (It rains),那么 Q 也必须为真 (The ground is wet)。表格列出了四种情况:第一行是 P 和 Q 都为真时,蕴含关系有效;第二行是 P 为真但 Q 为假时,蕴含关系无效;第三行是 P 为假但 Q 为真时,蕴含关系仍然有效;第四行是 P 和 Q 都为假时,蕴含关系有效。这表明在逻辑中,只要 P 为假,P → Q 都被认为是有效的。这种规则在实际应用中可以帮助我们理解条件语句的逻辑结构,例如天气预报中“如果下雨,地面会湿”的推理。

这一页讲的是命题逻辑中的真值表推理,分析违反规则的情况。重点是规则“如果是鸟,则会飞”,选项 B 违反了该规则,因为企鹅是鸟但不会飞。
这一页讲的是命题逻辑(Propositional Logic)中的真值表推理(Truth Table Reasoning)。规则是“如果某动物是鸟,则它会飞”(Bird(x) → CanFly(x))。这一规则表示所有鸟都必须能够飞行。题目要求分析哪个选项违反了这一规则。选项包括:A)鹰是鸟并且会飞;B)企鹅是鸟但不会飞;C)鱼不是鸟并且不会飞;D)蝙蝠不是鸟但会飞。答案是 B,因为企鹅是鸟但不能飞,这与规则“所有鸟都必须飞行”矛盾。其他选项均符合逻辑规则:A 满足规则;C 和 D 因为不是鸟,所以不影响规则的成立。这一题帮助理解逻辑规则的应用以及如何通过分析具体情况来判断规则是否被违反。
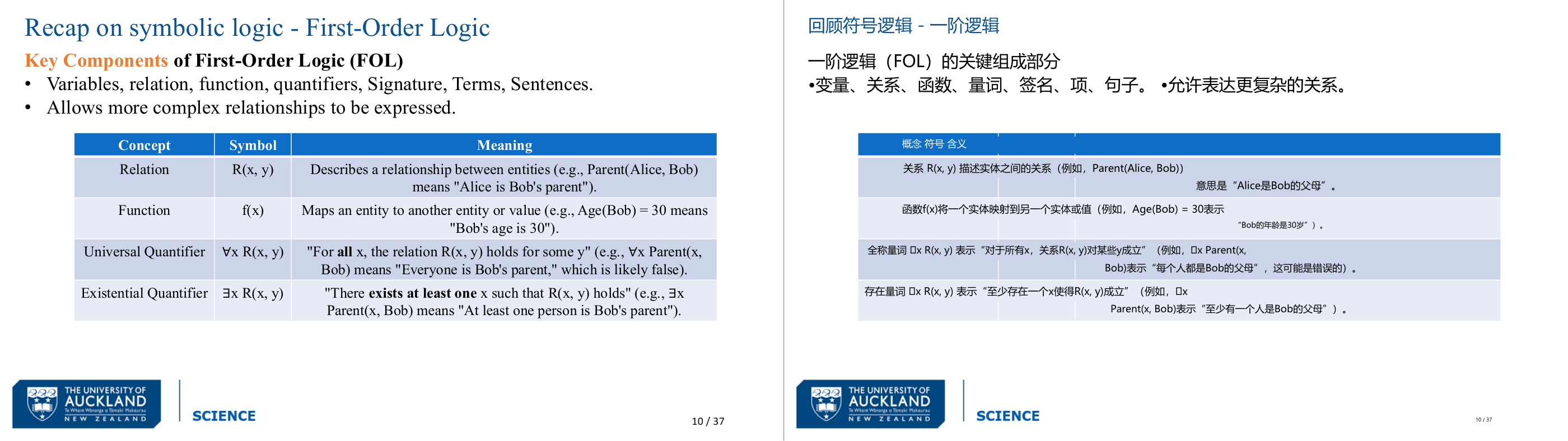
这一页讲的是一阶逻辑(First-Order Logic, FOL)的关键组成部分,包括变量、关系、函数、量词等。表格详细说明了关系、函数以及两种量词的符号和含义。
这一页讲的是一阶逻辑(First-Order Logic, FOL)的关键组成部分,它能够表达更复杂的关系。表格中列出了四个核心概念:关系(Relation)、函数(Function)、全称量词(Universal Quantifier)和存在量词(Existential Quantifier)。关系用 R(x, y) 表示,描述实体之间的关系,例如 Parent(Alice, Bob) 意味着“Alice 是 Bob 的父母”。函数用 f(x) 表示,将一个实体映射到另一个实体或值,例如 Age(Bob) = 30 表示“Bob 的年龄是 30”。全称量词 ∀x R(x, y) 表示“对于所有 x,关系 R(x, y) 对某些 y 成立”,例如 ∀x Parent(x, Bob) 意味着“所有人都是 Bob 的父母”,通常不成立。存在量词 ∃x R(x, y) 表示“至少存在一个 x,使得关系 R(x, y) 成立”,例如 ∃x Parent(x, Bob) 意味着“至少有一个人是 Bob 的父母”。这些概念在逻辑推理和知识表示中非常重要,能够帮助我们更精确地表达复杂的关系和约束。

这一页讲的是一阶逻辑中的规则推导练习,重点分析规则与结论的逻辑关系。关键点包括规则陈述、四个选项的逻辑表达以及错误结论的原因。
这一页讲的是一阶逻辑(First-Order Logic)的推导练习,给定规则为 ∀x(Student(x) → Enrolled(x, University)),即“对于所有 x,如果 x 是学生,那么 x 就会被大学录取”。这表示所有学生都被大学录取,但不代表所有被录取的人都是学生。接下来问题要求判断四个结论中哪个是错误的:A 选项表示如果 Bob 是学生,那么他被大学录取;B 选项表示存在一些学生被大学录取;C 选项表示如果 Bob 没有被大学录取,那么他不是学生;D 选项则表示所有被大学录取的人都是学生。通过分析,D 选项是错误的,因为规则只陈述了“学生 → 被录取”,而没有反向陈述“被录取 → 学生”。这一练习强调了逻辑规则的单向性以及推导结论时的严谨性。
这一页讲的是 First-Order Logic(一阶逻辑,FOL)的核心组件,相比命题逻辑,FOL 最大的进步是引入了「量词」和「关系/函数」,让我们能表达关于世界中实体的通用规律,而不仅仅是固定的 true/false 命题。四个关键概念:第一,Relation(关系),比如 Parent(Alice, Bob) 表示 Alice 是 Bob 的父母,是对实体之间关系的描述;第二,Function(函数),比如 Age(Bob) = 30,把一个实体映射到某个值;第三,Universal Quantifier(全称量词)∀x,读作「对所有 x」,相当于对论域里的每一个个体都断言某件事,比如 ∀x Human(x) → Mortal(x) 表示所有人都会死;第四,Existential Quantifier(存在量词)∃x,读作「存在至少一个 x」,比如 ∃x Parent(x, Bob) 说的是「至少有一个人是 Bob 的父母」。直觉对比:∀ 是「全班同学都及格了」,∃ 是「班里有人及格了」,后者弱得多。考试常考:给你一条 FOL 语句让你判断其逻辑含义,或者问你能不能从 ∀x(A→B) 推出 ∀x(B→A)(不能!)。易错点是把全称量词和存在量词弄反,或者在量词作用范围(scope)上出错,比如 ∀x P(x) → Q(x) 和 ∀x (P(x) → Q(x)) 的含义是不同的,考试里会利用括号来设陷阱。

