第 1 / 20 页

这一页讲的是机器人如何行走,重点是从 AI 模型到真实机器人之间的转化过程。
空格=播放/暂停当前页 · Tab=切换 简短/详细/深入 · 红色「深入」为重点页的深度讲解
这一页讲的是机器人如何行走,重点是从 AI 模型到真实机器人之间的转化过程。
这一页讲的是机器人如何行走,重点探讨了人工智能(AI)模型如何应用到实际的机器人中。通过 AI 模型,机器人可以学习复杂的运动控制策略,比如步态规划(gait planning)和动态平衡(dynamic balance)。这些技术让机器人能够在不同地形上稳定行走。幻灯片中的图片展示了一台四足机器人,它的设计模仿了动物的运动方式,结合了先进的机械结构和 AI 算法。这样的机器人可以用于搜索与救援、物流运输等场景。理解 AI 模型如何驱动机器人运动,不仅有助于提升机器人的功能,还能推动智能机器人领域的进一步发展。

这一页讲的是教机器人行走的挑战,与训练动物的对比。重点在于机器人没有本能,且由金属制成。
这一页讲的是如何教机器人行走的问题,并通过与训练动物的对比来说明其中的挑战。幻灯片左侧展示了一个机器人,标注为“Made of metal”和“No instinct”,强调机器人是由金属制成的,没有生物的本能行为。右侧是一位训练师在教狗握手的场景,暗示动物具有学习能力和本能,可以通过训练逐步掌握技能。机器人需要完全依赖编程和算法来完成类似的任务,这与动物通过本能和训练结合的方式形成鲜明对比。教机器人行走不仅涉及机械设计,还需要复杂的人工智能算法来模仿生物的运动模式,例如步态规划和实时环境感知。这一对比突出了机器人学习的复杂性和人工智能在模仿生物行为中的重要性。

这一页讲的是四足机器人 (Quadruped Robots),展示了四种不同类型的机器人,包括 Unitree Go2、ANYbotics 的 ANYmal 和 Boston Dynamics 的 Spot。
这一页讲的是四足机器人 (Quadruped Robots),它们是一种模仿动物四足步态的机器人,具有高灵活性和适应复杂地形的能力。页面展示了四种具体的例子:1. Unitree Go2,这是一款轻便且高性能的四足机器人,适用于研究和娱乐领域;2. ANYbotics 的 ANYmal,这是一种专为工业应用设计的机器人,能够在复杂环境中执行任务;3. Boston Dynamics 的 Spot,这是一款广泛应用于巡检和监控的机器人,以其高灵活性和稳定性著称;4. ANYmal wheeled quadruped,这是一种结合轮式和四足步态的机器人,进一步提升了移动效率和适应性。这些机器人展示了四足机器人在不同场景下的应用潜力,例如工业巡检、地形探索和灾难救援等领域。

这一页讲的是如何控制机器人,通过关节角度定义姿态。主要包括关节的自由度(DoF)和姿态表示的示例。
这一页讲的是如何控制机器人,特别是通过关节角度来定义机器人的姿态。机器人每个关节对应一个自由度(Degree of Freedom, DoF),四条腿总共有12个关节,因此有12个自由度,这些自由度可以用一个12维向量来表示。幻灯片中列举了一个站立姿态的关节角度示例,其中包括髋关节(Hip joint)、大腿关节(Thigh joint)和小腿关节(Calf joint)的角度值。例如,站立姿态的默认关节角度为:髋关节角度为0.0,大腿关节角度为0.8或1.0,小腿关节角度为-1.5。这些角度值精确地定义了每个关节的运动状态,从而实现对机器人的姿态控制。这种方法的重要性在于可以通过数学模型精确控制机器人动作,确保其稳定性和灵活性。例如,调整小腿关节角度可以改变机器人的高度,从而适应不同地形。

