Week 04 - 01 - W4L1_MYCIN-2 视图:双语并排 英文 中文 倍速:1x 1.5x 2x
空格=播放/暂停当前页 · Tab=切换 简短/详细/深入 · 红色「深入」为重点页的深度讲解
这一页讲的是 MYCIN,一个用于医疗诊断的反向推理专家系统。
这一页讲的是 MYCIN,它是一个基于反向推理(Backward-Chaining)的生产规则专家系统,专门用于医疗诊断。MYCIN通过一系列规则和推理机制,帮助医生进行复杂的诊断决策,特别是在感染性疾病的诊断方面。反向推理是一种从目标出发倒推原因的逻辑方法,适合解决目标明确的问题。该系统的设计是人工智能领域的重要里程碑,展示了专家系统如何将知识库和推理机制结合起来,为特定领域提供智能化支持。这一讲由奥克兰大学计算机科学学院的张老师主讲,课程编号为 COMPSCI 713,属于 AI Fundamentals 的内容。
这一页讲的是 MYCIN 系统的概述。MYCIN 是 1970 年代斯坦福开发的早期专家系统,用于细菌感染的医疗诊断。它的技术特点包括知识与推理分离、解释能力、知识编辑简便和先进的搜索策略。
这一页讲的是 MYCIN 系统的概述。MYCIN 是由 Ted Shortliffe 在斯坦福大学于 1970 年代开发的突破性系统,是人工智能应用于医疗诊断领域的一个重要里程碑,专注于细菌感染的治疗决策。它的重要性体现在两个方面:首先,它是最早的专家系统之一,尝试模拟领域专家在特定问题上的专业能力;其次,其技术方法具有开创性,包括将知识(data)与推理(code)分离,这种架构使系统更易于维护和扩展。此外,MYCIN 还具备解释能力(explanation capability),能够帮助用户理解诊断过程;支持知识编辑(easier knowledge editing),方便更新医学知识;以及采用了先进的搜索策略(leading-edge search strategy),提升了推理效率。这些特点使 MYCIN 成为人工智能领域知识表示与推理的经典案例。
这一页讲的是 MYCIN 的生产规则。它通过布尔条件判断是否触发规则,并使用符号推理来生成新的事实。
这一页讲的是 MYCIN 的生产规则。MYCIN 是一种基于规则的专家系统,其生产规则由多个谓词(Boolean predicates)组成,用来判断规则是否触发(fire)。规则的前提(premise)是这些谓词的组合,每个谓词比较患者相关的数据字段与定性值,例如「[stain of the organism] = gram negative」。虽然系统能够自动推理,但仍需要人类专家确定某些复杂的事实,例如微生物的形态是否为 rod(杆状)。规则的作用是生成新的事实,帮助完成目标或子目标,这是符号推理(symbolic reasoning)的典型应用,强调概念性处理而非数值公式。幻灯片中的例子展示了一条具体规则:如果微生物的染色结果是革兰氏阴性(gram negative),形态是杆状(rod),且是厌氧的(anaerobic),系统会根据 0.6 的支持证据推断该微生物可能是拟杆菌(Bacteroides)。这个例子说明了规则如何通过条件组合得出结论,体现了 MYCIN 的推理机制。
这一页讲的是 MYCIN 产生式规则(Production Rule)的结构与符号推理的本质。一条 MYCIN 规则由两部分组成:前提(premise)和结论(action)。前提是若干谓词的合取——每个谓词把某个病人相关字段(如染色结果、形态、需氧性)与一个定性值做比较。当所有前提谓词都成立时,规则就"触发(fire)",产生一条关于微生物身份的新事实。页面给出的例子是:如果微生物染色为革兰氏阴性、形态为杆状、需氧性为厌氧,那么有 0.6 的可信度认为该微生物是拟杆菌(Bacteroides)。注意那个 0.6——这就是置信因子(Confidence Factor, CF),是 MYCIN 处理不确定性的核心机制。符号推理的要义在于:系统操作的是概念符号,而不是数字运算;每条规则对应一段领域专家知识,知识与推理代码分离。考试常见考法:给你一条规则,问它是什么类型的推理;或者给前提真值,让你算结论的 CF。易错点:很多同学误以为 IF-THEN 规则是充要条件——实际上这里的 IF 只是充分条件,结论成立不代表前提必然成立;另外 CF 不是传统概率,不能当作 P(A) 直接用贝叶斯定理处理。整体来说这一页是理解 MYCIN 其他所有机制的入口,必须牢固掌握。
这一页讲的是规则在 LISP 中的实现,展示了内部表示和计算规则的置信度CF模型。