这一页讲的是逻辑推理的基础知识,重点介绍三种经典推理规则:Modus Ponens、Modus Tollens 和 Syllogism。
这一页讲的是逻辑推理(Logical Inference)的基本概念,即通过形式化的逻辑规则从给定的前提(premises)推导出结论。幻灯片重点介绍了三种经典的推理规则:第一是 Modus Ponens,它是一种直接推理方法,基于条件语句(如“如果 A,则 B”)推导出结论;第二是 Modus Tollens,它通过否定结论来进行推理,例如“如果 A 则 B,但非 B,因此非 A”;第三是 Syllogism,它通过连接多个前提来得出最终结论,例如“所有人都会死,苏格拉底是人,因此苏格拉底会死”。这些推理规则在形式逻辑中非常重要,能够帮助我们构建严谨的论证结构并避免逻辑错误。这些方法广泛应用于数学证明、计算机科学中的算法设计以及哲学中的论证分析。
这一页讲的是一道 FOL 推理判断题,核心考点是「逆命题(converse)」和「逆否命题(contrapositive)」的区别,这是逻辑推理里最经典的易错点之一。原规则是 ∀x Student(x) → Enrolled(x, University),即所有学生都在大学注册。选项 A 是直接把全称量词实例化给 Bob,合法。选项 B 是存在量词版本,说「存在学生在大学注册」,这从全称蕴含可以推出(只要论域非空),也合法。选项 C 是逆否命题:¬Enrolled(Bob) → ¬Student(Bob),逆否命题在逻辑上与原命题完全等价,所以也合法。选项 D 是逆命题:把方向反过来,说「凡是在大学注册的都是学生」——这是错的,因为原命题只保证了学生→注册,而注册→学生这个方向没有任何保证(比如旁听生、教职工也可以注册)。关键规则:原命题 P→Q 与其逆否命题 ¬Q→¬P 逻辑等价;但与逆命题 Q→P 和否命题 ¬P→¬Q 不等价。考试怎么考:给你一条规则,让你从四个推论里挑出「不能得出」或「错误的」结论,D 那种「把箭头方向翻转」的选项就是陷阱。记住口诀:逆否等价,逆和否不等价。

这一页讲的是 Modus Ponens 推理规则,用于从前提推出结论。主要包括定义、推理模式和一个天气相关的例子。
这一页讲的是 Modus Ponens,也叫肯定前件法,是一种逻辑推理规则。它的定义是:如果一个条件语句 P → Q(如果 P 则 Q)成立,并且 P 为真,那么可以推导出 Q 为真。它的推理模式包括三个步骤:第一前提是 P → Q(条件语句),第二前提是 P 为真,结论是 Q 为真。幻灯片还通过一个例子说明了这一逻辑:如果下雨(Rains),地面会湿(WetGround);现在假设下雨为真(Rains = True),那么可以得出结论地面湿(WetGround = True)。这个例子清晰地展示了 Modus Ponens 的应用,帮助理解如何从已知条件和事实推出合理结论。这种逻辑推理在数学证明和计算机科学中非常重要,可以确保推理的正确性和严密性。
这一页讲的是逻辑推理(Logical Inference)的三种基本规则:Modus Ponens、Modus Tollens 和 Syllogism。这三条规则是符号逻辑推理的基石,也是后面 LNN 推理机制的理论基础。Modus Ponens(肯定前件法)的模式是:已知 P→Q,又知 P 为真,则可以断定 Q 为真。比如「下雨路面会湿,现在下雨了,所以路面是湿的」。Modus Tollens(否定后件法)的模式是:已知 P→Q,又知 Q 为假,则可以断定 P 为假。比如「下雨路面会湿,路面没有湿,所以没有在下雨」——注意这里用的是 Q 的否定来倒推 P 的否定,本质上是利用了逆否等价。Syllogism(三段论)的模式是:已知 A→B 且 B→C,则可以断定 A→C,是传递性推理。比如「狗是哺乳动物,哺乳动物有脊梁骨,所以狗有脊梁骨」。考试常见考法:给你一组前提和一个结论,让你判断用了哪条推理规则;或者给你一条链式推理(像第 16-17 页的多步 Modus Tollens),让你逐步写出推理过程。易错点:Modus Tollens 里必须否定的是「后件 Q」,如果你否定的是「前件 P」,那是谬误(Denying the Antecedent),推不出任何结论。

这一页讲的是 Modus Tollens 推理规则,用于从条件假设中得出前件的否定。例子是交通规则,说明逻辑应用。
这一页讲的是 Modus Tollens 推理规则,它是一种逻辑推理方式,用于从条件假设中得出前件的否定(¬P)。其模式是:如果 P → Q(P 推导出 Q),并且 Q 是假的(¬Q),那么可以得出 P 也是假的(¬P)。幻灯片通过一个交通规则的例子来说明这一逻辑:假设交通灯是绿色(GreenLight),车辆可以通行(CanGo)。如果车辆不能通行(¬CanGo),那么可以推断交通灯不是绿色(¬GreenLight)。这个例子清晰地展示了如何通过 Modus Tollens 从一个假设和观察到的事实得出结论。这种逻辑推理在数学证明、计算机科学以及日常推理中都非常重要,因为它能够帮助我们从已知条件中得出可靠的结论。

这一页讲的是逻辑推理中的三段论法 (Syllogism),通过两个前提推导出结论。示例是动物分类问题。
这一页讲的是逻辑推理中的三段论法 (Syllogism)。三段论是一种逻辑论证方法,用两个前提连接起来推导出一个结论。它的逻辑结构是:第一个前提是 A → B (如果 A,那么 B),第二个前提是 B → C (如果 B,那么 C),因此可以得出结论 A → C (如果 A,那么 C)。幻灯片通过一个动物分类的例子来说明:第一个前提是“所有狗都是哺乳动物”,用符号表示为 Dog(x) → Mammal(x);第二个前提是“所有哺乳动物都有脊椎”,用符号表示为 Mammal(x) → HasBackbone(x)。根据这两个前提,可以得出结论“所有狗都有脊椎”,即 Dog(x) → HasBackbone(x)。这个推理过程展示了如何通过逻辑连接两个条件得到一个新的结论。这种方法在人工智能的知识推理中非常重要,比如用于知识图谱中的推理或规则系统的设计。

这一页讲的是科学理论的逻辑评估,介绍了三个逻辑规则和推导结论的重要性。重点包括理论支持数据、被科学界接受和获得资助的关系。
这一页讲的是科学理论的逻辑评估,重点介绍了三个逻辑规则及其推导过程。首先,规则 1 表明如果一个科学理论有实验数据支持(SupportedByData),那么它会被科学界接受(AcceptedByCommunity)。规则 2 进一步说明被科学界接受的理论会获得研究资助(ReceivesFunding)。规则 3 则指出获得资助的理论会在学术界广泛认可(RecognizedInAcademia)。此外,幻灯片提供了一个具体的例子:量子引力统一理论(Quantum-Gravity Unification Theory)“未被学术界广泛认可”(¬RecognizedInAcademia)。根据这些规则,可以推导出该理论未获得资助(¬ReceivesFunding),进而推断它未被科学界接受(¬AcceptedByCommunity),最终说明它缺乏实验数据支持(¬SupportedByData)。因此,正确答案是选项 B:量子引力统一理论不被实验数据支持。这些逻辑关系强调了科学理论评估中的因果链条及其重要性。
这一页讲的是多步链式推理的综合练习,考察如何把 Syllogism(三段论)和 Modus Tollens(否定后件法)链式组合使用。题目给出三条规则形成一条推理链:SupportedByData → AcceptedByCommunity → ReceivesFunding → RecognizedInAcademia,然后告知我们「量子引力统一理论没有被学术界广泛认可(¬RecognizedInAcademia)」,要求推出结论。正确答案是 B:该理论没有被实验数据充分支持(¬SupportedByData)。推理过程分三步,每步都是 Modus Tollens:第一步,已知 ReceivesFunding → RecognizedInAcademia 且 ¬RecognizedInAcademia,推出 ¬ReceivesFunding;第二步,已知 AcceptedByCommunity → ReceivesFunding 且 ¬ReceivesFunding,推出 ¬AcceptedByCommunity;第三步,已知 SupportedByData → AcceptedByCommunity 且 ¬AcceptedByCommunity,推出 ¬SupportedByData。直觉:就像一排多米诺牌,从最后一张推翻开始,依次向前推翻每一张,最终得知第一张也倒了。考试怎么考:这种多步链式推理题型非常典型,考试可能给你 4-5 条规则让你写出完整推理步骤,每步要注明用了什么规则。易错点:不要搞反方向,¬RecognizedInAcademia 只能通过 Modus Tollens 往前推,不能用 Modus Ponens 往前走,因为那需要已知前件为真。

