第 1 / 44 页

这一页讲的是 COMPSCI 713 课程的第 5 讲,主题是知识表示(Knowledge Representation)的基础与方法。
空格=播放/暂停当前页 · Tab=切换 简短/详细/深入 · 红色「深入」为重点页的深度讲解
这一页讲的是 COMPSCI 713 课程的第 5 讲,主题是知识表示(Knowledge Representation)的基础与方法。
这一页讲的是 COMPSCI 713 课程的第 5 讲,主题是知识表示(Knowledge Representation)的基础与方法。这一讲属于人工智能(AI Fundamentals)课程的一部分,由奥克兰大学计算机科学学院的 Xinyu Zhang 教授讲授。知识表示是人工智能领域的重要内容,主要研究如何以结构化的方式存储和处理知识,使得计算机能够理解和推理。这一页还提供了讲师的个人网站链接(https://zhangxinyu-xyz.github.io/),供学生获取更多信息。课程安排在 2026 年的第一学期(S1 2026)。

这一页讲的是知识表示(Knowledge Representation)的学习内容,包括介绍及其不同方法。
这一页讲的是知识表示(Knowledge Representation)的学习内容,具体包括六个主题:1. 知识表示简介(Introduction to Knowledge Representation),介绍什么是知识表示以及它在人工智能中的重要性;2. 符号逻辑(Symbolic Logic in Knowledge Representation),探讨如何用逻辑表达知识;3. 语义网络(Semantic Networks in Knowledge Representation),讨论用图结构表示概念及其关系的方式;4. 框架(Frames in Knowledge Representation),介绍一种结构化的知识表示方法;5. 基于规则的系统(Rule-Based System in Knowledge Representation),说明如何用规则来处理知识;6. 知识图谱(Knowledge Graphs in Knowledge Representation),解释如何用图谱连接和组织知识。这些主题覆盖了知识表示的核心方法和技术,为后续深入学习奠定基础。

这一页讲的是知识表示(Knowledge Representation, KR)。它定义了如何存储、检索和处理知识以支持智能推理。重点包括其桥接数据与决策的作用,以及在医疗诊断中的应用实例。
这一页讲的是知识表示(Knowledge Representation, KR)。定义部分说明,KR 是 AI 用于存储、检索和处理知识的方法,目的是实现智能推理。为什么需要 KR?首先,它将原始数据与智能决策连接起来,使 AI 能够进行逻辑推理并推导新事实。其次,它支持知识驱动的 AI 应用,例如专家系统、搜索引擎、自动机器人和聊天机器人。页面还举了一个医疗诊断的例子:一个医疗 AI 系统可以存储关于症状、疾病和治疗的知识,并根据患者的症状推断最可能的疾病并建议治疗方案。这说明 KR 在实际应用中非常重要,尤其是在需要复杂推理的领域,例如医疗。图中展示了一个医生与 AI 系统交互的场景,进一步强调了 KR 在帮助医疗决策中的实际作用。

这一页讲的是 AI 为什么需要知识表示 (Knowledge Representation)。重点包括 AI 系统依赖结构化知识进行理解、推理和决策,以及知识表示在实际应用中的作用。
这一页讲的是 AI 需要知识表示 (Knowledge Representation) 的原因。首先,AI 系统依赖结构化知识来完成理解、推理和决策等智能任务。如果没有结构化知识,AI 只能处理原始数据,难以进行逻辑推理。幻灯片列出了几个实际应用场景及其知识表示的使用方式:1. Google Search 使用知识图谱 (Knowledge Graph) 来组织和检索相关信息;2. IBM Watson 利用结构化知识进行问答和医疗诊断;3. 自动驾驶汽车依赖知识表示处理交通规则、物体和道路条件,以确保安全导航;4. AI 聊天机器人 (如 ChatGPT 和 Siri) 存储语言学和事实知识图谱以生成更好的响应;5. 推荐系统 (如 Netflix 和 Amazon) 使用语义网络 (Semantic Networks) 和知识图谱来建议相关内容。这些例子说明了知识表示在不同领域的广泛应用及其重要性。

这一页讲的是结构化知识与非结构化知识的区别。结构化知识有明确的格式,如数据库和知识图谱;非结构化知识没有固定格式,如文本、图像和视频。
这一页讲的是结构化知识(Structured Knowledge)与非结构化知识(Unstructured Knowledge)的定义和示例。结构化知识是按照预定义格式组织的知识,具有清晰的结构,可以存储在数据库(databases)、表格(tables)、本体(ontologies)和知识图谱(knowledge graphs)中。例如关系型数据库(Relational Databases)以行和列的形式存储数据,知识图谱(Knowledge Graphs)表示实体及其关系,本体(Ontologies)则用于分类层次结构,如医学分类体系。非结构化知识则没有固定的格式,通常以原始文本(raw text)、图像(images)、视频(videos)和自由形式文档(free-form documents)存在。示例包括文本数据(Text Data)如新闻文章、研究论文和社交媒体帖子;多媒体内容(Multimedia Content)如视频、图像和音频;以及人类交流(Human Communication)如对话、电子邮件和转录内容。这一页强调了两种知识的存储方式和应用场景的差异。

这一页讲的是结构化知识(Structured Knowledge)与非结构化知识(Unstructured Knowledge)的对比。主要比较了格式、存储、处理方式、可解释性和灵活性五个方面,并通过练习题帮助理解。
这一页讲的是结构化知识(Structured Knowledge)和非结构化知识(Unstructured Knowledge)的区别。从表格中可以看到,结构化知识的格式是有组织的,例如表格、图表或模式(schema),而非结构化知识是自由形式的,比如文本、图像和视频。结构化知识通常存储在数据库、本体(ontologies)或知识图谱中,处理方式快速高效,易于查询,可解释性高且容易理解,但灵活性较低,因为它依赖于固定的模式(schema)。相比之下,非结构化知识存储在文档或多媒体文件中,需要自然语言处理(NLP)或深度学习来处理,可解释性低,需要高级AI技术支持,但灵活性高,可以捕捉复杂知识。练习题通过选择实例帮助理解结构化知识的特点,例如选项B的客户购买历史数据库是结构化知识的典型例子,因为它符合表格或模式的存储形式。

这一页讲的是结构化知识(Structured Knowledge)与非结构化知识(Unstructured Knowledge)的对比。主要内容包括两者的格式、存储方式、处理效率、可解释性和灵活性差异,并通过练习题巩固理解。
这一页讲的是结构化知识(Structured Knowledge)与非结构化知识(Unstructured Knowledge)的特性对比。表格中列出了五个关键特性:格式(Format)、存储(Storage)、处理效率(Processing)、可解释性(Interpretability)和灵活性(Flexibility)。结构化知识通常以表格、图表或模式(schema)形式组织,存储于数据库、知识图谱等,处理速度快且查询效率高,易于理解但灵活性较低,依赖固定的模式(schema)。非结构化知识则是自由形式的,如文本、图片、视频等,存储在文档或多媒体文件中,处理需要自然语言处理(NLP)或深度学习技术,可解释性较低但灵活性较高,能捕获复杂知识。练习题通过选项帮助理解结构化知识的例子,正确答案是选项 B,即存储客户购买历史的数据库,因为它符合结构化知识的定义:以预定义的格式组织数据,例如数据库或知识图谱。这一页强调了两者在实际应用中的不同特点与适用场景。