这一页讲的是规则在 LISP (List Processing Language) 中的实现。首先,规则的实现采用了LISP语言,这是一种灵活且适合逻辑处理的编程语言。用户界面虽然提供了更易理解的翻译,但仍然与底层实现保持接近。系统在运行过程中,规则数量逐渐增长到约200条。页面中展示了一个内部表示的例子,包括前提(PREMISE)和行动(ACTION),例如前提包含多个条件的逻辑组合,行动则是一个具体的结论操作。置信度(CF, Certainty Factor)的计算公式也被详细列出:结论的CF等于前提的CF乘以规则的CF;如果条件A推出B,则B的CF等于A的CF;如果多个条件A、B、C联合推出D,则D的CF等于这些条件CF的最小值乘以规则的CF。这种计算方法可以帮助系统在逻辑推理中处理不确定性。例如,如果某规则的前提置信度较低,那么即使规则本身置信度较高,最终结论的置信度也会受到影响。这种设计提高了系统在复杂推理中的可靠性和灵活性。
这一页讲的是 MYCIN 规则在 LISP 内部的实现方式,以及置信因子(CF)的传播计算公式。规则在 LISP 里被表示为两个字段:PREMISE 是一个 $AND 表达式(各个谓词合取),ACTION 是 CONCLUDE 语句,最后跟一个数字 TALLY 表示规则本身的 CF。CF 的计算逻辑分两种情况:第一种是单条件触发——结论 CF 等于前提 CF 乘以规则 CF;第二种是多条件合取触发——前提 CF 取所有条件 CF 的最小值(即最弱一环),再乘以规则 CF 得到结论 CF。用公式口语说:CF(结论) 等于 min(CF(A), CF(B), CF(C)) 再乘以 CF(规则)。直觉上,AND 合取的可信度不能超过最不确定的那一条,就像木桶最短板。举例:若三个条件的 CF 分别是 0.9、0.5、0.7,则前提 CF 为 0.5,规则 CF 为 0.6,结论 CF 为 0.5 乘 0.6 等于 0.3。考试最爱考这个计算,题目给几个条件的 CF 和规则 CF,让你算最终结论 CF。易错点一:忘记取 min 而改为取均值或相乘;易错点二:把 CF 误理解为概率——CF 可以为负(表示反向证据),而概率不能为负。掌握这套公式是做 MYCIN 计算题的基础。
这一页讲的是 LISP 编程语言的特点及一个示例代码。主要包括 LISP 基于列表的结构、代码和数据的统一表示,以及前缀表示法的使用。
这一页讲的是 LISP 编程语言的特点及其历史背景。LISP 是一种基于列表的编程语言,列表可以包含符号、数字或嵌套列表。在经典 LISP 中,代码和数据都采用统一的列表表示,这种设计使得代码可以像数据一样操作,非常灵活。它使用前缀表示法,例如表达式 (+ 1 2) 的结果是 3。幻灯片还展示了一个计算阶乘的 LISP 示例代码:(defun factorial (N) ...),定义了一个递归函数,用来计算 N 的阶乘。如果 N 等于 1,返回 1;否则返回 N 乘以 (N-1) 的阶乘。最后提到 LISP 起源于 20 世纪 60 年代,并且至今仍有应用,比如 Common Lisp。这个语言的设计理念对人工智能领域和函数式编程影响深远。
这一页讲的是在 LISP 中创建和求值列表的操作。主要包括 cons 添加元素到列表前端、list 构建列表、setq 赋值操作,以及 eval 求值功能。
这一页讲的是在 LISP 编程语言中如何创建和求值列表。首先,cons 用于将一个元素添加到列表的前端,例如 (cons 'a (cons 'b '())) 结果是 (A B)。而 list 则直接构建一个列表,例如 (list 'a 'b) 也会生成 (A B)。setq 是 set 和 quote 的结合,用来给变量赋值,例如 (setq form1 '(+ 1 2 3)) 将一个表达式赋值给变量 form1。eval 则用于对表达式求值,例如 (eval form1) 会计算表达式 (+ 1 2 3) 的结果,得到 6。此外,幻灯片还提到了一些关键点,例如 ' 表示引用数据而非求值,'() 表示空列表。最后提到 MYCIN 系统利用列表构建和求值的能力,允许在咨询过程中接受新的生产规则并执行它们。这展示了 LISP 在动态构建和计算中的强大功能。
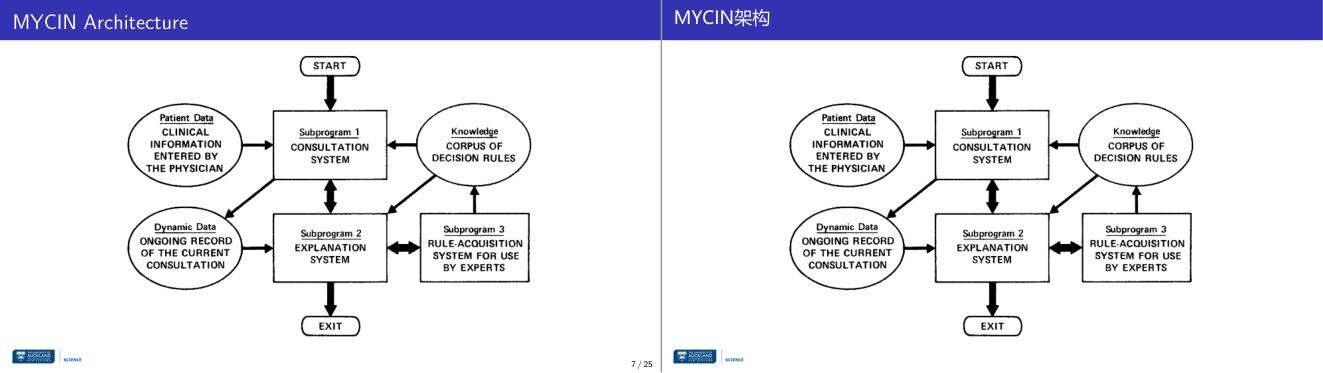
这一页讲的是MYCIN系统的架构。主要包括三个子程序:咨询系统、解释系统和规则获取系统,以及它们如何与患者数据、动态数据和知识库交互。
这一页讲的是MYCIN系统的架构,它是一个早期的医学专家系统,用于支持临床决策。MYCIN的架构由三个核心子程序组成:咨询系统(Consultation System)、解释系统(Explanation System)和规则获取系统(Rule-Acquisition System)。咨询系统接收医生输入的患者数据(Patient Data),如临床信息,并结合动态数据(Dynamic Data),即当前咨询的记录,进行诊断建议生成。解释系统负责提供诊断建议的详细说明,帮助医生理解系统的决策过程。规则获取系统由专家使用,用于扩展和维护知识库(Knowledge Corpus of Decision Rules),即系统的决策规则集合。流程图显示了这些组件之间的交互关系:从“开始”到“结束”,咨询系统是核心,连接患者数据、动态数据和知识库,同时与解释系统和规则获取系统双向交互。举例来说,医生输入患者症状后,系统会结合知识库中的规则生成诊断建议,并通过解释系统解释为什么选择这些建议。这种架构体现了模块化设计,便于知识更新和系统扩展。