这一页讲的是符号逻辑中的推理方法,特别是 Modus Tollens 的应用。主要分析了量子引力统一理论的支持情况,通过三步推理得出该理论缺乏实验数据支持。
这一页讲的是符号逻辑中的推理方法,主要通过 Modus Tollens(否定后件推理法)分析量子引力统一理论(Quantum-Gravity Unification Theory, QGTheory)的支持情况。第一步的规则是“理论获得资助(ReceivesFunding)意味着它被学术界认可(RecognizedInAcademia)”,事实是 QGTheory 没有被学术界认可,因此推导出 QGTheory 没有获得资助。第二步的规则是“理论被社区接受(AcceptedByCommunity)意味着它获得资助”,事实是 QGTheory 没有获得资助,因此推导出 QGTheory 没有被社区接受。第三步的规则是“理论有数据支持(SupportedByData)意味着它被社区接受”,事实是 QGTheory 没有被社区接受,因此推导出 QGTheory 没有数据支持。通过这三步逻辑推理,最终得出结论:量子引力统一理论缺乏实验数据支持。这一分析展示了符号逻辑在科学理论评估中的应用,强调了逻辑推理在验证理论合理性上的重要性。

这一页讲的是神经网络的训练过程,包括前向传播、损失计算、反向传播和梯度下降优化。图示解释了梯度下降如何通过调整权重减少损失。
这一页讲的是神经网络如何通过训练来优化权重以减少预测值与真实值之间的误差。主要步骤包括:1. 前向传播(Forward Propagation),输入数据通过网络层生成输出;2. 损失计算(Loss Calculation),通过损失函数计算预测值与真实值的差异;3. 反向传播(Backpropagation),通过计算梯度调整权重以减少误差;4. 梯度下降优化(Optimization using Gradient Descent),通过逐步更新权重来提高准确性。右侧的图表展示了梯度下降的数学原理,曲线代表损失函数 J(w),横轴是权重 w。初始权重通过梯度下降沿着曲线下降,最终接近全局最小值 J_min(w)。这表明网络通过不断调整参数来减少损失。举例来说,若初始预测值与真实值差距较大,梯度下降会逐步调整权重,使预测更加准确。这些步骤是神经网络学习的核心,确保模型能够有效地适应数据并提高性能。
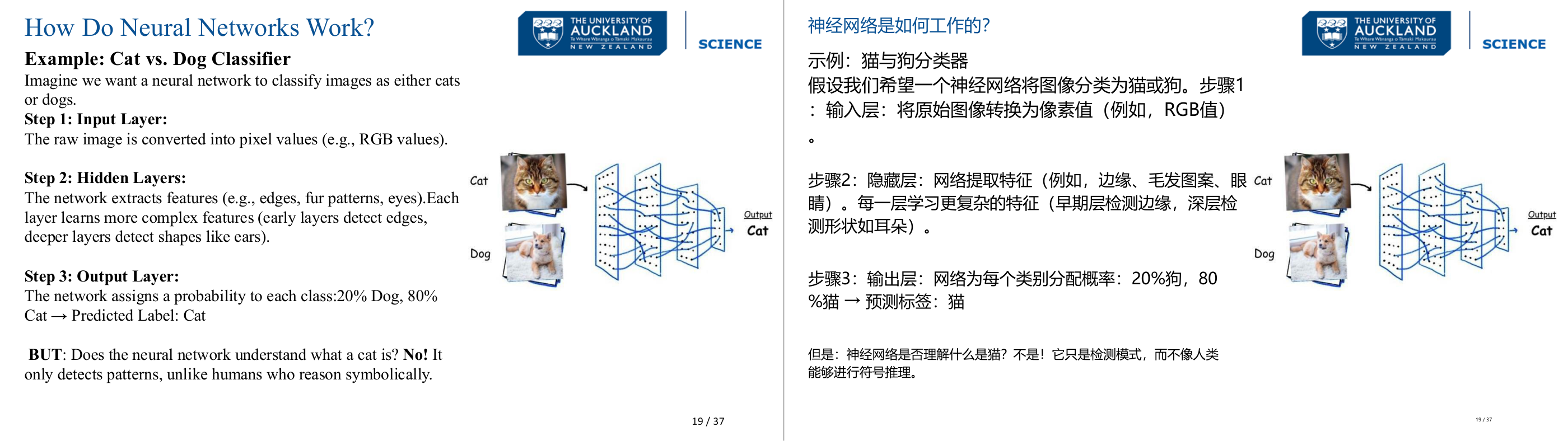
这一页讲的是神经网络如何工作,通过猫狗分类器的例子说明。重点包括输入层处理像素值、隐藏层提取特征以及输出层预测分类结果。
这一页讲的是神经网络的工作原理,通过一个猫狗分类器的例子来说明。首先,输入层将原始图像转化为像素值,例如 RGB 值,这是神经网络处理图像的第一步。接着,隐藏层负责提取特征,早期层识别简单特征如边缘和纹理,而深层则识别更复杂的形状和结构,比如耳朵的形状。最后,输出层根据提取的特征为每个类别分配概率,例如 20% 是狗,80% 是猫,最终预测结果为猫。图中展示了神经网络的结构,从输入图像到输出分类的流程。需要注意的是,神经网络并不真正“理解”猫或狗的概念,它仅仅通过模式识别来完成任务,而不像人类能够进行符号化推理。这种模式识别能力是神经网络在图像分类中的核心优势。

这一页讲的是传统神经网络的局限性及结合逻辑的必要性。主要包括黑盒问题、数据依赖性、缺乏逻辑推理和错误敏感性,并通过医疗图像预测的例子说明问题。
这一页讲的是传统神经网络的局限性以及为什么需要将逻辑与神经网络结合。首先,传统神经网络存在黑盒问题(black-box problem),即虽然强大但缺乏可解释性;其次是数据依赖性(data dependency),需要大量标注数据来训练模型;第三是缺乏逻辑推理能力(lack of logical reasoning),无法处理基于规则的推理;最后是错误敏感性(error sensitivity),可能会在错误预测时表现出高度自信。这些问题限制了神经网络在需要解释性和逻辑推理的场景中的应用。举例来说,一个训练在医疗图像上的神经网络可以预测疾病,但无法解释为什么某张图像表明癌症。这对医生来说是不够的,因为他们需要的不仅是预测结果,还需要明确的解释。这说明了结合逻辑推理的重要性,以提高模型的可解释性和可靠性。

