第 1 / 31 页

这一页讲的是软计算(Soft Computing)的主题,包括硬计算与软计算的对比以及模糊逻辑(Fuzzy Logic)和朴素贝叶斯(Naïve Bayes)。
空格=播放/暂停当前页 · Tab=切换 简短/详细/深入 · 红色「深入」为重点页的深度讲解
这一页讲的是软计算(Soft Computing)的主题,包括硬计算与软计算的对比以及模糊逻辑(Fuzzy Logic)和朴素贝叶斯(Naïve Bayes)。
这一页讲的是软计算(Soft Computing),是 COMPSCI 713 课程的第九讲。软计算是一种处理不确定性和模糊性的方法,与硬计算(Hard Computing)形成对比。硬计算通常依赖精确的数学模型和严格的规则,而软计算更强调灵活性和容错性,适合处理复杂和不确定的现实问题。模糊逻辑(Fuzzy Logic)是一种软计算方法,它通过模糊集合和模糊规则来处理不精确的数据,适用于例如自动控制系统中的决策问题。朴素贝叶斯(Naïve Bayes)是一种基于概率的分类算法,假设特征之间独立且简单,但在实际应用中表现出很高的效率和准确性。这些方法在人工智能领域非常重要,因为它们可以帮助解决传统计算无法高效处理的问题。

这一页讲的是Soft Computing的概述,包括与Hard Computing的对比、常见技术地图,以及模糊逻辑和朴素贝叶斯的特点。
这一页讲的是Soft Computing的概述。首先,它强调Soft Computing的核心目标不是追求完美的确定性,而是为了在复杂、不确定的环境中做出有用的决策。与Hard Computing相比,Soft Computing更注重处理模糊性和不确定性。幻灯片还列出了几种常见的Soft Computing技术,包括模糊逻辑(Fuzzy Logic)和朴素贝叶斯(Naïve Bayes)。模糊逻辑是一种基于成员度(degree of membership)的推理方法,适合处理模糊性问题,例如在模糊边界中判断某个值的归属。朴素贝叶斯则是一种概率分类方法,它通过简化假设来进行分类,例如假设特征之间相互独立。最后,幻灯片提到模糊性(vagueness)和不确定性(uncertainty)的对比,帮助理解Soft Computing在处理复杂问题中的独特价值。

这一页讲的是软计算(soft computing)的必要性,强调现实问题常不适合简单的真/假判断。主要讨论数据不完整性、模糊性,以及软计算如何帮助做出足够好且可解释的决策。
这一页讲的是软计算(soft computing)为什么重要。现实生活中很多问题无法用简单的真/假逻辑来回答,例如“这个人是否算高?”、“这个病人是否是高风险?”、“这封邮件是否是垃圾邮件?”等。这些问题通常涉及模糊性、不确定性或数据不完整性,而严格的符号规则在处理这些问题时容易显得脆弱。右侧的流程图展示了软计算如何处理类似“年龄是否大于65?”、“垃圾邮件的程度如何?”、“风险有多高?”的问题,通过近似推理(approximate reasoning)得出结果。软计算的目标是生成足够好、稳健且可解释的决策。这种方法在医疗诊断、垃圾邮件过滤、风险评估等领域非常重要,因为它能处理复杂且模糊的实际场景。例如,判断一个病人是否高风险可能需要综合考虑年龄、病史和其他模糊因素,而不是简单的二元分类。

这一页讲的是硬计算 (Hard Computing) 和软计算 (Soft Computing) 的对比。硬计算强调精确性和确定性,软计算容忍不精确性以解决复杂问题。
这一页讲的是硬计算 (Hard Computing) 和软计算 (Soft Computing) 的对比。硬计算使用明确的符号和精确值进行表示,逻辑严格遵循真/假规则,通常应用于规则明确且输入精确的场景,例如算术运算、编译器和最短路径计算。它的优势在于当模型准确时可以提供精确答案。软计算则采用近似值、概率和模糊度进行表示,逻辑基于部分真理或信念,适用于输入噪声较大、不完整或模糊的场景,例如模糊控制、贝叶斯分类器和神经网络。软计算的强项是面对复杂或混乱的环境时表现出的鲁棒性。这张表格通过对比两者的表示方式、逻辑特点、应用场景和优势,强调了软计算虽然容忍不精确性,但并不意味着弱,而是为了更好地解决实际问题。
这一页讲的是 Hard Computing(硬计算)与 Soft Computing(软计算)的核心对比。这张表格是本讲最重要的骨架,考试最爱考"两者各自的特点是什么"以及"为什么需要软计算"。硬计算追求精确——表示层用的是 crisp symbols(清晰符号)和 exact values(精确值),逻辑层只有 true 和 false 两种取值,适用场景是规则定义良好、输入精确的问题,比如算术运算、编译器、最短路径算法。软计算则用 approximate values(近似值)、degrees(程度值)或 probabilities(概率)来表示,逻辑层允许 partial truth(部分真)或 belief(置信度),适合输入存在噪声、不完整、模糊或不确定的场景,典型例子包括模糊控制、贝叶斯分类器、神经网络。关键直觉:'soft' 不代表弱,而是代表"允许不精确以换取在混乱现实中的可用性"。硬计算在模型完全正确时给出精确答案,软计算在世界本就混乱时给出鲁棒行为。易错点:考生常把软计算和"不严谨"画等号,但实际上软计算有严格的数学基础(模糊集合论、概率论),只是放弃了"输入必须精确"这一限制条件。考试常见题型:给一个场景(比如"判断一封邮件是否是垃圾邮件"),让你说明为什么用软计算而不是硬计算,答题要点就是指出输入特征的模糊性/不确定性以及硬阈值会导致 brittle(脆弱)行为。

这一页讲的是软计算 (Soft Computing) 的定义及应用场景。它处理不确定性、部分真理和近似问题,特别适合噪声环境或模型不精确的情况。
这一页讲的是软计算 (Soft Computing),它是一类专门处理不确定性 (uncertainty)、部分真理 (partial truth)、不精确性 (inaccuracy) 和近似 (approximation) 的方法。与早期人工智能强调严格逻辑和定理证明不同,软计算更灵活,适用于环境噪声较大、专家知识模糊或精确数学模型不可用的场景。幻灯片中列出了软计算的主要方法,包括模糊逻辑 (Fuzzy Logic)、贝叶斯方法 (Bayesian Methods)、神经网络 (Neural Networks) 和遗传/进化算法 (Genetic/Evolutionary Algorithms)。这些方法共同特点是能够在复杂或不确定的环境中提供解决方案。例如,在天气预测中,模糊逻辑可以处理不确定性,而神经网络能够从大量数据中学习模式。这些技术在现实世界中广泛应用于优化问题、数据分析和人工智能领域。

