第 1 / 56 页

这一页讲的是知识表示 (Knowledge Representation) 在人工智能中的应用,包括专家系统 (Expert Systems)、本体 (Ontologies)、知识图谱 (Knowledge Graphs) 和 RAG。
空格=播放/暂停当前页 · Tab=切换 简短/详细/深入 · 红色「深入」为重点页的深度讲解
这一页讲的是知识表示 (Knowledge Representation) 在人工智能中的应用,包括专家系统 (Expert Systems)、本体 (Ontologies)、知识图谱 (Knowledge Graphs) 和 RAG。
这一页讲的是知识表示 (Knowledge Representation) 在人工智能中的重要内容。知识表示是 AI 的核心领域之一,主要研究如何以结构化的形式存储和使用知识。专家系统 (Expert Systems) 是一种模拟人类专家决策的程序,通常利用规则库和推理引擎。本体 (Ontologies) 是知识表示的重要工具,用于定义概念及其关系,帮助构建语义理解。知识图谱 (Knowledge Graphs) 则是以图的形式组织信息,节点表示实体,边表示关系,广泛应用于搜索引擎和推荐系统。RAG (Retrieval-Augmented Generation) 是一种结合知识检索与生成的方法,能够在生成模型中动态引入外部知识。通过这些技术,AI 系统可以更好地理解和处理复杂问题。

这一页讲的是知识表示的概念及其在 AI 中的重要性,包括知识图谱、专家系统等主题。右侧图展示了从数据到智慧的知识模型。
这一页讲的是知识表示(Knowledge Representation)的回顾及其在人工智能中的应用。首先,知识表示是 AI 理解、存储和处理信息的核心技术。幻灯片列出了几个关键主题,包括专家系统(Expert Systems)、本体论(Ontologies)、知识图谱(Knowledge Graph)以及检索增强生成(Retrieval-Augmented Generation)。右侧的图表展示了一个知识模型,从数据(Data)到信息(Information),再到知识(Knowledge)和智慧(Wisdom)的逐步提升。横轴表示理解程度(Degree of Understanding),纵轴表示连接程度(Degree of Connectedness)。例如,数据是基本的原始信息,通过理解关系可以转化为信息;信息通过理解模式转化为知识;最终,通过理解原则达到智慧。这种模型强调了知识表示在帮助 AI 从简单数据到复杂智慧转化中的重要作用。

这一页讲的是知识表示(Knowledge Representation, KR)的定义与主要方法。重点包括符号逻辑(Symbolic Logic)、语义网络(Semantic Networks)、框架(Frames)、基于规则的系统(Rule-Based Systems)和知识图谱(Knowledge Graphs)。
这一页讲的是知识表示(Knowledge Representation, KR),即人工智能用于存储、检索和处理知识以实现智能推理的方法。KR帮助AI超越原始数据,理解关系(relationships)、规则(rules)和逻辑结构(logical structures)。主要方法包括:符号逻辑(Symbolic Logic),使用数学逻辑如一阶逻辑(First-Order Logic)进行知识表达;语义网络(Semantic Networks),通过概念之间的图状连接表示知识;框架(Frames),类似编程中的对象,用槽位填充结构化信息;基于规则的系统(Rule-Based Systems),使用“如果-那么”(IF-THEN)规则进行决策;知识图谱(Knowledge Graphs),通过实体和关系表示知识,例如谷歌知识图谱。右侧的图展示了知识表示的不同方法及其分类,帮助理解这些方法的应用场景和特点。

这一页讲的是语义网络 (Semantic Networks) 和知识图谱 (Knowledge Graphs) 的区别与联系。语义网络是早期知识表示方法,知识图谱是其现代扩展,使用 RDF 等标准进行大规模知识管理。
这一页讲的是语义网络 (Semantic Networks) 和知识图谱 (Knowledge Graphs) 的区别与联系。语义网络是一种早期的知识表示技术,通过图结构表示概念及其关系,主要用于 AI 推理和概念表示,规模较小且领域特定。知识图谱则是现代工业级知识管理系统,采用三元组 (Subject, Predicate, Object) 表示知识,基于 RDF 和 OWL 等标准,设计用于大规模网络知识库,广泛应用于搜索引擎、推荐系统和 AI 应用。表格对比了两者的起源、性质、表示方法、标准化程度、规模和应用场景。例如:语义网络中“爱因斯坦发现了相对论”可以用图结构表示,而知识图谱则用三元组表示为 (Albert Einstein, discovered, Theory of Relativity)。知识图谱是语义网络的现代扩展,能够更高效地存储和查询结构化知识。
这一页讲的是 Semantic Network(语义网络)和 Knowledge Graph(知识图谱)的对比。两者都是用图结构来表达知识,但时代背景和工程规模截然不同。语义网络诞生于1960-80年代的早期 AI 研究,是一种概念性的知识表示模型,节点是概念,边是关系,规模通常很小、针对特定领域。知识图谱则是2000年代兴起的工业级知识管理系统,核心在于采用 RDF(Resource Description Framework)三元组标准,即「主语-谓语-宾语」(Subject, Predicate, Object) 的格式来存储知识,并依托 OWL 等 Web 标准进行推理,规模可达亿级实体(如 Google Knowledge Graph、Wikidata)。理解它们关系的直觉是:知识图谱是语义网络理念的现代大规模工程实现,就像从手工地图升级到 Google Maps。考试易错点在于:不要混淆两者的「关系表达方式」——语义网络用箭头连接节点(Einstein →discovered→ Theory of Relativity),知识图谱用 RDF 三元组(Albert Einstein, discovered, Theory of Relativity)。另一个易错点是标准化问题:语义网络没有统一标准,而知识图谱基于 RDF/OWL 这些国际标准,这使得不同系统之间的知识可以互联互通。考试常考比较表格中的各维度,要能说出 Origin、Nature、Representation、Standardization、Scale 和 Applications 这六个维度的差异。

这一页讲的是知识表示(KR)对 AI 的重要性。主要内容包括现代 AI 缺乏结构化推理能力,KR 能帮助 AI理解关系、事实和规则,从而提升解释和决策能力。
这一页讲的是知识表示(KR)为什么对 AI 至关重要。首先指出现代 AI 擅长模式识别,但在逻辑推理方面存在不足。AI 需要结构化的知识来理解关系、事实和规则。表格比较了没有 KR 和有 KR 的 AI:没有 KR 的 AI 可以识别猫的图像,但无法解释为什么是猫;有 KR 的 AI 能通过语义网络将猫与“哺乳动物”、“有毛发”、“有胡须”等概念联系起来。没有 KR 的聊天机器人容易犯事实错误,而有 KR 的 AI 能从知识库中提取结构化事实以提高准确性。在医学领域,没有 KR 的 AI 仅基于统计模式建议治疗方案,而有 KR 的 AI 能理解疾病与症状之间的关系用于推理。结论是,KR 能帮助 AI 进行解释、推理并做出更好的决策,而不仅仅是预测模式。

这一页讲的是知识表示(KR)与人工智能(AI)如何协同工作。AI擅长模式识别、数据驱动预测和处理非结构化信息,而KR通过增加逻辑结构提升推理能力、知识结构化和解释性。
这一页讲的是知识表示(KR)与人工智能(AI)如何协同工作。AI,尤其是机器学习(ML)和深度学习(Deep Learning),在以下方面表现出色:第一,模式识别,例如图像和文本;第二,基于数据的预测,例如推荐系统;第三,处理非结构化信息,例如自然语言文本。KR则通过增加逻辑结构来补充AI的能力,包括明确编码规则和关系以改善推理能力,为AI提供结构化知识以支持决策过程,并通过提升透明性来改善AI的可解释性。两者的结合使得AI不仅能够从数据中学习,还能基于明确的规则和结构进行推理。例如,在推荐系统中,AI可以基于用户行为预测偏好,而KR可以提供规则来解释为什么某些推荐更符合逻辑。这种协作提高了系统的智能性和可信度。

这一页讲的是传统人工智能与知识表示(KR)方法。主要内容包括显式规则与符号逻辑的使用,以及四种关键方法:专家系统、基于规则的系统、本体论和信息检索系统。
这一页讲的是传统人工智能与知识表示(KR)方法。在深度学习出现之前,人工智能主要依赖结构化知识,例如显式定义的规则(explicitly defined rules)和符号逻辑(symbolic logic)。这些方法的优点是可解释性强,但在从数据中学习方面存在困难。关键的传统 AI + KR 方法包括:1. 专家系统(Expert Systems),基于规则的人工智能,依赖人类专家知识进行训练;2. 基于规则的系统(Rule-Based Systems),使用 IF-THEN 规则进行决策;3. 本体论(Ontologies),定义机器可以理解的结构化知识;4. 信息检索系统(Information Retrieval Systems),通过搜索外部知识源获取相关信息,是现代 RAG 的基础。这些方法在传统人工智能中占据重要地位,尤其在早期缺乏大规模数据的情况下。比如专家系统可以用于医疗诊断,通过专家知识库提供建议,而信息检索系统则帮助从文档中找到相关答案。

这一页讲的是知识表示的复习及其在 AI 中的重要性,涵盖专家系统、Ontology、知识图谱和检索增强生成,并展示了知识模型的层次结构。
这一页讲的是知识表示(Knowledge Representation)的复习及其在人工智能中的重要性。主要内容包括专家系统(Expert Systems)、本体论(Ontologies)、知识图谱(Knowledge Graph)和检索增强生成(Retrieval-Augmented Generation)。右侧的图表展示了知识模型的层次结构,从底层的数据(Data)到信息(Information),再到知识(Knowledge)和智慧(Wisdom),分别对应理解关系、模式和原则的递进过程。横轴表示理解程度(Degree of Understanding),纵轴表示连接程度(Degree of Connectedness)。例如,从数据到信息的转化需要理解数据之间的关系,而从知识到智慧则需要更深层次的原则理解。这张幻灯片为后续内容奠定了基础,强调知识表示在 AI 系统中帮助组织和利用信息的关键作用。