这一页讲的是逻辑神经网络(Logic Neural Networks, LNNs)的需求。逻辑的优势包括增加可解释性、减少对数据的依赖以及提高一致性,但单独使用逻辑存在扩展性和处理不确定性的局限。LNNs结合逻辑和神经网络的优点。
这一页讲的是逻辑神经网络(Logic Neural Networks, LNNs)的需求及其解决的问题。逻辑的优势在于:1)增加可解释性(Explainability),通过规则和约束提供透明的推理过程;2)减少数据依赖(Reduces data dependency),基于知识的推理降低了对大数据的需求;3)提高一致性(Improves consistency),逻辑约束可以避免输出结果的矛盾。例如,一个用于贷款审批的 AI 不仅需要预测“批准/拒绝”,还需要给出理由,比如“因为薪资高且信用评分好”。然而,单独使用逻辑存在问题:逻辑系统难以扩展(Scaling),手动编写大量规则不切实际,并且逻辑难以处理不确定性(Uncertainty),例如无法应对像“明天下雨的概率是多少?”这样的概率问题。解决方案是逻辑神经网络(LNNs),它结合了逻辑和神经网络的优势,既能提供透明的推理,又能处理复杂的概率和不确定性问题。
这一页讲的是为什么单独使用神经网络或单独使用逻辑都有不可克服的局限,进而引出 Logic Neural Networks(LNN,逻辑神经网络)作为结合方案的必要性。神经网络的三大弱点:一是黑箱问题,输出无法解释;二是数据依赖,需要大量标注数据才能训练;三是缺乏规则推理,对于规则确定的场景(如法律、医疗合规)无法胜任。纯逻辑系统的两大弱点:一是无法扩展,手写几千条规则极其耗费人工;二是无法处理不确定性,现实中很多情况是概率性的,例如「明天下雨的概率是 70%」,经典逻辑无法表达这类模糊信息。LNN 的价值主张就是用神经网络自动学习规则权重,同时用逻辑结构约束网络输出的一致性,并且提供可解释的推理路径。考试怎么考:这类「对比分析」题型常出现在简答或选择题里,比如「哪项是神经网络的缺点」或「LNN 相比纯神经网络的优势是什么」。关键词要记住:explainability(可解释性)、data dependency(数据依赖)、logical consistency(逻辑一致性)。易错点:不要把 LNN 的「可解释性」和普通 attention 可视化混淆,LNN 提供的是基于形式逻辑规则的结构性解释,而不仅仅是热力图。

这一页讲的是可微逻辑(Differentiable Logic)如何在 AI 中实现逻辑运算。主要内容包括传统布尔逻辑的局限性、软逻辑(Soft Logic)的连续值定义,以及其运算规则和应用示例。
这一页讲的是可微逻辑(Differentiable Logic)在 AI 中的应用。传统布尔逻辑是离散的(只包含 True/False),而神经网络处理的是连续值(0 到 1),因此无法直接使用传统逻辑。解决方法是将逻辑转化为可微的连续操作,使 AI 能够从数据中学习。例如,软逻辑为逻辑赋予概率值(如 0.8 表示可能为真)。表格展示了软逻辑运算的规则:AND 运算在传统逻辑中是取最小值(min(A, B)),在软逻辑中是 A×B;OR 运算在传统逻辑中是取最大值(max(A, B)),而在软逻辑中是 A+B-A×B;NOT 运算在两者中均为 1-A。一个应用示例是,传统逻辑会说“要么下雨,要么不下雨”,而软逻辑系统会说“下雨的概率是 75%”。这种逻辑的连续性使得神经网络能够更灵活地处理不确定性问题。
这一页讲的是 Differentiable Logic(可微分逻辑)的核心思想,以及 Soft Logic 运算符的具体公式,这是 LNN 能够用梯度下降训练的数学基础。问题的根源:传统布尔逻辑是离散的(非 0 即 1),不可微分,无法进行反向传播。解决方案:把逻辑运算替换成连续的、可微分的替代版本,使得逻辑值可以是 0 到 1 之间的任意实数(代表概率或置信度)。三个 Soft Logic 运算的公式:NOT(非)仍然是 1 减 A,和布尔一样;AND(与)从 min(A, B) 改为 A 乘以 B,即乘积;OR(或)从 max(A, B) 改为 A 加 B 减去 A 乘以 B,即 Product-Sum 公式。以 OR 为例,当 A 等于 0.9、B 等于 0.7 时,OR 结果是 0.9 加 0.7 减 0.63 等于 0.97,比任何单个值都高,符合「至少一个为真则结果更可能为真」的直觉。AND 的乘积形式确保只有两个都接近 1 时结果才高,任何一个接近 0 都会把结果拉低。考试怎么考:直接给概率数值让你计算 soft AND/OR,计算题非常常见(见第 23、24 页的练习题)。易错点:OR 公式的第三项「减去 A 乘以 B」很多人会忘记,导致结果超过 1,而 OR 的结果必须在 0 到 1 之间,忘了减项就会出错。另外注意 soft AND 用的是乘积,不是 min,这与 Fuzzy Logic 里用 min 表示 AND 是不同的。
这一页讲的是软逻辑 (Soft Logic) 在 AI 中的应用,通过公式计算症状的联合概率。
这一页讲的是软逻辑 (Soft Logic) 的应用,特别是在医疗领域,用于计算患者出现某些症状的联合概率。幻灯片中给出了三个症状的概率值:发烧 (Fever, F) 为 0.9,咳嗽 (Cough, C) 为 0.7,呼吸急促 (Shortness of Breath, SOB) 为 0.5。软逻辑公式 A∨B = A + B - A×B 用于计算两个事件的联合概率。这里的问题是计算发烧或咳嗽 (F∨C) 的概率。根据公式,计算过程为:0.9 + 0.7 - (0.9×0.7) = 1.6 - 0.63 = 0.97。因此正确答案是 A (0.97)。这种方法的重要性在于它能处理概率不确定性,并结合多个症状概率来帮助 AI 系统做出更准确的判断。例如,医院可以利用这种方法评估患者是否可能患有严重感染,从而优化诊断和治疗流程。

