Week 06 - 02 - W6L1_NEAT-3 视图:双语并排 英文 中文 倍速:1x 1.5x 2x
空格=播放/暂停当前页 · Tab=切换 简短/详细/深入 · 红色「深入」为重点页的深度讲解
这一页讲的是 Lecture 11 的主题 NEAT,即神经网络拓扑结构的进化方法。
这一页讲的是 Lecture 11 的主题 NEAT (NeuroEvolution of Augmenting Topologies),这是人工智能领域的一种进化算法,专注于神经网络拓扑结构的优化。NEAT 的核心思想是通过模拟生物进化来逐步优化神经网络的结构和权重,使其能够更好地解决复杂问题。它结合了遗传算法和神经网络,允许网络结构从简单到复杂逐步扩展,同时保持遗传信息的兼容性。NEAT 的重要性在于它解决了传统神经网络设计中结构固定的问题,使得网络能够动态适应任务需求。幻灯片还提到课程编号为 COMPSCI 713,由 Xinyu Zhang 授课,并基于 Prof. Jim Warren 的讲义材料。这门课属于奥克兰大学计算机科学学院,讲授时间为 2026 年第一学期。
这一页讲的是遗传算法(Genetic Algorithms, GA)的概述,并将重点介绍一种具体的算法——NEAT。
这一页讲的是遗传算法(Genetic Algorithms, GA),这是一种基于自然选择和遗传机制的优化方法。遗传算法通过模拟生物进化过程来解决复杂问题,涉及选择、交叉和变异等关键操作。随后,幻灯片将重点介绍一种具体的遗传算法——NEAT(NeuroEvolution of Augmenting Topologies)。NEAT是一种用于优化神经网络结构和权重的进化算法,能够动态调整网络拓扑结构以适应问题需求。通过这种方法,NEAT可以在解决复杂问题时表现出较高的灵活性和效率。这一页为接下来的深入讲解奠定了背景基础。
这一页讲的是遗传算法 (Genetic Algorithms, GAs)。它模拟生物进化过程寻找最优解,关键步骤包括初始化、适应度评估、选择、交叉和变异。
这一页讲的是遗传算法 (Genetic Algorithms, GAs),它是一类受达尔文进化论和遗传学原理启发的算法,用于搜索问题的最优解。遗传算法的核心流程包括五个关键步骤:初始化 (Initialization) 是生成初始种群;适应度评估 (Fitness/Evaluation) 用于衡量每个个体的优劣;选择 (Selection) 根据适应度挑选优秀个体;交叉/繁殖 (Crossover/Reproduction) 是通过基因组合生成下一代;变异 (Mutation) 引入随机变化以增加多样性。幻灯片中的流程图展示了遗传算法的循环过程,从新一代种群的生成开始,经过评估、选择、交叉和变异,最终形成新的种群。通过这一过程,算法逐渐优化解的质量。例如,在解决路径优化问题时,遗传算法可以不断生成更短的路径方案。
这一页讲的是遗传算法(Genetic Algorithm, GA)的整体框架和核心步骤。GA 是一类受达尔文进化论启发的搜索算法,它不像 A 或 minimax 那样依靠明确的数学梯度,而是通过模拟「自然选择+遗传」来在庞大的解空间里找到好的解。整个流程分五步:初始化(Initialization)、评估适应度(Fitness/Evaluation)、选择(Selection)、交叉/繁殖(Crossover/Reproduction)、变异(Mutation),这五步循环往复构成一代代迭代。直觉上可以把每个候选解想象成一只「生物」——适应环境的生存下来,优秀的基因传给后代,劣势的被淘汰。GA 之所以有用,是因为它把领域知识打包进了适应度函数和交叉方式里,让搜索带有方向性,而不是纯随机乱撞。考试中这一页常作为概念题:能不能完整写出 GA 的五个关键步骤?易错点是把「繁殖」和「交叉」混为一谈——繁殖是更宏观的过程,交叉是其中最主要的操作之一,变异是另一种操作,两者都属于遗传算子(genetic operators)。另外要记住:这只是「进化」的隐喻,实际上是一种启发式搜索策略。