这一页讲的是MYCIN系统架构,包括工作记忆和知识库的功能及三个子程序的交互。
这一页讲的是MYCIN系统架构,重点是系统如何处理医疗数据和决策。MYCIN是一个早期的专家系统,用于医疗诊断。图中展示了系统的流程:从“START”开始,医生输入患者数据(Patient Data),包括临床信息;动态数据(Dynamic Data)记录当前咨询的进展,这两部分构成了工作记忆(Working Memory),类似短期记忆,根据用户输入和规则触发实时更新。知识库(Knowledge Base)则是系统的长期记忆,包含决策规则(Corpus of Decision Rules),定期更新以保持准确性。系统包含三个子程序:1. Consultation System(咨询系统),处理医生输入并与知识库交互;2. Explanation System(解释系统),用于解释决策过程;3. Rule-Acquisition System(规则获取系统),专家用来更新和扩展知识库。整个流程通过子程序的协作完成诊断和建议。比如,医生输入患者症状后,咨询系统会调用知识库中的规则生成诊断建议,解释系统则可以向医生说明建议的依据。这种架构体现了专家系统的模块化设计和高效数据处理能力。
这一页讲的是 MYCIN 的系统架构,包括知识库(Knowledge Base)和工作内存(Working Memory)的角色分工。知识库是持久性的,类似人类的长期记忆,存储所有产生式规则,跨越多次会诊不会丢失,只有专家定期维护时才更新。工作内存是每次会诊专有的,类似短期记忆,随着用户输入和规则触发不断更新,一次会诊结束后清空。此外架构还包括:推理引擎(Inference Engine)负责控制推理过程;解释系统(Explanation System)支持 WHY/HOW 查询;规则获取系统(Rule Acquisition System)允许专家编辑规则。这种架构设计的精髓是:知识与推理代码彻底分离。这与传统编程不同——传统程序的逻辑硬编码在代码里,改一个业务规则就要改代码;而 MYCIN 的规则是数据,可以独立编辑。考试常考:知识库和工作内存的区别,以及为什么这种分离是革命性的。另一个高频考点是 MYCIN 成为第一个专家系统外壳(Expert System Shell)的意义——去掉医学领域知识,剩下的推理引擎和界面可以被复用到其他领域,这就是后来的 E-MYCIN。易错点:不要混淆知识库(静态规则)和工作内存(动态事实)。
这一页讲的是 MYCIN 的可重用架构及其影响。MYCIN 提供了首个专家系统 shell,可以替换领域知识解决不同问题。E-MYCIN 后来用于实现其他专家系统。
这一页讲的是 MYCIN 专家系统的可重用架构及其革命性意义。MYCIN 的 Consultation(咨询)、Explanation(解释)和 Rule-Acquisition(规则获取)模块并不局限于医疗领域,而是提供了首个专家系统 shell(系统框架)。这种架构允许替换领域知识,使用相同的软件结构解决不同的问题,这是一个突破,因为传统上计算机程序通常针对特定问题编写。图中展示了 E-MYCIN 的结构,包括一个专家系统框架(Expert System Skeleton)、一个空的知识库(Empty Knowledge Base,由构建者提供),以及 MYCIN 的推理引擎(Inference Engine,用于应用知识)。这种设计使得 E-MYCIN(“空的 MYCIN”)能够被用于构建其他领域的专家系统。例如,开发者可以通过填充新的领域知识库,快速实现一个新的专家系统。这种架构的意义在于极大地提高了系统开发的灵活性和效率。
这一页讲的是推理引擎的作用及 MYCIN 系统中的 MONITOR 和 FINDOUT 功能。重点包括推理引擎负责逻辑推理,MONITOR 负责规则扫描,FINDOUT 用于补充未知值。
这一页讲的是推理引擎(Inference Engine)的功能及其在 MYCIN 系统中的具体实现。推理引擎是系统中的逻辑推理部分,与知识库(knowledge)不同,它负责处理规则和逻辑关系。MYCIN 系统中有两个关键功能:MONITOR 和 FINDOUT。MONITOR 的作用是扫描可用规则,如果某条规则的前提条件为假,该规则会被丢弃。例如,若规则中的某个条件(由 AND 连接)为假,则整个前提条件为假。若某些前提值未知,推理引擎会调用 FINDOUT 功能,它可以从数据库(如实验室结果)或直接询问用户来获取缺失值。此外,MONITOR 和 FINDOUT 可以递归使用,沿着逻辑推理线索,直到推理被证伪或目标被确认。有时用户可能会选择暂时停止某条推理线索,转而处理其他问题,因为回答问题可能会产生成本。这一页强调了推理引擎在知识系统中的重要性,以及 MYCIN 系统如何通过功能模块实现高效推理。