这一页讲的是知识表示(KR)的五个关键需求,包括表达能力、计算效率、可扩展性、可解释性和可修改性。每个需求都配有具体例子,说明其在 AI 应用中的重要性。
这一页讲的是知识表示(KR)的五个关键需求及其重要性。首先,知识表示方法在 AI 应用中效果不尽相同,因此需要平衡效率、灵活性和可解释性。表格列出了五个需求:第一是表达能力(Expressiveness),即 KR 方法能否表示复杂和抽象的知识,例如自动驾驶汽车需要表示交通规则、行人移动和路况。第二是计算效率(Computational Efficiency),即 KR 方法能否快速处理信息,例如 AI 欺诈检测需要每秒分析数千笔交易。第三是可扩展性(Scalability),即 KR 系统能否处理大型且不断增长的知识库,例如谷歌知识图谱包含数十亿事实和关系。第四是可解释性(Interpretability),即人类能否理解 AI 的决策过程,例如 AI 医疗诊断系统需要提供清晰的治疗推荐理由。最后是可修改性(Modifiability),即 KR 系统能否随着新知识更新,例如 AI 聊天机器人需要从新的对话中不断学习。这些需求共同确保 KR 系统在复杂的 AI 应用中有效运作。
这一页讲的是知识表示的五个关键需求,这是理解为什么不同 KR 方法各有侧重的理论基础。五个需求分别是:Expressiveness(表达能力)、Computational Efficiency(计算效率)、Scalability(可扩展性)、Interpretability(可解释性)、Modifiability(可修改性)。理解这五个维度,相当于掌握了评价任何一种 KR 方法的"评分量表"。直觉上可以这样理解:一个好的知识表示系统,既要能说清楚复杂的事(表达能力强),又要能快速回答问题(效率高),还要在知识爆炸时不崩溃(可扩展),人类要能看懂 AI 的推理过程(可解释),最后还要能不断加入新知识(可修改)。举例来说,符号逻辑的表达能力很强,但计算效率相对低;规则系统可解释性高但可扩展性差;知识图谱扩展性极强但维护成本高。考试常见考法:给你一个 AI 应用场景,让你分析它主要需要满足哪个 KR 需求,或者给出某种 KR 方法的优缺点让你用这五个维度来对号入座。易错点是把「可解释性」和「表达能力」混淆——表达能力说的是能不能把复杂知识编码进去,可解释性说的是人类能不能看懂决策过程,两者方向不同。

这一页讲的是知识表示 (Knowledge Representation) 的五个关键需求及其在自动驾驶汽车中的应用。包括表达性、计算效率、可扩展性、可解释性和可修改性。
这一页讲的是知识表示 (Knowledge Representation) 的五个关键需求及其在自动驾驶汽车中的应用。首先,表达性 (Expressiveness) 是指系统能够准确表示真实世界的道路状况、交通信号以及车辆运动,这对于自动驾驶汽车理解复杂环境至关重要。其次,计算效率 (Computational Efficiency) 强调实时处理传感器数据以做出快速决策,例如避让障碍物或保持车道。第三,可扩展性 (Scalability) 使得系统能够学习和适应新的路线和驾驶模式,从而扩展其知识库。第四,可解释性 (Interpretability) 要求 AI 能够解释其行为,例如为什么在某些情况下刹车或变道,这对于用户信任和系统调试很重要。最后,可修改性 (Modifiability) 使得模型能够根据新的道路条件进行更新,例如添加新的交通规则或环境变化。图中展示了自动驾驶汽车的视角,强调了传感器数据如何实时处理并反馈到驾驶决策中,例如识别交通信号和障碍物。这些需求共同确保自动驾驶系统的可靠性和适应性。

这一页讲的是知识表示的学习内容,包括符号逻辑、语义网络、框架、规则系统和知识图谱等关键主题。
这一页讲的是知识表示(Knowledge Representation)的学习内容,列出了几个核心主题。首先是知识表示的介绍(Introduction to Knowledge Representation),它是人工智能中用于表达和存储知识的一种方法。接下来是符号逻辑(Symbolic Logic in Knowledge Representation),强调使用逻辑符号来表达知识和推理。然后是语义网络(Semantic Networks in Knowledge Representation),它通过节点和边来表示概念及其关系。框架(Frames in Knowledge Representation)是一种结构化的知识表示方式,适合描述对象和场景。规则系统(Rule-Based System in Knowledge Representation)则通过“如果-那么”规则来实现推理。最后是知识图谱(Knowledge Graphs in Knowledge Representation),它是用于存储和查询复杂关系的一种图结构。页面右侧的词云图展示了与知识表示相关的关键词,如“representation”和“knowledge”,强调了其重要性。这些内容为后续深入学习知识表示的具体技术和应用奠定了基础。

这一页讲的是符号逻辑在知识表示中的应用。主要内容包括符号逻辑的定义、两种常用逻辑类型以及医学诊断系统中的实例。
这一页讲的是符号逻辑(Symbolic Logic)在知识表示(Knowledge Representation, KR)中的应用。符号逻辑通过形式化符号(formal symbols)和逻辑表达式(logical expressions)来表示知识,广泛用于人工智能中的推理(reasoning)、推断(inference)以及形式化验证(formal verification)。两种常用的逻辑类型包括命题逻辑(Propositional Logic)和一阶逻辑(First-Order Logic, FOL)。命题逻辑使用简单的真假语句,而一阶逻辑允许在实体之间建立关系,例如“所有人都会死亡”。幻灯片还举了一个医学诊断系统的例子,展示了如何用一阶逻辑规则进行推理。例如,规则“∀x (Flu(x) → HasSymptom(x, Fever))”表示“如果某人患有流感,他们会出现发烧症状”。另一规则“∀x (HasSymptom(x, Fever) ∧ HasSymptom(x, Cough) → LikelyDiagnosis(x, Flu))”表示“如果某人有发烧和咳嗽的症状,可以推断他们可能患有流感”。通过这些逻辑规则,AI可以从已知症状中推断疾病,体现了符号逻辑在知识表示中的重要性。
这一页讲的是符号逻辑(Symbolic Logic)在知识表示中的应用,特别是命题逻辑和一阶逻辑(First-Order Logic, FOL)的区别与用途。命题逻辑只能处理简单的真假命题,比如「今天下雨」是 true 或 false,无法刻画对象之间的关系。FOL 则引入了量词(全称量词 for all x,存在量词 exists x)和谓词,能表达「所有 x,如果 x 是人,则 x 会死」这样的普遍规律。页面上给出了两条 FOL 规则:第一条说「对所有 x,如果 x 得了流感,则 x 有发烧症状」,用符号写就是 for all x,Flu(x) 推出 HasSymptom(x, Fever);第二条说「如果 x 既有发烧又有咳嗽,则 x 很可能是流感」。这两条规则合起来就能做推理:给定患者有发烧和咳嗽这两个事实,AI 可以链式推导出「可能是流感」的结论,这叫 Modus Ponens(假言推理)。直觉上,FOL 就是把自然语言的通用规律翻译成机器可以运算的格式。考试常见考法:给你一段自然语言规则,要你写出 FOL 表达式,或者给你 FOL 表达式问它能推出什么结论。易错点:全称量词 for all 和存在量词 exists 不能乱用;谓词的参数顺序要注意,比如 HasSymptom(x, Fever) 里 x 是主体、Fever 是症状,不要颠倒。

这一页讲的是知识表示 (Knowledge Representation) 的学习内容,包括六个核心主题。
这一页讲的是知识表示 (Knowledge Representation) 的学习内容,主要包括六个核心主题:1. 知识表示的介绍 (Introduction to Knowledge Representation),帮助理解知识表示的基本概念和重要性;2. 符号逻辑 (Symbolic Logic),用于形式化表达知识并进行推理;3. 语义网络 (Semantic Networks),一种图形化的知识表示方法,强调节点和关系的连接;4. 框架 (Frames),用于结构化表示对象及其属性;5. 基于规则的系统 (Rule-Based System),通过规则和推理机制来处理知识;6. 知识图谱 (Knowledge Graphs),一种现代化的知识表示方式,广泛用于搜索引擎和人工智能应用。页面右侧的词云图进一步强调了知识表示的核心术语和相关领域。这些主题为理解人工智能中的知识管理和推理奠定了基础,后续学习将围绕这些内容展开。