这一页讲的是遗传算法中的种群、基因和染色体。主要内容包括种群的定义、基因编码与表型的关系,以及初始种群的随机性。
这一页讲的是遗传算法中的种群 (Population)、基因 (Gene) 和染色体 (Chromosome)。种群由 N 个个体组成,每个个体对应一个染色体,染色体由一组基因构成。基因的编码方式与具体问题相关,比如在回归问题中可以表示特征权重,在分类问题中可以表示某种行为的存在或缺失。初始种群中的基因值通常是随机分配的,以确保算法的多样性。右侧的图展示了种群的结构,其中紫色框表示整个种群,绿色框表示单个染色体,红色框表示单个基因。这种结构是遗传算法的基础,用于模拟自然选择和进化过程。比如,如果基因编码为二进制值,可能表示某个特征是否被激活,这为后续的交叉和变异操作提供了灵活性。
这一页讲的是适应度函数(Fitness Function)在遗传算法(GA)中的作用及选择机制。关键点包括适应度评估、不同问题中的适应度定义,以及适者生存的原则。
这一页讲的是适应度函数(Fitness Function)的定义及其在遗传算法(GA)中的应用。适应度函数用于评估一个解与理想解的接近程度。在遗传算法中,适应度函数会为每个个体分配一个适应度值,用来衡量其表现。例如,在回归问题中,适应度可能是平方误差(squared error);在分类问题中,适应度可能是准确率(accuracy)或 F1 分数;而在仿真和游戏环境中,适应度可能是个体在环境中存活的回合数(与强化学习相关)。适应度高的个体会被选择传递基因到下一代,这体现了“适者生存”的原则。通过这样的选择机制,遗传算法能够不断优化解的质量。例如,在优化问题中,适应度函数可以帮助筛选出最优解或接近最优解的候选方案,从而提高算法效率和结果质量。
这一页讲的是适应度函数(Fitness Function)和选择(Selection)机制。适应度函数的作用是量化每个个体距离理想解有多近——它是 GA 里「环境压力」的数学化体现。不同问题的适应度函数形态差异很大:回归问题用均方误差,分类问题用准确率或 F1 分数,游戏/仿真场景则可以用「存活了多少回合」来衡量——这本质上就是强化学习(reinforcement learning)的奖励信号。选择的逻辑是:适应度高的个体被允许「繁殖」,把自己的基因传给下一代。注意这里说的是「被允许」,并非强制所有个体都能繁殖。考试高频问题:给定一个场景,如何设计适应度函数?比如「一个走迷宫的 agent」,适应度可以是到达终点的时间越短越好,或者剩余步数越多越好。易错点:适应度函数的设计本身就是 GA 效果好坏的关键——选错了适应度函数,算法会朝错误方向演化。另外要注意适应度函数在 NEAT 里与 speciation 中的「调整适应度」是不同的概念,后者是对原始适应度做了归一化处理。
这一页讲的是遗传算法中的交叉操作(Crossover)。主要包括交叉方法的多样性、单点交叉(Single-point Crossover)和均匀交叉(Uniform Crossover)的概念,以及精英保留(Elitism)策略。
这一页讲的是遗传算法中的交叉操作(Crossover),用于生成下一代个体。交叉操作通过混合适应度最高个体的基因来创建新的个体。幻灯片提到多种交叉方法,其中单点交叉(Single-point Crossover)是通过选择一个交叉点,将父代基因在该点分割并组合生成子代。图中展示了父代基因在交叉点分割后如何生成子代基因。另一种方法是均匀交叉(Uniform Crossover),每个位点随机选择一个父代基因进行组合,生成子代基因。图中显示了父代基因的每个位点如何随机选择生成子代。精英保留(Elitism)策略允许少量适应度最高的个体直接进入下一代而不进行交叉,确保优良基因的传递。最后,幻灯片明确指出并非所有个体都会参与交叉操作。交叉操作的重要性在于它能增强种群的多样性,同时保留适应度高的基因,从而提高算法的优化效果。