这一页讲的是推理中的前向链推理(Forward Chaining)和后向链推理(Backward Chaining)。前向链推理根据已知数据逐步推出结论;后向链推理从目标出发,逐步验证假设。
这一页讲的是推理的两种方法:前向链推理(Forward Chaining)和后向链推理(Backward Chaining)。前向链推理使用了逻辑规则中的“modus ponens”,即如果前提 p 为真且 p 推导出 q,那么 q 为真。p 可以是多个条件的结合,q 还可能成为其他规则的前提,例如 q 推导出 r。这种方法适合在推理开始前已收集固定数据的场景。后向链推理则是从目标出发,例如确定导致感染的病原体。我们尝试验证实现目标所需的前提,如果某些前提未知,就将其设为子目标(sub-goal)。子目标可以通过触发其他规则递归解决。图中展示了两种推理的流程:前向链推理从事实(Facts)出发,逐步应用规则(Rules)得出结论;后向链推理则从目标(Q)出发,验证相关规则并寻找支持目标的事实。这两种方法在知识推理领域非常重要,前者适合数据驱动场景,后者适合目标导向问题。
这一页讲的是 MYCIN 推理引擎的工作机制,特别是 MONITOR 和 FINDOUT 两个核心函数的协作方式。MONITOR 负责扫描当前可用的规则,对每条规则检查其前提是否成立:如果某个合取条件已知为假,整条规则直接丢弃;如果某个前提值未知,就调用 FINDOUT 去获取它。FINDOUT 的获取路径有两条:一是查数据库(如化验结果),二是直接问用户。关键在于这两个函数是递归调用的——FINDOUT 要获取某个值时,可能触发 MONITOR 去扫描能推导该值的规则,而那条规则的前提又可能触发新的 FINDOUT,如此递归形成深度优先的推理链。这正是后向链(Backward Chaining)的具体实现机制。直觉上可以把推理过程理解为「追根溯源」:我要证明目标 G,找到能得出 G 的规则 R,再去证明 R 的前提,如此递归直到找到已知事实或问到用户为止。考试常问:MONITOR 和 FINDOUT 各自的职责,以及它们的递归调用如何实现后向链。易错点:容易把 MONITOR 理解为正向扫描(forward)——实际上在 MYCIN 语境里,MONITOR 是在目标驱动下寻找能证明目标的规则,本质是后向的。
这一页讲的是两种推理方法:Forward chaining 和 Backward chaining。Forward chaining 从已知事实出发推导结论,Backward chaining 从目标出发验证条件。
这一页讲的是两种推理方法:Forward chaining(数据驱动)和 Backward chaining(目标驱动)。Forward chaining 的特点是从已知事实出发,比如病人有发烧症状,系统会根据规则(如果病人有发烧和皮疹,可能是麻疹)寻找其他相关症状(如皮疹),从而推导出可能的结论。Backward chaining 则是从目标出发,比如网络故障,系统会根据规则(如果路由器故障,网络会中断)逆向验证条件是否成立,最终确认假设是否正确。这两种方法在推理系统中非常重要,前者适用于从数据中发现结论,后者适用于验证假设。举例来说,Forward chaining 可以用于医疗诊断,而 Backward chaining 可以用于故障排查。
这一页讲的是前向链(Forward Chaining)和后向链(Backward Chaining)两种推理策略的原理与适用场景,这是专家系统最核心的考点之一。前向链是数据驱动的:从已知事实出发,用 modus ponens(肯定前件)不断推出新结论。如果 p 为真且 p 推出 q,则 q 为真;q 又可以作为下一条规则的前提继续推导。适合场景是数据已全部收集完毕、目标不明确时,像监控告警系统收到一堆传感器数据自动触发规则。后向链是目标驱动的:从想要证明的假设出发,找到能得出该假设的规则,再去证明那条规则的前提;前提未知就变成子目标递归处理。适合场景是目标明确但数据可能很多,只需按需获取相关数据,像 MYCIN 只问对诊断有用的问题而不是问所有化验。区别口诀:前向链"事实找结论"、后向链"目标找条件"。考试常给一个场景让你判断用哪种链更合适,或者画出推理过程。易错点:后向链的推理方向是从目标往前追溯必要条件,但必要条件不唯一——下一页会强调这点,IF A THEN B 中 A 只是 B 的充分条件,后向链检查的是可能必要条件,不能确定唯一原因。
这一页讲的是 Forward Chaining 和 Backward Chaining 的推理方式及逻辑条件。主要内容包括生产规则的形式、两种推理的方向与特点,以及重要的逻辑注意事项。