这一页讲的是不确定性(uncertainty)与模糊性(vagueness)的区别。重点包括概率不确定性与模糊逻辑的核心概念及工具。
这一页讲的是不确定性(uncertainty)与模糊性(vagueness)的区别。概率不确定性(Probabilistic uncertainty)关注在信息不完整情况下的信念(belief),例如我们不知道某种疾病是否存在,可以用条件概率 P(disease | symptoms) 来表示。其主要工具是贝叶斯推理(Bayesian reasoning),用于评估事件发生的可能性,回答“how likely?”的问题。模糊性(Fuzzy vagueness)则关注概念边界的模糊程度,例如某人身高 183cm 被认为是“高”的程度 μ_tall(183cm)=0.6。模糊逻辑(Fuzzy logic)是处理这种模糊性的重要工具,它回答的是“to what degree?”的问题。这两者的关键区别在于概率关注事件发生的可能性,而模糊逻辑关注属性或状态的程度。
这一页讲的是 Soft Computing 内部的两种根本不同的"不完美"类型——probabilistic uncertainty(概率不确定性)和 fuzzy vagueness(模糊含混性)。这是本讲最关键的概念区分,也是考试最高频的送分考点之一,很多学生会混淆。概率不确定性说的是:我们不知道世界处于哪种状态,问题是"可能性有多高",比如 P(disease | symptoms),工具是贝叶斯推理。模糊含混性说的是:概念本身的边界就是模糊的,问题是"属于这个概念的程度是多少",比如 µ_tall(183cm) = 0.6,工具是模糊逻辑。举个例子来区分:问"这个人明天会生病吗"——这是概率问题,世界有确定状态,我们只是不知道;问"这个人算高吗"——这是模糊问题,'高'这个概念本身没有清晰边界。直觉上:概率论里 0.6 是指"有 60% 的几率是真的",模糊逻辑里 0.6 是指"有 60% 的程度属于这个集合",两者含义完全不同,不能混用。考试易错点:看到 µ_tall(183) = 0.6,千万不要说"这个人有 60% 的概率是高的",正确说法是"这个人以 0.6 的隶属度属于高的集合"。题型常见:选择题让你辨别哪个情境用模糊逻辑、哪个用概率推理。

这一页讲的是软计算(Soft Computing)的两个重要主题:模糊逻辑(Fuzzy Logic)和贝叶斯推理(Bayesian Reasoning)。
这一页讲的是软计算(Soft Computing)的两个核心方法。首先是模糊逻辑(Fuzzy Logic),它是一种处理不确定性和模糊性的数学方法,允许在模糊边界条件下进行推理。例如,模糊逻辑可以用来判断一个温度是“热”还是“温暖”,而不是简单地分类为“热”或“冷”。其次是贝叶斯推理(Bayesian Reasoning),它基于贝叶斯定理,用概率方法处理不确定性。通过结合先验知识和观察数据,贝叶斯推理能够动态更新对事件发生概率的估计。例如,在诊断疾病时,医生可以根据患者的症状和已知疾病概率来推断最可能的病因。这两种方法都是软计算的重要组成部分,适用于处理传统硬计算无法有效解决的问题,如复杂系统建模和决策支持。
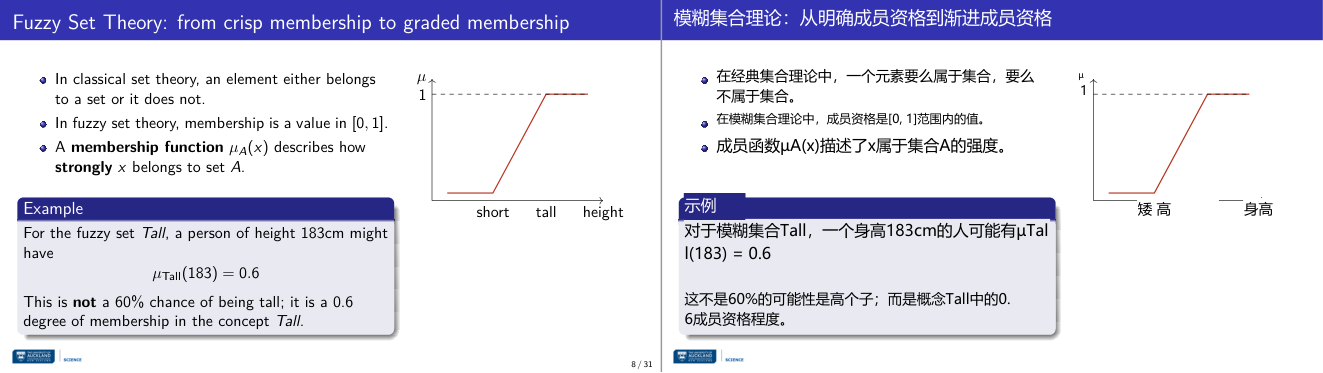
这一页讲的是 Fuzzy Set Theory 的基本概念及其与传统集合理论的区别。重点包括模糊集合中的隶属度范围 [0,1] 和隶属函数 μA(x) 的作用。
这一页讲的是 Fuzzy Set Theory(模糊集合理论),它与传统集合理论的主要区别在于元素的隶属关系。在传统集合理论中,元素要么属于集合,要么不属于集合,隶属关系是二值的。而在模糊集合理论中,隶属度是一个范围在 [0,1] 的连续值,表示元素属于集合的强度。隶属函数 μA(x) 用来描述某个元素 x 在集合 A 中的隶属程度。右侧的图展示了隶属函数的一个例子,其中身高越高,隶属度越接近 1,表明越符合“Tall”的概念。例如,一个身高 183cm 的人可能有隶属度 μTall(183) = 0.6,这表示他在“Tall”这个模糊集合中的隶属程度为 0.6,而不是 60% 的概率属于“Tall”。这种方法可以更灵活地处理现实中的模糊性,例如描述人的身高或其他连续变量。
这一页讲的是 Fuzzy Set Theory(模糊集合理论)的基础——从 crisp membership(清晰隶属)到 graded membership(渐进隶属)的转变。经典集合论里,元素要么属于集合要么不属于,是 0 或 1 的二值判断。模糊集合论里,隶属度是 [0,1] 区间内的连续值,用 membership function(隶属函数)µ_A(x) 来描述 x 属于集合 A 的程度。例子:对模糊集合 Tall,身高 183cm 的人 µ_Tall(183) = 0.6。这里 0.6 是隶属度,不是概率!原理上看,隶属函数可以有各种形状——三角形、梯形、S 形曲线等,由专家根据实际语义来设计。直觉是:现实中"高"和"矮"之间不存在一条精确的分界线,183cm 的人比 160cm 的人更"高",比 210cm 的人更"矮",这种渐进性正好用 [0,1] 的连续值来捕捉。考试考点:要能解释 µ_A(x) 的含义(不是概率!),知道 µ=1 表示完全属于、µ=0 表示完全不属于、0 < µ < 1 表示部分属于。易错:把模糊隶属度和概率混淆,两者用不同数学体系,不满足概率论的加法公理。
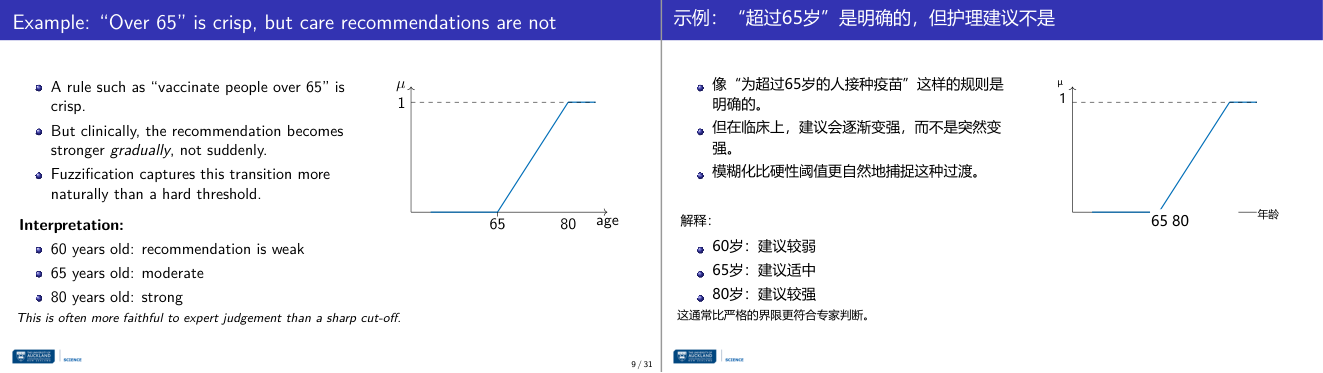
这一页讲的是模糊化(Fuzzification)在年龄相关建议中的应用,强调其比硬性阈值更自然。
这一页讲的是模糊化(Fuzzification)在年龄相关建议中的应用。幻灯片以“65岁以上接种疫苗”的规则为例,说明硬性阈值规则是清晰的(crisp),但在实际临床中,建议的强度是逐渐增强的,而不是突然改变的。模糊化通过引入渐进式的变化,更自然地捕捉了这种过渡过程。右侧的图表展示了年龄与建议强度(μ)的关系:在60岁时,建议强度较弱;65岁时,强度达到中等;80岁时,强度变为强。这种方法比简单的硬性界限更符合专家的判断,能够更好地反映实际情况。模糊化的重要性在于它能处理不确定性和渐变性,使规则更灵活和贴近现实。例如,对于疫苗接种,如果直接规定“65岁以上接种”,可能忽略了部分60岁到65岁之间的人群的需求,而模糊化可以逐步增强建议强度,覆盖更多人群。