这一页讲的是遗传算法中的交叉(Crossover)操作以及精英保留(Elitism)策略。交叉是 GA 中产生新个体的核心遗传算子:从上一代适应度高的个体中各取部分基因,拼合出后代。最常见的是单点交叉(single-point crossover)——在染色体某位置切断,左边来自父本、右边来自母本(或反过来)。当基因顺序对表现型有重要意义时,选择切点位置就需要谨慎。精英保留(Elitism)是一种策略:让少数极优秀的个体直接「原封不动」地进入下一代,不参与交叉和变异,防止最好的解在进化中丢失。这是一个重要的考试概念,因为它体现了一种权衡:纯粹的选择压力 vs 多样性保持。页面还提到了一个问答:「所有个体都会发生交叉吗?」答案是否——只有被选中的高适应度个体才参与繁殖。考试易错点:很多人误以为交叉一定会产生比父代更好的后代——实际上不保证,需要后续评估再选择。单点交叉只是众多交叉方式之一,还有两点交叉、均匀交叉等。
这一页讲的是遗传算法中的变异(Mutation)操作。主要内容包括变异的定义、变异率的概念及其重要性,以及与交叉(Crossover)的关系。
这一页讲的是遗传算法(Genetic Algorithm, GA)中的变异(Mutation)操作。变异是一种基因操作,用于生成种群中的新个体。在具体实现中,可以随机翻转基因(对于二进制位)或扰动、重新分配基因值(对于权重)。变异率(Mutation Rate)是指基因或个体发生变异的概率,通常设定为较低的值,例如 0.01 或 0.001,以避免对种群结构造成过度扰动。交叉(Crossover)和变异都是遗传操作,它们共同模拟达尔文进化的过程,但实际应用中如何平衡两者的使用取决于具体问题。幻灯片中的图表展示了交叉和变异的效果:交叉通过交换父代基因生成新个体,变异则通过随机改变基因进一步增加种群的多样性。总的来说,在应用遗传算法时,需要探索多个参数,包括遗传操作的选择、变异率、种群规模以及适应度测试的长度和性质等。
这一页讲的是遗传算法中的变异(Mutation)操作和变异率(Mutation Rate)的设置原则。变异的作用是引入种群中原本不存在的新基因变体,防止算法过早收敛到局部最优。常见变异方式有两种:如果基因是二进制位,就随机翻转某些位(bit flip);如果基因是连续权重,就对其施加随机扰动(perturb)或直接随机重赋值。变异率通常设置得很低,典型值是 0.01 到 0.001——如果太高,算法退化成随机搜索;如果太低,种群多样性不足,容易陷入局部最优。页面指出:交叉和变异都是遗传算子(genetic operators),具体依赖哪个更多是问题相关的选择。GA 的超参数非常多:种群大小、变异率、适应度测试的长度和形式……这些都需要针对问题调优。考试常考:变异的根本目的是什么(引入多样性/新变体)?变异率过高会怎样(随机搜索,失去进化方向)?易错点:不要把变异误解为「改进」——变异是随机的,多数变异是中性甚至有害的,只有极少数变异碰巧产生更高适应度的个体。
这一页讲的是遗传算法(GA)的应用。主要包括配置与调度、金融投资组合优化、车辆路径规划和蛋白质折叠。遗传算法适用于广阔搜索空间,并利用领域直觉嵌入适应度函数和变异交叉策略。
这一页讲的是遗传算法(Genetic Algorithm, GA)的应用场景及其特点。遗传算法是一种搜索解决方案的方式,特别适用于广阔的搜索空间,比如传统的搜索方法(如广度优先、深度优先)难以处理的情况。具体应用包括配置与调度(Configuration and scheduling),用于优化资源分配;金融投资组合优化(Financial portfolio optimization),帮助设计最优投资组合;车辆路径规划(Vehicle routing),在物流和运输领域优化路径;以及蛋白质折叠(Protein folding),在生物信息学中预测分子结构。遗传算法的优势在于,它将领域的直觉嵌入到适应度函数(Fitness function)中,并通过交叉(Crossover)和变异(Mutation)策略进行优化。这种方法不仅能处理复杂问题,还能通过模拟自然选择的过程找到近似最优解。例如,在投资组合优化中,遗传算法可以通过模拟不同投资组合的“进化”,找到风险与收益平衡的最佳方案。