这一页讲的是专家系统 (Expert Systems),其定义、关键组成部分和一个经典例子。专家系统通过模仿人类专家,使用 IF-THEN 规则和逻辑推理解决问题,核心组件包括知识库、推理引擎和用户界面。
这一页讲的是专家系统 (Expert Systems),即一种模仿人类专家在特定领域做决策的人工智能系统。专家系统通过使用 IF-THEN 规则和逻辑推理解决问题,主要由知识库 (Knowledge Base) 和推理引擎 (Inference Engine) 构建。知识库存储专家知识,包括事实和规则;推理引擎应用逻辑规则以得出结论;用户界面 (User Interface) 则允许用户输入数据并接收建议。页面还举了一个经典例子 MYCIN,这是1970年代用于医疗诊断的专家系统。它的规则是:如果患者有发热症状且有细菌感染,则推荐抗生素治疗。MYCIN 在诊断细菌感染方面甚至超过了一些医生的表现。这说明专家系统在处理复杂问题时的潜力和重要性。右侧的图示展示了专家系统的工作流程,包括用户输入查询、推理引擎处理逻辑、知识库提供支持,最终生成建议。
这一页讲的是 Expert System(专家系统)的核心概念与结构。专家系统是一种模拟领域专家决策过程的 AI 系统,使用 IF-THEN 规则(条件-结论规则)和逻辑推理来解决专业领域问题。其最关键的两个组件是:一、Knowledge Base(知识库),存储由领域专家提炼出来的规则和事实;二、Inference Engine(推理引擎),负责将规则应用到当前事实上,推导出新结论。以 MYCIN(1970年代)为例,这是医疗领域最著名的专家系统,其规则形如「IF 患者有发烧 AND 细菌感染,THEN 推荐抗生素治疗」,MYCIN 在诊断细菌感染方面甚至超过了部分医生。理解专家系统的直觉:把它想象成一个把专家的思考步骤编码成 if-else 树的程序,规则越多、覆盖越全,系统就越"智能"。考试会考:专家系统的三大组件名称(Knowledge Base、Inference Engine、User Interface);专家系统的局限性(只能处理规则覆盖的情况,无法从数据中学习,知识获取瓶颈即 knowledge acquisition bottleneck);MYCIN 是典型案例必须记住。易错点是把 Knowledge Base 和 Database 混淆——Knowledge Base 存的是规则和逻辑,Database 存的是原始数据。

这一页讲的是银行用专家系统检测欺诈交易的规则。主要包括基于规则的推理方法,列出了五个 IF-THEN 规则用于判断交易是否可疑。
这一页讲的是银行通过专家系统(Expert System)来检测欺诈交易的规则设计,采用基于规则(rule-based reasoning)的推理方法。表格列出了五条 IF-THEN 规则:R1 如果交易金额超过 10,000 美元且发生在外国但用户没有旅行记录,则标记为潜在欺诈(Potential Fraud);R2 如果在不同地点的多笔交易在 5 分钟内发生,则标记为高风险欺诈(High-Risk Fraud);R3 如果用户通过双因素认证(2FA)确认交易,则批准交易;R4 如果交易被标记为欺诈(符合 R1 或 R2),且用户未通过双因素认证,则暂时冻结卡片;R5 如果用户有类似交易的历史记录且在相同地点,则批准交易。这些规则通过条件和结论的逻辑关系帮助系统快速判断交易是否安全,提高了银行的反欺诈能力。例如,如果某用户在短时间内从不同国家进行多笔交易且未通过认证,系统会根据 R2 和 R4 规则暂时冻结其卡片以防止潜在损失。

这一页讲的是专家系统中的欺诈检测案例。主要内容包括规则表、案例细节及问题讨论,重点分析如何判断交易是否可疑及系统应采取的响应。
这一页讲的是专家系统在欺诈检测中的应用。首先,规则表列出了五种条件及对应的系统响应,例如 R1 条件为交易金额超过 $10,000 且发生在用户无旅行记录的外国地点时,系统会标记为潜在欺诈;R3 条件为用户通过双因素认证 (2FA) 确认交易时,系统批准交易。案例中,一个用户尝试在日本进行 $12,500 的交易,但用户无日本旅行记录,且未使用 2FA 确认交易,同时五分钟前在美国纽约发生了另一笔 $100 的交易。用户也无类似交易记录。根据规则表,R1 和 R4 条件可能适用,系统应标记交易为潜在欺诈并暂时冻结用户卡片。问题部分提供了四种可能的响应选项,要求分析哪种最符合规则表的逻辑。通过这个案例可以学习如何利用专家系统规则对复杂情况进行快速判断和决策。

这一页讲的是专家系统在判断潜在欺诈活动时的决策过程。主要包括规则匹配(R1、R2)和用户未通过双因素认证(2FA)的情况,最终决定暂时冻结用户的卡片并通知其可疑活动。
这一页讲的是专家系统在处理潜在欺诈交易时的决策逻辑。首先,规则 R1 匹配:交易金额 $12,500 超过 $10,000,且发生在外国(日本),用户没有旅行记录,因此被标记为潜在欺诈。其次,规则 R2 匹配:在 5 分钟内发生了两笔交易(日本和美国),被标记为高风险欺诈。最后,用户未通过双因素认证(2FA),因此满足规则 R4 的条件,系统最终决定暂时冻结用户的卡片并通知其发生了可疑活动。这一决策流程体现了专家系统在分析交易行为和风险时的逻辑性和自动化能力,有助于降低欺诈风险并保护用户账户安全。
这一页讲的是专家系统推理链的实际应用——银行欺诈检测案例的完整推理过程。这道题展示了专家系统如何通过链式规则推理(chained rule firing)得出最终决策,是理解 Forward Chaining(前向推理)的绝佳例子。推理步骤是:第一步,事实匹配 R1:交易金额1.25万美元超过1万,在境外日本,且无出行记录,三个条件同时满足,触发 R1,得到「标记为潜在欺诈」;第二步,事实匹配 R2:5分钟内在纽约和日本各有一笔交易,不同地点同时出现,触发 R2,得到「标记为高风险欺诈」;第三步,R1 或 R2 已触发,且用户未完成 2FA 验证,触发 R4,最终结论「临时冻结卡片」。这就是 Forward Chaining 的过程:从已知事实出发,不断匹配规则条件,逐步推导出新结论,直到得出最终决策。考试重点:一是能描述 Forward Chaining vs Backward Chaining 的区别(前者从事实推结论,后者从目标倒推需要哪些事实);二是能在给定规则集和事实集的情况下,手工走完推理链,这类题目在713期末非常常见;三是注意规则之间的依赖关系,R4 的触发依赖 R1 或 R2 的结果,这体现了规则之间的 chaining。易错:看到多个规则同时满足时,要判断哪条规则的优先级更高,或者是否所有满足的规则都会执行。

这一页讲的是知识表示的相关内容,包括其重要性、应用领域以及知识模型的层次结构。
这一页讲的是知识表示(Knowledge Representation)的相关内容,重点包括知识表示的回顾、AI为什么需要知识表示、专家系统(Expert Systems)、本体论(Ontologies)、知识图谱(Knowledge Graph)以及检索增强生成(Retrieval-Augmented Generation)。右侧的知识模型图展示了从数据到智慧的层次结构:数据(Data)是基础,通过理解关系形成信息(Information),进一步理解模式形成知识(Knowledge),最终通过理解原则达到智慧(Wisdom)。图中还标注了连接度(Degree of Connectedness)和理解度(Degree of Understanding)的提升方向,说明知识的深化和广度是逐步积累的。这些内容对于理解AI如何处理和利用知识,以及如何构建智能系统至关重要。例如,知识图谱可以帮助AI更好地组织和检索信息,而本体论则定义了领域内的概念和关系,是知识表示的重要工具。
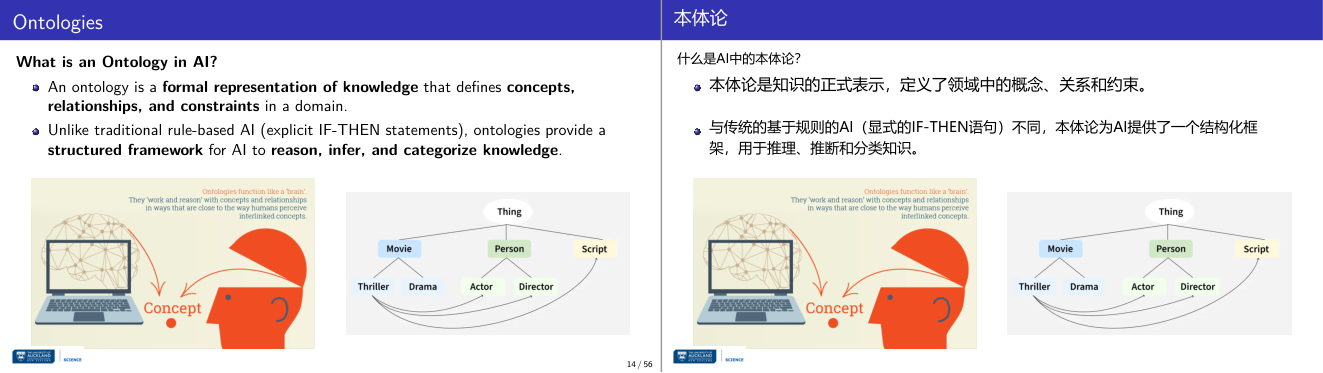
这一页讲的是本体论(Ontology)在人工智能中的定义与作用。重点包括本体论是知识的形式化表示,定义概念、关系和约束,并为 AI 提供推理、归纳和分类的结构化框架。
这一页讲的是本体论(Ontology)在人工智能中的定义与作用。本体论是一种知识的形式化表示,能够定义特定领域中的概念、关系和约束。这与传统基于规则的人工智能(如显式的 IF-THEN 语句)不同,本体论通过结构化框架帮助 AI 进行推理、归纳和分类。左侧图示展示了本体论的功能类似于“大脑”,能够以接近人类感知概念间关系的方式工作和推理。右侧的层级图则展示了一个简单的本体结构,其中“Thing”是顶层概念,下属包括“Movie”、“Person”和“Script”,进一步细分为具体类型如“Thriller”、“Drama”、“Actor”和“Director”。通过这样的层次结构,本体论能够有效地组织和管理知识。例如,在电影推荐系统中,本体论可以帮助系统理解电影类型与演员之间的关系,从而更精准地推荐内容。