这一页讲的是机器人行走的简单解决方案及其局限性。主要内容包括预定义轨迹的概念、周期性动作的局限性,以及在复杂环境中需要泛化能力。
这一页讲的是机器人行走的简单解决方案及其局限性。首先,简单方案是通过预定义轨迹 (predefined trajectory) 来控制机器人动作,即 action(t) = predefined trajectory。这种方法假设机器人行走是周期性的,因此可以提前设定所有关节动作。然而,这种方法在复杂环境中存在明显问题,例如岩石路 (rocky road)、沙地 (sandy road) 和障碍物 (obstacles)。这些环境的变化使得机器人无法依靠固定轨迹完成任务,强调了泛化能力 (generalization) 的重要性。图片展示了机器人在不同环境中行走的挑战,岩石路上需要应对不平整表面,沙地上需要适应松软地面,障碍物环境则需要灵活规避。这说明预定义轨迹无法满足动态环境的需求,必须通过更高级的算法或学习方法来提升机器人适应能力。这一页的核心是指出简单方案的局限性,并为后续讨论更先进的解决方案铺垫。
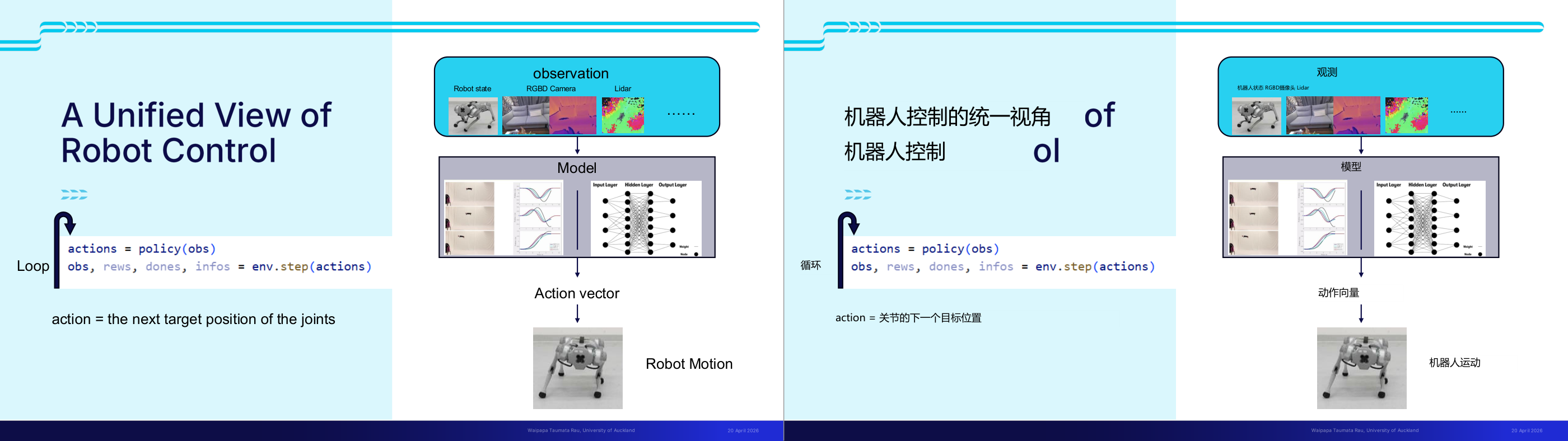
这一页讲的是机器人控制的统一视角,包括观察、模型和动作循环的流程。主要内容包括观察数据的输入、模型处理生成动作向量,以及机器人执行动作的循环过程。
这一页讲的是机器人控制的统一视角,重点在于通过循环流程实现机器人动作。首先,机器人从环境中获取观察数据(observation),包括机器人状态、RGBD相机图像和激光雷达(Lidar)信息等。这些数据作为输入传递给模型(Model),模型通过神经网络结构(包含输入层、隐藏层和输出层)处理数据,生成动作向量(Action vector)。动作向量表示机器人关节的下一目标位置。然后,机器人根据动作向量执行具体的动作(Robot Motion),并更新环境状态。此过程以循环形式进行,代码片段展示了循环的实现:通过 policy(obs) 生成动作,env.step(actions) 更新观察和环境状态。这个循环机制在机器人控制中非常重要,因为它确保了机器人能够实时感知环境并做出适应性动作。例如,一个四足机器人可以通过这种方式实现动态避障或目标跟踪。

这一页讲的是输入观测(Input Observation),包括机器人状态和控制指令的关键数据。主要包括角速度(base_ang_vel)、重力投影(projected_gravity)、控制指令(commands)等。
这一页讲的是输入观测(Input Observation),它是机器人控制系统的重要组成部分,用于描述机器人当前状态和接收到的控制指令。右侧表格列出了观测数据的组成部分及其含义:1. base_ang_vel 表示机器人底座的角速度(rad/s),由 IMU 提供,用于反映旋转运动状态;2. projected_gravity 是重力矢量在机器人坐标系中的投影,体现姿态信息;3. commands 是期望的速度指令,包括 vx、vy 和 yaw_rate,用于控制机器人运动;4. dof_pos 和 dof_vel 分别表示关节位置偏移和关节角速度,由关节编码器和电机提供;5. actions 是之前的动作输出,用于平滑控制。代码部分展示了如何通过 PyTorch 的 torch.cat 方法将这些观测数据组合成一个输入缓冲区(obs_buf),并对部分数据进行缩放处理,例如对角速度和关节速度进行归一化。
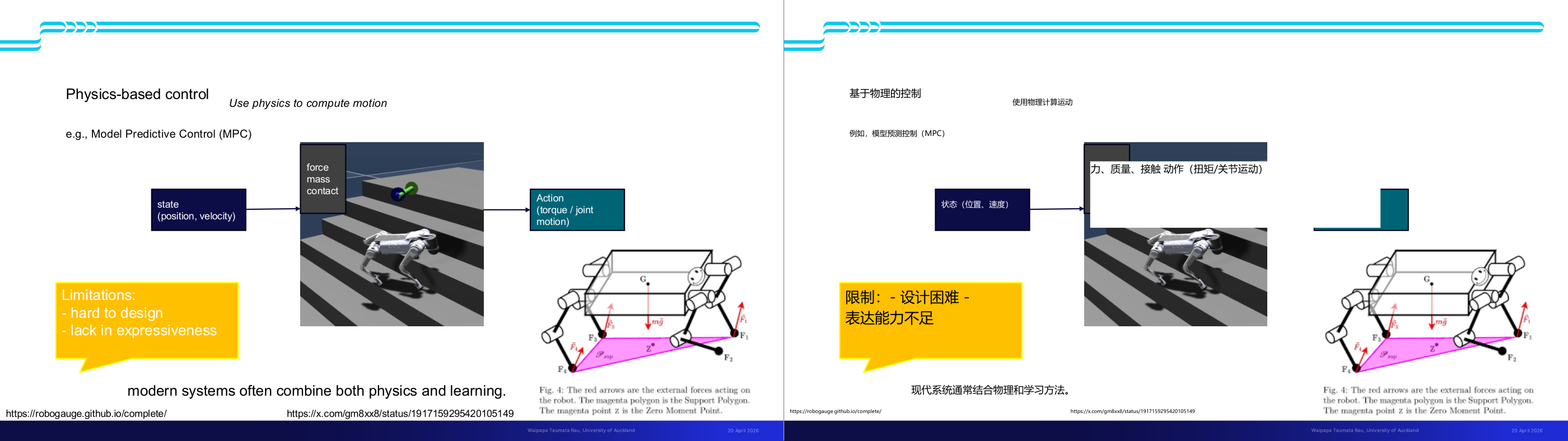
这一页讲的是基于物理的控制(Physics-based control)方法及其局限性。关键点包括利用物理计算运动、模型预测控制(MPC)的应用,以及设计难度和表达能力不足的问题。