这一页讲的是 NEAT 算法如何通过遗传算法 (GA) 优化神经网络结构。重点包括基因组编码节点和边,以及初始连接和权重的设置。
这一页讲的是 NEAT (NeuroEvolution of Augmenting Topologies) 算法,它利用遗传算法 (GA) 来优化神经网络结构。NEAT 的核心是基因组 (genome),它编码了神经网络的节点和边。初始状态下,所有输入节点都直接连接到输出节点,没有隐藏节点(例如图中的节点 5 是通过后续变异添加的)。权重在初始时是随机分配的。幻灯片中的表格展示了基因组的具体编码方式:列出了节点类型(传感器、输出、隐藏)以及连接信息,包括输入节点、输出节点、连接权重、是否启用,以及创新编号 (Innov)。例如,连接从节点 1 到节点 4 的权重是 0.7,状态为启用,创新编号为 1。这张图还展示了基因型 (Genotype) 如何映射为网络表型 (Phenotype),即具体的神经网络结构。图中的箭头表示节点间的连接,节点 5 是隐藏节点,通过变异添加。NEAT 的这种编码方式能够有效支持结构的动态进化,从而找到更优的网络拓扑。
这一页讲的是 NEAT 算法如何用染色体(genome)对神经网络进行编码,以及初始状态的设定。NEAT 中每个个体的「基因组」直接编码了神经网络的节点(nodes)和边/连接(connections/edges)。初始状态非常简单:所有输入节点直接连接到输出节点,没有任何隐藏节点,权重随机初始化。这种极简起点是 NEAT 的设计哲学的体现:从最小结构开始,让复杂性通过进化逐步增长,而不是从一个大的固定结构出发再剪枝。这和传统神经网络的做法截然不同——传统方法通常预先固定网络拓扑,只优化权重;NEAT 同时优化权重和结构。图中节点 5 是一个通过变异后来加入的隐藏节点,说明结构是动态增长的。考试关键点:NEAT 的染色体编码了什么?答:节点基因(node genes)和连接基因(connection genes)。初始网络的结构如何?答:所有输入直连输出,无隐藏节点。易错点:不要忘记「权重」也是基因组的一部分——连接基因既包含拓扑信息(哪两个节点相连)也包含权重值。
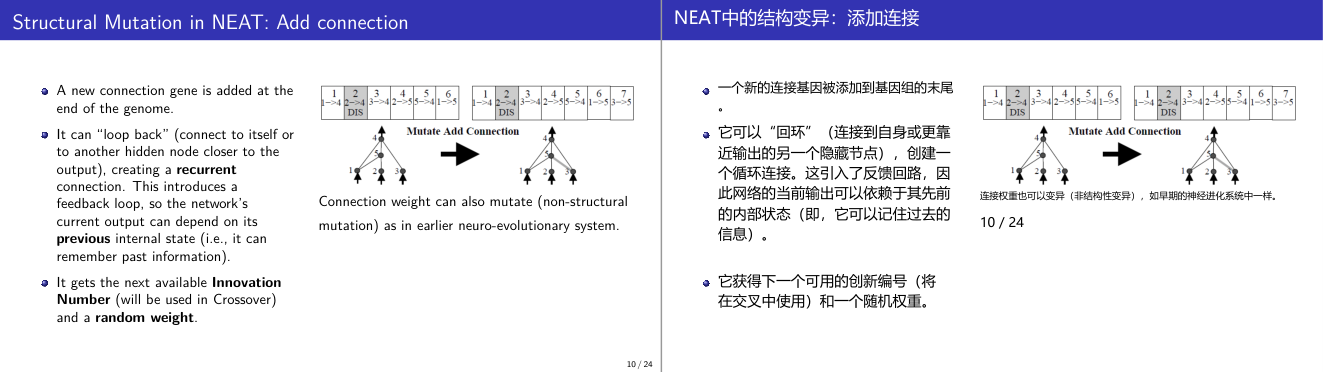
这一页讲的是 NEAT 中的结构突变:添加连接。主要包括新增连接基因、递归连接和创新编号的使用。
这一页讲的是 NEAT(NeuroEvolution of Augmenting Topologies)中的结构突变,具体是添加连接(Add Connection)。首先,新增的连接基因会被添加到基因组末尾,这代表神经网络结构的扩展。新增连接可以形成递归连接(recurrent connection),即连接到自身或更靠近输出的隐藏节点。这种递归连接引入了反馈回路,使网络能够根据之前的内部状态生成当前输出,从而具备记忆过去信息的能力。此外,新增的连接会获得一个新的创新编号(Innovation Number),这是 NEAT 中用于交叉操作的重要标识,同时还会分配一个随机权重(random weight)。页面上的图表展示了基因组在添加连接前后的变化,新增的连接基因编号为 7,连接了节点 5 和 3。图中还提到连接权重可以发生非结构性突变(non-structural mutation),类似于早期的神经进化系统。这种机制的重要性在于,它允许网络结构和权重同时进化,从而提升适应性和表现能力。