这一页讲的是 Forward Chaining 和 Backward Chaining 的推理方式,以及它们在逻辑条件中的应用。生产规则的形式是 IF A THEN B,其中 A 是 B 的充分条件,而 B 是 A 的必要条件。Forward Chaining 的推理方向是从 A 到 B,基于已知事实推导结论,利用充分条件推理出新的事实;而 Backward Chaining 的推理方向是从 B 到 A,从目标出发尝试证明它,通过检查必要条件是否满足来进行推理。重要注意事项包括:IF A THEN B 并不意味着 A 是 B 的唯一原因;Backward Chaining 的目标是识别可能的必要条件,而非唯一条件。这两种推理方式在人工智能推理系统中非常重要,例如 Forward Chaining 常用于数据驱动的推理,而 Backward Chaining 则适合目标驱动的推理。
这一页讲的是前向链与后向链关于充分条件和必要条件的逻辑关系,这是一个容易混淆的逻辑细节,考试爱出陷阱题。对于产生式规则 IF A THEN B:逻辑上 A 是 B 的充分条件(A 成立足以推出 B)、B 是 A 的必要条件(B 成立是 A 成立的必要前提)。前向链方向是 A 推 B,用的是充分条件——知道下雨就能推出地面湿;后向链方向是从 B 往回追 A,检查 A 是否成立,但这里只是在验证一个可能的必要条件,并不能确认 A 是唯一原因。关键提醒:IF 下雨 THEN 地面湿,并不意味着地面湿的原因只有下雨——洒水车也能让地面湿。所以后向链识别的是「可能的必要条件」,而非「唯一充分必要条件」。这意味着 MYCIN 的后向链得到的诊断也是带不确定性的,这也是为什么需要 CF 来量化可信度。考试常见陷阱:给你 IF A THEN B,问「B 成立时 A 一定成立吗」——答案是不一定,因为可能存在其他能推出 B 的规则。另一个陷阱:把充分条件和必要条件弄反。记住:充分→能推出结论;必要→结论成立时需要检查它是否满足。
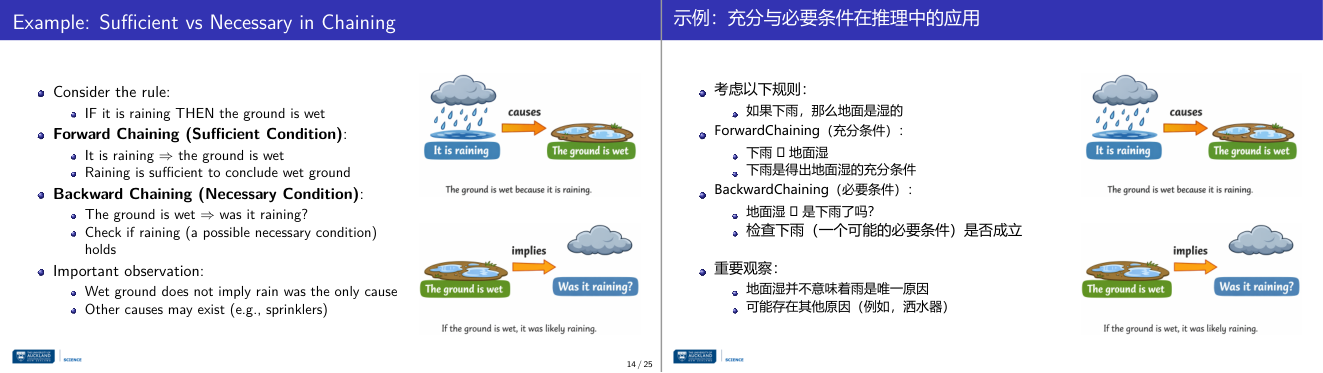
这一页讲的是充分条件与必要条件在链式推理中的应用。重点包括正向链式推理(Forward Chaining)和反向链式推理(Backward Chaining)的区别,以及湿地面可能有多种原因的观察。
这一页讲的是充分条件(Sufficient Condition)与必要条件(Necessary Condition)在链式推理中的应用。首先,规则是“如果下雨(It is raining),那么地面是湿的(The ground is wet)”。正向链式推理(Forward Chaining)指从充分条件出发:下雨可以推导出地面湿,因为下雨是导致地面湿的充分条件。而反向链式推理(Backward Chaining)则从必要条件出发:地面湿时,我们需要检查是否下雨,因为下雨可能是地面湿的必要条件。图中通过两种箭头分别展示了因果关系和推导关系:下雨导致地面湿(因果关系),而地面湿可能意味着下雨(推导关系)。最后,重要观察指出,地面湿并不一定是因为下雨,还可能有其他原因(例如洒水器)。这强调了必要条件并不等同于充分条件。例如,如果地面湿了,我们不能直接断定一定是下雨导致的。这种区分在逻辑推理和因果分析中非常重要。
这一页讲的是 MYCIN 的逆向推理 (Backward Chaining) 方法。重点包括它如何通过启发式问题开始咨询、利用信心因子 (Confidence Factor, CF) 引导推理,以及在 CF 低于阈值时放弃某条推理路径。
这一页讲的是 MYCIN 系统中的逆向推理 (Backward Chaining) 方法。首先,MYCIN 会通过一组启发式选择的问题开始咨询,这些问题通常涉及两类信息:一是为得出结论所需的关键信息,二是能够排除较少可能结论的信息。接着,MYCIN 进入逆向推理模式,以尝试证明具体目标。该系统使用信心因子 (Confidence Factor, CF) 作为指导,并从最有可能被证明的目标开始。例如,若系统有多个结论:Bacteroides (CF=0.8)、E. coli (CF=0.6) 和一种稀有细菌 (CF=0.2),它会从 CF 最高的 Bacteroides 开始推理。此外,当某条推理路径的 CF 降至 0.2 以下时,系统会放弃该路径。幻灯片中给出了一个推理链的示例:结论 → 条件1 → 条件2 → 条件3,其中 CF 的计算过程为:CF(条件1) = CF(初始) × CF(规则) = 0.5 × 0.6 = 0.3;CF(条件2) = CF(条件1) × CF(规则) = 0.3 × 0.6 = 0.18,因低于阈值 0.2 而被放弃。这种方法确保系统能更高效地集中资源于最可能的推理路径。