这一页讲的是基于物理的控制(Physics-based control)方法,用物理学原理来计算运动。比如,模型预测控制(Model Predictive Control, MPC)是一个典型的应用,它通过状态(state,包括位置和速度)输入,结合物理参数如力(force)、质量(mass)和接触(contact),计算出动作(action,例如关节的扭矩或运动)。图中展示了一个四足机器人爬楼梯的例子,强调了基于物理的控制如何利用力学原理实现运动规划。右下角的图则进一步解释了支持多边形(Support Polygon)和零力矩点(Zero Moment Point, ZMP)的概念,这些是机器人稳定性分析中的重要工具。尽管基于物理的控制方法可以提供较为精准的运动计算,但其局限性包括设计难度较高(hard to design)和表达能力不足(lack in expressiveness)。现代系统通常结合物理和学习方法,以弥补这些不足,从而实现更复杂的控制任务。

这一页讲的是基于学习的控制方法,包括强化学习 (Reinforcement Learning) 和模仿学习 (Imitation Learning)。强化学习通过试错和奖励机制改进,模仿学习通过专家演示进行监督学习。
这一页讲的是基于学习的控制方法,重点介绍了两种主要技术:强化学习 (Reinforcement Learning) 和模仿学习 (Imitation Learning)。强化学习是一种通过试错过程进行学习的方法,系统会尝试不同的动作,根据获得的奖励信号进行优化,从而逐步提高性能。左侧图片展示了多个机器人在复杂环境中通过强化学习进行任务训练的场景,说明这种方法适用于动态和未知环境。模仿学习则是一种从专家演示中学习的技术,与监督学习类似。右侧的图表展示了模仿学习的过程,包括从专家演示中提取关键点轨迹 (Keypoint Trajectories),并将其应用到机器人部署中,使机器人能够模仿专家的动作。这种方法适合需要精准模仿人类或其他专家行为的场景,例如机器人行走或操作复杂设备。两种方法各有优势:强化学习适合探索未知环境,模仿学习则能快速实现高效的行为复制。
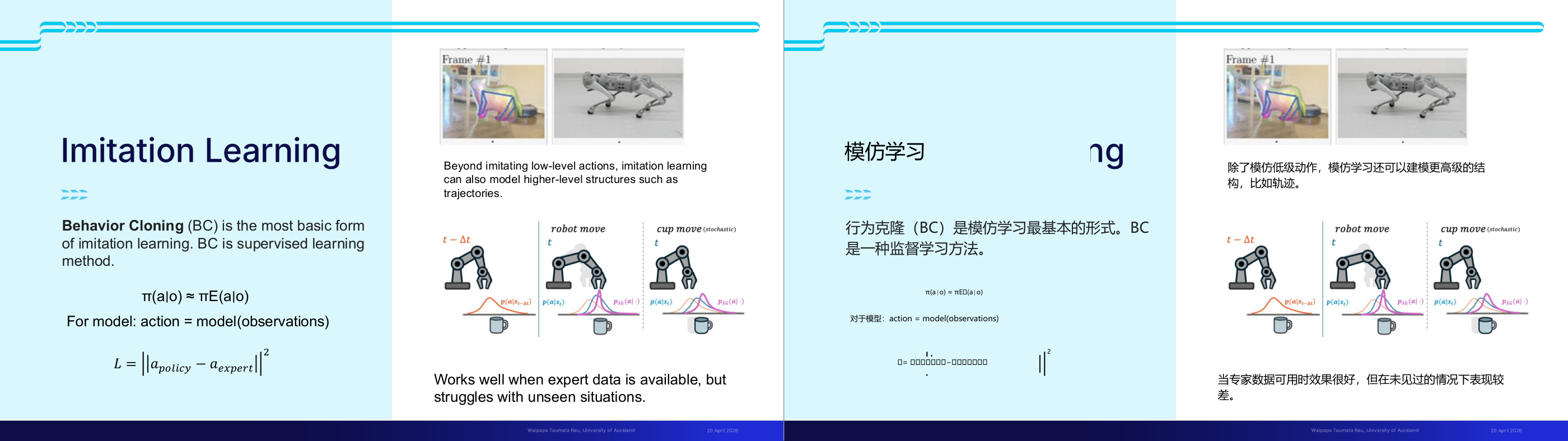
这一页讲的是模仿学习(Imitation Learning)中的行为克隆(Behavior Cloning, BC)。重点包括 BC 的监督学习性质、公式描述以及其适用场景和局限性。
这一页讲的是模仿学习(Imitation Learning)中的行为克隆(Behavior Cloning, BC),这是模仿学习中最基础的形式。BC 是一种监督学习方法,其目标是通过专家数据训练模型,使模型的策略 π(a|o) 尽可能接近专家策略 πE(a|o)。公式中,模型根据观察值(observations)预测动作(action),而损失函数 L = ||a_policy - a_expert||^2 用于衡量模型动作与专家动作的差距。右侧的图例展示了模仿学习不仅可以模仿低层次动作,还可以建模更高层次的结构,例如轨迹(trajectories)。图中还对比了机器人移动和杯子随机移动的概率分布,说明不同任务的复杂性。BC 在有专家数据时表现良好,但在处理未见过的场景时效果较差,这也是其局限性所在。