这一页讲的是 NEAT 中的结构性变异之一:添加连接(Add Connection)。当这种变异发生时,基因组末尾新增一条连接基因,随机权重。这条新连接可以是从较低层节点到较高层节点的前向连接,也可以是「回路」连接(loopback)——即连接到自身或更靠近输出的隐藏节点。这种回路连接创造了递归连接(recurrent connection),使网络能记住之前时间步的内部状态。这对于需要感知时序变化的任务至关重要:比如双杆平衡任务的「无速度输入」版本——网络必须通过检测两帧之间角度的变化来隐式估计角速度,而不是直接读取速度输入。每条新连接都获得一个「创新编号」(Innovation Number),这是 NEAT 的核心设计,用于跨代追踪同源基因,在后续交叉时对齐不同个体的基因组。考试高频点:recurrent connection 的意义是什么?创新编号的作用是什么(在交叉中对齐同源基因)?易错点:添加连接是非破坏性的——原有网络结构不变,只是新增了一条边,所以初始性能和变异前相同(新权重随机)。
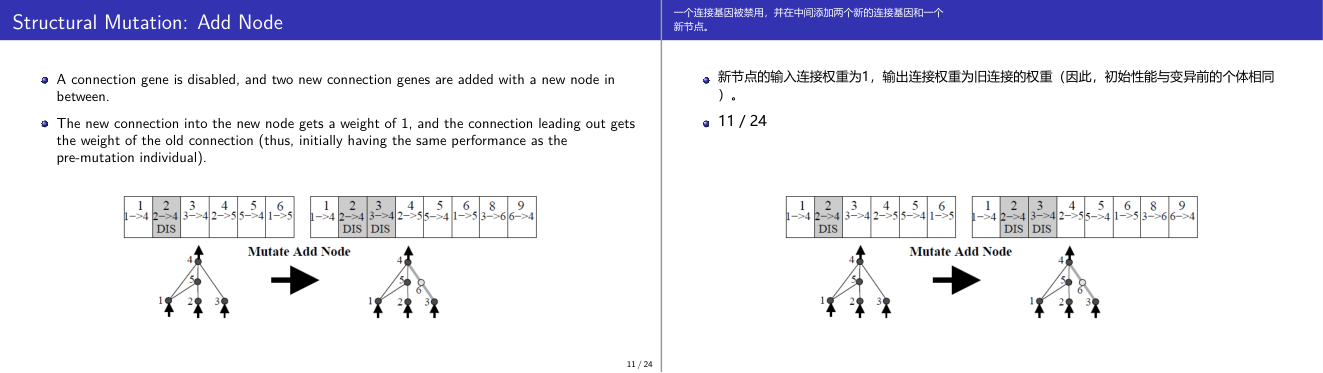
这一页讲的是结构突变中的 Add Node 操作。主要内容包括禁用连接基因、插入新节点及新增两条连接基因。
这一页讲的是结构突变(Structural Mutation)中的 Add Node 操作。首先,一个连接基因被禁用(DIS),然后在原连接中间插入一个新节点,并新增两条连接基因。新连接基因的权重设置为 1,而连接到新节点的权重继承原连接的权重,确保突变后初始性能与突变前个体一致。幻灯片中的表格展示了突变前后连接基因的变化:原来的连接基因 2->4 被禁用,新生成了 2->5 和 5->4 两条连接基因。图示进一步说明了这一过程,突变前图中直接连接的节点被分隔开,插入了一个新节点(节点 5),并通过两条新连接完成替代。这个操作对于神经网络结构优化非常重要,能够增加网络复杂度和表达能力,同时保持突变的稳定性。
这一页讲的是 NEAT 中的另一种结构性变异:添加节点(Add Node)。操作过程是:先禁用(disable)一条已有的连接基因,然后在这条连接的起点和终点之间插入一个新节点,再添加两条新的连接基因——进入新节点的连接权重设为 1,从新节点出来的连接继承原连接的权重。这种设计极其精妙:新节点插入后,整个网络的输出和变异前完全相同(因为 1 乘以原权重等于原权重),所以初始适应度不会因为添加节点而下降。这保证了结构变异不会立即破坏已经学到的功能,网络可以在此基础上进一步优化新节点的连接。这是 NEAT「最小化起点原则」的具体体现。考试重点:添加节点时新连接的权重分别是多少?进入节点的权重是 1,出去的权重继承旧连接。为什么这样设计?保持功能连续性,防止结构变异立即降低适应度。易错点:旧连接是被「禁用」(disabled)而不是删除——这条基因仍然保留在基因组里,只是标记为不活跃,后续有小概率被重新激活。
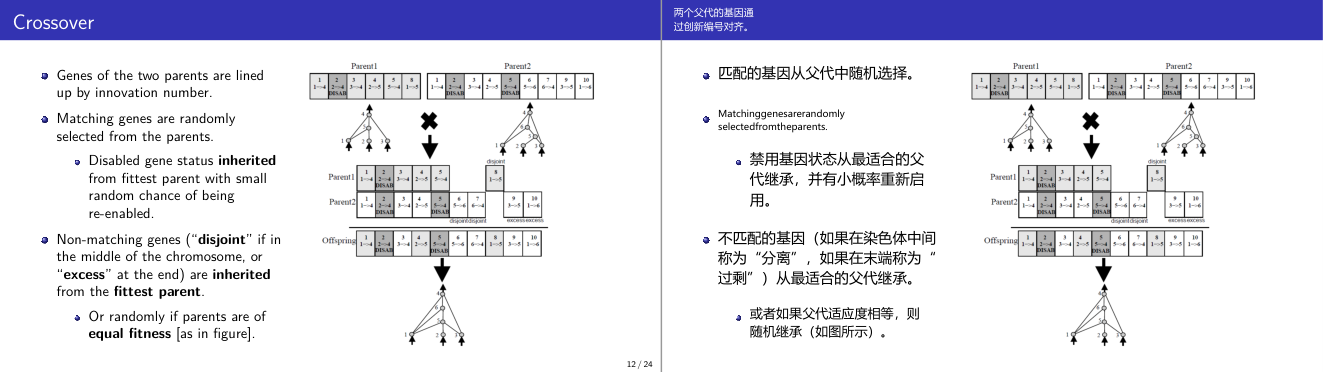
这一页讲的是基因交叉 (Crossover) 的机制。主要包括基因匹配的选择规则、非匹配基因的继承方式,以及父母基因如何影响后代基因的形成。
这一页讲的是基因交叉 (Crossover) 的具体机制。在遗传算法中,两个父母的基因通过创新编号 (Innovation Number) 对齐。匹配的基因会从父母中随机选择,若某基因被禁用 (Disabled),则从最优父母 (Fittest Parent) 继承,并有一定概率重新启用。对于非匹配基因,分为两种情况:如果位于染色体中间,称为“分离基因 (Disjoint Genes)”,如果位于染色体末端,称为“过剩基因 (Excess Genes)”。这些基因通常从最优父母继承,或者在父母适应度相等时随机选择。图中展示了具体的交叉过程:两个父母的基因分别对齐,匹配基因随机选择,分离和过剩基因根据规则继承,最终形成后代基因。这个过程确保了遗传多样性,同时保留了父母的优良特性。例如,父母1的禁用基因被继承到后代,但有可能重新启用。