这一页讲的是本体论(Ontologies)的关键组成部分,包括概念、实例和关系。概念是实体的类别,实例是具体的数据点,关系是实体或实例之间的连接。
这一页讲的是本体论(Ontologies)的关键组成部分及其定义和作用。第一部分是概念(Concepts/Classes),它指的是实体的类别,例如疾病(Disease)、药物(Medicine)、治疗(Treatment)、患者(Patient)。第二部分是实例(Instances/Individuals),即具体的数据点或概念的具体例子,例如流感(Flu)、COVID-19、阿司匹林(Aspirin)、John Doe。实例可以通过“isA”关系连接到概念,例如流感“是”一种疾病,COVID-19“是”一种疾病。第三部分是关系(Relationships/Properties),它描述了实体或实例之间的连接方式。关系可以分为两种层级:概念关系(entity-level),例如定义哪些连接是允许的;实例关系(point-level),例如实际的事实连接,如“药物治疗疾病”(Medicine treats Disease)或“阿司匹林治疗头痛”(Aspirin treats Headache)。页面还包含一个图示,展示了本体论如何组织对象的实例及其关系,强调本体论不仅是知识表示的结构,还能扩展领域知识。
这一页讲的是 Ontology(本体)在 AI 中的定义及其与规则系统的核心区别。Ontology(注意不是哲学本体论,而是 AI 领域的知识本体)是对某个领域知识的形式化表示,它明确定义了概念(Concepts/Classes)、概念之间的关系(Relationships/Properties)以及约束条件(Constraints)。与传统规则系统(写死的 IF-THEN 规则)不同,本体提供的是一个结构化框架,让 AI 能够在此框架上进行推理、推断和分类。直觉上,可以把 Ontology 理解为一个领域的「词典+语法书」:词典规定了哪些概念存在以及它们的含义,语法书规定了这些概念之间允许有哪些关系和限制。而 Knowledge Graph 是用这本词典和语法书写出来的「具体句子」(事实三元组)。考试常考区分:Ontology 定义了「什么是合法的知识结构」(schema/rules),Knowledge Graph 存储的是「具体的事实实例」(facts)。两者配合使用:Ontology 是 KG 的 schema,KG 是 Ontology 的实例化。易错:不要把 Ontology 单纯理解为分类树(taxonomy),它还包含约束和推理规则,这是比分类树更丰富的表达。

这一页讲的是本体论的关键组件与知识图谱的区别。重点包括约束与规则、推理机制,以及本体论与知识图谱在概念和关系上的差异。
这一页讲的是本体论的关键组件和知识图谱的区别。首先,约束与规则(Constraints & Rules)是本体论中的逻辑限制,用于定义关系的有效性,例如“一个治疗方法必须与至少一种疾病关联”。其次,推理机制(Inference Mechanisms)允许 AI 基于本体论结构推导新的关系,例如如果阿司匹林(Aspirin)是一种止痛药(Pain Reliever),而止痛药可以治疗头痛(Headache),那么阿司匹林可以用来治疗头痛。本体论与知识图谱的区别在于,知识图谱主要表示事实(facts),例如“阿司匹林治疗头痛(Aspirin treats Headache)”,但不明确定义什么是药物或有效关系。而本体论则包含概念、关系和规则,例如定义“只有药物可以治疗疾病”。最后,AI 系统通常通过将本体论(规则/schema)与知识图谱(事实)相结合来实现更复杂的推理能力。这种结合能够帮助系统更好地理解数据之间的逻辑关系,从而支持智能决策。
这一页讲的是 Ontology 的五大核心组件,这是考试必考的结构性知识点。第一个组件是 Concepts/Classes(概念/类),即领域中实体的类别,例如 Disease、Medicine、Treatment、Patient。第二个是 Instances/Individuals(实例/个体),即具体的数据点,例如 Flu 是 Disease 的实例,Aspirin 是 Medicine 的实例,关系表达为 Flu isA Disease。第三个是 Relationships/Properties(关系/属性),分两层:概念级关系(entity-level,定义哪种连接是允许的,如 Medicine treats Disease)和实例级关系(instance-level,具体事实,如 Aspirin treats Headache)。第四个是 Constraints(约束),对关系施加逻辑限制,如「一个 Treatment 必须关联至少一个 Disease」。第五个是 Inference Mechanisms(推理机制),基于本体结构推导新知识,如「Aspirin isA Pain Reliever,Pain Reliever treats Headache,因此 Aspirin treats Headache」。这个推理过程叫做 subsumption reasoning(归纳推理)。考试易错点:分清概念级关系和实例级关系——前者是 schema 层面(Medicine treats Disease,说的是类别之间的关系),后者是 data 层面(Aspirin treats Headache,说的是具体实例之间的事实)。另一个常考点是推理机制,要能写出简单的三段论式推导步骤。
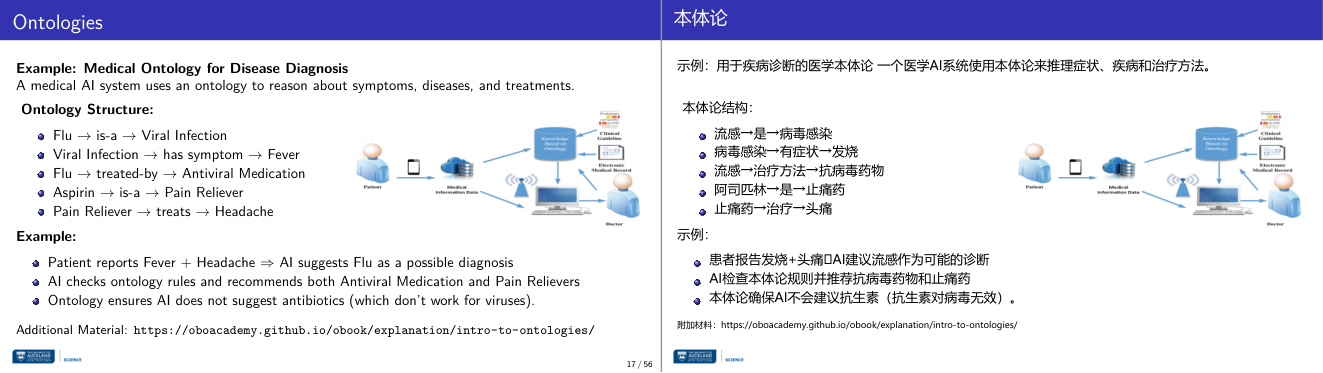
这一页讲的是医学领域的本体论(Ontology)及其在疾病诊断中的应用。重点包括本体结构如何表示疾病、症状和治疗关系,以及通过本体论辅助 AI 做出准确诊断和推荐治疗方案。
这一页讲的是医学本体论(Ontology for Disease Diagnosis),其目的是帮助 AI 系统通过逻辑推理理解疾病、症状和治疗之间的关系。本体结构的例子包括:流感(Flu)属于病毒感染(Viral Infection),病毒感染的症状是发烧(Fever),流感可以通过抗病毒药物(Antiviral Medication)治疗;阿司匹林(Aspirin)属于止痛药(Pain Reliever),止痛药可以治疗头痛(Headache)。这些关系通过本体论明确定义,使得 AI 能够基于患者报告的症状(如发烧和头痛)推断可能的疾病(如流感),并推荐相应的治疗方案(如抗病毒药物和止痛药)。此外,本体论还确保 AI 不会推荐不适合病毒感染的抗生素(antibiotics)。右侧的流程图展示了患者、医疗信息数据、知识库和医生之间的交互过程,说明本体论在实际应用中的信息流。通过这样的结构化知识,AI 能够提高诊断的准确性和治疗建议的合理性。

这一页讲的是公司用本体论(ontology)管理员工、项目和角色的知识结构。关键点包括定义概念(员工、项目、角色)、关系(工作于、拥有角色、负责项目)及实例(员工与项目的具体关联)。
这一页讲的是公司如何通过本体论(ontology)来组织员工、项目和角色的知识结构。首先定义了三个主要概念(classes):员工(Employee,包括Alice、Bob、Charlie)、项目(Project,包括Project X和Project Y)以及角色(Role,包括Manager和Developer)。接着定义了关系(properties):员工可以“工作于”(works on)某个项目、拥有某个角色(has a role),而角色可以“负责”(is responsible for)某个项目。实例部分具体展示了这些关系,例如Alice是Manager并负责Project X,同时她也工作于Project X;Bob是Developer并工作于Project Y;Charlie是Developer并工作于Project X。最后是约束(constraints):1)每个项目至少有一个员工参与;2)每个角色至少负责一个项目;3)如果员工拥有某角色且该角色负责某项目,则可以推断该员工参与该项目;4)每个员工只能参与一个项目。这种结构化的知识表示有助于清晰地管理员工与项目间的关系,并支持推理和查询。

这一页讲的是关于逻辑推理的练习题,要求判断哪种推论是逻辑上有效的。选项包括人员与项目的工作关系和责任分配。
这一页讲的是逻辑推理练习题,核心问题是判断给出的推论是否在逻辑上有效。题目列出了四个选项,分别涉及人员(Alice、Charlie、Bob)与项目(Project X、Project Y)的工作关系和责任分配。例如,选项 A 推论 Alice 在从事 Project Y 的工作;选项 B 推论 Charlie 对 Project X 负有责任;选项 C 推论 Bob 因为其角色是开发者(Developer),所以负责 Project Y;选项 D 推论 Alice 和 Bob 必须交换项目,因为所有项目都需要分配一个经理(Manager)。这一练习的目的是帮助学生理解如何基于语义和角色关系进行逻辑推理,并判断推论是否符合逻辑规则。通过分析这些选项,学生可以更好地掌握本体论(Ontology)中推理的应用场景和方法。

这一页讲的是本体论推理题的答案解析,正确答案是 C。重点包括角色与责任的关系,以及推理规则的应用。
这一页讲的是关于本体论推理题的答案解析,正确答案是 C。首先,选项 A 被排除,因为 Alice 和 Project Y 之间没有任何关系。选项 B 错误的原因是,虽然 Charlie 是 Developer,但本体论明确说明责任是由角色(Role)而非个体(Individual)承担的,因此不能直接推断 Charlie 对 Project Y 负责。选项 C 是正确的,因为 Bob 是 Developer,而本体论指出 Project Y 的责任归属于 Developer 角色,因此可以推断 Bob 在参与 Project Y。选项 D 被排除,因为没有规则要求 Manager 必须负责所有项目。此外,E 提到 Charlie 可以被推断为正在参与 Project Y。这页还强调了两点重要的本体论推理原则:一是显式事实优先,二是推理不能与已知事实矛盾或替代已知事实。这些原则确保了推理的逻辑性和准确性。

这一页讲的是知识表示的概述及其重要性,包括知识图谱和检索增强生成等主题。图表展示了从数据到智慧的知识模型。
这一页讲的是知识表示(Knowledge Representation)的概述以及它在人工智能中的重要性。主要内容包括知识表示的回顾、AI为何需要知识表示、专家系统(Expert Systems)、本体论(Ontologies)、知识图谱(Knowledge Graph)和检索增强生成(Retrieval-Augmented Generation)。右侧的图表展示了一个知识模型,从数据(Data)到信息(Information)、知识(Knowledge)再到智慧(Wisdom)的逐步演进过程。横轴表示理解的深度(Degree of Understanding),纵轴表示连接的程度(Degree of Connectedness)。例如,数据是基础,通过理解关系形成信息;信息进一步通过识别模式形成知识;最终知识通过理解原则上升到智慧。这种模型强调了知识表示在人工智能中逐步深化的过程。知识图谱是其中的重要工具,它通过结构化的方式连接数据和知识,支持复杂推理和语义理解。检索增强生成则结合知识库与生成模型,提高生成内容的准确性和相关性。