这一页讲的是语义网络 (Semantic Network) 在知识表示中的应用。主要内容包括节点 (Nodes) 表示概念或对象,边 (Edges) 表示它们之间的关系,以及如何通过图结构组织知识并进行推理。
这一页讲的是语义网络 (Semantic Network) 在知识表示中的应用。语义网络是一种基于图的知识表示方法,其中节点 (Nodes) 用来表示概念或对象,比如“Cat”、“Mammal”、“Animal”,而边 (Edges) 用来定义节点之间的关系,比如“is-a”(是某种类型)或“has-part”(有某部分)。这种结构可以用来层次化地组织知识,并基于关系进行推理。页面右侧的图例展示了一个简单的语义网络,说明了“Cat”属于“Mammal”,“Mammal”属于“Animal”,以及“Cat”有“Fur”等关系。通过这种网络结构,可以清晰地表达实体之间的层次和属性关系。例如,如果我们知道“Cat is-a Mammal”,而“Mammal is-a Animal”,就可以推断“Cat is-a Animal”。此外,页面还提供了两个额外的学习资源链接,帮助深入理解语义网络的概念和应用。
这一页讲的是语义网络(Semantic Network)的基本结构和推理机制。语义网络用图来表示知识:节点(Node)代表概念或实体,边(Edge)代表实体之间的关系,最常见的关系是 is-a(是一种)和 has-property(具有属性)。比如「猫 is-a 哺乳动物」「哺乳动物 is-an 动物」「猫 has 毛发」,这三条关系构成一个小型语义网络。语义网络最核心的推理能力是继承推理(Inheritance Inference):通过 is-a 链,AI 可以传递性地推断更高层的类别归属。比如「猫 is-a 哺乳动物」加上「哺乳动物 is-an 动物」,AI 就能推出「猫是动物」,虽然网络里没有直接写这条边。另一个是属性继承(Property Inheritance):「哺乳动物是温血动物」加上「狗 is-a 哺乳动物」,AI 能推出「狗是温血动物」——狗从哺乳动物那里继承了温血这个属性。直觉类比:语义网络很像生物分类树,从界门纲目科属种逐层继承属性,代码实现上有点类似面向对象的继承。考试考法:画一个语义网络,问 AI 能推导出哪些新事实;或者反过来,给出推理结论,问它是通过哪条 is-a 链得出的。易错点:语义网络假设关系是确定的,不能处理异常(比如企鹅是鸟但不会飞),这是它的经典缺陷,考试常考。

这一页讲的是语义网络(Semantic Networks)在知识表示中的推理方式,包括层级推理和属性继承。
这一页讲的是语义网络(Semantic Networks)如何通过关系遍历来推导新知识。首先介绍了层级推理(Hierarchical Reasoning),通过“is-a”关系的传递性,AI可以从“Cat → is-a → Mammal”和“Mammal → is-an → Animal”推导出“Cat is an Animal”。其次是属性继承(Property Inheritance),通过“has-property”关系,AI可以从“Mammal → has-property → Warm-blooded”和“Dog → is-a → Mammal”推导出“Dog is warm-blooded”。图中展示了一个语义网络结构,节点代表实体如“Cat”、“Mammal”,边表示关系如“is-a”、“has”,通过遍历这些关系可以进行推理。例如,“Dog”通过“is-a”关系继承“Mammal”的属性,从而得知它是温血动物。这种推理方式在知识表示中非常重要,因为它能帮助AI高效地组织和利用知识。
这一页讲的是语义网络的优缺点对比,这是考试最常考的「批判性分析」考点之一。优点三条:一是自然直觉,语义网络的图结构符合人类思维方式,关系一眼看懂;二是支持逻辑推理,通过 is-a 和 has-property 可以推导出新事实;三是检索效率高,图结构可以快速定位相关节点。缺点三条值得重点记忆:第一,当节点和关系数量爆炸时网络会变得极其复杂,难以管理;第二,没有统一的标准格式,不同 AI 系统构建的语义网络难以互通;第三,也是最重要的考点——无法处理不确定性(Poor Handling of Uncertainty)。语义网络假设所有关系都是确定的,比如「鸟会飞」被直接编码为事实,但现实中企鹅是鸟却不会飞,这种异常情况语义网络处理起来非常笨拙。考试常见考法:给你一个场景,问语义网络是否适合,或者问某个缺点在实际中如何体现。经典易错:把语义网络和知识图谱混淆——两者都是基于图的,但知识图谱更大规模、更标准化,通常用 RDF 三元组表示;语义网络是早期、小规模的图式知识表示,不一定有严格格式。

这一页讲的是语义网络在知识表示中的优缺点。优点包括自然表示、支持逻辑推理和高效知识检索;缺点包括复杂性高、缺乏标准化表示和不擅处理不确定性。
这一页讲的是语义网络在知识表示中的优缺点。优点方面,语义网络提供了一种自然表示(Natural Representation),模仿人类思维,关系直观且易于理解;支持逻辑推理(Supports Logical Inference),通过 IS-A 和 HAS-PROPERTY 等关系推导新知识;还可以高效地进行知识检索(Efficient Knowledge Retrieval),利用图结构快速查找关联节点。缺点方面,语义网络可能变得过于复杂(Can Become Too Complex),尤其是当网络包含数百万个节点时,管理变得困难;缺乏标准化表示(No Standardized Representation),不同 AI 模型使用不同的图结构,导致整合困难;此外,对于不确定性处理较差(Poor Handling of Uncertainty),假设关系是确定性的,例如“鸟会飞”,但无法处理特殊情况如企鹅不会飞。这些优缺点说明语义网络在知识表示中有强大的能力,但在实际应用中也需要克服一些挑战,例如优化复杂性和增强灵活性。

这一页讲的是语义网络中的推理。重点是通过“is-a”关系进行推理的最佳示例。
这一页讲的是语义网络 (Semantic Network) 中的推理机制。语义网络是一种知识表示方法,使用节点和边来表示概念及其关系。在这道练习中,问题要求选择最能体现语义网络推理的选项。正确答案是选项 B,即 AI 通过“is-a”关系推断“鲸鱼是哺乳动物”。这种推理基于语义网络中的层级关系,例如“鲸鱼属于哺乳动物”这一事实可以通过网络中的节点和边表示并推导出来。其他选项中,A 描述的是随机生成响应,与推理无关;C 是基于网页的流行度排序,不涉及语义关系;D 是图像识别任务,与语义网络推理无直接关联。因此,选项 B 是最佳示例,体现了语义网络的推理能力。这种推理对于知识表示和人工智能系统的构建非常重要,因为它能够帮助系统理解和扩展知识。

这一页讲的是语义网络 (Semantic Networks) 中的推理 (Inference)。重点是通过层级关系推导知识,选项 B 是正确答案。
这一页讲的是语义网络 (Semantic Networks) 中的推理 (Inference),以及如何通过层级关系推导知识。语义网络是一种知识表示方式,允许 AI 基于层级连接(例如 IS-A 和 HAS-PROPERTY 关系)推导属性和关系。例如,选项 B 中的 AI 能够通过“鲸鱼是哺乳动物”的 IS-A 关系推导知识,这正是语义网络的核心功能。其他选项不符合推理的定义:选项 A 的随机生成回答没有基于关系;选项 C 的搜索引擎排名基于用户行为,而非语义网络中的结构化知识;选项 D 的神经网络处理非结构化数据(如图像和文本),但不基于现有符号知识推导新关系。这说明语义网络在知识表示和逻辑推理中的独特作用,可以帮助 AI更高效地理解和推导复杂的知识体系。