这一页讲的是模糊逻辑的组合因素与规则触发。主要内容包括模糊变量及隶属函数、聚合操作符如 AND/OR,以及规则的形式与应用示例。
这一页讲的是模糊逻辑(Fuzzy Logic)中如何通过组合因素触发规则。模糊逻辑的核心包括以下几个部分:模糊变量(fuzzy variables)及其隶属函数(membership functions),用于描述变量的模糊程度;聚合操作符(aggregation operators),例如 AND 和 OR,用于组合多个条件;以及规则的形式,例如 IF x AND y THEN z。页面右侧的流程图展示了一个简单的规则应用:当温度(temperature)为高且湿度(humidity)为高时,风扇速度(fan speed)会变快。假设高温度的隶属度为 0.8,高湿度的隶属度为 0.7,使用常见的模糊 AND 操作,规则触发强度为 min(0.8, 0.7),即 0.7。这说明规则的触发强度取决于输入条件的最低隶属度。这个示例展示了模糊逻辑在处理不确定性和连续变量时的灵活性,例如在环境控制系统中优化风扇速度。
这一页讲的是模糊逻辑中组合多个 fuzzy rules(模糊规则)并计算 rule firing strength(规则激活强度)的机制,以温度控制为例展示了最常用的 fuzzy AND 操作。基本流程:先对输入变量做 fuzzification(模糊化),得到各输入的隶属度;然后用 fuzzy connectives 将条件组合起来;最后得到规则的激活强度,用于决定输出。例子:IF temperature is high AND humidity is high THEN fan speed is fast。已知 µ_high_temp = 0.8,µ_high_humidity = 0.7,fuzzy AND 用 min 算子:激活强度 = min(0.8, 0.7) = 0.7。原理:min 算子对应的是"取最弱的那条件"的逻辑,类似经典逻辑里 AND 的"两个都要成立"。除了 min,还可以用乘积(product)作为 fuzzy AND。实际的模糊控制系统通常有多条规则同时激活,最后需要 defuzzification(去模糊化,比如取加权重心)得到一个精确的控制量输出。考试易错点:fuzzy AND 用 min,fuzzy OR 用 max,fuzzy NOT 用 1 减,要记准。别把 min(0.8, 0.7) 算成 0.8 × 0.7 = 0.56(那是 product T-norm,不是 min)。
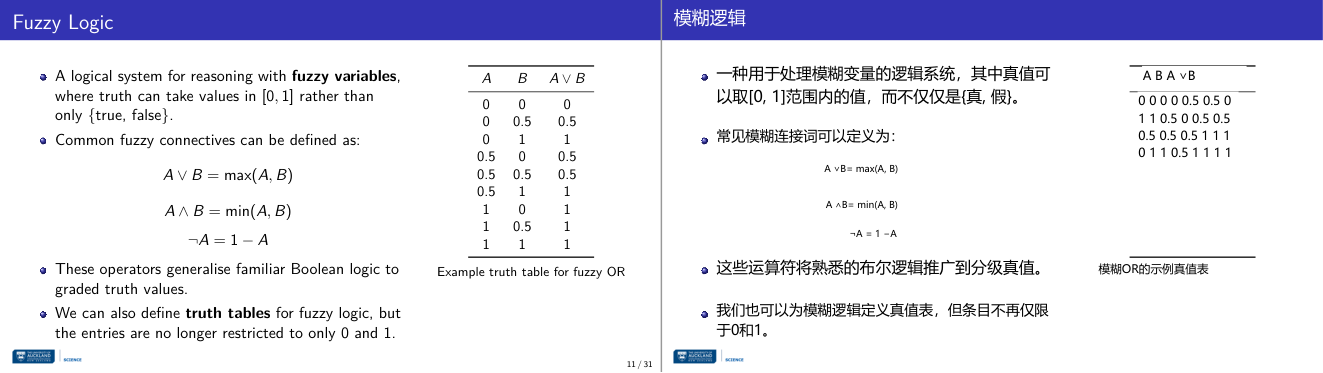
这一页讲的是模糊逻辑 (Fuzzy Logic),它处理真值范围在 [0,1] 的模糊变量。主要介绍了模糊逻辑的常见连接词和模糊真值表的定义。
这一页讲的是模糊逻辑 (Fuzzy Logic),它是一种逻辑系统,用于处理真值范围在 [0,1] 的模糊变量,而不是传统布尔逻辑中的 {true, false}。常见的模糊连接词包括:模糊“或”(A ∨ B)定义为 A 和 B 的最大值;模糊“与”(A ∧ B)定义为 A 和 B 的最小值;模糊“非”(¬A)定义为 1 减去 A。这些操作符将传统布尔逻辑推广到分级的真值范围,使逻辑更灵活。右侧的表格展示了模糊“或”的真值表,其中 A 和 B 的可能值包括 0、0.5 和 1,结果是它们的最大值。例如,当 A=0.5, B=1 时,A ∨ B 的结果为 1。这种真值表不再局限于 0 和 1,而是允许连续的数值,用于表达更细腻的逻辑关系。这种方法在处理不确定性和模糊性的问题中非常重要,例如人工智能中的决策系统。
这一页讲的是 Fuzzy Logic 的基本逻辑运算符——模糊逻辑的 OR、AND、NOT 如何通过数学公式从布尔逻辑推广到连续真值空间,以及对应的真值表结构。公式:A OR B = max(A, B);A AND B = min(A, B);NOT A = 1 减 A。这三个操作是模糊逻辑的最基础构件,满足布尔逻辑的所有基本性质(幂等律、交换律、结合律、德摩根定律等),只是真值从 {0,1} 扩展到 [0,1]。直觉:OR 取最大——两个条件只要有一个强就够了;AND 取最小——两个条件都要成立,瓶颈是最弱的那个;NOT 是 1 的补——完全真的否定是完全假。真值表说明:当 A=0、B=0.5 时,A OR B = max(0, 0.5) = 0.5;当 A=0.5、B=0.5 时,AND = 0.5,OR 也 = 0.5,这和布尔逻辑差异最大,需要理解。考试题型:给出两个隶属度,让你计算 AND 或 OR 或 NOT 的结果,答案要用 min/max/1减,快速选择题的高频考点。易错:有学生用乘法算 AND(把它当联合概率),在模糊逻辑里 AND = min,不是乘积。