这一页讲的是知识图谱(Knowledge Graph, KG)。它是一种图结构化表示法,用于存储实体(nodes)和关系(edges)。
这一页讲的是知识图谱(Knowledge Graph, KG)。知识图谱是一种图结构化表示法,用于存储实体(nodes)和关系(edges),与传统数据库不同,它不仅存储原始事实,还能帮助 AI 进行推理(reason)、推断(infer)和检索(retrieve)结构化信息。定义中提到,节点(nodes)表示实体,例如人物、地点、物品等;边(edges)表示实体之间的关系,例如“达芬奇(DA VINCI) → 绘制(painted) → 蒙娜丽莎(MONA LISA)”。幻灯片中的图形展示了一个知识图谱的实例,其中包括多个节点如“蒙娜丽莎”、“卢浮宫”和“巴黎”,以及它们之间的关系,例如“蒙娜丽莎位于卢浮宫”、“卢浮宫位于巴黎”。通过这种结构化表示法,知识图谱能够有效地组织和连接信息,支持复杂的知识查询和推理。例如,基于图谱可以快速回答“蒙娜丽莎在哪里?”或“达芬奇的作品有哪些?”等问题。
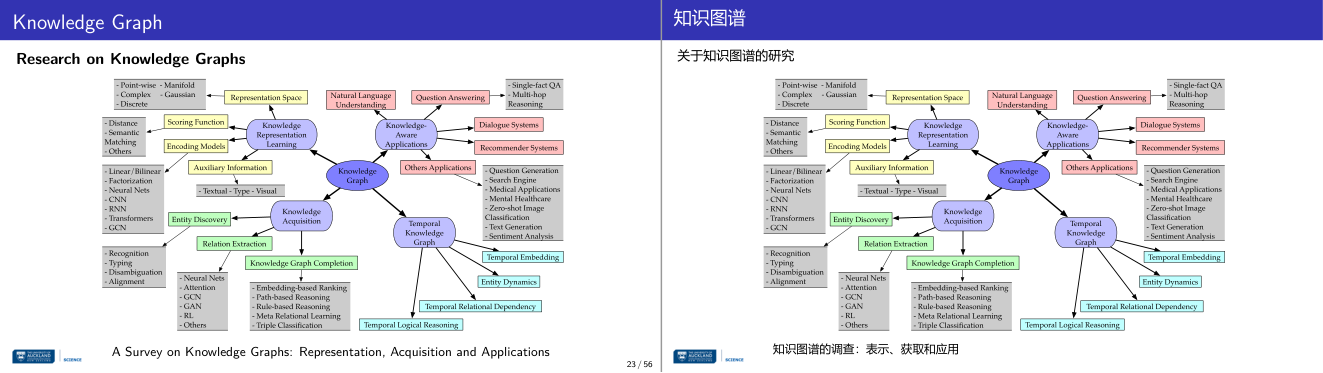
这一页讲的是知识图谱的研究方向,包括表示学习、知识获取和应用领域。
这一页讲的是知识图谱(Knowledge Graph)的研究方向,主要分为三个部分:知识表示学习(Knowledge Representation Learning)、知识获取(Knowledge Acquisition)和知识图谱的应用(Knowledge-aware Applications)。知识表示学习包括表示空间(Representation Space)和评分函数(Scoring Function),例如使用点对(Point-wise)、流形(Manifold)等方法,以及基于距离或语义匹配的编码模型(Encoding Models)。知识获取则涉及实体发现(Entity Discovery)和关系抽取(Relation Extraction),通过神经网络(Neural Nets)、GCN、GAN等技术完成知识图谱补全(Knowledge Graph Completion)。最后,知识图谱的应用领域涵盖问答系统(Question Answering)、对话系统(Dialogue Systems)、推荐系统(Recommender Systems)等,甚至扩展到医疗、情感分析等其他应用(Others Applications)。此外,时间知识图谱(Temporal Knowledge Graph)强调时间嵌入(Temporal Embedding)、实体动态(Entity Dynamics)和时间逻辑推理(Temporal Logical Reasoning),以支持复杂的时间相关任务。这些研究方向共同推动了知识图谱在人工智能中的广泛应用。

这一页讲的是知识图谱如何存储和表示数据,重点介绍 RDF 的三元组结构 (Subject, Predicate, Object)。
这一页讲的是知识图谱如何存储和表示数据,主要通过 RDF (Resource Description Framework) 的三元组结构来实现。RDF 使用三元组 (S, P, O) 或 (h, r, t) 表示知识,其中 S 或 h 是主体 (Subject),表示实体,例如 Einstein;P 或 r 是谓词 (Predicate),表示关系,例如 born_in;O 或 t 是客体 (Object),表示相关实体,例如 Germany。这种结构具有灵活性、可扩展性,并且易于机器读取和处理。幻灯片中的代码示例展示了 RDF 的语法,例如 <Einstein> <born_in> <Germany>,表示爱因斯坦出生在德国。类似地,<Theory of Relativity> <related_to> <Physics> 表示相对论与物理学相关。这种表示方法适用于构建知识图谱,用于存储和检索复杂的关系信息,广泛应用于语义搜索和人工智能领域。
这一页讲的是 RDF(Resource Description Framework)三元组表示和 OWL(Web Ontology Language)的功能,以及两者的关键区别。RDF 是知识图谱存储知识的核心格式,用三元组 (Subject, Predicate, Object) 也写作 (Head, Relation, Tail) 即 (h, r, t) 来表达每一条知识。例如 (Einstein, born_in, Germany) 就是一个完整的 RDF 三元组,主语是 Einstein,谓语(关系)是 born_in,宾语是 Germany。这种格式灵活、可扩展、机器可读,是语义网的基础。OWL 是在 RDF 之上的扩展,它增加了本体层面的逻辑推理能力,可以定义概念的层级继承关系(如 Scientist 是 Person 的子类),从而让 AI 推断出「Einstein isA Scientist,Scientist isA Person,因此 Einstein isA Person」这样的新知识,即使这条关系没有被显式存储。两者区别的口诀:RDF 管「事实」,OWL 管「逻辑加本体」。RDF 提供基础数据模型,OWL 提供更丰富的本体构造和逻辑推理能力。考试常考:给出一段场景,判断用 RDF 还是 OWL 来实现某个功能;或者给出 RDF 三元组集合加上 OWL 规则,推导出 AI 能得出什么新结论(如Exercise 3中 Prof. John 属于哪个学院的推理)。易错:不要把 OWL 当成替代 RDF 的工具,而是扩展——OWL 在 RDF 之上工作。

这一页讲的是知识图谱中 OWL 的作用。OWL 扩展了 RDF,通过逻辑推理和本体分类定义概念、关系和层次约束。它能帮助 AI 推断缺失知识,比如科学家属于人类。
这一页讲的是知识图谱中 OWL(Web Ontology Language)的作用及其与 RDF 的区别。OWL 是一种扩展 RDF 的语言,它通过逻辑推理和本体分类,能够定义知识图谱中的概念、关系以及层次约束。本页举例说明了 OWL 如何分类实体:通过定义“Scientist”(科学家)是“Person”(人类)的子类,所有科学家都被归类为人类。这种分类能力使得 AI 能够推断缺失知识,例如,如果爱因斯坦是科学家,那么他也是人类。关键区别在于,RDF 主要用于表示事实(基于三元组的数据模型),而 OWL 在此基础上增加了逻辑和本体功能,提供更丰富的构造和推理能力。这种扩展使得知识图谱不仅能存储数据,还能进行复杂的逻辑推理,从而更有效地支持智能应用。

这一页讲的是使用 RDF 三元组和 OWL 推理规则进行 AI 推理。重点包括知识图谱中教授、课程和部门的关系,以及 OWL 本体推理规则的应用。
这一页讲的是使用 RDF 三元组和 OWL 推理规则进行 AI 推理。场景是一个大学知识图谱,存储了教授、课程和部门之间的关系。幻灯片中列出了 RDF 三元组,例如教授 John 教授 AI 课程,AI 课程属于 CS 部门,CS 部门属于工程学院等。OWL 本体定义了一些层次结构和推理规则,包括每门课程属于一个部门,教授教的课程属于该课程的部门,所有部门属于一个学院,以及教授在某个部门工作时属于该部门所在的学院。通过这些规则,可以推断 Prof. John 属于工程学院,因为他教的 AI 课程属于 CS 部门,而 CS 部门属于工程学院。这一推理展示了 OWL 推理规则如何帮助知识图谱进行逻辑推断,解决复杂关系问题。

这一页讲的是通过 OWL 推理规则确定 Prof. John 属于 Engineering Faculty。要点包括 RDF 数据、OWL 规则 2 和 4 的应用,以及最终结论。
这一页讲的是如何通过 OWL 推理规则确定 Prof. John 属于 Engineering Faculty。首先,RDF 数据指出 Prof. John 教授 AI_Course,而 AI_Course 属于 CS_Department,因此 Prof. John 在 CS_Department 工作。接着,OWL 规则 2 表明教授的课程属于某个部门,因此教授也属于该部门,这进一步确认 Prof. John 在 CS_Department。最后,OWL 规则 4 指出教授在某个部门工作意味着他也是该部门所属学院的成员,而 CS_Department 属于 Engineering_Faculty,因此可以推导出 Prof. John 属于 Engineering Faculty。这一逻辑链条展示了语义推理在知识图谱中的应用,帮助我们从分散的信息中得出明确结论。