这一页讲的是知识表示 (Knowledge Representation) 的学习内容,包括六个主要主题。
这一页讲的是知识表示 (Knowledge Representation) 的学习内容,列出了六个主要主题:1. 知识表示的简介 (Introduction to Knowledge Representation),介绍知识表示的基本概念和重要性;2. 知识表示中的符号逻辑 (Symbolic Logic),讨论如何用逻辑表达知识;3. 语义网络 (Semantic Networks),展示如何用图形结构表示概念及其关系;4. 框架 (Frames),重点讲解一种结构化表示知识的方法;5. 基于规则的系统 (Rule-Based System),探索用规则推理知识的方式;6. 知识图谱 (Knowledge Graphs),研究如何用图谱连接和组织知识。页面右侧的词云图强调了知识表示的核心术语,如“representation”和“knowledge”,直观展示了该领域的重要关键词。这些主题涵盖了知识表示的多种方法,为后续深入学习奠定了基础。

这一页讲的是知识表示中的框架 (Frame)。框架是一种结构化表示,将实体相关信息组织为 slot-filler 结构。关键概念包括 frame 是对象,slot 是属性,filler 是属性的具体值。
这一页讲的是知识表示中的框架 (Frame)。框架是一种结构化表示方法,用于将实体相关信息组织为 slot-filler 结构。Slot 是属性或特性,用于存储具体知识(例如文本、列表、规则或操作步骤),而 Filler 是该属性的具体值。框架的灵感来源于人类认知:当我们思考某个对象时,会联想到相关属性、动作和关系。幻灯片中的表格提供了一个具体例子:以“Car”为框架,列出了四个 Slot(Brand、Colour、Engine、Owner),对应的 Filler 分别是 Tesla、Red、Electric 和 Alice。这表明框架可以系统地描述对象的多维信息。这样的结构化表示在人工智能中非常重要,因为它能帮助系统高效地存储和检索知识。例如,在一个汽车推荐系统中,可以通过框架快速匹配用户需求和车辆属性。
这一页讲的是框架(Frame)这种知识表示方法的基本结构和推理机制。Frame 由三个要素构成:Frame 本身代表某个概念或对象,Slot 是该对象的属性或特征,Filler 是属性的具体值。比如「汽车」这个 Frame 有 Brand(特斯拉)、Color(红色)、Engine(电动)等 Slot。Frame 的设计灵感来自人类认知:我们脑海中对「餐厅」有一个固定模板,包括名字、地址、菜单、营业时间等,看到一家新餐厅就自动往这个模板里填值。Frame-Based Reasoning 支持三种核心推理能力:一是默认值(Default Values),如果某个 Slot 没填,就用默认值,比如狗的腿数默认是 4;二是继承(Inheritance),子 Frame 继承父 Frame 的属性,比如「狗」Frame 继承「哺乳动物」Frame 的「有毛发 = 是」;三是过程附件(Procedural Attachment),某些 Slot 被访问时会触发特定动作,比如酒店预订 Frame 的 Check-in Time 被访问时自动发送确认邮件。直觉上,Frame 非常像面向对象编程中的类(Class):Frame 是类,Slot 是成员变量,Filler 是值,继承也和 OOP 继承一样。考试考法:给你一个场景,让你构建一个 Frame 结构;或者给出一个不完整的 Frame,问 AI 会用什么默认值或继承规则来填充。易错:不要忘记过程附件这个功能,它是 Frame 区别于简单数据结构的重要特性。

这一页讲的是框架推理 (Frame-Based Reasoning)。重点包括默认值 (Default Values) 和继承 (Inheritance)。
这一页讲的是框架推理 (Frame-Based Reasoning),它通过使用默认值 (Default Values)、继承 (Inheritance) 和关系 (Relationships) 来帮助 AI 推断缺失的知识。第一部分是默认值,当框架中的某个槽位 (Slot) 没有明确值时,AI 可以使用预设的默认值。例如,对于框架 Dog,如果槽位 Has legs 没有值,AI 会推断默认值为 4,表示狗通常有四条腿。第二部分是继承,框架可以从更高层级的框架继承属性,这类似于面向对象编程中的继承机制。例如,框架 Mammal 的属性 Has Hair 为 True,那么框架 Dog 作为 Mammal 的子框架,也会继承 Has Hair = True。通过这种方式,框架层次结构可以有效地组织和传播知识。
这一页讲的是 Frame-Based Reasoning 的进阶机制,包括槽约束(Slot Constraints)和过程附件(Procedural Attachment),以及 Frame 作为 AI 个人助手的实际例子。槽约束是指某些 Slot 对可填入的值有限制条件,比如「学生」Frame 的「年龄」Slot 要求年龄必须大于 5 岁,这相当于数据库的约束检查,防止无效信息进入知识库。过程附件则更有意思:它让 Frame 具备了动态响应能力,当某个 Slot 被读取或写入时,系统自动触发一段预定义的程序,比如酒店预订 Frame 的「入住时间」被修改时,系统自动发送确认邮件。页面给出的例子是 CS713 课程讲座的 Frame,包含日期、时间、地点、参与者等 Slot,这非常贴近实际的日历系统或会议管理软件的底层数据结构。直觉类比:Frame 的这两个机制(约束 + 过程附件)组合起来,让知识库不再是死的数据存储,而是有「规则」和「行为」的活系统,这正是早期专家系统能做自动推理和触发动作的基础。考试常考:给你一个复杂场景(比如医院病历系统),让你识别哪些 Slot 需要约束、哪些需要过程附件,以及继承结构该怎么设计。易错:过程附件不是规则系统的 IF-THEN 规则,两者都能触发动作,但规则系统是基于条件匹配,而过程附件是基于 Slot 的访问事件。

这一页讲的是框架推理中的槽位约束与条件,以及程序附加机制。主要内容包括槽位的有效值限制和触发动作规则,并通过一个AI助理的例子说明应用。
这一页讲的是框架推理(Frame-Based Reasoning)中的两个重要机制:槽位约束与条件(Slot Constraints & Conditions)和程序附加(Procedural Attachment)。槽位约束指的是某些槽位对其值有具体限制,例如学生框架中的年龄槽位要求值必须大于5岁。程序附加则是指某些槽位在被访问时会触发特定动作,例如酒店预订框架中的入住时间槽位可以触发发送确认邮件的动作。页面还通过一个AI助理的例子展示了框架的实际应用:讲座框架(Lecture)包含日期、时间、地点和参与者等槽位,其中日期为每周一,时间为中午12点,地点为BLT100/106-100,参与者为CS713课程的学生。这张表格展示了框架如何组织信息,并通过槽位和填充值(Filler)实现结构化数据管理,方便进一步处理和推理。

这一页讲的是知识表示中的框架 (Frames) 的优势,包括结构化组织、继承与默认推理、程序性知识以及易于更新与修改。
这一页讲的是知识表示中的框架 (Frames) 的优势。框架通过 slot-filler 结构将相关知识组织起来,使得信息检索更加高效,例如“餐厅”框架包含名称、位置、菜单和营业时间等信息。第二个优势是继承与默认推理 (Inheritance and Default Reasoning),即 AI 可以利用默认值和层次继承来推断缺失信息,例如“狗”框架没有指定腿的数量时,可以从“哺乳动物”框架继承默认值“4”。第三个优势是程序性知识 (Procedural Knowledge),框架中的 slot 可以触发动作,例如“酒店预订”框架在预订完成时触发电子邮件确认。最后,框架易于动态更新与修改 (Easy to Update & Modify),例如 AI 助手可以在时间变化时更新“讲座”框架。这些特点使框架在知识表示中非常实用,既能高效组织信息,又能支持复杂的推理和动态调整。