这一页讲的是模糊逻辑中的推理。主要介绍模糊逻辑的推理公式、与经典逻辑的对比,以及模糊蕴含算子的真值表。
这一页讲的是模糊逻辑中的推理。首先回顾经典逻辑中,A → B 的定义是 ¬A ∨ B,这表示如果 A 为假或 B 为真,则 A → B 为真。在模糊逻辑中,这一概念被扩展为 A → B = max(1 - A, B),即取 1-A 和 B 的最大值作为结果。这定义了一个模糊蕴含算子。右侧的表格展示了模糊蕴含的真值表,其中列出了不同 A 和 B 值下 A → B 的结果。例如,当 A=0.5 且 B=0 时,A → B 的值为 0.5,这可能与直觉不符,因为我们可能期望结果更接近 0。这表明模糊逻辑推理比经典逻辑更复杂,且结果可能不符合直觉。这种模糊推理在处理不确定性或模糊信息时非常重要,例如在控制系统中应用模糊逻辑可以更灵活地处理连续变量。
这一页讲的是 fuzzy implication(模糊蕴含)运算符的定义与其真值表,核心是把经典逻辑中的蕴含 A→B 等价于 NOT A OR B 推广到模糊情境,得到 A→B = max(1-A, B)。经典逻辑里 A→B 等价于 ¬A ∨ B,用模糊版本替换后就是 max(1-A, B)。验算:A=0, B=0 时,max(1-0, 0) = max(1,0) = 1,符合经典逻辑(假前提推出任何东西都是真);A=1, B=0 时,max(0,0) = 0,符合(真前提推出假结论是假)。但这一页的重点是指出一个反直觉现象:A=0.5, B=0 时,max(1-0.5, 0) = max(0.5, 0) = 0.5。从直觉上,"如果 A 成立但 B 不成立,蕴含应该为假",但这里得到 0.5,感觉不够低,显得不直观。这引出下一页的 Gödel 蕴含作为替代方案。考试要点:能写出 fuzzy implication 的公式,知道它来自哪里(从 NOT A OR B 推广),以及它与经典逻辑的区别(真值不再只有 0/1)。易错:混淆 fuzzy AND 和 fuzzy implication,两者公式完全不同,不要相互混用。
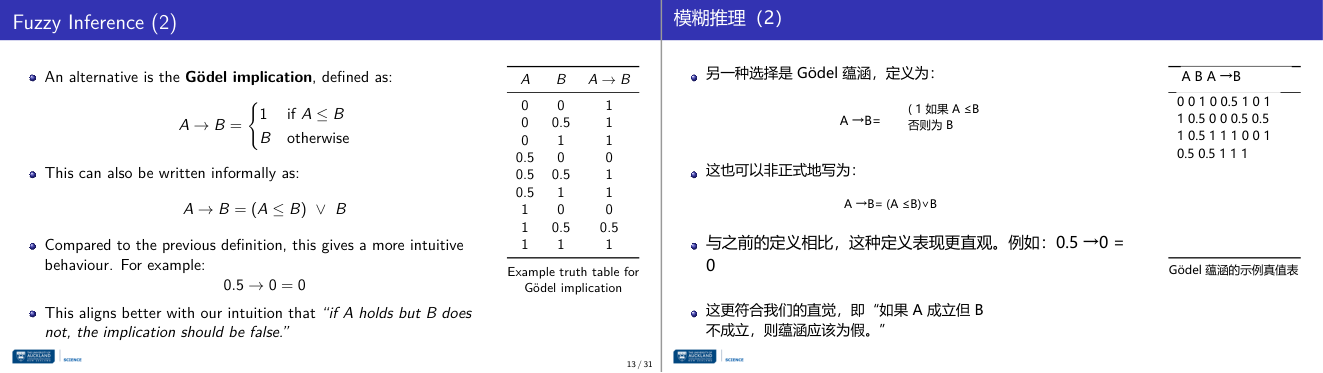
这一页讲的是 Gödel implication,用于模糊推理的替代定义,强调直观性。
这一页讲的是 Gödel implication,它是模糊推理的一种替代定义。公式定义为:如果 A 小于等于 B,则 A → B 等于 1;否则,A → B 等于 B。非正式表达可以写作 A → B = (A ≤ B) ∨ B。这种定义相比之前的模糊推理定义,更符合直觉。例如,当 A=0.5 且 B=0 时,A → B 的结果是 0,表明“如果 A 成立但 B 不成立,那么推理应该为假”。右侧的表格是 Gödel implication 的真值表,列出了不同情况下 A 和 B 的值,以及对应的 A → B 的结果。例如,当 A=1 且 B=0 时,A → B 的值为 0;而当 A=1 且 B=0.5 时,A → B 的值为 0.5。这个定义更好地捕捉了人类对“蕴含关系”的直觉理解,特别是在模糊逻辑中处理不确定性时非常重要。
这一页讲的是 Gödel implication(哥德尔蕴含),它是模糊蕴含的一个替代定义,比上一页的 max(1-A, B) 公式在直觉上更符合"如果前提成立而结论不成立,蕴含应该为假"的期望。Gödel 蕴含的定义:若 A ≤ B,则 A→B = 1;否则 A→B = B。可以用非正式写法表达为:A→B 等于 (A ≤ B) OR B。验算关键案例:A=0.5, B=0 时,因为 A > B,所以结果 = B = 0,完全符合直觉(前提成立但结论为假,蕴含为假)。对比:用 max(1-A,B) 同样情况得 0.5,用 Gödel 得 0,后者更接近我们对"蕴含为假"的直觉。理解:Gödel 蕴含的核心逻辑是"只要前提不超过结论(A ≤ B),蕴含无条件为真(值 1);一旦前提超过结论(A > B),蕴含的强度就退化为结论本身的强度 B"。这在模糊控制规则中有实际意义——规则是否"被违反"由结论的弱程度决定,而不是由前件的强程度决定。考试考点:能填出 Gödel 蕴含的真值表某几行,理解为什么它比 max 公式更直观。易错:计算时忘了先判断 A ≤ B 是否成立,直接用 B 作为结果。