这一页讲的是 MYCIN 后向链的具体执行策略,包括如何选择起始目标、如何利用置信因子 CF 剪枝,以及何时放弃一条推理链。MYCIN 进入后向链之前会先问一组启发式选定的初始问题覆盖常见情况,然后才开始目标导向推理。在有多个候选诊断时,MYCIN 优先从 CF 最高的目标开始证明——比如 Bacteroides(CF=0.8)、E. coli(CF=0.6)、罕见菌(CF=0.2),先攻 Bacteroides。沿着推理链往下,每一步都要乘以规则 CF,CF 会不断衰减。当推理链某节点的 CF 低于阈值 0.2 时,MYCIN 放弃这条链(剪枝)。页面给出了具体计算:起始 CF=0.5,规则 CF=0.6,条件1的 CF 等于 0.5 乘 0.6 等于 0.3;条件2的 CF 等于 0.3 乘 0.6 等于 0.18,低于 0.2,因此放弃。直觉上这很像搜索中的剪枝——置信度越来越低的推理链耗费资源却不可能有高可信结论,提前放弃是合理的。考试会给一条推理链和各步 CF,让你算出哪步被剪掉。易错点:别忘了每一步的 CF 都要乘以那一步用到的规则 CF,不是只乘一次初始值。
这一页讲的是 MYCIN 系统的解释功能,包括 WHY 和 HOW 查询,以帮助医疗专业人员理解系统推理过程。WHY 查询用于解释目标驱动的推理,HOW 查询用于解释数据驱动的推理。
这一页讲的是 MYCIN 系统的解释功能,强调透明性对于医疗专业人员信任系统建议的重要性。MYCIN 支持两种查询:WHY 查询和 HOW 查询。WHY 查询(goal-driven explanation)用于回答系统为何需要某个前提值,解释推理过程中的子目标,并与逆向链推理(backward chaining)密切相关。例如,用户问“为什么要判断这个生物是否是厌氧的?”系统回答“因为我需要判断它是否是 Bacteroides,而这需要知道它是否是厌氧的。”HOW 查询(data-driven explanation)则解释系统如何根据已知事实得出结论,类似于正向链推理(forward chaining),但重点在于推理的说明。例如,用户问“你如何得出这是 Bacteroides 的结论?”系统回答“因为它是革兰氏阴性、杆状、厌氧,因此是 Bacteroides,置信度为 0.6。”这些查询功能使医疗人员能够深入了解系统的推理逻辑,从而更好地做出最终决策。
这一页讲的是 MYCIN 的解释功能(Explanation Capability),具体是 WHY 查询和 HOW 查询的工作原理与区别。解释能力被认为是临床医生信任系统推荐的前提——医生对病人的治疗负最终责任,所以需要理解系统的推理依据。WHY 查询是目标导向的解释:当系统提问时,用户问「为什么问这个」,系统回答「因为我正在尝试证明目标 G,而这个问题的答案是 G 的前提」;继续追问 WHY 可以沿着后向链一层层向上追溯到高层目标。HOW 查询是事实导向的解释:用户问「你怎么得出这个结论的」,系统列出触发结论的那条规则的所有前提以及它们的 CF,像是前向链的回放。两者的对比:WHY 追的是「还需要什么才能证明目标」(后向方向);HOW 追的是「哪些已知事实导致了这个结论」(前向方向的解释)。这种解释能力在现代 AI 的可解释性(Explainability/XAI)讨论中仍然高度相关——MYCIN 是最早把可解释性作为系统设计目标的 AI 之一。考试常问 WHY 和 HOW 的区别,以及它们各自与哪种链对应。易错点:不要把 WHY 和 HOW 搞反;WHY 是向前(目标方向)追,HOW 是向后(事实方向)追。
这一页讲的是 WHY 与 HOW 的区别及推理方式。WHY 关注问题为何被提出,HOW 关注结论如何得出。
这一页讲的是 WHY 和 HOW 的区别,以及两种推理方式的应用。WHY(Backward Chaining Style)解释为什么提出某个问题,通常从目标出发,回溯需要的条件。例如,为了判断地面是否湿,系统会问“是否下雨?”因为下雨是地面湿的必要条件。HOW(Forward Explanation Style)解释结论是如何得出的,通常从已知事实开始推导。例如,已知事实是“正在下雨”,系统应用规则“如果下雨,那么地面湿”,从而得出地面湿的结论。页面最后总结了两者的核心区别:WHY 是从目标追溯到所需事实,HOW 是从事实推导到结论。这种区分对于理解推理系统的工作方式非常重要,帮助我们设计更高效的逻辑推理过程。
这一页讲的是 MYCIN 系统的评估方法与结果。重点包括专家组的评价、与人类专家一致性,以及未能进一步验证的原因。
这一页讲的是 MYCIN 系统的评估过程及其局限性。首先,MYCIN 的评估通过专家组和真实病例进行。研究准备了 15 名血液培养阳性患者的摘要,由 10 名感染疾病领域的医生(5 名来自斯坦福,5 名来自其他机构)对每个病例回答三个问题:病原体的重要性(是否需要治疗)、病原体身份以及治疗方案。结果显示 MYCIN 与专家组的意见高度一致,甚至与专家之间的意见一致性相当。评估该系统的一种方法是比较它与人类专家的意见一致性,另一种方法是验证使用 MYCIN 的临床医生是否能取得比未使用者更好的健康结果,但这需要控制其他因素的影响。然而,MYCIN 未能达到这一验证阶段,原因包括医学责任问题、法律风险、伦理问题以及医生对机器推荐的信任不足等。这些限制反映了早期人工智能在医疗领域应用的挑战。