这一页讲的是图数据库(Graph Database)在知识图谱中的应用,介绍了三种主要的图数据库:Neo4j、RDF Store 和 Dgraph,以及它们的类型和使用案例。
这一页讲的是图数据库(Graph Database)如何存储、查询和管理图结构化数据。与传统关系型数据库(SQL)使用表格存储不同,图数据库通过节点(nodes)和边(edges)存储数据,非常适合知识图谱(Knowledge Graph)。图数据库作为容器存储知识图谱内容。页面重点介绍了三种图数据库:1. Neo4j 是最流行的图数据库,采用属性图模型(Property Graph Model),常用于社交网络、欺诈检测和知识图谱应用;2. RDF Store 主要用于语义网和链接数据,采用 RDF 三元组存储模型(RDF Triple Store),支持开放知识图谱,如 DBpedia 和 Wikidata;3. Dgraph 是一种分布式图数据库,专为大规模知识图谱设计,支持实时 AI 驱动应用,如搜索引擎和聊天机器人。这些数据库的具体类型和使用场景帮助理解它们在知识图谱中的独特优势。
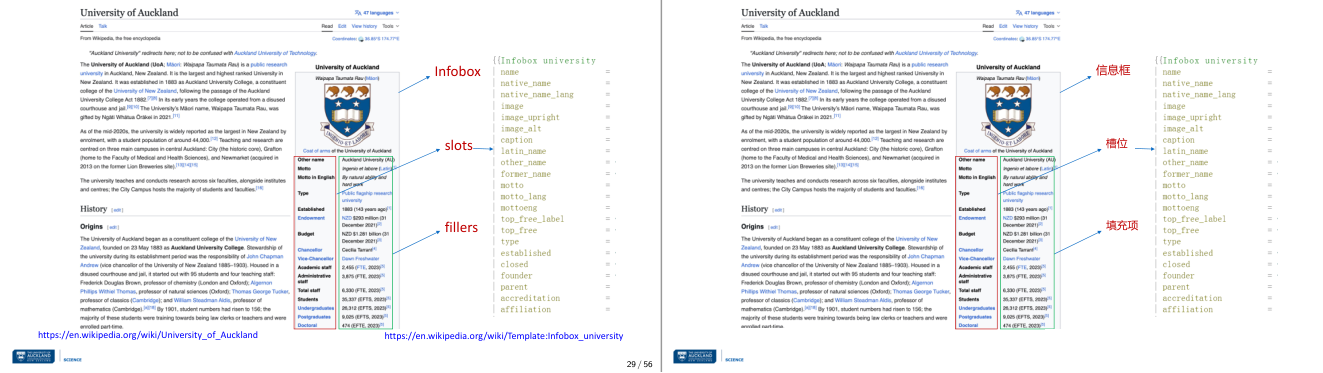
这一页讲的是维基百科中的 Infobox 模块结构及其组成部分。主要包括 Infobox 的定义、slots 和 fillers 的功能。
这一页讲的是维基百科中用于组织信息的 Infobox 模块。Infobox 是一种标准化的信息框架,通常用于页面右侧显示概览信息。它由三个主要部分组成:Infobox 本身是模块的整体框架,slots 是框架中的信息字段,例如 name、native_name 等,fillers 是填充这些字段的具体内容,例如大学名称、成立年份等。页面中以奥克兰大学为例,展示了 Infobox 的结构和内容。Infobox 提供了一个简洁的方式来组织和展示信息,方便用户快速了解关键数据。通过 slots 和 fillers 的结合,可以灵活地适应不同类型的信息需求,例如历史、预算、学生人数等。这个模块在维基百科中非常重要,因为它提高了信息的可读性和一致性。

这一页讲的是知识图谱的构建数据来源,分为结构化、非结构化和半结构化三类。结构化数据来自数据库等;非结构化数据通过 NLP 提取;半结构化数据需转换为图谱格式。
这一页讲的是知识图谱(Knowledge Graph, KG)的构建数据来源,主要分为三类:结构化(Structured)、非结构化(Unstructured)和半结构化(Semi-Structured)。第一类结构化数据已经在关系型数据库或现有知识库中组织好,例如 DBpedia、Wikidata 和 Freebase,这些数据直接可用。第二类非结构化数据包括文本、网页和科学论文等,需要通过自然语言处理(NLP)技术提取知识。常用方法有命名实体识别(Named Entity Recognition, NER),用于识别实体如“Einstein”;关系抽取(Relation Extraction, RE),用于识别实体间的关系如“Einstein → Discovered → Theory of Relativity”。第三类半结构化数据部分组织好,如 JSON、XML 或 API,需要进一步转换为知识图谱格式。例如 Wikipedia Infoboxes 的 JSON 格式可提取为 KG 三元组;Web APIs 如 Google Knowledge Graph API 和 OpenAI API 也属于此类。这三种数据来源共同构成知识图谱的基础,帮助实现知识的组织与推理。

这一页讲的是知识图谱构建方法,包括实体抽取和关系抽取两部分。
这一页讲的是知识图谱构建方法,主要分为两个步骤:第一步是实体抽取(Entity Extraction),即从文本中识别出实体,例如人物、地点和组织等。页面举例说明:从句子“Albert Einstein was born in Germany and developed the Theory of Relativity”中可以抽取出实体(Albert Einstein, Germany, Theory of Relativity)。第二步是关系抽取(Relation Extraction),即识别实体之间的关系。例如从上述实体中可以得到关系(Albert Einstein, born_in, Germany)和(Albert Einstein, discovered, Theory of Relativity)。这两个步骤是构建知识图谱的基础,实体抽取确保图谱中包含关键信息,而关系抽取则定义了实体之间的关联,使知识图谱能够表达复杂的语义关系。

这一页讲的是知识图谱构建的两个方法:知识整合和存储查询。知识整合用于合并重复实体,存储查询则依赖图数据库完成数据存储和检索。
这一页讲的是知识图谱构建中的两个重要步骤。首先是知识整合(Knowledge Integration),它的目的是合并重复的实体并确保一致性。例如,来自维基百科的“Albert Einstein”和研究论文中的“A. Einstein”可能指的是同一个人,通过整合将它们合并为知识图谱中的一个实体。这对于保持数据的准确性和避免冗余非常重要。其次是存储与查询(Storage & Query),知识图谱需要存储在图数据库中,例如 Neo4j、RDF Stores 和 Dgraph 等。不同的图数据库支持不同的查询语言,例如 RDF Store 使用 SPARQL,Neo4j 使用 Cypher。页面还展示了一个 SPARQL 查询的例子,用于检索爱因斯坦的出生地。这个查询通过定义资源和属性(如出生地)来获取相关信息。这种方法可以高效地从知识图谱中提取结构化数据,适用于复杂的知识检索任务。

这一页讲的是从文本中提取三元组 (Subject, Predicate, Object) 来构建知识图谱 (Knowledge Graph)。主要方法包括命名实体识别 (NER) 和关系抽取 (RE)。
这一页讲的是如何通过命名实体识别 (Named Entity Recognition, NER) 和关系抽取 (Relation Extraction, RE) 从非结构化文本中提取三元组 (Subject, Predicate, Object),以构建知识图谱 (Knowledge Graph, KG)。幻灯片提供了一个历史书段落作为示例,内容涉及玛丽·居里 (Marie Curie) 的生平和成就。通过分析文本,可以提取如下三元组:例如,(Marie Curie, born in, Poland)、(Marie Curie, born in, 1867)、(Marie Curie, discovered, radium)、(Marie Curie, discovered, polonium)、(Marie Curie, awarded Nobel Prize in, Physics)、(Marie Curie, awarded Nobel Prize in, Chemistry)、(Marie Curie, collaborated with, Pierre Curie)。这些三元组通过明确的主语、谓语和宾语表达了实体间的关系,是知识图谱的基础。知识图谱的构建对信息检索、问答系统等应用非常重要,因为它能将非结构化信息转化为结构化数据,提升数据的可用性和语义理解。

这一页讲的是如何从文本中提取三元组(triples)用于知识图谱(KG)构建。重点包括使用命名实体识别(NER)和关系抽取(RE)技术,以及从示例段落中提取三元组的练习。
这一页讲的是知识图谱(Knowledge Graph, KG)的构建方法,具体是通过从非结构化文本中提取三元组(triples)。三元组的形式是 (Subject, Predicate, Object),简称 (S, P, O)。构建 KG 的关键技术包括命名实体识别(Named Entity Recognition, NER)和关系抽取(Relation Extraction, RE)。页面提供了一段关于居里夫人的历史文本作为练习素材:“Marie Curie, a physicist and chemist, was born in Poland in 1867. She discovered radium and polonium, and was awarded the Nobel Prize in Physics in 1903 along with Pierre Curie. Later, in 1911, she won another Nobel Prize, this time in Chemistry.” 示例中展示了部分三元组,例如:(Marie Curie, born_in, Poland) 和 (Marie Curie, discovered, Radium)。通过分析这段文本,可以提取更多三元组,如 (Marie Curie, awarded, Nobel Prize in Physics) 和 (Marie Curie, won, Nobel Prize in Chemistry)。这些三元组帮助将非结构化信息转化为结构化数据,便于知识的组织和查询。这种方法在构建智能系统中非常重要,例如问答系统或推荐系统。

这一页讲的是知识图谱推理(Knowledge Graph Inference)的定义和一个简单例子。重点包括AI如何通过逻辑规则、嵌入和图推理从已有事实中推导新知识,以及链接预测的作用。
这一页讲的是知识图谱推理(Knowledge Graph Inference),即AI通过逻辑规则、嵌入(embeddings)和基于图的推理从已有事实中推导出新的知识。这种推理方法可以扩展知识图谱的内容,帮助AI生成不在原始数据中的关系。页面举了一个例子:如果知识图谱中包含“爱因斯坦赢得了物理学诺贝尔奖”和“诺贝尔奖属于科学奖”这两个事实,那么AI可以推导出“爱因斯坦获得了科学奖”,尽管这一关系在原始知识图谱中并未明确列出。图中展示了链接预测(Link Prediction)的概念,节点之间的连线表示可能的关系,通过推理可以预测新的连接。这个过程对于知识图谱的扩展和增强非常重要,例如在推荐系统或语义搜索中,可以帮助发现隐藏的关联关系。