这一页讲的是模糊逻辑(Fuzzy Logic)的应用领域及其在控制系统中的优势。主要包括控制系统、消费设备和决策支持的应用,以及模糊逻辑为何适用于控制场景的原因。
这一页讲的是模糊逻辑(Fuzzy Logic)在实际应用中的表现及其优势。首先,模糊逻辑在控制系统中表现优异,例如自动驾驶仪(包括有人驾驶和无人驾驶的飞机、船舶)、自动变速器以及防抱死制动系统(ABS)。其次,它在消费设备中也有广泛应用,比如洗衣机、吸尘器和冰箱,用于调节温度、功率和湿度等参数。此外,模糊逻辑还用于决策支持,通过结合专家规则和不精确概念来辅助决策。页面还解释了模糊逻辑为何适用于控制场景的原因:它能够直接编码专家启发式规则,不需要精确的数学模型,并且表现平滑,避免了硬阈值下的剧烈变化。例如,在洗衣机中,模糊逻辑可以根据衣物的湿度和重量动态调整洗涤时间和水量,从而提高效率和用户体验。

这一页讲的是模糊控制(Fuzzy Control)的应用,强调不仅要考虑误差(error),还要考虑误差变化率(rate of change)。
这一页讲的是模糊控制(Fuzzy Control)的应用,指出在控制系统中,输入不仅可以基于当前误差 e(t),还可以基于误差的变化率 Δe(t)。误差 e(t) 表示目标值与实际值之间的差距,而误差变化率 Δe(t) = e(t) - e(t-1) 表示误差随时间的变化趋势。这种方法在控制器设计中非常重要。例如,当系统低于目标值时,控制器的反应可能因系统正在接近目标值还是远离目标值而有所不同。页面中的飞机图形举例说明了这一点:飞机在飞行过程中,控制器需要根据飞行路径的变化趋势调整操作,以确保飞行稳定性。这种基于变化率的控制输入可以提高系统的响应效率和稳定性,特别是在动态环境中。

这一页讲的是软计算(Soft Computing)的两个重要主题:模糊逻辑(Fuzzy Logic)和贝叶斯推理(Bayesian Reasoning)。
这一页讲的是软计算(Soft Computing)中的两个核心概念:模糊逻辑(Fuzzy Logic)和贝叶斯推理(Bayesian Reasoning)。模糊逻辑是一种处理不确定性和模糊性的方法,它允许变量具有连续值而不是简单的二元值(如真或假),这在处理现实世界复杂问题时非常有用,例如模糊分类或模糊控制。贝叶斯推理则是一种基于概率的推理方法,它利用贝叶斯定理来更新事件的概率,特别适合处理不确定性和条件概率问题,例如医疗诊断或机器学习中的分类问题。这两种方法都是软计算的重要组成部分,能够帮助我们在复杂、不确定的环境中进行有效的决策。

这一页讲的是贝叶斯推理如何通过证据更新信念。重点包括先验信念、观察证据和计算后验概率。
这一页讲的是贝叶斯推理(Bayesian reasoning),核心在于处理不确定性,通过证据来判断哪种解释最合理。首先从先验信念(prior belief)开始,即在观察证据之前对假设的初始信念。接着观察证据(evidence),然后计算后验概率(posterior probability),即在看到证据后更新的信念。幻灯片中还介绍了贝叶斯定理(Bayes' theorem),公式为 P(H | e) = P(e | H)P(H) / P(e)。其中,P(H) 是假设 H 的先验概率,表示在看到证据之前对 H 的信念;P(e | H) 是在假设 H 成立时观察到证据 e 的可能性;P(H | e) 是后验概率,表示在观察到证据 e 后对假设 H 的更新信念。右侧的流程图展示了从先验信念到证据再到更新信念的过程。关键思想是后验概率与先验概率和似然性成正比。举例来说,如果我们认为某人可能生病(先验信念),观察到其症状(证据),可以通过贝叶斯定理更新我们对其是否生病的信念。
这一页讲的是贝叶斯推理的核心公式——Bayes' theorem(贝叶斯定理),以及其中每一项的含义。公式:P(H|e) = P(e|H) × P(H) / P(e)。逐项解释:P(H) 是 prior probability(先验概率),是在看到证据前对假设 H 的初始信念;P(e|H) 是 likelihood(似然),是在假设 H 成立的条件下看到证据 e 的概率;P(H|e) 是 posterior probability(后验概率),是在看到证据 e 之后对 H 的更新信念;P(e) 是 marginal likelihood(边际概率),通常由全概率公式展开:P(e) = Σ P(e|H_i) × P(H_i),起归一化作用。最关键的直觉:posterior 正比于 prior 乘以 likelihood,即 P(H|e) ∝ P(H) × P(e|H)。贝叶斯推理的本质是"用证据更新信念"——你有初始判断,然后观察新证据,按照证据与假设的兼容程度来调高或调低信念。考试核心:能默写公式,知道每一项叫什么名字,能用全概率公式展开分母,会代数计算。易错点:把 P(e|H) 和 P(H|e) 搞反(两者含义完全不同),以及忘记分母要用全概率公式计算而不是直接给出。