这一页讲的是 MYCIN 的评估方法及其结果的意义,以及专家系统最终未能在医疗领域大规模落地的原因。评估方案设计很严谨:准备 15 位真实住院病人的病历摘要,邀请 10 位传染病专科医生(5 位来自斯坦福,5 位来自外部)对每个病例给出判断,涵盖微生物重要性、身份识别和治疗方案三个维度。结果发现 MYCIN 与专家的一致程度,和专家之间互相的一致程度差不多——这是一个很强的结论,意味着 MYCIN 达到了专家级别的表现。但 MYCIN 最终没有走向临床实践,核心阻碍包括:医疗责任归属问题(谁为 AI 的错误决策负责)、法律风险、对机器推荐缺乏完全信任、以及知识库维护成本。这揭示了专家系统的一个普遍困境:技术上可行不等于社会和制度上可行。考试可能问:MYCIN 的评估方式是什么、为什么没有普及、以及评估专家系统还有哪些其他方法(比如衡量使用 MYCIN 的医生的实际治疗效果)。易错点:不要只答技术局限,要答到医疗责任和伦理这类非技术障碍。
这一页讲的是专家系统(Expert Systems)的意义及局限性。专家系统能帮助人类专家回忆知识,处理复杂问题,但在医学领域未被广泛采用,且难以全面编码专家知识。
这一页讲的是专家系统(Expert Systems)的作用和局限性。专家系统的主要优势在于模拟人类专家的能力,帮助专家回忆与当前案例相关的知识。人类容易出现记忆“遗漏”,而计算机的记忆一致且不会疲劳。此外,计算机可以维护更大的工作记忆并快速搜索大型知识库,而人类一次只能处理约 7 个“块”的信息,通常需要借助白板等工具解决复杂问题。专家系统在某些场景下尤其重要,例如前线护理、灾难和战场等专家不可用的情况。然而,专家系统并未在医学领域成为主流,其原因包括医疗专业人员仍需承担最终责任,专家系统更多被用作决策支持系统(Decision Support System)来提供帮助。此外,全面编码所有专家知识仍然非常困难。举例来说,在医疗诊断中,专家系统可以为医生提供相关症状的可能性,但医生仍需根据实际情况做出最终判断。
这一页讲的是知识获取的瓶颈问题。主要内容包括专家知识输入的局限性、知识的动态变化以及知识库的不完美性。
这一页讲的是知识获取的瓶颈问题。首先,期望领域专家将所有知识直接输入系统是不现实的。以 MYCIN 为例,它的知识获取工具主要支持专家对规则的审查,或者在预设概念中进行有限的调整。其次,知识是动态变化的,例如,如果今天运行 MYCIN,它仍然停留在 1970 年代的医学水平,而现代医学有新的药物、新的临床证据以及抗生素耐药性等新问题,即使知识库非常完善,也需要不断维护。最后,知识库本身从未达到完美状态。在 1970 年代,人们认为可以通过增加规则解决问题,但 Shortliffe 在 1974 年指出规则数量已经达到 200,并且未来还会增加。此外,大型生产规则系统调试难度极高。这些问题说明知识获取和维护的复杂性,以及知识库系统需要持续改进的必要性。
这一页讲的是知识获取瓶颈(Knowledge Acquisition Bottleneck),这是专家系统最根本的局限性之一,也是整个第一次 AI 冬天的重要成因。核心问题有三层:第一,知识是动态的——医学在不断进步,新药、新证据、新病原体(如抗生素耐药菌)不断涌现,1970 年代写入的规则到今天基本已经过时;第二,专家知识难以完整外化——大量领域知识是隐性的(tacit knowledge),专家自己也说不清楚所有判断依据,让他们直接写规则既费时又不完整;第三,大型规则库极难调试——规则之间可能存在冲突、覆盖、循环依赖,随着规则数量增长(MYCIN 有约 200 条)调试难度指数级上升。这个瓶颈说明了为什么专家系统没有成为「通往强 AI 的道路」——不是方向不对,而是可扩展性存在根本性障碍。考试常问:什么是知识获取瓶颈,以及它对专家系统发展有何影响。易错点:有同学认为「加更多规则就能解决问题」——实际上 Shortliffe 在 1974 年就已经意识到这不是正确方向,规则越多系统越难维护。这也是后来机器学习(从数据自动学习规则)兴起的重要动机之一。
这一页讲的是语义网络的发展及相关技术的进展,包括 RDF、OWL、Wikidata 的作用,以及 IBM Watson 和 GPT 模型的特点与局限性。