这一页讲的是知识图谱推理任务,包括预测缺失链接、关系类型、验证事实等,应用于 AI 助手、语义搜索等场景。
这一页讲的是知识图谱推理(Knowledge Graph Inference)的任务分类及其应用。表格列出了六种主要任务:1. KGC (Completion) 的目标是预测缺失链接,例如“Paris, located_in, ? → France”,主要用于 AI 助手和医疗 AI。2. Relation Prediction 用于预测关系类型,例如“Einstein, ?, Physics → studied”,适用于语义搜索和欺诈检测。3. Fact Verification 验证事实的准确性,例如“Moon, made_of, Cheese”,在假新闻检测和数据库清理中有重要作用。4. Fact Generation 负责生成新的事实,例如“Drug X, treats, ? → Disease Y”,被广泛用于生物医学 AI 和科学发现。5. KG Reasoning 推理新知识,例如“Paris, (France, in EU) → (Paris, in EU)”,在法律 AI 和科学研究中发挥作用。6. KG Alignment 用于合并多个知识图谱,例如“Barack Obama ≈ B. Obama”,应用于企业 AI 和多语言 AI。通过这些任务,知识图谱可以更好地支持复杂的推理和决策场景,提升 AI 系统的智能化程度。
这一页讲的是 Knowledge Graph Inference(知识图谱推断)的六大任务类型,这张表格是本讲最重要的考试考点之一。六类任务分别是:一、KGC Knowledge Graph Completion(知识图谱补全),预测缺失的链接,如 (Paris, located_in, ?) 推断出 France;二、Relation Prediction(关系预测),给定头尾实体预测中间关系类型,如 (Einstein, ?, Physics) 推断 studied;三、Fact Verification(事实验证),判断某个三元组是否为真,如 (Moon, made_of, Cheese) 是假,应用于假新闻检测;四、Fact Generation(事实生成),创造新的假设事实,如 (Drug X, treats, ?) 生成 Disease Y,用于生物医学发现;五、KG Reasoning(知识图谱推理),通过链式推理得到新知识,如 (Paris in France) 加上 (France in EU) 推出 (Paris in EU);六、KG Alignment(知识图谱对齐),合并来自不同源的 KG,识别出 Barack Obama 和 B. Obama 是同一实体。直觉上,这六类任务从「填空」到「判断」再到「创造」再到「整合」,覆盖了 KG 在 AI 系统中几乎所有的智能应用场景。考试会给出一个应用描述,让你判断属于哪类推理任务,所以要能记住每类任务的核心目标和典型例子。

这一页讲的是知识图谱推理的两种方法:规则推理和图结构推理。规则推理通过逻辑规则推导新事实,常用 OWL 和 SPARQL;图结构推理通过遍历图结构推导关系,使用图查询语言和算法。
这一页讲的是知识图谱推理的两种方法。第一种是规则推理(Rule-Based Reasoning),它基于显式逻辑规则(如 IF-THEN 逻辑)来推导新事实,属于符号推理(Symbolic Inference)。实现时通常使用 OWL(Web Ontology Language)、SPARQL 和一阶逻辑(First-Order Logic)。例如,利用传递性规则:如果 A 是 B 的一部分,B 又是 C 的一部分,那么可以推导出 A 是 C 的一部分。第二种是图结构推理(Graph-Based Reasoning),通过遍历知识图的结构来推导实体之间的关系。这种方法使用图查询语言(如 SPARQL 和 Cypher)以及图算法(如 PageRank 和最短路径算法)。一个例子是 Neo4j 中的最短路径查询:通过路径查询,AI 可以发现爱因斯坦间接受到居里夫人的指导。图中的代码展示了如何通过 Cypher 查询实现这一推理,代码中定义了从居里夫人到爱因斯坦的路径并返回结果。这两种推理方法在知识图谱中都非常重要,分别适用于不同的场景和需求。
这一页讲的是知识图谱推断的三种技术路径:规则推理、图路径推理和嵌入推理。第一种 Rule-Based Reasoning(规则推理/符号推理):基于显式的逻辑规则(IF-THEN)推导新事实,常用工具是 OWL 和 First-Order Logic(FOL)。典型例子是传递性规则:如果 A 是 B 的一部分,B 是 C 的一部分,那么 A 是 C 的一部分。这种方式可解释性强,但需要人工定义规则。第二种 Graph-Based Reasoning(图路径推理):AI 通过遍历图的路径结构来推断实体之间的隐含关系,使用 SPARQL/Cypher 等图查询语言和 PageRank、最短路径等图算法。例如查询 Einstein 和 Curie 之间的学术关系链。第三种 Embedding-Based Inference(嵌入推理)将在后续页面详细展开(TransE 等模型),核心思想是把实体和关系映射成向量,通过向量运算推断缺失知识。三种方法的对比直觉:规则推理像代数解方程(精确但需要手写规则),图路径推理像地图导航(沿已知路径走),嵌入推理像查字典的语义相似度(模糊但能泛化到未见过的情况)。考试常考:区分这三类方法的特点,以及在给定场景下选择最合适的方法(已有逻辑规则用 Rule-Based,大规模缺失链接预测用 Embedding-Based)。

这一页讲的是基于嵌入的知识图谱推理 (Embedding-Based Knowledge Graph Inference)。主要内容包括定义知识图谱嵌入、其用途及优势。
这一页讲的是基于嵌入的知识图谱推理 (Embedding-Based Knowledge Graph Inference)。知识图谱嵌入 (Knowledge Graph Embeddings, KGE) 是将实体和关系表示为连续空间中的稠密向量 (dense vectors),这样可以帮助模型预测缺失链接 (missing links)、验证事实 (validate facts),并对结构化知识进行推理 (reason over structured knowledge)。使用嵌入的优势包括:第一,能够捕捉隐含模式,超越显式的三元组 (explicit triples);第二,具有可扩展性和高效性,适用于大规模知识图谱 (如 Wikidata 和 Freebase);第三,可以支持深度学习和与大型语言模型 (LLMs) 以及生成式 AI 的集成。页面底部的图示展示了知识图谱嵌入的工作原理:左侧是知识图谱中的关系结构,例如伦敦 (London) 和英国 (United Kingdom) 的关系;右侧是嵌入后的向量空间,关系被转化为数学公式,说明实体间的向量关系。通过这种方式,系统可以更好地处理复杂的知识推理任务,例如预测某个国家的首都或验证地理关系。

这一页讲的是知识图谱推理中的表示学习,重点是通过学习方法将知识图谱转化为适合任务的嵌入表示。
这一页讲的是知识图谱推理中的表示学习(Knowledge Representation Learning)。表示学习是一种方法集合,旨在将输入数据转化为适合特定任务的特征表示。图片中的知识图谱展示了 August Ferdinand Möbius 的相关信息,包括他的身份(科学家)、发明(Möbius Transformation)、学习经历(Leipzig University)以及生活地点(Dresden)。知识图谱通过节点和关系连接知识点,然后通过表示学习方法将这些复杂的关系转化为低维嵌入(Embedding),以便机器学习模型处理。图中展示了知识图谱如何通过一个学习过程转化为嵌入表示,嵌入表示保留了图谱中的语义和结构信息。这种方法在很多场景中很重要,例如推荐系统、问答系统和知识推理。举例来说,通过嵌入表示,可以预测 Möbius 是否可能与其他科学家合作或发明新的理论。

这一页讲的是知识图谱推理中的嵌入生成,重点是将符号知识转化为连续向量表示。
这一页讲的是知识图谱推理中的嵌入生成(Knowledge Graph Embedding Generation)。主要内容是将符号知识(symbolic knowledge,例如图谱数据)转化为连续的向量表示(continuous vector representations)。具体过程包括:首先从文本数据(Text data)出发,通过神经网络(Neural Networks,例如 Word2Vec 或 BERT)生成语义表示(Semantic Representations),这些表示位于高维空间中,能够捕捉知识的语义关系。最后,这些向量空间不仅仅表达语义,还可以捕捉知识图谱(Knowledge Graph)的结构和内容。图中展示了三个主要步骤:从文本到神经网络,再到语义表示,最终连接到知识图谱。知识图谱中节点之间的关系可以通过嵌入向量来反映,例如可以表示人物之间的关联或组织之间的关系。这种方法的重要性在于,它能够将复杂的符号知识转化为计算机可处理的连续数据,从而支持后续的推理和分析。

这一页讲的是知识图谱推理中的 TransE 模型。它通过向量表示实体和关系,并将关系建模为向量空间中的平移操作。
这一页讲的是知识图谱推理中的 TransE 模型(Translating Embeddings for Modeling Multi-relational Data)。TransE 是一种嵌入模型,它将知识图谱中的实体和关系表示为连续空间中的向量。核心思想是:给定一个三元组(头实体 Head、关系 Relation、尾实体 Tail),模型将关系 r 表示为向量空间中的平移操作,公式为 h + r ≈ t,其中 h 是头实体的向量,t 是尾实体的向量。意思是,头实体的向量加上关系的向量应该接近尾实体的向量。图中展示了这种关系的几何表示,h、r 和 t 在向量空间中形成一种平移关系。 举例来说,如果 AI 已知以下事实:(University of Auckland, located_in, Auckland)和(Auckland, part_of, New Zealand),TransE 会学习到以下嵌入关系:UoA + located_in ≈ Auckland,Auckland + part_of ≈ NZ。通过这种方式,AI 可以推理出缺失的知识,例如:(University of Auckland, located_in, New Zealand)。这说明 TransE 模型可以有效地进行知识图谱中的推理,帮助发现隐含的关系。
这一页讲的是 TransE(Translating Embeddings)模型,这是知识图谱嵌入领域最经典、最基础的模型,也是713考试的高频考点。TransE 的核心思想极为优美:给定一个三元组 (h, r, t),即头实体、关系、尾实体,TransE 把关系 r 建模为从 h 到 t 的「平移向量」,用数学表达就是 h 加 r 约等于 t。这意味着在向量空间中,从头实体出发,沿关系方向移动,应该恰好落到尾实体的位置。用一个生活例子:如果 Paris 的向量加上 capital_of 的向量大约等于 France 的向量,那么模型就「理解」了首都关系。这种平移思想让 TransE 能够推断缺失知识:已知 (UoA, located_in, Auckland) 和 (Auckland, part_of, New Zealand),TransE 可以推断 (UoA, located_in, New Zealand),因为向量路径是连续的。数学评分函数是 f(h,r,t) 等于 h 加 r 减 t 的 L1 或 L2 范数——有效三元组的分数应该接近 0(距离小),无效三元组分数应该大(距离大)。考试必考:能写出 TransE 的核心公式 h 加 r 约等于 t,以及评分函数;能手算 L1 范数来判断哪个候选实体最匹配(如Exercise 5);理解「分数低=三元组合理」这个反直觉设定(越接近0越好)。