这一页讲的是 NEAT 中最关键的机制之一:基于创新编号(Innovation Number)的交叉(Crossover)。NEAT 最大的技术挑战是:来自同一代不同个体的神经网络可能有完全不同的拓扑结构,如何对它们做有意义的交叉?答案就是创新编号——每一条连接基因在首次出现时都被赋予一个全局唯一的递增编号,代表「这条连接是第几个被发明出来的」。交叉时,把两个父代的基因组按照创新编号对齐,相同编号的基因叫做「匹配基因」(matching genes),从两个父代中随机选一个继承。创新编号不同的基因分两类:在范围中间的叫「不相交基因」(disjoint genes),在末尾超出范围的叫「超出基因」(excess genes)。这两类都从适应度更高的父代继承;如果两个父代适应度相等,则随机继承。另外,如果某基因在某个父代中被禁用(disabled),后代在继承时有小概率被重新激活。考试关键:matching、disjoint、excess 三类基因如何处理?创新编号的根本作用是什么?易错点:很多人忘记「从适应度更高的父代继承不匹配基因」这个规则——如果两个父代适应度相等,才随机选。
这一页讲的是 NEAT 的物种划分 (Speciation) 概念,用于保护创新。通过计算个体间的距离 δ,将相似个体分组为同一物种,避免新结构被淘汰。
这一页讲的是 NEAT (NeuroEvolution of Augmenting Topologies) 中的物种划分 (Speciation) 概念,目的是保护创新。NEAT 借鉴了达尔文进化中的物种概念,允许新结构在自己的群体中竞争并逐步优化,而不是直接被性能更好的现有网络淘汰。个体间的距离 δ 用公式计算:δ = c1E/N + c2D/N + c3W,其中 E 和 D 分别表示多余基因和分离基因的数量,W 是匹配基因的平均权重差异,c1、c2 和 c3 是可配置参数。通过设定阈值 δt,距离小于 δt 的个体被认为属于同一物种。这种机制确保了新结构有时间改进,而不是在早期阶段因为性能较差而被淘汰。例如,一个新网络结构可能初期表现不佳,但通过物种划分,它可以在自己的群体中逐步优化,最终超越现有网络。
这一页讲的是 NEAT 中的物种划分(Speciation)机制及其背后的个体距离公式。物种化解决的核心问题是「保护创新」(protecting innovation):一个刚出现的新结构在早期往往表现比成熟网络差,如果让它们直接在同一个种群里竞争,新结构会立即被淘汰,进化无法探索新方向。NEAT 的解法是:把相似的个体归为同一物种,让它们在物种内部竞争,给新结构时间成熟。判断两个个体是否属于同一物种,用一个距离公式:δ 等于 c1 乘以 E 除以 N,加上 c2 乘以 D 除以 N,加上 c3 乘以 W。其中 E 是超出基因数量,D 是不相交基因数量,W 是匹配基因的平均权重差异,N 是更大基因组的基因总数(用于归一化),c1、c2、c3 是可配置的超参数。如果两个个体的 δ 小于阈值 δt,它们就被划入同一物种。直觉上:拓扑结构越相似(匹配基因多)、权重越接近,δ 越小,越可能同种。考试高频:δ 公式中各项的含义?物种化的目的?易错点:N 是用来归一化的——这样公式对不同大小的网络都公平。c1、c2、c3 是人为设定的权重,需要根据问题调整。
这一页讲的是物种划分与繁殖配额的分配。主要包括如何根据距离划分物种、调整适应度的计算方式,以及如何根据调整后的适应度分配繁殖配额。
这一页讲的是物种划分与繁殖配额的分配。首先,个体会根据与前代随机选取的样本个体的距离被划分到物种中,如果与现有物种不兼容,就会形成新的物种。适应度(fitness)通过公式“个体适应度除以物种大小”进行调整,例如,物种 A 的适应度分别为 10, 8, 6, 12, 9,调整后分别为 2, 1.6, 1.2, 2.4, 1.8;物种 B 的适应度为 10, 8,调整后为 5, 4。然后,根据调整后的适应度总和分配下一代的繁殖配额。调整后的适应度总和决定物种的繁殖机会,例如物种 A 和 B 的调整后适应度总和均为 9,因此它们的繁殖配额比例为 1:1。这样既能让适应度高的物种获得更多个体,也能保护适应度较低、个体较少的物种不被淘汰。