这一页讲的是贝叶斯定理的经典例子,用警报声推断是否发生入室盗窃。重点包括警报的准确率、误报率和区域盗窃率。
这一页讲的是贝叶斯定理的经典应用场景,通过警报声推断是否发生入室盗窃。假设警报检测盗窃的准确率是 0.95,意味着如果确实发生盗窃,警报有 95% 的概率会响起;误报率为 0.01,表示警报在没有盗窃时也可能因其他原因(如雷声或猫)响起;区域盗窃率为 0.0001,即每晚每 10,000 户中约有 1 户可能发生盗窃。这些数据构成了问题的背景,通过贝叶斯定理可以计算警报响起时实际发生盗窃的概率。这个例子强调了直觉可能与实际概率的差异,警报响起并不一定意味着盗窃发生,因为误报率和低盗窃率会显著影响最终的推断。

这一页讲的是贝叶斯定理在报警与盗窃概率中的应用。主要内容包括总概率计算、贝叶斯公式推导,以及结果的解释。
这一页讲的是贝叶斯定理在一个经典案例中的应用:报警声并不一定意味着发生盗窃。首先定义事件 H 为盗窃发生,事件 e 为报警声。已知条件概率 P(e | H) = 0.95,盗窃的先验概率 P(H) = 0.0001,以及非盗窃情况下报警的概率 P(e | ¬H) = 0.01。通过总概率公式计算报警发生的概率 P(e),公式为 P(e) = P(e | H)P(H) + P(e | ¬H)P(¬H),结果为 0.010094。接着应用贝叶斯公式计算盗窃发生的后验概率 P(H | e),公式为 P(H | e) = P(e | H)P(H) / P(e),结果约为 0.0094。最后的解释部分指出,尽管报警声使盗窃的概率增加了近 100 倍,但盗窃的概率仍然小于 1%,因此报警声并不是决定性证据,但它是强有力的证据,能够更新我们对盗窃发生的信念。这一案例直观地展示了贝叶斯定理如何结合先验概率和证据更新后验概率。
这一页讲的是贝叶斯定理的经典计算例子——闹铃响了,到底有没有发生入室盗窃?这个例子直接演示了完整的贝叶斯计算流程,展示了先验概率极低时即使似然较高、后验仍然可能很低(base rate neglect 的反例)。已知数据:P(alarm | burglary) = 0.95(报警器检测到入室盗窃的概率);P(alarm | NOT burglary) = 0.01(误报率);P(burglary) = 0.0001(入室盗窃的基础率,每晚万分之一)。计算步骤:先用全概率公式算 P(alarm) = 0.95 × 0.0001 + 0.01 × 0.9999 = 0.000095 + 0.009999 = 0.010094。然后代入贝叶斯公式:P(burglary | alarm) = (0.95 × 0.0001) / 0.010094 ≈ 0.0094,不到 1%。结论解读:虽然报警器触发了,但入室盗窃的概率依然极低,因为基础率(先验)太低了。不过 0.0094 是原先 0.0001 的将近 100 倍,说明证据确实有效更新了信念,只是基础率的影响太大。这个例子强调了 base rate(基础率)的重要性——忽略基础率是一种常见的认知偏差(base rate neglect)。考试考法:给出三个概率数据,让你用全概率公式和贝叶斯公式算后验概率,务必要记住先算 P(e),再算 P(H|e)。

这一页讲的是 Naïve Bayes 分类器的基本原理。重点包括贝叶斯公式的应用、条件独立假设以及特征向量的定义。
这一页讲的是 Naïve Bayes 分类器的基本原理。首先,贝叶斯公式用于计算某输入 x 属于某类别 c 的概率,公式为 P(C = c | x) = P(C = c)P(x | C = c) / P(x)。其中 P(C = c) 是类别的先验概率,P(x | C = c) 是特征向量在给定类别下的条件概率,P(x) 是特征向量的总概率。Naïve Bayes 的核心假设是特征在类别给定的条件下是独立的,因此 P(x | C = c) 可以近似为各特征条件概率的乘积,即 P(x | C = c) ≈ ∏ P(xi | C = c)。接着,c 是类别标签,例如垃圾邮件与非垃圾邮件,x 是特征向量,描述一个实例的所有特征,xi 是特征向量中的第 i 个特征,例如某词是否出现在邮件中或某应用是否尝试更改文件权限。这个分类器简单高效,适合处理文本分类等问题,例如垃圾邮件检测。
这一页讲的是 Naïve Bayes classifier(朴素贝叶斯分类器)的数学公式推导,核心是引入了条件独立性假设(conditional independence assumption),从而把联合概率 P(x|C=c) 分解为各特征概率的连乘积。问题设定:输入特征向量 x = (x_1, ..., x_n),要分配到类别 c ∈ C。贝叶斯公式给出 P(C=c|x) 正比于 P(C=c) × P(x|C=c)。难点在于 P(x|C=c) = P(x_1, x_2, ..., x_n | C=c),这是 n 个特征的联合分布,参数量指数级增长(2^n 个参数),数据量根本不够估计。"朴素"假设(Naïve assumption):在给定类别 c 的条件下,各特征 x_i 之间彼此独立,于是 P(x|C=c) ≈ 连乘 P(x_i|C=c),参数量降到 n 个,线性可扩展。分类决策:选使后验概率最大的那个类别,即 argmax_c P(C=c) × 连乘 P(x_i|C=c)。考试要点:能写出朴素假设的分解公式,理解"朴素"二字指的是条件独立性假设,知道这个假设大大减少了所需的参数量(从指数级降到线性级)。易错:说"特征之间相互独立"是不对的,正确表达是"在给定类别条件下,特征之间条件独立",两者有根本区别。