这一页讲的是 Imitation Learning(模仿学习)中最基础的形式——Behavior Cloning(BC,行为克隆)。核心思想是:让机器人直接模仿专家的动作,本质上把它转化成一个监督学习问题。模型的输入是观测 o,输出是动作 a,目标是让策略 π(a|o) 尽可能接近专家策略 πE(a|o)。损失函数是预测动作与专家动作之差的平方,即 L 等于 a_policy 减 a_expert 的平方。这个形式非常直白:给定一堆专家示范数据(专家做什么动作、在什么状态下),用这些数据训练一个神经网络,就像训练图像分类器一样。 听上去简单,但有一个非常经典且高频考点的问题叫 Distribution Shift(分布偏移)。训练时,专家数据覆盖的是专家走过的状态分布;但测试时,机器人一旦犯了小错误,就会进入从未见过的状态,然后模型就不知道该怎么办了,错误不断放大。这是 BC 最致命的弱点。 一个简单例子:想象教一个机器人在走廊里直行。专家数据全是正中间走路的场景。如果机器人稍微偏到了左边,这个状态在训练集里从未出现过,模型可能给出一个奇怪的动作,使机器人越偏越远。 BC 的优点是训练快、数据效率高,适合有大量专家示范的场景。局限是泛化能力差,遇到 out-of-distribution 的情况会失效。考试常考:BC 属于有监督学习还是强化学习?(有监督)为什么 BC 在长时序任务上容易失败?(distribution shift 累积误差)如何缓解?(DAgger 算法让专家对机器人实际遇到的状态打标签)。注意不要把 BC 和 RL 混淆——BC 不需要奖励信号,RL 需要。
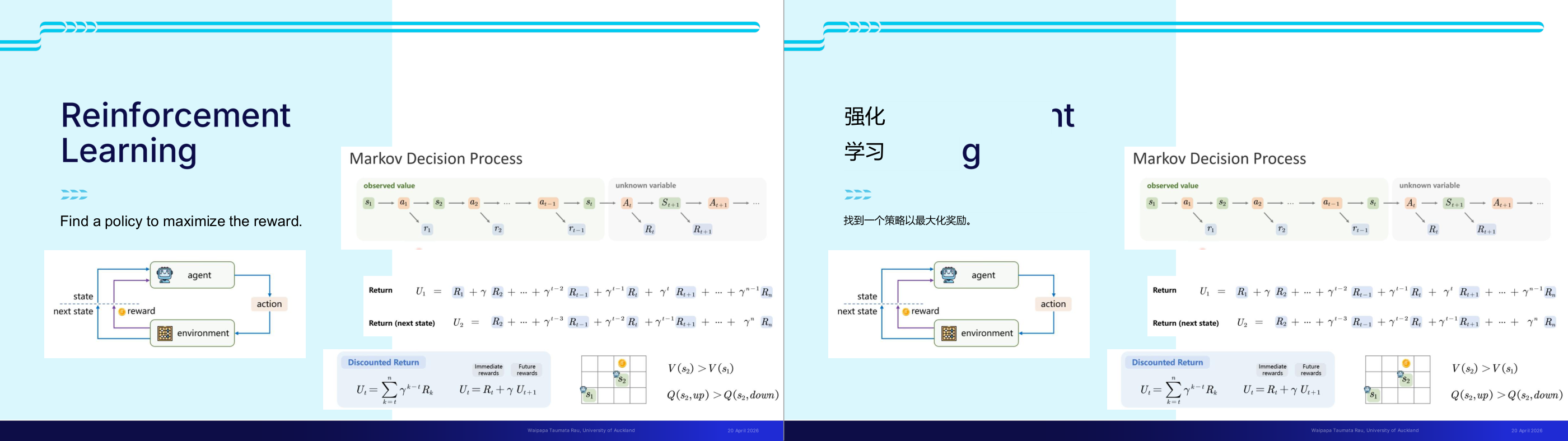
这一页讲的是强化学习 (Reinforcement Learning),重点包括马尔科夫决策过程 (Markov Decision Process)、回报计算和折扣回报的公式。
这一页讲的是强化学习 (Reinforcement Learning),其目标是找到一个策略 (policy) 来最大化奖励 (reward)。页面展示了强化学习的核心框架:智能体 (agent) 根据环境 (environment) 的状态 (state) 采取行动 (action),环境返回奖励和下一个状态,形成一个循环。右侧的马尔科夫决策过程 (Markov Decision Process, MDP) 描述了状态、动作和奖励的序列关系,强调当前状态和动作决定下一状态及奖励。公式部分解释了回报 (Return) 的计算方法,包括即时奖励和未来奖励的加权和,使用折扣因子 γ 来降低远期奖励的影响。折扣回报公式进一步细化,展示了如何通过累加折扣后的奖励来计算总回报。图中还通过一个网格示例说明了状态价值 (state value) 和动作价值 (action value) 的比较,例如在状态 s2 中选择向上移动的价值高于向下移动。强化学习的核心是通过优化策略使智能体能够在长期内获得最大回报。

这一页讲的是 Actor-Critic 方法的结构和工作流程。主要包括 Actor 和 Critic 的角色分工、策略更新和目标计算。
这一页讲的是 Actor-Critic 方法,它是一种强化学习算法,结合了策略梯度(Policy Gradient)和价值函数(Value Function)的优点。Actor 部分负责生成动作策略 π,输入当前状态 st,输出动作分布参数 μ 和 σ,通过采样生成具体动作 at。Critic 部分则评估该动作的质量,计算 Qπ(st, at),即基于策略 π 的动作价值函数。环境会执行动作 at 并返回奖励 r,结合折扣因子 γ 和 Critic 的输出 Qπ,计算目标值 target = r + γ Qπ,用于更新 Critic 的参数。Actor 的更新则依赖 Critic 提供的反馈,优化策略以最大化预期奖励。右下角的流程图进一步展示了交互过程:状态 s 输入后生成动作 a,执行后得到新状态 s' 和奖励 r,Critic 更新 Qπ(s', a'),Actor 更新策略 π。这种方法的好处是同时优化策略和价值函数,提升学习效率。