这一页讲的是软逻辑 (Soft Logic) 在 AI 中的应用,通过公式计算症状组合的概率。
这一页讲的是软逻辑 (Soft Logic) 的应用,具体例子是一个医院用基于软逻辑的 AI 系统来评估患者患严重感染的概率。幻灯片列出了三个症状的概率值:发烧 (Fever, F) 为 0.9,咳嗽 (Cough, C) 为 0.7,呼吸急促 (Shortness of Breath, SOB) 为 0.5。问题要求计算“咳嗽与呼吸急促的概率”与“发烧的概率”的联合概率,即 (C ∧ SOB) ∨ F,使用软逻辑公式。公式定义为:A ∧ B = A × B,A ∨ B = A + B - A × B。计算过程如下:首先计算 C ∧ SOB = 0.7 × 0.5 = 0.35;然后计算 (C ∧ SOB) ∨ F = 0.35 + 0.9 - (0.35 × 0.9) = 1.25 - 0.315 = 0.935。因此答案是 C。这个例子展示了软逻辑如何处理概率组合,特别适合在不确定性环境下的决策问题。
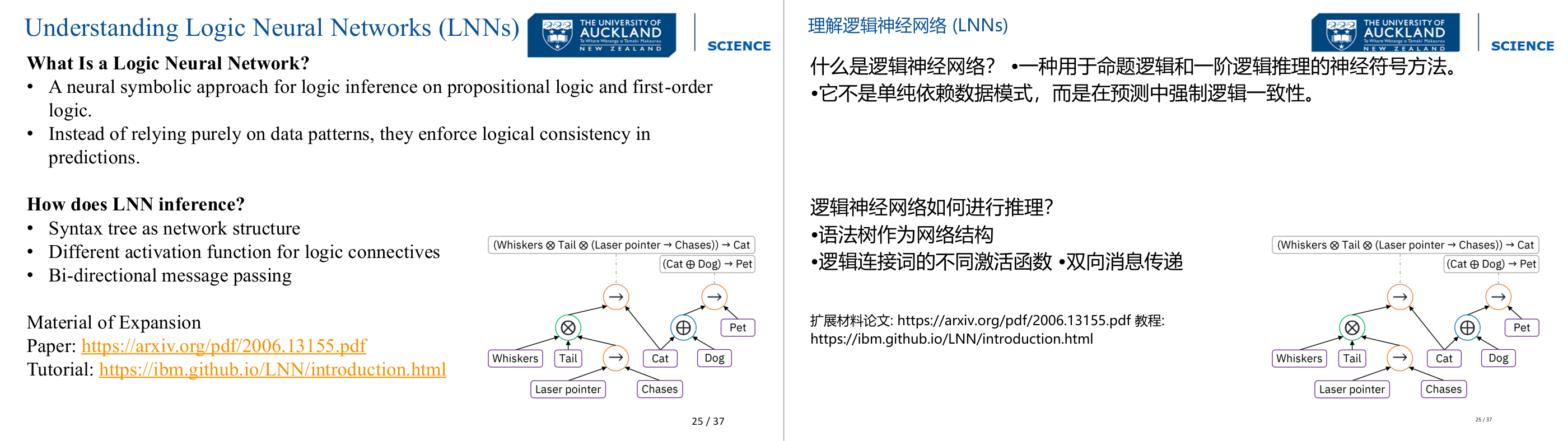
这一页讲的是 Logic Neural Networks (LNNs) 的定义与推理机制。主要包括 LNN 的逻辑符号方法、语法树网络结构和双向信息传递等特点。
这一页讲的是 Logic Neural Networks (LNNs),一种用于命题逻辑和一阶逻辑推理的神经符号方法。LNN 不仅依赖数据模式,还强调逻辑一致性,从而提高预测的准确性。在推理机制方面,LNN 使用语法树作为网络结构,将逻辑连接词映射为不同的激活函数,并通过双向信息传递来实现推理。图示部分展示了一个语法树结构,其中逻辑连接词如“⊗”和“⊕”分别表示逻辑与和逻辑或,箭头表示逻辑推导关系。例如,图中展示了“Whiskers 和 Tail 与 Laser pointer 导致 Chases,从而推导出 Cat”的逻辑关系。这种结构化的推理方式使得 LNN 能够处理复杂的逻辑关系。对于进一步学习,幻灯片提供了相关的论文和教程链接,帮助深入理解 LNN 的理论和应用。
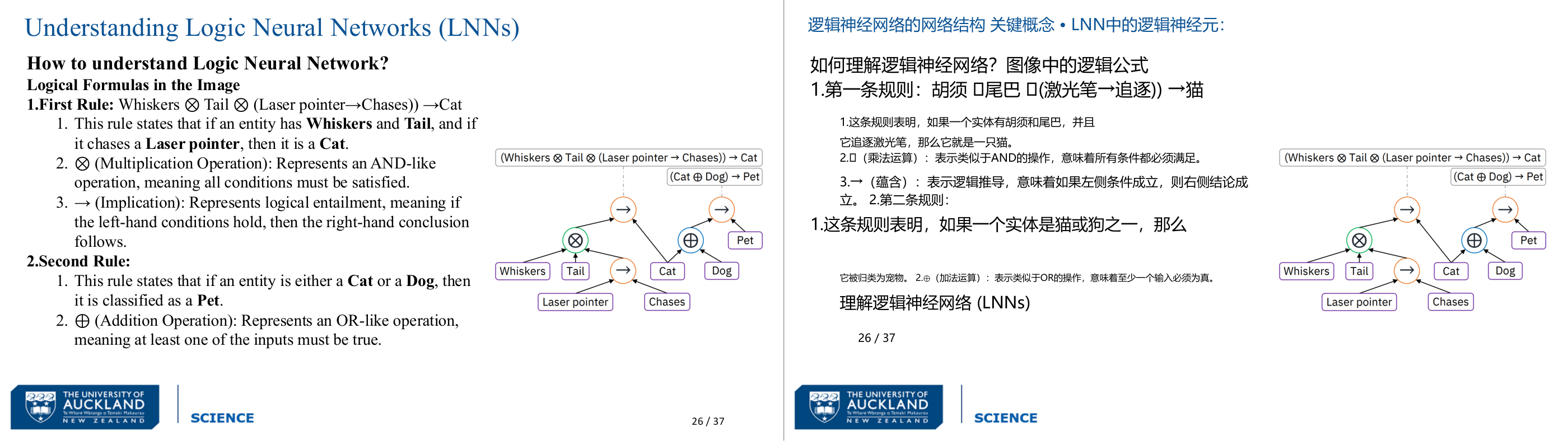
这一页讲的是逻辑神经网络 (Logic Neural Networks, LNNs) 的理解方法,重点介绍了两个逻辑规则:第一条规则定义如何识别猫,第二条规则定义宠物的分类。
这一页讲的是逻辑神经网络 (Logic Neural Networks, LNNs) 的工作原理,主要通过两个逻辑规则来说明。第一条规则是:如果一个实体同时具有 Whiskers(胡须)和 Tail(尾巴),并且它追逐 Laser pointer(激光笔),那么它可以被归类为 Cat(猫)。这里的“⊗”表示乘法操作,类似于逻辑中的 AND,要求所有条件都满足;“→”表示逻辑蕴含,即如果左侧条件成立,则右侧结论必然成立。第二条规则是:如果一个实体是 Cat(猫)或 Dog(狗),那么它可以被归类为 Pet(宠物)。这里的“⊕”表示加法操作,类似于逻辑中的 OR,表示至少一个输入条件成立即可。图中展示了这两个规则的逻辑结构:左侧的树形结构说明了如何通过多个条件推导出实体是猫;右侧的树形结构说明了如何通过猫或狗的分类推导出实体是宠物。这些规则和结构展示了 LNNs 的逻辑推理能力,能够将复杂的条件组合转化为明确的分类结果。
这一页讲的是如何把逻辑规则直接转化为 LNN 的网络结构,以猫狗分类为例说明 LNN 的「可读性」和符号神经结合的机制。第一条规则:Whiskers 与 Tail 与 (LaserPointer → Chases) 这三者通过「乘法节点 ⊗(AND-like)」组合,蕴含 Cat,意思是「如果有胡须、有尾巴、且追激光笔,那么是猫」。第二条规则:Cat 或 Dog 通过「加法节点 ⊕(OR-like)」组合,蕴含 Pet,意思是「猫或狗都是宠物」。网络结构的直接对应:每条规则的语法树(syntax tree)对应 LNN 里的一个子网络,每个逻辑连接词(AND/OR/IMPLICATION)对应一种有特定激活函数的神经元,而不是普通神经网络里统一的 sigmoid 或 ReLU。这样做的好处是:网络结构本身就是可读的规则,不再是黑箱,每个神经元都有明确的逻辑语义。考试怎么考:给你一段自然语言描述,让你画出或识别对应的 LNN 网络结构;或者给你网络结构,让你翻译回逻辑规则。易错点:⊗ 代表 AND(所有条件都要满足),⊕ 代表 OR(至少一个满足),不要弄混,考试里符号可能会变换,要从语义判断是哪种运算。
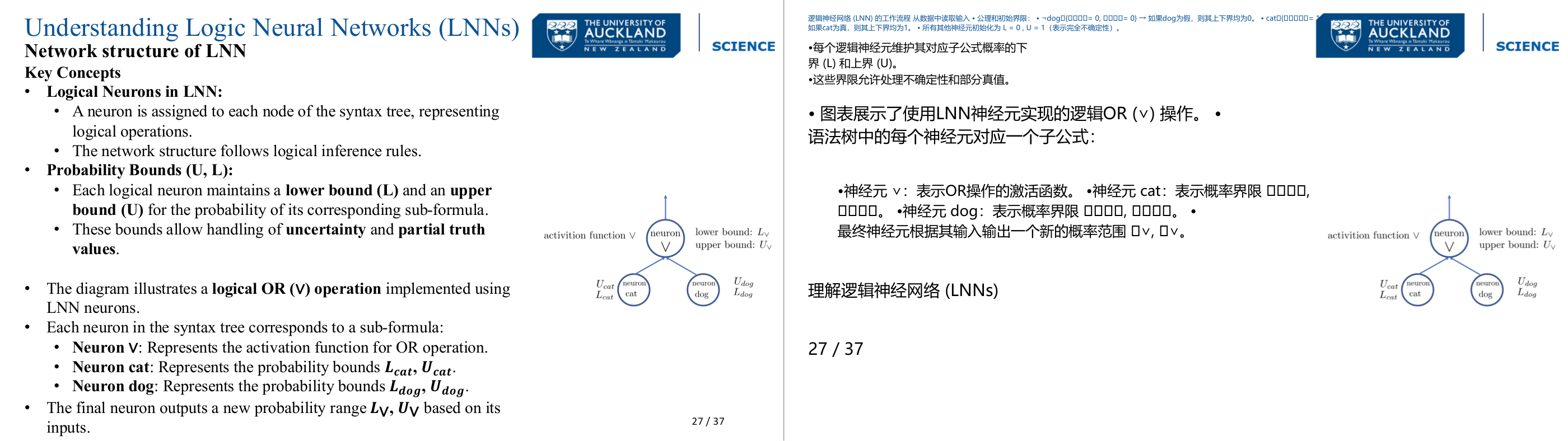
这一页讲的是逻辑神经网络 (LNN) 的网络结构,重点包括逻辑神经元的分配和概率范围 (U, L) 的处理,以及逻辑 OR 操作的实现。
这一页讲的是逻辑神经网络 (LNN) 的网络结构。首先,LNN 的逻辑神经元 (Logical Neurons) 被分配到语法树的每个节点,用于表示逻辑运算,并遵循逻辑推理规则。其次,概率范围 (Probability Bounds) 包括下界 (Lower Bound, L) 和上界 (Upper Bound, U),用于表示子公式的概率。这种设计可以处理不确定性和部分真值 (Partial Truth Values)。页面右侧的图展示了一个逻辑 OR (∨) 操作的实现。每个语法树中的神经元对应一个子公式,例如图中的 Neuron cat 和 Neuron dog 分别表示与“猫”和“狗”相关的概率范围 Lcat, Ucat 和 Ldog, Udog。最终,Neuron ∨ 结合输入的概率范围,输出新的概率范围 Lv, Uv。这个结构能够有效地将逻辑推理与概率处理结合,用于处理复杂的逻辑问题。