这一页讲的是 NEAT 中物种分配与繁殖配额(Breeding Quota)的计算方式,包括适应度共享(Fitness Sharing)机制。每一代中,新个体和上一代的「代表个体」(随机从各物种中选出)计算距离 δ,距离小于阈值就归入该物种,否则独立成一个新物种。适应度调整的方法是「除以物种大小」:每个个体的调整适应度等于原始适应度除以该物种的成员数量。例如物种 A 有 5 个成员,适应度分别是 10、8、6、12、9,调整后分别是 2、1.6、1.2、2.4、1.8;物种 B 有 2 个成员,适应度 10 和 8,调整后是 5 和 4。两个物种调整适应度之和都是 9,因此繁殖配额 1:1 相等。这个机制的双重效果是:大种群反而被「惩罚」(分母大),小种群被「保护」(分母小),从而防止某一类结构占满整个种群,鼓励多样性。极低适应度的物种会自然消亡,但少量成员的物种因为分母小反而能存活更久。考试重点:调整适应度的计算公式;为什么这个机制能保护小物种?给定具体数字能计算出配额。易错点:这里的「调整适应度」求和才用于分配配额,不是单独的最大值。
这一页讲的是神经网络的评估任务,主要是通过小车平衡双杆的能力来测试其性能。重点包括任务环境和难度提升方法。
这一页讲的是神经网络的评估任务,环境是通过控制一个小车来平衡两根不同长度的杆,并根据系统稳定的时间长短来评估其适应性(fitness)。双杆平衡任务中,小车需要在有限轨道内来回移动,同时保持两杆的平衡。更高难度的版本要求算法在没有杆的角速度(angular velocity)或小车速度作为输入的情况下完成任务。为了实现这一点,需要引入递归节点(recurrent node),以检测时间步之间的角度变化。公式中,角速度被近似为角度变化量除以时间变化量,即 Δθ/Δt。图示展示了小车和双杆的动态结构,杆的角度 θ1 和 θ2 以及小车的受力情况 F。评估指标包括小车在轨道内保持杆角度在阈值内的时间步数,同时还需通过额外的适应性标准来减少速度、角速度和角度的振荡。这种任务用于测试神经网络的控制能力和稳定性。
这一页讲的是神经网络进化的流程(Pipeline)。主要包括初始化网络、模拟测试与适应度评估、选择高适应度网络、交叉变异和复杂化,最终进化出能平衡杆子的网络。
这一页讲的是神经网络进化的流程(Pipeline),通过模拟和遗传算法逐步优化网络性能。首先,初始化一组简单的神经网络,每个网络控制模拟中的小车,输出力来平衡杆子。接着运行模拟并测量每个网络的适应度(fitness),通常以杆子平衡的时间长度来评估。然后选择高适应度的网络进行保留(selection),并应用交叉(crossover)和变异(mutation)操作来生成新的网络。为了增加网络的复杂性,还会添加新的节点和连接。通过这一过程,形成下一代网络,这些网络随着时间推移变得越来越复杂。经过多代迭代,最终进化出一个能够成功平衡杆子的网络。这种方法模拟了生物进化的过程,能够自动优化网络结构和性能。一个例子是通过这种方法训练一个能在动态环境中控制机器人的小车。
这一页讲的是 NEAT 的评估结果和消融实验分析。NEAT 比之前的方法更快完成任务,消融实验验证了其创新组件的重要性。
这一页讲的是 NEAT 的评估结果和消融实验分析。NEAT(NeuroEvolution of Augmenting Topologies)比当时最好的神经进化方法更快完成任务,证明了其效率和优势。消融实验(ablation)是通过去除某些组件并与完整版本进行比较来评估每个组件的重要性。Stanley 和 Miikkulainen 进行了四种消融实验:1)使用固定的全连接网络,2)从比最小网络更大的结构开始,3)禁用物种划分(speciation),4)禁用交叉(crossover,仅使用突变)。结果显示,所有被消融的版本学习速度更慢,甚至无法完成任务。这表明 NEAT 的创新组件对其性能至关重要。例如,物种划分可以保护创新,交叉可以有效结合有益的特性,这些机制共同提升了算法的表现。