这一页讲的是 Actor-Critic 算法的结构与更新流程,是强化学习中最重要的经典框架之一,也是现代机器人控制策略的核心基础。整个框架由两个网络构成:Actor(策略网络)和 Critic(价值网络)。 Actor 的作用是根据当前状态 s_t 输出动作的概率分布。具体来说,Actor 输出均值 μ 和标准差 σ,然后从高斯分布 N(μ, σ) 中采样得到实际动作 a_t。这种随机采样设计让策略具有探索性,避免陷入局部最优。 Critic 的作用是评估当前状态-动作对的价值,即计算 Q^π(s_t, a_t),表示在状态 s_t 执行动作 a_t 之后,按照策略 π 所能获得的累积期望奖励。 更新流程是:执行动作 a_t 后,环境返回奖励 r;Critic 的更新目标是 target 等于 r 加 γ 乘以 Q^π(下一状态),用 TD(时序差分)误差来更新 Critic 网络;然后用 Critic 给出的 Q 值来指导 Actor 的更新——Actor 朝着能使 Q 值变大的方向调整参数。 直觉上,Critic 相当于一个「评委」,Actor 相当于「演员」。演员采取动作后,评委打分;演员根据分数改进表演。两者交替优化,最终收敛到好策略。 考试常考:Actor 和 Critic 各自的输入输出是什么?Target 的计算公式是什么?(r + γ·Q)为什么 Actor-Critic 比纯 Policy Gradient 更稳定?(Critic 降低了方差)γ(discount factor)的作用是什么?(权衡即时奖励与长期奖励,γ 接近 1 重视未来,接近 0 只看眼前)。易错点:不要把 Q^π(s,a) 和 V^π(s) 混淆——前者是状态-动作对的价值,后者是状态价值。

这一页讲的是模仿学习(Imitation Learning, IL)与强化学习(Reinforcement Learning, RL)的比较。主要包括两者的核心理念、数据需求、优势及局限性。
这一页讲的是模仿学习(Imitation Learning, IL)与强化学习(Reinforcement Learning, RL)的区别与比较。IL的核心理念是通过专家的示范学习行为,依赖已有的演示数据,优点是学习速度快,但容易受到分布偏移(Distribution Shift)的影响。RL则通过试错和奖励机制学习行为,不需要预先的数据集,优势是灵活性强,但训练过程复杂且困难。这张表格清晰地列出了两者在理念(Idea)、数据需求(Data)、优势(Advantage)和局限性(Limitation)上的对比。最后一句总结了两者的本质区别:模仿学习是复制行为,而强化学习是发现行为。举例来说,IL适用于机器人模仿人类操作,而RL更适合解决复杂的游戏策略问题。
这一页讲的是 Imitation Learning(IL)与 Reinforcement Learning(RL)的系统对比,是本讲最具总结性的一页,高度契合考试常见的对比题型。 从思想上看:IL 是「向专家学习」——给定专家示范,模仿它的行为;RL 是「从试错中学习」——通过与环境交互,不断尝试、失败、根据奖励信号改进。 从数据来源看:IL 需要人工标注的专家示范数据集(demonstrations),数据来自人类或优秀策略的轨迹;RL 只需要与环境交互得到的(状态, 动作, 奖励)序列,不需要预先准备数据集。 从优势看:IL 训练快,尤其是 Behavior Cloning 这类方法,数据效率高,容易收敛;RL 更灵活,不需要专家,可以在没有示范数据的情况下从零学习,理论上能超越人类专家水平。 