这一页讲的是知识表示中框架(Frame)的弱点,包括结构僵化、处理不确定性差、难以扩展以及逻辑推理能力有限。
这一页讲的是知识表示中框架(Frame)的弱点。首先,框架的结构僵化(Rigid Structure & Limited Flexibility),它适合处理预定义的知识,但难以应对模糊或新颖的情况,例如一个预定义的“车辆”框架可能无法涵盖未来的自动驾驶汽车。其次,框架对不确定性的处理较差(Poor Handling of Uncertainty),通常假设知识是完整的,难以处理概率信息,例如“天气”框架可能无法准确表示70%下雨的概率。第三,框架难以扩展到大型知识库(Hard to Scale for Large Knowledge Bases),随着实体和槽位数量增加,维护变得困难,例如一个包含成千上万个框架的医疗系统可能会变得复杂且难以管理。最后,框架的逻辑推理能力有限(Limited Logical Reasoning),与符号逻辑不同,框架不能进行深层次的逻辑推理,例如虽然框架可以存储“所有鸟类都会飞”,但无法自动推断出企鹅是例外。这些弱点限制了框架在复杂和动态场景中的应用。

这一页讲的是基于框架(Frame-Based Reasoning)的医疗诊断应用。重点包括患者信息框架和疾病信息框架的匹配,以及如何利用症状和历史信息进行推理。
这一页讲的是如何利用框架(Frame-Based Reasoning)进行医疗诊断。场景描述中,一个 AI 医疗助手通过框架管理患者的医疗记录并根据症状和病史建议可能的诊断。患者 Alice 报告了发烧和头痛的症状,AI 系统通过两个框架——患者框架(Patient Frame)和疾病框架(Malaria Frame)进行分析。患者框架记录了 Alice 的年龄(25岁)、症状(发烧和头痛)、家族病史(无)、近期旅行(两周前去过热带地区)以及疫苗接种历史(无近期旅行疫苗)。疾病框架则描述了疟疾的常见症状(发烧、头痛、寒战)、传播风险(在热带地区高)以及预防措施(疫苗接种)。通过对比两个框架,AI 可以推断 Alice 的症状可能与疟疾相关,因为她的症状和旅行历史与疟疾的传播风险和症状匹配。这种方法展示了框架推理如何有效整合结构化信息进行诊断。

这一页讲的是基于框架推理的练习,通过患者信息和疾病特征匹配来推断诊断原因。
这一页讲的是基于框架推理(Frame-Based Reasoning)的练习,重点是通过对患者信息和疾病特征的匹配来推断可能的诊断原因。左侧表格描述了患者 Alice 的具体信息,包括年龄(25岁)、症状(发烧、头痛)、家族病史(无)、近期旅行(2周前去过热带地区)以及疫苗接种记录(无近期疫苗接种)。右侧表格则列出了疟疾(Malaria)的相关特征:常见症状(发烧、头痛、寒战)、传播风险(热带地区高风险)以及预防措施(疫苗接种)。通过对比可以发现,Alice 的症状和旅行经历与疟疾的特征高度吻合,因此最可能的原因是选项 D:Alice 最近去了高风险地区并表现出匹配的症状。这种基于框架的推理方法能够帮助 AI 系统快速筛选可能的诊断,尤其是在处理复杂数据时非常高效。

这一页讲的是基于框架推理的练习,通过患者信息与疾病特征匹配,分析疟疾诊断的可能性。
这一页讲的是基于框架推理(Frame-Based Reasoning)的应用,通过患者信息与疾病特征框架的匹配,推导疟疾(Malaria)作为潜在诊断的可能性。左侧表格是患者 Alice 的信息框架,包括年龄(Age: 25)、症状(Symptoms: 发烧和头痛)、家族病史(Family History: 无)、近期旅行史(Recent Travel: 两周前去过热带地区)和疫苗接种史(Vaccination History: 无疟疾疫苗接种)。右侧表格是疟疾的疾病框架,列出常见症状(Common Symptoms: 发烧、头痛、寒战)、传播风险(Transmission Risk: 热带地区高风险)和预防措施(Prevention: 疟疾疫苗接种)。问题问 AI 为什么认为疟疾是潜在诊断,答案是选项 D:Alice 有疟疾的关键症状(发烧和头痛),她两周前去过疟疾高风险地区(符合潜伏期),且没有接种疟疾疫苗,这增加了感染的可能性。这一练习展示了如何通过框架推理将患者信息与疾病特征关联起来,得出合理的诊断结论。

这一页讲的是知识表示(Knowledge Representation)的主要内容,包括六个关键主题。
这一页讲的是知识表示(Knowledge Representation),列出了六个关键主题:1. 知识表示简介(Introduction to Knowledge Representation),介绍知识表示的基本概念和重要性;2. 符号逻辑在知识表示中的应用(Symbolic Logic in Knowledge Representation),讨论如何用逻辑表达知识;3. 语义网络(Semantic Networks in Knowledge Representation),强调知识的图形化表示及其关系;4. 框架(Frames in Knowledge Representation),一种结构化的知识表示方法;5. 基于规则的系统(Rule-Based System in Knowledge Representation),重点是通过规则推理来处理知识;6. 知识图谱(Knowledge Graphs in Knowledge Representation),展示知识的图形化连接及其应用。这些主题涵盖了知识表示的基本理论和应用领域,为后续学习打下基础。右侧的词云图强调了知识表示的核心概念,如“representation”、“logic”和“systems”。

这一页讲的是基于规则的系统(Rule-Based System, RBS)在知识表示中的应用。重点包括其结构为 IF-THEN 规则、用于明确决策的特点,以及在诊断和自动化决策中的应用。
这一页讲的是基于规则的系统(Rule-Based System, RBS)在人工智能中的知识表示。RBS 通过一组 IF-THEN 规则来表示知识,当满足特定条件时触发相应的动作或结论。这种系统的核心是明确的决策过程,与框架(Frames)或语义网络(Semantic Networks)不同。其结构是:IF(条件)→ THEN(动作或结论),AI 根据事实检查并应用合适的规则。幻灯片中的表格列出了三个规则:R1 表示“发烧和咳嗽”可能诊断为流感;R2 表示“发烧、关节痛和去过热带地区”可能诊断为登革热;R3 表示“咳嗽和呼吸困难”可能诊断为肺炎。通过推理,若患者同时具备发烧、咳嗽、关节痛和最近旅行的条件,则可能诊断为流感或登革热。这种系统广泛应用于专家系统、诊断、欺诈检测和自动化决策等领域,因其能够快速处理明确的规则并得出结论。
这一页讲的是规则系统(Rule-Based System, RBS)的核心结构:IF-THEN 规则以及推理引擎的工作方式。规则系统把知识编码成一组「如果条件满足则得出结论」的规则,形式是 IF (Condition) THEN (Action/Conclusion)。系统维护一个事实库(Working Memory),推理引擎反复扫描所有规则,找到条件与当前事实匹配的规则,触发它,把结论加入事实库,再继续扫描,直到没有新规则被触发为止,这个过程叫前向链接(Forward Chaining)。页面上的例子是医疗诊断规则:R1 说「如果发烧且咳嗽,则可能是流感」,R2 说「如果发烧且关节痛且去过热带,则可能是登革热」,R3 说「如果咳嗽且呼吸困难,则可能是肺炎」。当患者同时有发烧、咳嗽、关节痛、最近旅行这四个事实时,R1 和 R2 都被触发,AI 同时推出「可能是流感」和「可能是登革热」两个结论。这正是 MYCIN 专家系统的工作原理——MYCIN 是 713 课程的高频考点,它就是用规则系统做血液感染诊断的。规则系统的最大优势是透明可解释,每一步推理都有明确的规则依据;最大弱点是规则数量爆炸后难以维护,且无法处理规则库之外的新情况。考试常见题型:给出规则库和事实,让你手动执行推理,写出触发了哪些规则、得出了哪些结论。易错:注意一个规则被触发后产生的结论会成为新事实,可能再次触发其他规则,要做完整的链式推理,不能只看第一轮。