这一页讲的是逻辑神经网络(LNN)的工作流程,包括数据输入、双向信息传递及其收敛过程。主要介绍了初始边界设定和上下行消息传递的机制。
这一页讲的是逻辑神经网络(Logical Neural Networks, LNN)的工作流程。首先在数据输入阶段,定义了初始边界条件,例如如果“dog”为假,则其上下界均为0;如果“cat”为真,则上下界均为1;其他神经元的初始值设为L=0, U=1,表示完全不确定性。接着,双向信息传递直到收敛是LNN的核心机制。上行传递(Upward Pass)根据神经元的子节点更新其边界,例如“dog”和“cat”共同影响“pet”,则“pet”的边界根据两者计算。下行传递(Downward Pass)则根据父节点更新子节点的边界,例如如果“pet”已知为真(U=1, L=1),则其子节点“dog”和“cat”的边界需调整以保持一致性。这种双向传递机制确保了网络的逻辑一致性和收敛性。
这一页讲的是 LNN 的推理工作流,重点是「双向消息传递(Bidirectional Message Passing)」机制,这是 LNN 区别于普通神经网络最独特的地方。LNN 推理分三个阶段:第一阶段是读入数据,将已知事实映射为神经元的概率区间,比如已知「dog 为假」则设 U_dog 等于 0、L_dog 等于 0;已知「cat 为真」则设 U_cat 等于 1、L_cat 等于 1;其余神经元初始化为 L 等于 0、U 等于 1,代表完全不确定。第二阶段是双向消息传递:向上传播(Upward Pass)从叶节点(具体事实)出发,逐层计算父节点的概率区间,比如 Whiskers 和 Tail 的真值合并后影响 Cat 的真值范围;向下传播(Downward Pass)从高层规则出发,把约束向下传递,比如若已知 Pet 为真,则 Cat 和 Dog 的真值范围必须调整以满足 OR 逻辑的一致性。这个双向传播会反复迭代,直到所有神经元的 L 和 U 不再变化为止(收敛)。第三阶段是读取目标神经元的最终 L 和 U,判断结论的逻辑状态。考试怎么考:描述向上/向下传播各自的作用,或者给出一组初始边界让你手算一步传播。易错点:不要把「向上」和「向下」搞反,向上是数据驱动(从已知事实推断结论),向下是规则驱动(从规则约束反推前提)。