从局限看:IL 最大问题是 Distribution Shift——模型只在专家轨迹的分布上表现好,一旦偏离就会出错;RL 的问题是训练困难——奖励稀疏、探索低效、超参数敏感、容易不收敛。 一个直觉类比:IL 就像看着食谱做菜(有专家指导),RL 就像靠试吃反馈摸索出一道菜(只有奖励信号)。前者快但受限于食谱质量,后者慢但可以超越食谱。 考试常考:给定场景判断用 IL 还是 RL;解释 distribution shift 的含义;为什么说 RL 比 IL 更灵活但更难训练。两者也可以结合使用,例如用 IL 预训练初始策略,再用 RL 微调——这是现代机器人训练的常见做法。
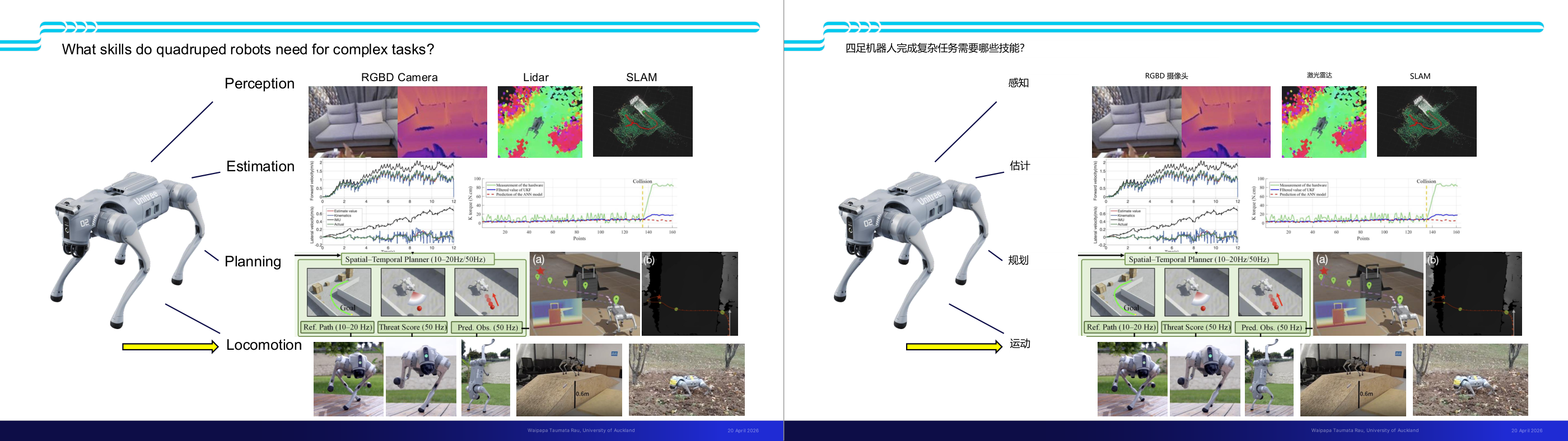
这一页讲的是四足机器人完成复杂任务所需的技能,包括感知 (Perception)、估计 (Estimation)、规划 (Planning) 和运动 (Locomotion)。
这一页讲的是四足机器人完成复杂任务所需的技能。首先是感知 (Perception),通过 RGBD Camera、Lidar 和 SLAM 技术,机器人能够捕捉环境的视觉信息、深度数据和构建地图。这些工具帮助机器人理解周围环境,例如识别障碍物或导航路径。其次是估计 (Estimation),通过分析图表可以看到,机器人需要估算速度、位置等关键参数,并与实际值进行比较来优化性能。图中展示了估计模型预测与实际数据的对比,以及碰撞检测的情况。然后是规划 (Planning),通过空间-时间规划器 (Spatial-Temporal Planner),机器人能够实时分析路径、威胁评分和预测障碍物位置,从而制定安全的行动计划。最后是运动 (Locomotion),机器人需要具备在不同地形上稳定行走的能力,例如跨越障碍、爬坡或在草地上移动。总的来说,这些技能的结合使得四足机器人能够在复杂环境中完成任务,例如搜索与救援或自动巡逻。

这一页讲的是机器人训练的流程,重点介绍模拟训练、Sim2Real技术和真实环境微调三个阶段。
这一页讲的是机器人训练的流程,特别是如何通过模拟训练(Simulation Training)和真实环境微调(Real-World Fine-Tuning)来提高效率并降低成本。首先,模拟训练阶段在虚拟环境中进行,通过强化学习(Reinforcement Learning)或模仿学习(Imitation Learning)让机器人掌握初步技能。其次是Sim2Real阶段,通过域随机化(Domain Randomization)等技术,使机器人能够适应真实环境,避免过拟合(Overfitting),从而形成更鲁棒的策略。最后是真实环境微调阶段,在真实机器人上进行少量的强化学习更新(On-Policy Fine-Tuning),进一步优化性能。页面右侧的两张图片分别展示了机器人在模拟环境和真实环境中的训练场景,强调了这种训练流程的实际应用。通过这种方法,可以有效减少硬件损耗和人工成本,同时提高机器人学习的效率和可靠性。
这一页讲的是真实机器人训练的三阶段范式:Simulation Training、Sim2Real、Real-World Fine-Tuning。这是机器人学习领域的核心工程方法,也是本讲最有考试价值的系统性知识点之一。 为什么不直接在真实机器人上训练?因为 RL 训练需要大量交互次数(通常是百万次级别),真实机器人每次交互都消耗时间、电力,还有硬件损耗和安全风险。因此业界通用做法是先在仿真器(simulator)中完成大量训练。 第一阶段——Simulation Training:在仿真器(如 NVIDIA Isaac Sim、Gazebo)中做 RL 或 IL 训练。仿真器可以并行运行成千上万个环境实例,极大加速训练。