这一页讲的是基于规则的系统在知识表示中的优势,包括透明性、易于实现和无需大量训练数据。
这一页讲的是基于规则的系统(Rule-Based Systems)的优势。首先,透明性和可解释性(Transparent and Explainable)是其主要特点。每个决策都基于清晰且人类可读的 IF-THEN 规则,例如 AI 医生根据预定义规则进行诊断,使其推理过程对医生来说易于理解。其次,它在定义明确的问题中易于实现(Easy to Implement for Well-Defined Problems),尤其是在结构化领域中,例如欺诈检测系统可以通过规则“如果交易金额大于 10,000 且来自外国,则标记为可疑”来有效工作。最后,基于规则的系统无需大量训练数据(Works Without Large Training Data),与机器学习(ML)不同,它不需要庞大的数据集。例如,法律 AI 助理可以直接应用 IF-THEN 逻辑分析合同条款,而无需事先训练。这些优势使得基于规则的系统在特定领域中非常实用,特别是当规则明确且数据有限时。

这一页讲的是基于规则的系统在知识表示中的弱点,包括扩展性差、适应性弱和依赖专家知识。
这一页讲的是基于规则的系统(Rule-Based Systems)在知识表示中的弱点。首先,扩展性差(Hard to Scale with Complex Knowledge),随着规则数量增加,管理大量的 IF-THEN 规则变得困难,例如税务 AI 需要处理数千条税法规则,更新和维护非常复杂。其次,适应性弱(Poor Adaptability to New Situations),基于规则的系统无法超出预设规则进行泛化,例如一个 AI 聊天机器人可能无法处理用户提出的意外问题。最后,依赖专家知识(Requires Expert Knowledge to Define Rules),规则需要由领域专家手工编写,例如法律 AI 需要律师编写大量规则。这些弱点限制了基于规则系统在复杂和动态环境中的应用。

这一页讲的是基于规则的火灾检测系统,使用传感器数据触发行动。关键点包括规则条件与当前传感器数据的匹配,以及系统采取的行动。
这一页讲的是基于规则的 AI 系统在智能建筑中的火灾检测应用。通过 IF-THEN 规则,系统根据传感器数据触发相应的警报或行动。表格列出了四条规则:R1 触发火警的条件是温度超过 60°C 且检测到烟雾;R2 触发紧急疏散的条件是温度超过 80°C;R3 在一氧化碳超标时通知建筑管理员;R4 在喷淋系统激活且检测到烟雾时确认火灾。当前传感器数据显示温度为 85°C,检测到烟雾,一氧化碳水平安全,喷淋系统未激活。根据这些数据,R1 和 R2 的条件满足,因此系统会触发火警并启动紧急疏散。选项中正确答案是 A,即同时触发火警和紧急疏散。这种规则系统的重要性在于能快速响应危险情况,保护人员安全并减少损失。

这一页讲的是基于规则的系统在火灾场景中的应用。主要涉及触发火警和紧急疏散的条件。
这一页讲的是基于规则的系统在火灾场景中的应用,具体分析了不同规则(R1-R4)如何影响AI的决策。R1规则表示当温度超过60°C且检测到烟雾时,触发火警(Fire Alarm);R2规则表示当温度超过80°C时,触发紧急疏散(Emergency Evacuation)。R3规则未触发,因为一氧化碳浓度处于安全水平;R4规则也未触发,因为洒水器未激活,AI无法确认是否存在活跃火灾。最终AI采取的行动是根据R1触发火警,根据R2触发紧急疏散。这些规则展示了基于条件逻辑的决策过程,确保火灾场景下的安全响应。举例来说,如果某建筑内温度达到85°C且有烟雾,系统会同时触发火警和疏散警报,以最大化人员安全。

这一页讲的是知识表示(Knowledge Representation)的学习内容,包括六个主要主题。
这一页讲的是知识表示(Knowledge Representation)的学习内容,列出了六个主要主题:1. 知识表示的介绍(Introduction to Knowledge Representation),即理解知识表示的基本概念和重要性;2. 知识表示中的符号逻辑(Symbolic Logic in Knowledge Representation),强调逻辑推理在知识表示中的应用;3. 语义网络(Semantic Networks in Knowledge Representation),通过图结构表达知识及其关系;4. 框架(Frames in Knowledge Representation),用结构化方式表示对象和属性;5. 基于规则的系统(Rule-Based System in Knowledge Representation),通过规则驱动推理;6. 知识图谱(Knowledge Graphs in Knowledge Representation),以图形化方式连接和组织知识。页面右侧的词云图展示了与知识表示相关的关键词,强调其核心概念和应用领域。这六个主题构成了知识表示的核心内容,帮助理解如何有效地组织和处理知识,支持人工智能中的推理和决策。

这一页讲的是知识图谱 (Knowledge Graph) 的定义及其组成部分。主要包括知识图谱如何通过节点 (nodes) 和边 (edges) 表示实体与关系,以及它的三个核心组件:节点、边和属性。
这一页讲的是知识图谱 (Knowledge Graph) 在知识表示中的作用及其组成部分。知识图谱是一种基于图的表示方法,它通过连接实体 (nodes) 和关系 (edges) 来组织信息。与传统的框架或基于规则的系统不同,知识图谱具有以下特点:它存储结构化知识(包括事实、概念和关系),能够帮助人工智能从已知关系推断新的连接,并提供一种可扩展且灵活的方式来组织信息。知识图谱的核心组件包括:节点 (Nodes),表示实体或主题,例如人、地点或物品;边 (Edges),表示实体之间的关系或谓词;属性 (Properties),用于描述实体或关系的特性。右侧的图展示了一个知识图谱的可视化示例,其中节点代表实体,边表示连接它们的关系。这种图形结构有助于更直观地理解复杂的知识网络,例如在推荐系统或语义搜索中的应用。

这一页讲的是知识图谱在知识表示中的应用。主要内容包括 RDF 三元组 (Subject, Predicate, Object) 的结构、节点和边的关系,以及推理的过程。
这一页讲的是知识图谱 (Knowledge Graphs) 在知识表示中的应用。知识图谱通常使用 RDF 三元组 (Subject, Predicate, Object) 来描述实体之间的关系,也可以理解为节点 (Node) 和边 (Edge) 的连接关系。例如表格展示了实体 (Entity) 与关系 (Relation) 的具体例子:Albert Einstein 与 Germany 的关系是 Born In;Albert Einstein 与 Theory of Relativity 的关系是 Discovered;Theory of Relativity 与 Physics 的关系是 Related To;Albert Einstein 与 Princeton University 的关系是 Worked At。这些三元组构成了知识图谱的基础结构。右侧的图示展示了这些关系的可视化网络结构。通过推理 (Inference),如果系统知道「Theory of Relativity 与 Physics 有关」以及「Einstein 发现了 Theory of Relativity」,那么系统可以进一步推断出「Einstein 对 Physics 有贡献」。这种推理能力使得知识图谱在人工智能中非常重要,能够帮助系统理解复杂的知识关系并生成新的结论。
这一页讲的是知识图谱(Knowledge Graph)的核心数据结构:RDF 三元组(Triple),以及如何用它来表示和推理知识。知识图谱用「主体 Subject、谓词 Predicate、客体 Object」这三元组格式来存储每一条事实,也叫 Subject-Predicate-Object 或者 Node-Edge-Node。比如「爱因斯坦 出生于 德国」「爱因斯坦 发现了 相对论」「相对论 相关于 物理学」「爱因斯坦 工作于 普林斯顿大学」,四条三元组就能构成一个关于爱因斯坦的迷你知识图谱。RDF 全称 Resource Description Framework,是万维网联盟(W3C)制定的标准格式,是现代知识图谱(Google Knowledge Graph、Wikidata 等)的通用底层格式。知识图谱之所以强大,是因为可以做传递性推理(Transitive Inference):已知「爱因斯坦发现相对论」加上「相对论属于物理学」,AI 可以推导出「爱因斯坦对物理学有贡献」,这条关系在图里并不直接存在,是通过路径遍历推导出来的。知识图谱相比语义网络更大规模、更标准化,但本质都是图结构;相比规则系统,知识图谱侧重事实存储和实体关系,规则系统侧重条件-动作推理。考试常见考法:给你一张知识图谱的三元组表格,问能推导出什么新关系;或者给你一个自然语言事实,让你写成 RDF 三元组。易错:三元组里谓词的方向很重要,比如「A 影响了 B」和「B 被 A 影响」是同一事实但方向不同,遍历图路径时要注意有向边。