这一页讲的是逻辑神经网络 (LNN) 中的真值范围解释,包括下界 L 和上界 U 的逻辑意义。
这一页讲的是逻辑神经网络 (Logic Neural Networks, LNN) 中如何通过真值范围的上下界 (Lower Bound, L 和 Upper Bound, U) 来解释逻辑意义。L 和 U 的范围在 0 到 1 之间,不同的范围组合对应不同的逻辑解释。幻灯片的表格列出了四种主要情况:第一种是 L=0.0 且 U=1.0,表示不确定性 (uncertain),即没有足够的信息;第二种是 L 和 U 都小于某阈值 α,表示逻辑为假 (false),因为上下界都低于阈值;第三种是 L 和 U 都大于等于 α,表示逻辑为真 (true),因为上下界都高于阈值;最后一种情况是 L > U,表示逻辑矛盾 (contradiction),即检测到不一致的逻辑。下方的图形进一步直观展示了这些范围的逻辑解释,黄色和绿色区域分别代表真值范围的不同状态,例如未知 (unknown)、假 (false)、真 (true) 和矛盾 (contradiction)。这种方法在逻辑推理和不确定性处理方面非常重要,因为它能以数学方式明确表达逻辑状态。
这一页讲的是 LNN 中概率区间 (L, U) 的四种逻辑解释,这是判断 LNN 推理结论的标准,也是考试里最可能出现的填空/判断题材料。LNN 用下界 L 和上界 U 表示一个命题的真值范围,而不是单一概率值,目的是显式表达不确定性。四种状态:第一,L 等于 0、U 等于 1,代表「完全不确定(Uncertain)」,没有任何信息可以约束这个命题;第二,L 和 U 都低于阈值 α,代表「假(False)」,即便在最乐观的情形下(取上界)也仍然低于判断门槛;第三,L 和 U 都高于或等于 α,代表「真(True)」,即便最悲观的情形(取下界)也超过了门槛;第四,L 大于 U,代表「矛盾(Contradiction)」,说明系统中存在逻辑冲突,这种情况在软逻辑里是可以检测出来的(而传统逻辑里矛盾会导致「爆炸」,推出任何结论)。通常 α 取 0.5 作为默认阈值。考试怎么考:给你具体的 L、U 数值和 α,让你判断该命题是 True / False / Uncertain / Contradiction,见第 31 页练习题(L=0.3, U=0.7, α=0.5,区间横跨阈值,答案是 Uncertain)。易错点:如果 L 小于 α 但 U 大于 α,说明区间跨越了阈值,结论是 Uncertain,不要误判为 True 或 False。
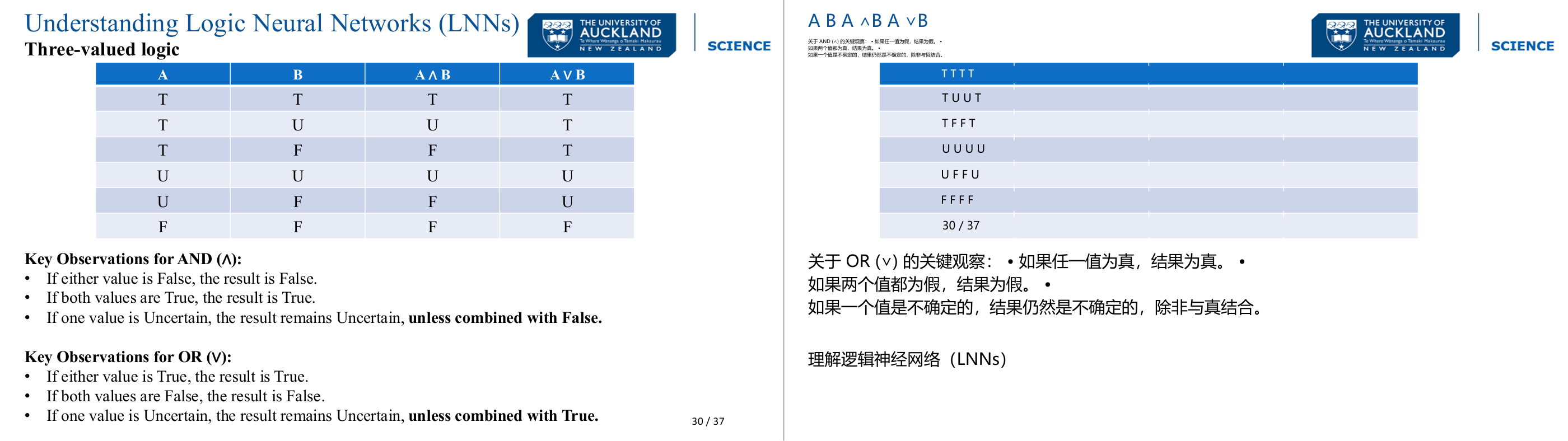
这一页讲的是三值逻辑在逻辑神经网络 (Logic Neural Networks, LNNs) 中的应用,重点分析 AND (∧) 和 OR (∨) 的逻辑运算规则。
这一页讲的是三值逻辑 (Three-valued logic) 在逻辑神经网络 (Logic Neural Networks, LNNs) 中的应用。三值逻辑包括 True (T)、Uncertain (U)、False (F) 三种值,幻灯片通过表格展示了 AND (∧) 和 OR (∨) 运算的结果。表格的列分别表示输入值 A 和 B,以及运算结果 A∧B 和 A∨B。对于 AND 运算:当任一输入为 False 时,结果为 False;若两者均为 True,结果为 True;若有一个值为 Uncertain,结果为 Uncertain,除非另一个值为 False。对于 OR 运算:当任一输入为 True 时,结果为 True;若两者均为 False,结果为 False;若有一个值为 Uncertain,结果为 Uncertain,除非另一个值为 True。这种三值逻辑扩展了传统二值逻辑的表达能力,允许处理不确定性信息,在复杂逻辑推理中具有重要意义。例如,在实际应用中,传感器数据可能包含不确定性(U),三值逻辑可以帮助更准确地处理这些情况。
这一页讲的是三值逻辑(Three-valued Logic)的真值表,LNN 在推理过程中用到的不是传统二值逻辑(True/False),而是包含第三个值 Uncertain(U)的三值系统,这直接影响 LNN 中 AND 和 OR 运算的传播行为。AND 运算的规律:只要有一个输入是 False,结果就是 False(False 有「吸收性」);只有两个都是 True 才是 True;如果有一个是 Uncertain 但另一个不是 False,结果是 Uncertain。OR 运算的规律:只要有一个输入是 True,结果就是 True(True 有「吸收性」);只有两个都是 False 才是 False;Uncertain 与 False 的 OR 是 Uncertain。这张表的意义在于:当 LNN 做双向消息传递时,True 和 False 这两个确定值会通过 AND/OR 的「吸收性」直接固定住某些结论,而 Uncertain 会继续等待更多信息。比如第 32 页的练习:Heavy 是 True,Sharp 是 Uncertain,Dangerous 等于 Sharp OR Heavy,由于 True OR Uncertain 等于 True,所以 Dangerous 一定是 True。考试怎么考:给你一组 True/False/Uncertain 输入和一个逻辑表达式,让你推导结论是 True/False/Uncertain。易错点:很多人会把 Uncertain OR False 误判为 False,但正确答案是 Uncertain——只有两个都是 False 时 OR 才是 False。

这一页讲的是逻辑神经网络(LNN)中神经元的真值范围与阈值的关系。题目给定 L=0.3, U=0.7, α=0.5,答案是 C,神经元的真值不确定。
这一页讲的是逻辑神经网络(LNN)中如何通过真值范围(L 和 U)和阈值(α)来判断神经元的状态。题目中,真值范围 L=0.3 和 U=0.7,阈值 α=0.5。由于真值范围同时跨越了阈值 α=0.5 的两侧,导致无法明确判断神经元是真还是假,因此神经元的真值被归类为“不确定”(uncertain)。这反映了 LNN 模型中处理模糊逻辑的能力,允许神经元的状态处于一种不确定性状态,而不是简单地归类为绝对真或绝对假。这种机制在处理复杂逻辑推理时非常重要,例如在实际应用中,面对模棱两可的数据时,模型可以保留这种不确定性,而不是强行做出明确判断。

这一页讲的是逻辑神经网络 (LNN) 的推理过程,用于判断物体是否危险。
这一页讲的是逻辑神经网络 (LNN) 的推理过程,用于判断物体是否危险。幻灯片中给出了一个机器人助手的训练实例,基于物体的两个属性:“Sharp”(尖锐)和“Heavy”(沉重),分别定义了其真值范围:Lsharp = 0.2, Usharp = 0.8;Lheavy = 0.6, Uheavy = 1.0。分类的阈值 α 设置为 0.5,规则为危险物体满足“Sharp 或 Heavy”(Sharp ∨ Heavy)。根据这些条件,推理问题是:物体的危险性属于哪种分类?选项包括:A) 明确危险;B) 明确安全;C) 不确定(可能危险但不保证);D) 矛盾状态。通过分析,这种推理方法展示了 LNN 如何结合属性范围和逻辑规则进行分类,强调了 LNN 在处理模糊性和不确定性方面的能力。