缺点是仿真与现实之间存在「现实差距」(Reality Gap)。 第二阶段——Sim2Real:将仿真训练好的策略迁移到真实机器人时,需要处理仿真与现实的差异。核心技术是 Domain Randomization(域随机化):在训练时随机化仿真参数(摩擦力、质量、关节刚度等),让策略对各种条件都能适应,从而迁移到真实环境。还需要处理传感器噪声、延迟等问题。 第三阶段——Real-World Fine-Tuning:在真实机器人上做少量 on-policy RL 微调,让策略适应真实环境中无法完全仿真的细节。 考试常考:为什么需要三阶段而不是直接在真实环境训练?Domain Randomization 的作用是什么?(提升策略对参数变化的鲁棒性,减少对仿真器过拟合)什么是 on-policy fine-tuning?(策略用自己当前的行为采集数据来更新,与 off-policy 相对)。

这一页讲的是仿真训练(Simulation Training)。主要内容包括常用仿真器、Genesis模型的关节级控制以及目标位置设定。
这一页讲的是仿真训练(Simulation Training)。首先介绍了常用的仿真器,包括 NVIDIA Isaac Sim 和 Gazebo 等,用于机器人行为的模拟和测试。接着提到 Genesis 模型在关节级别进行控制,需要配置 18 个参数。这些参数定义了机器人各个关节的自由度(DOFs)。页面中的代码示例展示了如何通过函数 go2.control_dofs_position 来设定目标位置,其中 position=stand_full 表示目标位置为完全站立状态,dofs_idx_local=idx 指定了局部关节索引。最后提到位置控制的原理:输入为目标位置,系统通过内部的 kp/kd 约束驱动机器人逐步接近目标位置。右侧的图片展示了一个仿真实验场景,机器人需要在复杂地形中导航,避开障碍物。这种仿真训练对于验证机器人在现实环境中的性能和稳定性非常重要。

这一页讲的是Sim2Real(从模拟到现实)技术的关键挑战与解决方法,包括延迟、滤波、领域随机化和跨模拟器测试。
这一页讲的是Sim2Real(从模拟到现实)技术的关键挑战与解决方法。首先,延迟(Latency)是机器人在现实环境中不可避免的状态观测延迟问题,训练时需考虑这一点,例如通过公式action = f(obs(t − Δt))来调整动作决策。其次,滤波(Filtering)是指真实机器人上的观测数据,例如dq,通常经过低通滤波器平滑处理,因此在模拟器中也需要加入类似滤波机制以匹配真实情况。领域随机化(Domain Randomization)是通过在训练中引入随机性(如kp、kd、摩擦力、马达强度等参数的变化)来提高策略的鲁棒性,因为这些参数在真实机器人中并非恒定。最后,跨模拟器测试(Sim-to-Sim)解决了单一模拟器训练的策略可能过拟合的问题,通过在多个模拟器中测试和验证策略显著提升鲁棒性,但要求所有测试参数保持一致。这些方法共同帮助机器人从模拟环境成功迁移到现实应用,确保性能稳定可靠。
这一页讲的是 Sim2Real 迁移中的关键技术细节,即如何弥合仿真与真实之间的差距。这是本讲最技术性的内容,涉及若干值得深讲的工程细节。 第一个问题是 Latency(延迟):真实机器人上,传感器读取、计算、执行之间存在不可消除的时间延迟。因此策略实际执行的是「根据过去状态做出的决策」,即 action 等于 f(obs(t 减 Δt))。如果训练时不考虑延迟,部署时会出现明显的控制不稳定。解决方法是在仿真器里人为引入延迟。 第二个问题是 Filtering(低通滤波):真实机器人的关节速度(dq)等测量值本身已经经过内部低通滤波器(Low-Pass Filter, LPF)平滑处理。