这一页讲的是语义网络(Semantic Web)及其相关技术的发展。语义网络的目标是通过结构化数据和关系来增强网络信息的意义表达,其中 RDF(Resource Description Framework)用于指定元数据,OWL(Web Ontology Language)用于定义关系以支持推理,而 Wikidata 则提供了一个与 Wikipedia 对应的结构化知识库。这些技术为信息的组织和推理奠定了基础。随后,IBM Watson 在 2011 年后展示了系统读取自然语言并回答问题的潜力,证明了人工智能在处理复杂语言任务上的进步。然而,GPT 风格的模型虽然展现了广泛的语言生成能力和流畅性,但它们的机制与显式符号推理不同,因此在需要多步推理时可能会出现显著的逻辑错误。例如,GPT 模型可能在回答复杂问题时遗漏关键步骤或产生不一致的结论。这一页的内容强调了从语义网络到现代 AI 模型的技术演变及其各自的优势与局限性。
这一页讲的是生产规则的实际应用。重点包括 Drools 和 Nools 作为业务规则引擎的优势、典型应用场景以及区域性规则差异。
这一页讲的是生产规则(Production Rules)的实际应用。Drools(基于 Java 的服务器端)和 Nools(基于 JavaScript/Node.js)是两种业务规则引擎,它们相比直接硬编码复杂逻辑,提供了更好的软件工程实践。这些工具特别适合处理经常变化或因地区而异的政策。典型应用场景包括金融和医疗领域,尤其是健康保险;保险权益因计划而异;由政府政策(如 Medicare)决定的规则;以及特定地区的就业规则。在新西兰和澳大利亚,养老金(superannuation)和休假权益可能因司法管辖区不同而有所差异。此外,反向推理(backward chaining)还可以支持“软性”推荐任务,例如根据客户需求推荐合适的保险政策、房贷或投资选项。这些应用展示了业务规则引擎在动态政策管理和区域差异处理中的重要性。
这一页讲的是 MYCIN 的突破性贡献及其局限性。MYCIN 展现了规则操作化和假设测试的能力,并推动了专家系统的思考方向。
这一页讲的是 MYCIN 的突破性贡献及其局限性。MYCIN 是一种专家系统,它通过规则的操作化完成了通常需要专业人士才能完成的任务,并展示了类似侦探式的假设测试能力(hypothesis testing),利用了逆向推理(backward chaining)。此外,它提供了一个可重复使用的框架,可以基于不同的知识库进行扩展。虽然 MYCIN 的成就令人瞩目,但它的局限性也促使研究者认识到专家系统并不是实现大规模高级人工智能的实际路径。这些系统虽然无法推动通用人工智能(general AI)的突破,但在自动化复杂政策和结构化选项排序方面仍然具有实际价值。同时,MYCIN 还引发了对人类与 AI 系统责任问题的深入思考。例如,它让研究者意识到在设计 AI 系统时需要明确责任归属,以避免潜在的伦理问题。
这一页讲的是 AI 的下一阶段发展方向,重点是概率、不确定性和近似计算。
这一页讲的是 AI 的下一阶段发展方向,强调了 MYCIN 系统中的信心因子(confidence factor)概念,例如“suggestive evidence (0.6)”。MYCIN 是一个早期的人工智能系统,用于医学诊断,其中信心因子用于表示某一结论的可信度。这种方法表明 AI 不仅仅依赖确定性规则,而是开始处理概率、不确定性和近似计算。下一阶段的 AI 将更加关注如何量化和处理不确定性,例如通过概率模型或模糊逻辑来表达知识和推理。这种转变对于解决复杂问题至关重要,例如诊断中如何综合多个模糊证据来得出结论。举例来说,在医学诊断中,如果某种症状的出现概率为 60%,系统可以结合其他证据进行综合判断,而不是简单地依赖单一规则。这种能力使 AI 更加灵活和智能,适应复杂的现实世界场景。
这一页讲的是参考文献,列出了两篇与 MYCIN 系统相关的研究论文。第一篇讨论了 MYCIN 的规则获取能力,第二篇评估了计算机咨询系统的性能。
这一页讲的是参考文献,重点列出了两篇与 MYCIN 系统相关的经典研究论文。第一篇是 Shortliffe 等人在 1975 年发表的文章,标题为《Computer-based consultations in clinical therapeutics: Explanation and rule-acquisition capabilities of the MYCIN system》,发表在《Computers and Biomedical Research》期刊上。这篇论文分析了 MYCIN 系统在临床治疗中的应用,特别是它的解释能力和规则获取能力。这是人工智能早期在医学领域应用的重要研究之一。第二篇是 Yu 等人在 1979 年发表的文章,标题为《Evaluating the performance of a computer-based consultant》,发表在《Computer Programs in Biomedicine》期刊上。这篇论文评估了计算机咨询系统的性能,进一步探讨了 MYCIN 系统的实际效果。这两篇文献为医学专家系统的研究奠定了基础,展示了人工智能在医疗领域的早期应用成果。