这一页讲的是知识图谱推理中的 TransE 方法及其数学公式,重点是向量空间表示和评分函数。
这一页讲的是知识图谱推理中 TransE 方法的数学公式和评分函数。TransE 将每个实体 e 和关系 r 映射到 d 维嵌入空间的向量表示中,实体和关系分别表示为 e 属于 R^d 和 r 属于 R^d。为了评估一个三元组 (h, r, t) 的合理性,TransE 定义了评分函数 f(h, r, t),计算公式是 ||h + r - t||,其中 h 是头实体的向量,r 是关系的向量,t 是尾实体的向量。评分函数的值通过 L1 范数(曼哈顿距离)或 L2 范数(欧几里得距离)来计算。L1 范数计算的是所有维度差值的绝对值之和,而 L2 范数则是所有维度差值的平方和的平方根。有效的三元组会得到较低的评分值,而错误的三元组则会有较高的评分值。这种评分机制帮助模型区分知识图谱中的真实关系和错误关系,从而提高推理准确性。
这一页讲的是 TransE 的数学公式细节:评分函数的两种范数形式,以及训练时用的 Margin-Based Ranking Loss(基于间隔的排名损失)。评分函数部分:f(h,r,t) 等于 h 加 r 减 t 的范数,有两种选择:L1(曼哈顿距离)是各维度差的绝对值之和,L2(欧几里得距离)是各维度差的平方和再开根。两者的选择影响模型对噪声的敏感度,L1 对异常值更鲁棒,L2 更平滑。训练目标函数部分:TransE 使用 Margin-Based Ranking Loss,其形式是对所有正确三元组 (h,r,t) 和对应的负样本三元组 (h',r,t') 求和,取 max(0, gamma 加 f(h,r,t) 减 f(h',r,t'))。其中 gamma 是超参数「间隔 margin」,正确三元组的分数应该比错误三元组小至少 gamma 的距离,否则就产生损失。负样本 (h',r,t') 是通过「腐蚀」(corruption)生成的,即随机替换头实体或尾实体为其他实体。训练策略的直觉:「拉近正确三元组的向量,推远错误三元组的向量」。这就像 metric learning 中的 triplet loss。考试重点:能理解 margin 的作用(提供安全边界,防止模型把所有分数都压到0);能区分正样本集合 S 和负样本集合 S';知道 max(0,...) 是 hinge loss(铰链损失)的形式,仅在违反 margin 时才产生梯度。

这一页讲的是知识图谱推理中的 TransE 模型及其训练目标。关键点包括边际排序损失函数的定义和训练策略。
这一页讲的是知识图谱推理中的 TransE 模型及其数学公式和训练目标。TransE 的训练目标是通过最小化边际排序损失函数 (Margin-Based Ranking Loss) 来优化嵌入。公式中,S 是正确三元组 (h, r, t) 的集合,S' 是被扰乱的负三元组 (h', r, t') 的集合,γ 是边际超参数。损失函数的目标是让正确三元组的得分 f(h, r, t) 尽可能高,同时负三元组的得分 f(h', r, t') 尽可能低。训练策略包括两部分:一是最小化正确三元组的得分,二是通过负采样 (negative sampling) 来最大化错误三元组的得分。这种方法确保模型能够区分正确和错误的知识图谱关系。例如,如果 (h, r, t) 表示“巴黎是法国的首都”,而 (h', r, t') 表示“纽约是法国的首都”,模型会学习到前者的得分高于后者,从而提升知识图谱的推理能力。

这一页讲的是知识图谱推理模型 TransE 的训练过程,包括初始化嵌入、计算三元组得分、梯度优化和嵌入归一化。
这一页讲的是知识图谱推理模型 TransE 的训练过程。首先,初始化实体和关系的嵌入(embeddings),为每个实体和关系分配随机向量。接着,计算正负三元组的得分。正三元组的得分通过函数 f(h, r, t) 计算,而负三元组通过扰乱头实体 h 或尾实体 t 生成。然后,通过梯度下降优化嵌入,最小化损失函数以提高模型的预测能力。最后,可选步骤是对嵌入进行归一化处理,以防止数值不稳定。这个过程的核心是通过优化嵌入,使模型能够更好地表示知识图谱中的关系和实体。举例来说,如果有一个三元组 (Paris, capital_of, France),模型会学习到 Paris 和 France 的嵌入之间的距离与关系 capital_of 的嵌入相匹配,从而捕捉知识图谱中的语义信息。

这一页讲的是使用 TransE 模型进行知识图谱推理,通过 L1 距离预测缺失的尾实体。
这一页讲的是使用 TransE 模型进行知识图谱推理。TransE 是一种知识图谱嵌入模型,它通过将实体和关系表示为向量,并优化这些向量使得 h + r ≈ t(头实体加关系向量近似尾实体向量)。这一页的场景中,模型已经学习了实体和关系的向量嵌入,例如 Paris → (0.5, 0.2, 0.7),France → (0.8, 0.4, 1.0),located_in → (0.3, 0.2, 0.3)。接下来,模型需要根据查询 (Paris, located_in, ?) 使用 L1 距离(曼哈顿距离)预测最可能的尾实体。L1 距离的公式是向量维度逐项相减后取绝对值再求和。通过计算 Paris 和 located_in 的向量相加,然后与候选实体的向量比较,选择距离最小的实体作为预测结果。这种方法的重要性在于它可以高效地处理知识图谱中的推理任务,帮助发现关系和实体之间的潜在联系。

这一页讲的是 TransE 推理的答案。重点是使用 h + r ≈ t 的公式计算向量,并通过 L1 距离选择最可能的实体。
这一页讲的是 TransE 推理的答案。TransE 模型遵循 h + r ≈ t 的公式,其中 h 是头实体 (head),r 是关系 (relation),t 是尾实体 (tail)。在例子中,针对问题“Paris, located_in, ?”,我们通过计算 (0.5, 0.2, 0.7) + (0.3, 0.2, 0.3) 得到结果向量 (0.8, 0.4, 1.0)。然后分别计算这个向量与候选实体(France, Europe, Germany)的 L1 距离。L1 距离的计算方式是取两个向量对应维度差值的绝对值之和: 与 France 的距离为 |0.8-0.8| + |0.4-0.4| + |1.0-1.0| = 0。 与 Europe 的距离为 |0.8-0.9| + |0.4-0.3| + |1.0-1.2| = 0.1 + 0.1 + 0.2 = 0.4。 与 Germany 的距离为 |0.8-1.2| + |0.4-0.6| + |1.0-1.5| = 0.4 + 0.2 + 0.5 = 1.1。 由于 France 的 L1 距离最小(0.0),它是最可能的预测结果。这说明 TransE 模型通过向量运算和距离比较可以有效地进行关系推理。这个过程展示了如何利用向量空间中的距离来选择最合适的实体。

这一页讲的是 TransE 的局限性,尤其在处理 1-to-N、N-to-1 和 N-to-N 关系时的不足。TransE 使用单一翻译向量,导致难以区分共享同一尾实体的头实体。
这一页讲的是 TransE 在知识图谱推理中的局限性。TransE 模型在处理 1-to-N、N-to-1 和 N-to-N 关系时存在问题,因为它将所有关系都映射为嵌入空间中的单一翻译向量。这种方式在面对共享同一尾实体的多个头实体时,无法有效区分它们的表示。例如,在 (City, located_in, Country) 的关系中,巴黎、里昂和马赛都位于法国。如果 'located_in' 的翻译向量将每个城市映射到法国的向量,那么这些城市的嵌入会完全重叠,导致实体之间的区分性丧失。这种问题会影响模型对知识图谱中复杂关系的表达能力,尤其是需要区分具有相同尾实体的多个头实体时。解决这一问题对于提高知识图谱推理的准确性非常重要。
这一页讲的是 TransE 的关键局限性:它无法很好地处理 1-to-N、N-to-1 和 N-to-N 关系,以及解决方案 TransH 的核心思想。TransE 的问题在于,它为每个关系学习一个单一的平移向量。对于 N-to-1 关系(多个头实体对应同一个尾实体),例如 Paris、Lyon、Marseille 都通过 located_in 关系指向 France,TransE 会强迫这三个城市的向量都平移到 France 的向量附近,最终导致 Paris、Lyon、Marseille 的嵌入向量「坍缩」成几乎相同的值,丧失了对不同城市的区分能力。TransH 的解决方案:引入「关系专属超平面(relation-specific hyperplane)」。每个关系 r 有一个法向量 w_r 定义的超平面,在做平移之前,先把实体 h 投影到该超平面上,得到 h⊥ 等于 h 减去 w_r 转置乘 h 再乘以 w_r(即去掉法方向的分量),然后在超平面内做 TransE 风格的平移:h⊥ 加 r 约等于 t⊥。这样不同的实体可以在各自的超平面投影上有不同的位置,解决了多对一的坍缩问题。但 TransH 仍然无法解决同一实体出现在多个关系两端的 many-to-one 双向问题(如 Paris located_in France 和 Paris located_in Germany),这需要 TransR 来解决(TransR 为每个关系 r 投影头和尾实体到不同的关系空间)。考试常考:描述 TransE 的局限,说明 TransH 如何缓解,以及 TransR 的改进方向。

这一页讲的是知识图谱推理中的 TransH 方法。它解决了多对一问题,通过将实体投影到关系特定的超平面来避免实体重叠。
这一页讲的是知识图谱推理中的 TransH 方法,它是对 TransE 的改进,旨在解决多对一的问题。TransH 的核心思想是为每个关系 r 定义一个法向量 wr,从而确定一个超平面。实体 h 被投影到这个超平面上,投影公式为 h⊥ = h - wr^T h wr。投影后,TransE 风格的平移操作应用于新的空间,即 h⊥ + r ≈ t⊥。这样可以避免实体在嵌入空间中重叠。例如,“Paris located_in France”和“Louvre located_in France”被投影到不同的平面,避免了实体重叠的问题。然而,对于多对一的问题,例如“Paris located_in France”和“Paris located_in Germany”,仍然存在挑战,需要通过 TransR 等进一步方法来解决。这一页还包含一个图示,展示了实体和关系在不同空间的投影方式,帮助理解模型的几何直觉。

这一页讲的是知识表示 (Knowledge Representation) 的复习及其在 AI 中的重要性,涵盖专家系统、知识图谱和检索增强生成等内容。图表展示了从数据到智慧的知识层次模型。
这一页讲的是知识表示 (Knowledge Representation) 的复习及其在人工智能中的重要性。主要内容包括:为什么 AI 需要知识表示、专家系统 (Expert Systems)、本体论 (Ontologies)、知识图谱 (Knowledge Graph) 和检索增强生成 (Retrieval-Augmented Generation)。右侧的图表展示了知识层次模型,从数据 (Data) 开始,通过信息 (Information)、知识 (Knowledge) 和智慧 (Wisdom) 的逐步提升,横轴表示理解程度 (Degree of Understanding),纵轴表示连接程度 (Degree of Connectedness)。例如,从数据到信息需要理解关系,从信息到知识需要识别模式,从知识到智慧则需要掌握原则。这种模型强调了知识表示在 AI 系统中帮助机器从简单数据到复杂智慧的转化过程。检索增强生成是知识表示的一种新应用,它结合了知识图谱和生成技术,提升了 AI 的回答准确性和上下文理解能力。