这一页讲的是知识图谱中的推理应用,包括传递推理、关系扩展、实体消歧和问答功能。
这一页讲的是知识图谱(Knowledge Graphs)在知识表示中的推理应用。知识图谱通过分析现有关系帮助 AI 推导新的事实。主要有四种方式:第一是传递推理(Transitive Inference),例如“爱因斯坦发现了相对论,相对论属于物理学”推导出“爱因斯坦贡献了物理学”。第二是关系扩展(Relationship Expansion),用于识别隐藏连接,例如两位讲师共同参与课程可以推导出合作关系。第三是实体消歧(Entity Disambiguation),帮助区分同名实体,例如“苹果公司”和“苹果水果”。第四是问答功能(Question Answering),通过图谱关系检索结构化答案,例如“谁发明了电话?”可以推导出“亚历山大·格拉汉姆·贝尔”。这些推理方式提升了 AI 的知识处理能力,尤其在复杂数据环境中具有重要意义。
这一页讲的是知识图谱的四种核心推理类型,这是考试最可能直接考的知识点之一。第一种是传递推理(Transitive Inference),格式是 A 推 B、B 推 C,可以得出 A 推 C。例子:爱因斯坦发现相对论,相对论属于物理学,所以爱因斯坦对物理学有贡献。第二种是关系扩展(Relationship Expansion),发现图中隐藏的间接连接,比如两位研究者共同贡献了同一门课程,AI 可以推断他们之间有协作关系。第三种是实体消歧(Entity Disambiguation),帮助 AI 区分同名实体,比如「Apple」这个词在知识图谱里对应两个不同的节点:Apple 公司和苹果水果,通过上下文中的关联实体来确定具体是哪一个。第四种是问答(Question Answering),通过遍历图结构回答自然语言问题,比如「谁发明了电话?」可以直接在图里找到 Alexander Graham Bell 这个节点。这四种推理能力是知识图谱作为 AI 知识库的核心价值所在。直觉上,知识图谱推理就是「在图里沿着边走路」,能走几步就能推多深。考试常见题型:给你一个知识图谱,列举具体推理路径,写出结论。易错:实体消歧这个功能容易被忽视,但它是知识图谱应用于搜索引擎(比如 Google)的关键能力,考试可能会结合 Google Knowledge Graph 的实际例子来考。

这一页讲的是知识图谱 (Knowledge Graph, KG) 的优势,包括结构化与可解释性、推理与知识发现、大规模扩展性、多领域知识整合等。
这一页讲的是知识图谱 (Knowledge Graph, KG) 在知识表示中的优势。首先,知识图谱具有高度结构化与可解释性 (Highly Structured & Interpretable),相比非结构化文本,知识图谱能够清晰地定义实体之间的关系,例如 Google 的知识图谱会以结构化方式组织人物、地点和事实。其次,它支持推理与知识发现 (Enables Inference & Knowledge Discovery),可以基于已知关系推断缺失的知识,例如通过科学家研究的理论预测潜在的合作关系。第三,大规模知识表示的可扩展性 (Scalable for Large-Scale Knowledge Representation) 使知识图谱能够处理数百万条事实和关系,例如 Siri 和 Alexa 等 AI 助手实时检索结构化知识。最后,知识图谱支持多领域知识整合 (Supports Multi-Domain Knowledge Integration),将医疗、科学、商业和通用知识整合到一个系统中,例如医疗 AI 可以链接症状、疾病、治疗和药物以进行诊断。这些特点使知识图谱成为强大的知识表示工具,广泛应用于 AI 和数据处理领域。

这一页讲的是知识图谱 (Knowledge Graphs) 的弱点,包括信息不完整和维护复杂性。弱点会影响 AI 的预测准确性,并需要持续更新以保持图谱的有效性。
这一页讲的是知识图谱 (Knowledge Graphs) 在知识表示中的弱点。首先是信息不完整和数据稀疏性 (Incomplete Knowledge & Data Sparsity)。如果知识图谱缺乏某些领域的数据,例如关于罕见疾病的信息,AI 就无法进行准确的推断或预测。这说明知识图谱的覆盖范围直接影响 AI 的表现。其次是高维护成本和复杂性 (High Maintenance & Complexity)。知识图谱需要不断更新以添加新的实体和关系,例如为 AI 聊天机器人 (ChatGPT) 更新知识图谱时,需要持续进行事实核查。这意味着知识图谱的动态性要求较高,维护工作量大。这些弱点表明尽管知识图谱在知识表示中具有重要作用,但其应用需要克服数据质量和维护成本的挑战。页面还提供了额外的学习资源链接,可帮助深入了解知识图谱的构建与应用。

这一页讲的是知识图谱的应用,通过关系推理回答问题。主要包括节点间关系表和问题解析。
这一页讲的是知识图谱(Knowledge Graph)的应用场景,重点是如何通过关系推理来回答问题。知识图谱用于组织历史人物、科学发现及其影响,表格列出了节点(Entity)之间的已知关系(Relation)。表格中展示了几个关键关系,例如 Isaac Newton 发现了万有引力定律(Law of Gravity),万有引力定律与物理学(Physics)相关,Albert Einstein 对物理学有贡献并发展了相对论(Theory of Relativity),相对论与重力(Gravity)相关且受到万有引力定律的影响。通过这些关系可以推断出 Isaac Newton 的发现间接影响了 Albert Einstein 的研究。问题部分询问 Isaac Newton 的发现是否影响了 Einstein,选项 C 是正确答案,因为 Newton 的万有引力定律与 Einstein 的相对论通过重力产生了联系。这一页强调了知识图谱在关系推理中的实用性,同时展示了如何通过关系链条进行逻辑推断。

这一页讲的是知识图谱的推理能力,重点是通过遍历图谱推导出间接关系。
这一页讲的是知识图谱(Knowledge Graphs)的推理能力,特别是如何通过遍历图谱(traversing the graph)推导出间接关系。幻灯片中解释了虽然图谱中没有直接连接牛顿(Isaac Newton)和爱因斯坦(Albert Einstein),但可以通过节点和边的关系推理出爱因斯坦的相对论(Theory of Relativity)受牛顿的万有引力定律(Law of Gravity)影响。推理过程如下:牛顿发现了万有引力定律,万有引力定律影响了相对论,而爱因斯坦发展了相对论,因此可以推导出爱因斯坦的理论间接受到牛顿发现的影响。表格列出了知识图谱中的节点(Entity)和边(Relation),例如牛顿与“发现”(Discovered)连接到万有引力定律,万有引力定律与“影响”(Influenced By)连接到相对论。这说明知识图谱可以通过关系链条推理复杂的因果关系,展示了其在人工智能推理中的重要性。