这一页讲的是 Naïve Bayes 方法为何在假设不完全真实的情况下仍然有效。主要讨论假设与现实的差异,以及其成功的原因。
这一页讲的是 Naïve Bayes 方法为何能够在假设不完全真实的情况下仍然有效。首先,它的假设包括特征在给定类别下是独立的,以及每个特征对类别评分的贡献是乘法关系。然而,现实中特征几乎从不完全独立,并且某些特征的重要性远高于其他特征,例如“FREE!!!”比“hello”更强烈地指向垃圾邮件。尽管如此,Naïve Bayes 仍然有效的原因包括:分类通常只需要类别的排名而非绝对概率,例如 P(spam|x)=0.3 和 P(notspam|x)=0.2;许多弱信号可以有效结合;参数估计在数据有限的情况下仍然容易实现,且其计算复杂度较低(2^n 对比 Naïve Bayes 的 n)。右侧的流程图展示了垃圾邮件分类的例子,特定单词如“free”和“offer”以及链接数量被用来判断邮件是垃圾邮件还是非垃圾邮件。这说明 Naïve Bayes 在实际应用中能够有效处理复杂问题,即使其基本假设不完全符合现实。
这一页讲的是朴素贝叶斯分类器为什么在假设不现实的情况下仍然在实践中工作良好,以及垃圾邮件检测中的 log-space 评分方法。首先是为什么 Naïve Bayes 工作:分类任务只需要对类别的排序(ranking)正确,而不需要后验概率完全精确。只要 P(spam|x) > P(not-spam|x) 就分类为 spam,即使实际数值误差较大,排序仍然正确。弱特征可以叠加——许多弱信号的乘积仍然有判别力。参数估计简单:不假设条件独立需要 2^n 个参数,朴素贝叶斯只需要 n 个,少数据也能有效估计。然后是 log-space 技巧:argmax_c [P(C=c) × 连乘 P(x_i|C=c)],取对数后等价于 argmax_c [log P(C=c) + 求和 log P(x_i|C=c)]。这解决了两个问题:一是数值下溢(很多小数连乘会趋于零,取 log 变成负数求和,不会下溢);二是每个特征的贡献变成加法,更直观可解释,log P(x_i|spam) - log P(x_i|not-spam) 就是这个词对 spam 判断的贡献度。直觉:"FREE!!!" 在 spam 中比 not-spam 中常见得多,log P('free'|spam) 远大于 log P('free'|not-spam),所以它对 spam 评分贡献大。考试常考:写出 log-space 的评分公式,理解为什么要取 log(数值稳定性),以及 log prior 和 log likelihood 各贡献了什么。

这一页讲的是垃圾邮件检测的应用。定义假设 H 和证据 e,并用朴素贝叶斯方法选择最大后验概率的假设。
这一页讲的是垃圾邮件检测的应用。首先定义假设 H,表示分类标签,可以是垃圾邮件(spam)或非垃圾邮件(not spam)。然后定义证据 e,表示从邮件中提取的特征集合,例如某些单词是否出现(如“free”或“offer”),或者邮件是否包含大量链接等。通过朴素贝叶斯(Naïve Bayes)方法,选择后验概率最大的假设,即通过公式 argmax H 属于 {spam, not spam} 的 P(H | e) 来实现分类。这种方法的核心思想是利用概率模型,根据邮件内容特征判断其是否属于垃圾邮件。举例来说,如果一封邮件中出现了多个促销相关单词且包含大量链接,朴素贝叶斯可能会倾向于将其分类为垃圾邮件。

这一页讲的是垃圾邮件检测的应用,基于贝叶斯定理和条件独立假设。重点包括公式推导和分类方法。
这一页讲的是垃圾邮件检测的应用,利用贝叶斯定理和朴素条件独立假设来进行分类。首先,根据贝叶斯定理,后验概率 P(H | e) 与先验概率 P(H) 和似然 P(e | H) 成正比。这里 H 表示类别(垃圾邮件或非垃圾邮件),e 表示观察到的证据。接着,假设每个证据 ei 在给定类别 H 的条件下独立,则可以将 P(e | H) 分解为各个证据的条件概率乘积,即 P(e | H) ≈ Π P(ei | H)。最终,分类器通过最大化后验概率来预测类别,公式为 Ĥ = argmaxH∈{spam,not spam} P(H) Π P(ei | H)。这种方法简单高效,适合处理文本分类问题,比如垃圾邮件检测。举例来说,如果某封邮件包含多个关键词,每个关键词的出现概率可以独立计算,然后综合这些概率来判断邮件是否为垃圾邮件。

这一页讲的是垃圾邮件检测的概率模型,重点是通过对数转换简化计算,并解释了模型的直觉。
这一页讲的是垃圾邮件检测的概率模型。首先,公式中 H 表示假设(spam 或 not spam),P(H) 是先验概率,P(ei | H) 是特征 ei 在假设 H 下的条件概率。通过对数转换,原来的乘积形式被简化为加法形式,即 log P(H) 加上所有 log P(ei | H) 的累加。这种转换使得证据在对数空间中累积,计算更方便。解释部分指出,log P(H) 是先验的贡献,而每个 log P(ei | H) 是单个特征的贡献。整体上,模型通过比较词语在垃圾邮件和非垃圾邮件中的出现频率,来判断邮件是否为垃圾邮件。例如,如果某些词在垃圾邮件中出现的频率远高于非垃圾邮件,那么这些词会显著提高垃圾邮件的评分,使得 H 更倾向于 spam。这种方法直观且计算效率高,适用于实际应用。