这一页讲的是 LLMs 和知识表示(KR)的结合。主要内容包括 LLMs 的问题如幻觉、缺乏显式推理和记忆限制,以及通过整合 KR 提升准确性、推理能力和实时更新知识的解决方案。
这一页讲的是 LLMs(大型语言模型)与知识表示(KR)的结合及其重要性。LLMs 如 GPT、PaLM 和 Llama 在自然语言理解方面表现强大,但存在一些问题:一是幻觉(hallucinations),即生成不正确或误导性的信息;二是缺乏显式推理(lack of explicit reasoning),更多依赖隐式知识而非结构化事实;三是记忆限制(memory limitations),上下文窗口有限,难以处理长期依赖关系。解决方案是将 LLMs 与 KR 整合。KR 包括知识图谱(KGs)、数据库和本体论,能够提供三方面支持:第一,提升事实准确性(factual accuracy),通过检索验证过的知识来源减少错误;第二,增强推理能力和解释性(reasoning & explainability),KR 提供结构化、基于逻辑的支持,使模型输出更可信;第三,实现实时知识更新(enable real-time knowledge updates),无需重新训练即可利用外部 KR 资源。图中展示了 LLM 与 KR 的结合框架,强调两者协作的重要性。举例来说,结合 KR 的 LLM 可以在回答复杂问题时引用最新的数据库信息,确保答案的准确性和时效性。

这一页讲的是 Retrieval-Augmented Generation (RAG)。RAG结合检索式知识与生成模型,提高事实准确性并减少幻觉。它动态检索实时外部数据,解决传统 LLM 的局限性。
这一页讲的是 Retrieval-Augmented Generation (RAG)。RAG 是一种结合检索式知识与生成模型的技术,旨在提高生成内容的事实准确性并减少幻觉问题。与传统的大型语言模型(LLM)仅依赖预训练知识不同,RAG 能够动态检索实时的外部数据,如数据库、文档和知识图谱,然后生成答案。它的重要性体现在三个方面:首先,它减少了 LLM 的幻觉风险,避免生成错误或过时信息;其次,它增强了实时知识的访问能力,可以使用最新的外部数据;最后,它提高了解释性,为生成的回答提供参考和理由。页面下方的流程图展示了 RAG 的工作机制:用户提出问题后,LLM 通过智能搜索检索相关信息,结合生成模型生成丰富的答案。这种方法特别适合需要高准确性和实时性的应用场景,例如客户服务或学术研究。
这一页讲的是 RAG(Retrieval-Augmented Generation,检索增强生成)的概念、动机和完整工作流程。RAG 的出现是为了解决纯 LLM(大语言模型)的三大痛点:一是 Hallucination(幻觉),即 LLM 有时会自信地生成错误信息;二是缺乏显式推理,LLM 依赖训练时学到的隐式知识,无法保证事实准确;三是 Memory Limitation,LLM 的上下文窗口有限,无法随时获取最新信息。RAG 的解决方案:在 LLM 生成回答之前,先从外部知识源(数据库、文档、知识图谱)检索相关信息,然后把检索到的内容作为「额外上下文」传给 LLM,再生成回答。完整流程分四步:一、用户提交查询;二、知识检索(用 BM25 关键词搜索或 DPR/FAISS 向量相似度搜索);三、把检索到的文档和原始查询一起传给 LLM;四、LLM 生成基于证据的回答,并可以做 re-ranking 优化。数学表达:Generated Response 等于 LLM(Query 加上 Retrieved Knowledge)。对比效果:没有 RAG 的 LLM 可能回答「我不确定2023年图灵奖得主是谁」;有 RAG 的系统会先检索到相关文档,然后准确回答「2023年图灵奖授予 Geoffrey Hinton」。考试重点:能说出 RAG 的四步流程;能比较 BM25(基于关键词的稀疏检索)和 DPR/FAISS(基于深度学习嵌入的密集检索)的区别;理解 RAG 如何缓解幻觉问题——答案有「证据支撑」而非凭空生成。

这一页讲的是 Retrieval-Augmented Generation (RAG) 的工作流程,包括用户查询、知识检索和上下文整合。
这一页讲的是 Retrieval-Augmented Generation (RAG) 的工作流程,分为三个步骤:第一步是用户查询 (User Query),用户输入问题,例如“2023 年图灵奖的获奖者是谁?”;第二步是知识检索 (Knowledge Retrieval),系统从结构化数据 (如数据库、知识图谱) 和非结构化数据 (如文本文档、网站) 中搜索相关信息。检索方法包括 BM25(基于关键词的稀疏检索)和 DPR(Dense Passage Retrieval,利用深度学习嵌入进行相似性搜索),也可以使用 FAISS(基于深度学习嵌入的搜索工具)。第三步是上下文整合 (Contextual Integration with LLM),将检索到的文档作为额外上下文传递给大型语言模型 (LLM),生成更为准确的回答。例如,用户询问“2023 年图灵奖的获奖者是谁?”,系统检索到的文档可能包含“2023 年图灵奖授予了 Geoffrey Hinton,以表彰他对深度学习的贡献”,LLM 将用户输入和检索内容结合后生成最终答案。这种流程能够显著提升回答的准确性和信息量。

这一页讲的是 Retrieval-Augmented Generation (RAG) 的响应生成和重排序。重点包括基于检索知识生成答案、重排序技术优化准确性,以及一个具体例子对比传统 LLM 和 RAG 的回答差异。
这一页讲的是 Retrieval-Augmented Generation (RAG) 的响应生成和重排序。RAG 的核心是结合检索的知识 (retrieved knowledge) 作为事实依据 (ground truth),生成更准确的答案。数学表达式为“Generated Response = LLM(Query + Retrieved Knowledge)”,即通过语言模型结合查询和检索知识生成响应。重排序 (re-ranking) 技术可以进一步优化答案的准确性和优先级。页面中的例子展示了传统 LLM 和 RAG 的回答差异:在用户询问 2023 年图灵奖时,传统 LLM 可能出现幻觉 (hallucination),给出不确定或错误的信息;而使用 RAG 的模型则通过检索真实数据,准确回答图灵奖授予 Geoffrey Hinton 的事实。这说明 RAG 能显著提升回答的准确性和可信度。最后,页面提供了相关学习材料链接,便于深入了解 RAG 的实现和应用。
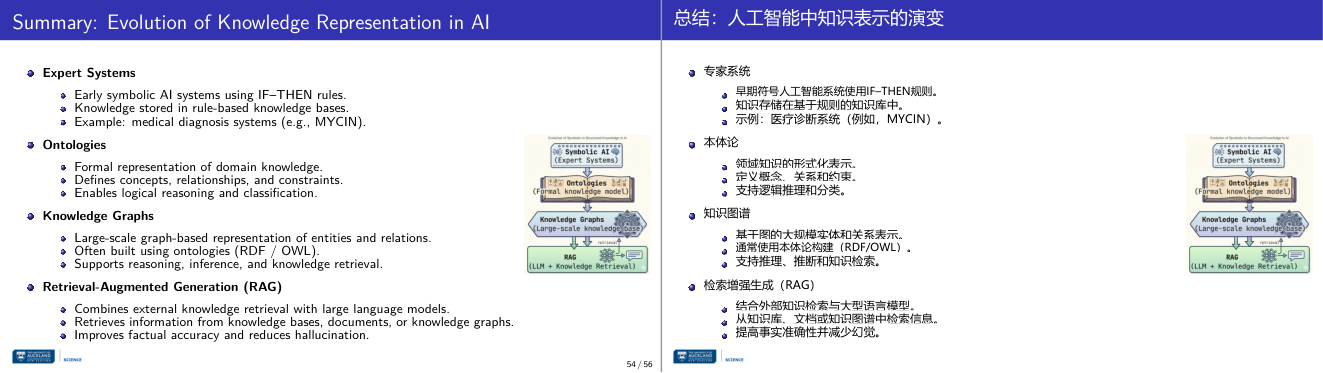
这一页讲的是知识表示在 AI 中的演变,包括 Expert Systems、Ontologies、Knowledge Graphs 和 RAG。重点是这些技术的特点、应用及其发展路径。
这一页讲的是知识表示在 AI 中的演变,主要包括四个阶段:Expert Systems、Ontologies、Knowledge Graphs 和 Retrieval-Augmented Generation (RAG)。第一阶段是 Expert Systems(专家系统),它是早期的符号 AI 系统,使用 IF-THEN 规则,知识存储在基于规则的知识库中,例如 MYCIN 医疗诊断系统。第二阶段是 Ontologies(本体论),它提供了领域知识的形式化表示,定义了概念、关系和约束,支持逻辑推理和分类。第三阶段是 Knowledge Graphs(知识图谱),它是一种基于图的大规模实体和关系表示,通常使用 RDF 或 OWL 本体构建,支持推理、知识检索等功能。最后是 RAG(检索增强生成),它结合了外部知识检索与大型语言模型,从知识库、文档或知识图谱中检索信息,提高了生成内容的准确性并减少了幻觉现象。右侧的流程图展示了这些技术的演变路径,从符号 AI 到本体论,再到知识图谱,最后到 RAG,体现了知识表示逐步复杂化和智能化的趋势。

这一页讲的是现代 AI 系统中知识表示 (Knowledge Representation, KR) 和数据驱动模型 (LLMs) 的结合。重点包括 KR 的功能、专家系统、知识图谱、嵌入技术和检索增强生成 (RAG)。
这一页讲的是现代 AI 系统如何结合结构化知识 (KR) 和数据驱动模型 (LLMs) 来提高推理能力和可靠性。知识表示 (Knowledge Representation, KR) 是 AI 系统存储、组织和推理结构化知识的核心技术。专家系统 (Expert Systems) 通过基于规则的推理模拟人类在特定领域的决策过程。本页还介绍了本体论 (Ontologies),它提供了一个正式框架来表示概念、关系和约束。知识图谱 (Knowledge Graphs) 使用实体和关系来表示真实世界的知识,并支持推理和推断。知识图谱嵌入 (Knowledge Graph Embeddings),例如 TransE,帮助机器学习模型学习结构化知识的表示。检索增强生成 (Retrieval-Augmented Generation, RAG) 则结合外部知识检索与 LLMs,以提高事实准确性并减少幻觉现象。最后的关键洞察是,现代 AI 越来越多地结合 KR 和 LLMs,以实现更强的推理能力和可靠性。

这一页讲的是总结与问答环节。主要表达感谢并邀请观众提问。
这一页讲的是总结与问答环节。幻灯片以“Thank you! Q&A”为主要内容,表示演讲或课程已经结束,感谢观众的参与,并开放问答环节。这是一个常见的结束页,旨在鼓励互动和解决观众的疑问。在问答环节中,观众可以针对之前讲解的内容提出问题,讲解者会进一步解释或澄清相关概念。这种设计有助于巩固学习效果,确保观众充分理解所学内容。