这一页讲的是知识表示(Knowledge Representation, KR)方法之间的关系。重点包括这些方法是不同的表示范式(paradigms),而非彼此的子类型。它们支持不同的推理方式。
这一页讲的是知识表示(Knowledge Representation, KR)方法之间的关系。主要内容指出,符号逻辑(Symbolic Logic)、语义网络(Semantic Networks)、框架(Frames)、基于规则的系统(Rule-Based Systems)和知识图谱(Knowledge Graphs)是知识表示的不同方法,而不是彼此的子类型。这些方法支持不同的推理方式。幻灯片提供了一种简单的分类方式:语义网络和知识图谱都使用图结构;框架通过槽-填充(slot-filler)结构组织知识;基于规则的系统使用“如果-那么”(IF-THEN)规则进行决策;符号逻辑使用正式语句进行精确推理。图表展示了知识表示的整体框架,分为逻辑为基础的、图为基础的和结构化/基于规则的三大类。结论是这些方法是不同的知识表示范式,而不是知识图谱的不同类型。这种分类有助于理解这些方法的特点及其适用场景,例如符号逻辑适合精确推理,而知识图谱适合处理图形化关系。
这一页讲的是五种知识表示方法的横向对比,这是整讲最重要的综合总结页,几乎必考。五种方法并列:符号逻辑(Symbolic Logic)、语义网络(Semantic Networks)、框架(Frames)、规则系统(Rule-Based Systems)和知识图谱(Knowledge Graphs)。关键区分:语义网络和知识图谱都是图结构,但语义网络是早期的、小规模的、非标准化的图式表示;知识图谱是现代的、大规模的、通常用 RDF 三元组标准化的表示,两者不是父子关系而是兄弟关系。框架用 Slot-Filler 结构来描述对象的属性,更像数据库的记录;规则系统用 IF-THEN 来编码决策逻辑,最接近人类专家的诊断流程;符号逻辑用形式化语言(尤其是 FOL)来做精确的逻辑推导,表达能力最强但计算最重。表格式对比要记清楚:语义网络的核心例子是「鸟 is-a 动物」;框架的例子是「Frame: 鸟; 翅膀=2; 会飞=是」;知识图谱的例子是三元组 (鸟, is-a, 动物)。这三个形式看起来像是在说同一件事,但结构和推理方式完全不同。考试常见考法:给你一个 AI 应用需求,让你选择最合适的 KR 方法并说明理由;或者给出一种 KR 方法的特征,让你识别是哪种。易错:不要认为这五种方法是同一大类下的不同子类型,它们是完全独立的 KR 范式,各有所长。
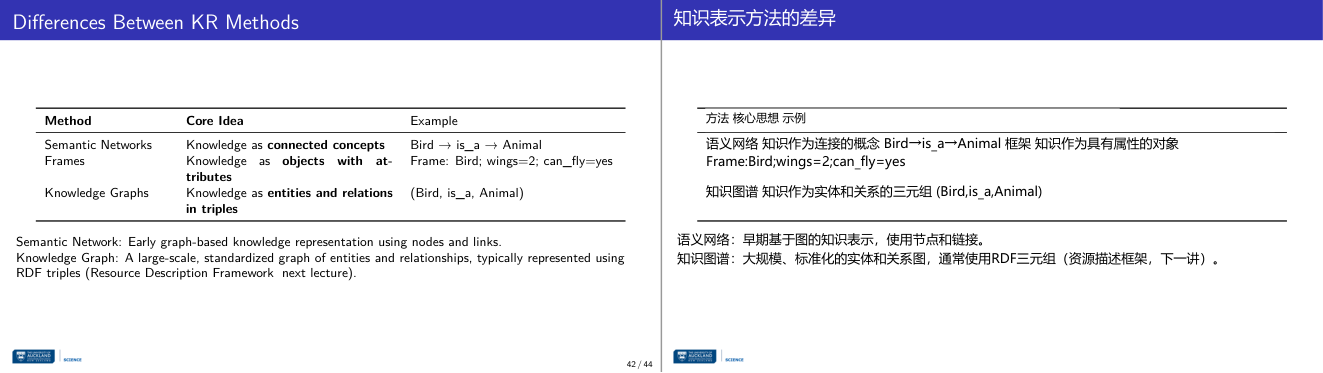
这一页讲的是知识表示(KR)方法的区别,包括语义网络、框架和知识图谱的核心思想及示例。
这一页讲的是知识表示(KR)方法的区别,主要介绍了三种方法的核心思想和示例。第一种方法是语义网络(Semantic Networks),它将知识表示为连接的概念(connected concepts),通过节点和链接构成图结构。例如,鸟(Bird)通过“is_a”关系连接到动物(Animal)。第二种方法是框架(Frames),它将知识表示为具有属性的对象(objects with attributes)。例如,鸟的框架可以包括属性“翅膀数量=2”和“能飞=是”。第三种方法是知识图谱(Knowledge Graphs),它将知识表示为三元组(triples),即实体和关系的组合,例如(Bird, is_a, Animal)。幻灯片还提到语义网络是早期的图形化知识表示方法,而知识图谱是一种大规模、标准化的图结构,通常使用RDF三元组(Resource Description Framework)表示,这将在后续课程中进一步讲解。这些方法在知识管理和人工智能领域中具有重要意义,帮助我们更系统地组织和推理复杂信息。
这一页讲的是五种知识表示方法的核心概念差异对比表,是全讲的精华总结,需要能背下来并举例说明。这张对比表列出了每种方法的 Core Idea 和 Example:语义网络是「知识作为相互连接的概念」,例子 Bird is-a Animal;框架是「知识作为带属性的对象」,例子是 Frame: Bird, wings=2, can_fly=yes;知识图谱是「知识作为实体与关系的三元组」,例子是 (Bird, is-a, Animal)。注意一个重要的区分:语义网络是早期的图式知识表示,使用节点和链接;知识图谱是大规模、标准化的图,通常用 RDF(Resource Description Framework)三元组来表示。两者的例子虽然看起来相似(都是「鸟是动物」),但知识图谱的 RDF 三元组格式是机器可读的 W3C 标准,可以在互联网上跨系统共享,而语义网络没有这种标准化。为什么要区分这些方法?因为在考试和实际工程中,选错 KR 方法会导致系统设计失败:需要快速决策用规则系统,需要继承推理用框架或语义网络,需要大规模实体关系用知识图谱,需要精确逻辑推导用符号逻辑。考试最高频的考法是让你分析某个真实 AI 系统(比如 IBM Watson、Google Search、MYCIN)用的是哪种 KR 方法,并解释为什么。易错:IBM Watson 综合使用了多种 KR 方法,不能简单归为某一种;Google Search 后台主要是知识图谱而不是规则系统。

这一页讲的是知识表示(Knowledge Representation, KR)的总结。主要介绍了 KR 的作用、五种方法及其特点,并强调没有单一最佳方法。
这一页讲的是知识表示(Knowledge Representation, KR)的总结。KR 的主要作用是帮助 AI 系统存储(store)、组织(organize)、检索(retrieve)和推理(reason)知识。不同的 KR 方法适用于不同任务和应用场景。页面介绍了五种主要的 KR 方法:1. Symbolic Logic(符号逻辑)通过形式化逻辑表达知识,适合精确推理;2. Semantic Networks(语义网络)用图中的节点和边表示概念及关系;3. Frames(框架)以插槽填充结构组织知识,描述实体及其属性;4. Rule-Based Systems(基于规则的系统)使用 IF-THEN 规则进行显式决策和推理;5. Knowledge Graphs(知识图谱)连接实体、关系和属性,具有可扩展性。关键结论是没有单一最佳 KR 方法,不同方法在表示、推理、扩展性和可解释性方面各有优势。在实际应用中,AI 系统常结合多种 KR 方法解决复杂问题。

这一页讲的是总结与问答环节。感谢听众并开放提问。
这一页讲的是总结与问答环节。幻灯片以“Thank you! Q&A”为主要内容,表达了演讲者对听众的感谢,并邀请大家进行提问。这是演讲或课程结束时的常见做法,旨在与听众互动,解决他们的疑问或进一步探讨相关内容。问答环节通常是深入交流的机会,可以帮助听众更好地理解课程内容,也让演讲者获得反馈。建议在问答环节中积极参与,提出具体问题或分享自己的观点,以促进知识的交流和深化。