这一页讲的是垃圾邮件检测的应用,使用朴素贝叶斯模型。重点包括公式的作用、log-score优势和模型优点。
这一页讲的是垃圾邮件检测的应用,使用朴素贝叶斯模型进行分类。公式表示通过最大化后验概率来预测分类结果,其中 H 是类别(垃圾邮件或非垃圾邮件),P(H) 是类别的先验概率,P(ei|H) 是特征在类别下的条件概率。log-score 的使用避免了数值下溢问题,同时使每个特征的贡献更容易解释。朴素贝叶斯模型的优点包括简单(simple),计算速度快(fast),可扩展性强(scalable),并且在文本任务中是一个强大的基准模型(strong baseline for text tasks)。这一模型适合处理大规模文本数据,例如电子邮件分类。页面还提供了额外阅读材料链接,深入了解朴素贝叶斯方法的应用。
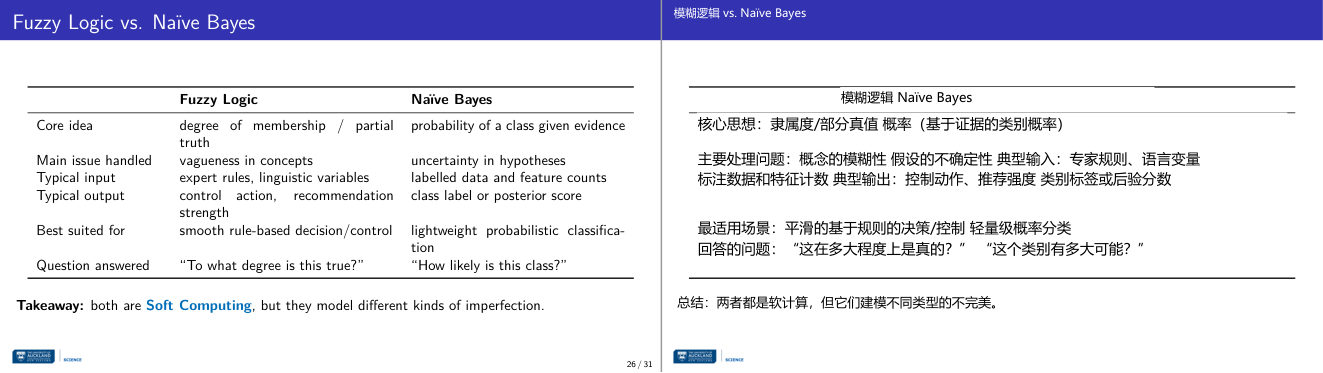
这一页讲的是模糊逻辑 (Fuzzy Logic) 与朴素贝叶斯 (Naïve Bayes) 的比较。主要对比了两者的核心理念、处理问题类型、输入输出及适用场景。
这一页讲的是模糊逻辑 (Fuzzy Logic) 与朴素贝叶斯 (Naïve Bayes) 的比较。模糊逻辑的核心是处理模糊性和部分真值,适用于规则驱动的决策控制,典型输入是专家规则和语言变量,输出是控制动作或推荐强度,回答的问题是“某事在多大程度上是真的?”而朴素贝叶斯的核心是根据证据计算类别概率,处理假设中的不确定性,输入是标注数据和特征计数,输出是类别标签或后验概率,适用于轻量级概率分类,回答的问题是“某类别的可能性有多大?”表格清晰地列出了两者的对比,结论是它们都属于软计算 (Soft Computing),但处理不同类型的不完美性。

这一页讲的是软计算(Soft Computing)的核心思想及其与硬计算(Hard Computing)的区别,重点介绍模糊逻辑(Fuzzy Logic)和朴素贝叶斯(Naïve Bayes)。
这一页讲的是软计算(Soft Computing)如何处理不确定性、不精确性和近似问题。与硬计算(Hard Computing)追求精确符号和严格逻辑不同,软计算允许一定的模糊性以实现实际的实用性。模糊逻辑(Fuzzy Logic)通过隶属函数和模糊规则来建模分级概念,例如在处理模糊边界的问题时非常有效;而朴素贝叶斯(Naïve Bayes)基于贝叶斯定理和独立假设,用于处理不确定分类问题,例如在邮件分类或疾病诊断中应用广泛。这两种方法虽然不同,但共同体现了软计算的核心思想:在不确定的世界中,我们不需要完美的答案,而是需要一个实用、稳健且可解释的解决方案。

这一页讲的是模糊逻辑(Fuzzy Logic)和贝叶斯推理(Bayesian Reasoning)的概念比较。正确答案是 C,模糊逻辑描述概念的模糊性。
这一页讲的是模糊逻辑(Fuzzy Logic)和贝叶斯推理(Bayesian Reasoning)的核心概念及其区别。模糊逻辑主要用于处理概念的模糊性(vagueness),即事物之间的边界不明确,例如“温暖”可以是一个模糊的范围,而不是明确的数值。贝叶斯推理则是基于概率模型,用来描述某事件属于某类别的可能性,强调的是成员关系的程度(degree of membership)。幻灯片的问题要求选择正确的陈述,答案是 C,模糊逻辑用于建模概念的模糊性,而不是不确定性或成员关系。二维码可能链接到相关的学习资源或答案解析。

这一页讲的是模糊逻辑 (Fuzzy Logic) 中的模糊与运算 (Fuzzy AND)。
这一页讲的是模糊逻辑 (Fuzzy Logic) 中的模糊与运算 (Fuzzy AND)。模糊逻辑是一种处理不确定性的方法,模糊与运算用于计算两个模糊集合的交集。题目给出了两个模糊集合的隶属度 μA = 0.6 和 μB = 0.8,要求计算 A ∧ B 的值。根据模糊与运算的定义,通常采用最小值法,即取两个隶属度的较小值作为结果。因此,A ∧ B = min(μA, μB) = min(0.6, 0.8) = 0.6。选项中正确答案是 A。这种运算在模糊系统中非常重要,因为它帮助我们在不确定环境下进行逻辑推理,例如在控制系统或决策支持系统中。

这一页讲的是 Naïve Bayes 的关键假设,选项包括特征重要性、条件独立性和类别独立性。
这一页讲的是 Naïve Bayes 的核心假设,重点是理解其简化计算的基础。Naïve Bayes 假设特征在给定类别的情况下是条件独立的,这意味着每个特征的出现与其他特征无关,只依赖于类别。这种假设虽然简单,但在实际应用中非常有效,尤其是在文本分类等领域。选项 A 提到特征的等重要性,这并非 Naïve Bayes 的假设;选项 C 提到类别独立性,这也不符合该模型的逻辑。正确答案是 B,即特征在给定类别时是条件独立的。这种假设使得计算概率更加简化,例如在邮件分类中,词语的出现可以被独立地处理,而不需要考虑它们之间的复杂关系。
这一页讲的是总结与问答环节。主要表达感谢并邀请提问。
这一页讲的是总结与问答环节。幻灯片以“Thank you! Q&A”为主要内容,表示演讲或课程已经结束,并对听众表示感谢,同时邀请大家进行提问。这通常是一个开放的互动环节,旨在解决听众在课程中未完全理解的内容或进一步探讨相关主题。问答环节的重要性在于它能够促进知识的深化和交流,帮助听众更好地掌握课程重点。例如,如果课程涉及机器学习中的某个算法,听众可以在此环节询问具体应用场景或算法优化的细节,从而获得更有针对性的解答。