这一页讲的是逻辑神经网络 (LNNs) 中的推理规则,重点是如何判断对象是否危险。主要讨论了 Heavy 和 Sharp 属性的状态,以及逻辑规则 Dangerous 的推导过程。
这一页讲的是逻辑神经网络 (Logic Neural Networks, LNNs) 中的推理过程,具体分析了 Heavy 和 Sharp 属性对 Dangerous 属性的影响。首先,Heavy 属性的下界 L = 0.6 和上界 U = 1.0,均高于阈值 α = 0.5,因此 Heavy 是确定为 true 的。其次,Sharp 属性的下界 L = 0.2 和上界 U = 0.8,跨过了阈值 α = 0.5,这意味着 Sharp 是不确定的。接着,逻辑规则 Dangerous ← (Sharp ∨ Heavy) 表示只要 Sharp 或 Heavy 中任意一个为 true,Dangerous 就必须为 true。由于 Heavy 已经确定为 true,即使 Sharp 是不确定的,Dangerous 仍然是确定为 true。因此,最终结论是该对象是“Definitely Dangerous”(绝对危险)。这一推理过程展示了 LNNs 如何处理不确定性并得出逻辑结论。

这一页讲的是逻辑神经网络(Logic Neural Networks, LNNs)的 Lukasiewicz 类逻辑,包括基础激活函数和逻辑与(AND)操作的定义与计算方式。
这一页讲的是逻辑神经网络(Logic Neural Networks, LNNs)的 Lukasiewicz 类逻辑。首先,基础激活函数(Basis Activation Function)定义为 f(x) = max(0, min(1, x)),它确保输出值始终在 [0,1] 的范围内。这种设计有助于保持逻辑神经网络的可微性,从而支持梯度计算。其次,逻辑与(AND)操作的计算公式为 Λxi = f(1 - Σi(1 - xi))。这个公式的直觉是,当所有输入值都接近 1 时,逻辑与操作的输出值才会较高。通过例子可以看出其应用:如果输入 x1 = 1, x2 = 0.5,则 AND(x1, x2) = f(1 - (0 + 0.5)) = f(0.5) = 0.5;而如果输入 x1 = 0, x2 = 0,则 AND(x1, x2) = f(1 - (1 + 1)) = f(-1) = 0。这说明只有当所有输入值都接近 1 时,逻辑与操作的输出才会接近 1。
这一页讲的是 Lukasiewicz(卢卡西维奇)逻辑风格的激活函数,这是 LNN 具体实现 AND/OR 运算的数学公式,也是 LNN「可微分」特性的技术核心。基础激活函数 f(x) 定义为 max(0, min(1, x)),即把 x 截断在 0 到 1 区间内,类似 ReLU 但是双向截断,保证输出始终是有效的概率值,且处处可微(除了截断边界)。AND 运算的计算方式是:先对每个输入求「补」(1 减去该输入),然后把所有补求和,再用 1 减去这个和,最后套上激活函数 f。公式可以理解为:把每个输入偏离 1 的距离加起来,再从 1 里扣除。如果所有输入都是 1,补都是 0,求和是 0,结果是 f(1) 等于 1,AND 成立;如果有任何输入接近 0,其补接近 1,求和会超过 1,1 减去它会变负,f 截断到 0,AND 失败。例子验证:x1 等于 1,x2 等于 0.5,AND 等于 f(1 减去 (0 加 0.5)) 等于 f(0.5) 等于 0.5;x1 等于 0,x2 等于 0,AND 等于 f(1 减去 (1 加 1)) 等于 f(-1) 等于 0。考试怎么考:直接代入数值计算 AND 或 OR 的结果,考验你对公式的记忆和运算。易错点:AND 公式里「1 减去所有补的和」容易算错,特别是当有多个输入时要把每个 (1 减 xi) 都加进去,别漏项。

这一页讲的是 Lukasiewicz-like Logic 中的逻辑 OR 操作。重点包括公式定义、确保至少一个输入为高时输出为高,以及具体计算示例。
这一页讲的是 Lukasiewicz-like Logic 中逻辑 OR 操作的计算方式。公式表示为:逻辑 OR 的输出是通过对所有输入值求和后,应用一个函数 f 得到的。这个操作的核心是确保当至少一个输入值较高时,输出的 truth value 也会较高。幻灯片提供了两个具体示例:第一个例子中,若 x₁=1, x₂=0.5,则 OR(x₁, x₂)=f(1+0.5)=f(1.5)=1,说明输出为高值;第二个例子中,若 x₁=0, x₂=0,则 OR(x₁, x₂)=f(0+0)=f(0)=0,说明输出为低值。这种逻辑操作在逻辑神经网络(LNNs)中非常重要,用于处理不确定性输入时确保逻辑推理的准确性。
这一页讲的是 Lukasiewicz 逻辑中 OR 运算的激活函数,与 AND 是对偶关系,也是 LNN 里「OR 神经元」的具体计算方式。OR 的计算方式是:直接把所有输入相加,然后套上激活函数 f,公式是 f(x1 加 x2 加...加 xn)。直觉理解:OR 表示「至少有一个为真」,把所有输入直接相加,任何一个接近 1 就会让总和足够大,激活函数把它截断到 1;当所有输入都是 0 时,和也是 0,f(0) 等于 0,OR 失败。与第 22 页的 Product-Sum 公式对比:这里是 Lukasiewicz 风格(直接加再截断),而 Product-Sum 是 A 加 B 减 A 乘以 B,两种都是 OR 的 soft 近似,但 Lukasiewicz 版本在多输入时更简洁,直接把所有项加起来即可。例子验证:x1 等于 1,x2 等于 0.5,OR 等于 f(1 加 0.5) 等于 f(1.5) 等于 1(截断上界);x1 等于 0,x2 等于 0,OR 等于 f(0 加 0) 等于 f(0) 等于 0。考试怎么考:注意区分两种 soft OR 公式——Lukasiewicz 版(直接求和后截断)和 Product-Sum 版(A 加 B 减 A 乘以 B),考试题目会明确说明用哪种,要会两种都计算。计算步骤:先求和,再 max(0, min(1, 结果))。易错点:不少同学在多输入 OR 时忘记套激活函数 f,直接输出求和值,如果和超过 1 就会得到错误结果;f 是保证输出合法概率的关键步骤,必须套上。

这一页讲的是逻辑神经网络 (LNN) 的推理和收敛过程,重点包括双向信息传递、上下传播以及目标神经元的边界检查。
这一页讲的是逻辑神经网络 (Logic Neural Networks, LNN) 的推理和收敛过程。LNN 通过双向信息传递 (bidirectional message passing) 来更新神经元的真值边界,直到收敛。主要步骤包括:第一,读取输入数据,输入通常是公理和事实,这些会映射到神经元的真值边界。第二,进行双向信息传递,分为上下两种传播方式:上行传播 (upward pass) 从叶节点(输入数据)开始向上传播,例如“Whiskers”和“Tail”结合影响“Cat”,确保逻辑规则逐步评估;下行传播 (downward pass) 从高层逻辑规则开始向下传播,例如“Pet”会影响“Cat”和“Dog”的真值边界,确保网络逻辑一致性。最后,检查目标神经元的边界,当信息传递收敛后,目标神经元的真值边界会被最终确定,从而支持推理和决策。右侧的图展示了这一过程的结构,绿色箭头表示上行传播,黄色箭头表示下行传播,节点之间的关系体现了逻辑规则的影响。

这一页讲的是总结与问答环节。感谢听众参与,并邀请提问交流。
这一页讲的是总结与问答环节。幻灯片以“Thank you! Q&A”为主要内容,表达了对听众的感谢,同时开启了问答互动的机会。这种设计通常用于演讲或报告的最后一页,目的是结束正式内容并鼓励听众参与讨论或提出问题。下方标注了演讲者姓名和所属机构(The University of Auckland, Science),表明演讲的来源和专业背景。这一页的重要性在于它为听众提供了一个开放交流的机会,同时也是演讲者展示专业性和开放态度的时刻。