如果仿真观测是原始噪声信号而真实观测是滤波后的平滑信号,两者分布差距很大。因此仿真器里也要加 LPF 来匹配真实传感器行为。 第三个问题是 Domain Randomization(域随机化):真实机器人的物理参数(如关节刚度 kp/kd、摩擦力、电机强度)因制造公差、磨损等因素会有个体差异。训练时随机化这些参数,能让策略对参数变化保持鲁棒。直觉是:如果策略在「最难的一批仿真条件」下都能运行,部署到真实机器人时自然也能应对。 第四个问题是 Sim-to-Sim 验证:策略可能过拟合到某一特定仿真器的特性。在多个不同仿真器中测试同一策略,是验证泛化性的好方法。 考试易错点:Domain Randomization 不是在测试时随机化,而是在训练时随机化。LPF 是为了让仿真观测匹配真实传感器,不是为了让控制更平滑。延迟建模要写进观测函数里,不能忽略。

这一页讲的是机器人步态控制的评估,比较不同随机性条件下的运动表现。主要包括基础评估、延迟影响以及加入动态随机性(DR)和低通滤波(LPF)的效果。
这一页讲的是机器人步态控制的评估,展示了在不同随机性条件下的运动表现。第一张图片是基础评估(eval),机器人在理想条件下的步态表现。第二张图片是加入一步延迟(eval with 1 step delay),显示延迟对步态的影响。第三张图片是加入一步延迟和动态随机性(eval with 1 step delay+DR),动态随机性模拟了更复杂的真实环境。第四张图片则进一步加入了低通滤波(eval with 1 step delay+DR+LPF),用于平滑控制信号以减少噪声干扰。通过这些图可以看出,随着随机性的增加,机器人的运动变得更加僵硬,但仍能维持行走能力。这说明在复杂环境中,加入动态随机性和信号处理方法能够提高机器人适应性和稳定性。例如,在真实应用中,低通滤波可以帮助机器人在不稳定地面上保持平稳行走。
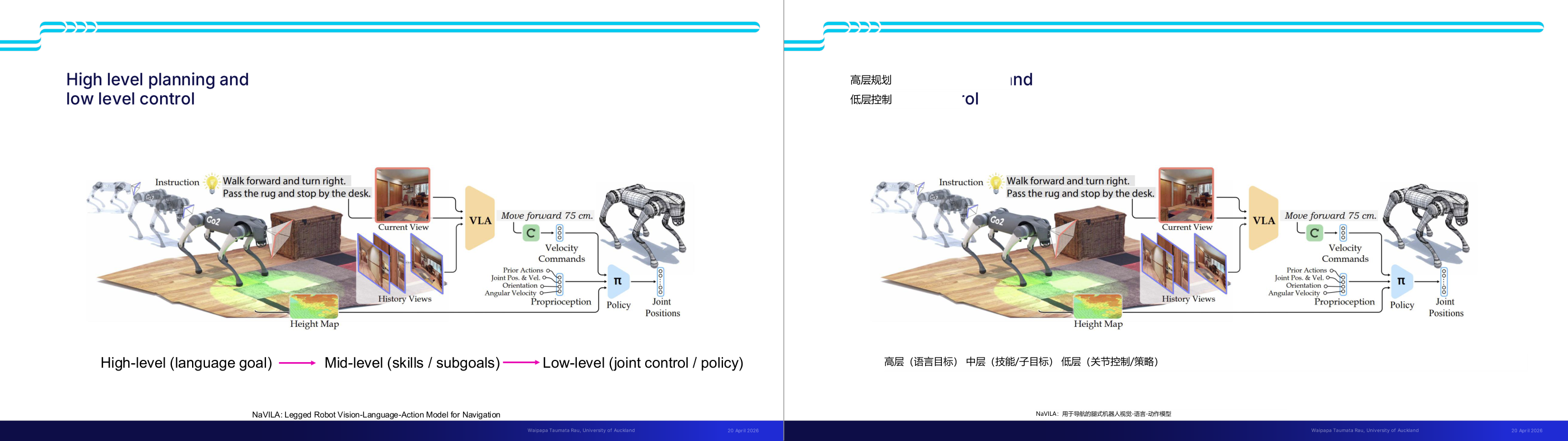
这一页讲的是高层规划与低层控制的关系。重点包括高层语言目标、中层技能与子目标,以及低层关节控制策略的分层架构。
这一页讲的是机器人导航中的高层规划与低层控制的分层架构。图中展示了一个四足机器人如何根据语言指令完成复杂的导航任务。高层 (High-level) 处理语言目标,例如“向前走并右转,穿过地毯,在桌子旁停下”。中层 (Mid-level) 通过视觉语言动作模型 (VLA) 将当前视图、历史视图和高度地图转化为具体的子目标,例如“向前移动75厘米”。低层 (Low-level) 负责具体的关节控制策略 (Policy),根据速度指令 (Velocity Commands)、关节位置 (Joint Positions)、速度、角度等感知数据 (Proprioception) 执行动作。整个流程从语言目标到关节控制,逐层细化,确保机器人能够准确完成任务。例如,当机器人接收到“穿过地毯”的指令时,它会通过视觉信息识别地毯的位置,并生成具体的移动指令,最终通过低层控制调整关节动作完成导航。这种分层架构有效地将复杂任务分解为可执行的步骤,提升了机器人在动态环境中的适应能力。

这一页讲的是 Q&A 环节,提供听众提问和交流的机会。
这一页讲的是 Q&A 环节,通常在演讲或课程结束时设置,用于回答听众的问题并进行互动交流。这一环节非常重要,因为它可以帮助听众解决未解的疑问,加深对内容的理解,同时也是讲者与听众建立联系的机会。幻灯片背景简单清晰,突出 Q&A 的主题,底部的 'Thank you for your listening!' 表达了对听众的感谢,营造了友好的氛围。这种设计能够让听众专注于提问和讨论,而不会被其他信息分散注意力。