这一页讲的是针对 NEAT 各关键组件的消融实验(Ablation Analysis)结果。消融实验是机器学习中验证各模块贡献的标准方法:每次去掉一个组件,比较去掉前后的性能差异,从而判断该组件是否真的有用。Stanley 和 Miikkulainen 在双杆平衡任务上测试了四种消融版本:1) 固定全连接网络(不允许结构进化);2) 从比最小结构更大的网络出发;3) 禁用物种化(speciation);4) 禁用交叉(只用变异)。结果是四种消融版本都比完整版 NEAT 更慢,甚至有的无法完成任务。这有力证明了 NEAT 的三大核心创新——结构进化、物种化、交叉——各自独立地贡献了性能。消融实验在 AI 论文中非常常见,考试里可能会问:什么是 ablation study?它的目的是什么?答:系统地移除某个组件来检验其必要性,证明模型设计是合理的,不存在无用的复杂性。易错点:消融实验结果「更慢」并不等于「完全失败」——有的版本最终也能学会,只是需要更多代数;有的则完全无法掌握任务。这两种情况都说明被消融的组件是重要的。
这一页讲的是 NEAT 的应用。NEAT 可用于搜索最佳配置和路径,特别适合游戏策略。其生成的小型神经网络可能有助于可解释性。
这一页讲的是 NEAT (NeuroEvolution of Augmenting Topologies) 的应用。NEAT 和遗传算法 (GAs) 类似,适用于搜索最佳配置、调度和路径等问题。此外,NEAT 在游戏策略中有特别的应用价值。例如,幻灯片提到两个视频,一个是关于 NEAT 如何解决“Flappy Bird”的问题,另一个展示了 NEAT 玩“大富翁”的过程,这些展示了 NEAT 在复杂游戏中的潜力。最后,NEAT 的一个额外优势是它生成的小型神经网络,这可能有助于提高模型的可解释性。例如,小型网络更容易分析其决策过程,从而帮助理解模型行为。这种特性对需要透明度的领域尤为重要,例如医疗或金融。
这一页讲的是总结内容,涵盖遗传算法(GA)、NEAT方法和软计算策略的应用。重点包括GA的迭代优化机制、NEAT在控制和游戏中的优势,以及软计算在不确定性问题中的应用。
这一页讲的是总结遗传算法(Genetic Algorithm, GA)、NEAT方法和软计算策略(Soft Computing Strategies)的应用。遗传算法通过适应度函数(fitness function)驱动,结合解的交叉(crossover)和变异(mutation),在多代中不断优化解决方案。NEAT是一种特定的遗传算法方法,专门用于创建节点数较少的神经网络以解决问题,尤其在控制和游戏领域表现出色。此外,软计算策略被用于处理不确定性或近似解问题,分为两种主要类型:一种基于专家知识表示,例如模糊逻辑(Fuzzy Logic);另一种基于机器学习,如标注数据的监督学习或强化学习(Reinforcement Learning),代表方法包括朴素贝叶斯(Naïve Bayes)和NEAT。这些方法的结合展示了在不同场景下创建人工智能解决方案的多样性和灵活性。
这一页讲的是参考文献,列出了与神经进化和团队协作相关的三篇重要论文。
这一页讲的是参考文献,主要列举了三篇与神经进化(Neuroevolution)和相关应用领域的重要研究论文。第一篇是 Kassahun 等人在 2008 年发表的,讨论了如何使用 Kalman 滤波器加速神经进化方法,发表于 GECCO 会议。这篇文章的重点在于优化神经进化的效率。第二篇是 Stanley 和 Miikkulainen 在 2002 年发表的,介绍了通过拓扑结构扩展(Augmenting Topologies)来进化神经网络的技术,发表在《Evolutionary Computation》期刊。这篇研究奠定了 NEAT(NeuroEvolution of Augmenting Topologies)方法的基础。第三篇是 Wittkamp 等人在 2008 年的论文,探讨了如何在 Pacman 游戏中使用 NEAT 方法实现持续适应和团队协作,发表在 CIG 会议。这三篇文献为神经进化领域提供了理论支持和实践应用的案例,适合进一步深入学习这些技术的原理和应用场景。
这一页讲的是遗传算法中 mutation 的主要目的,选项包括保留最佳个体、引入新变异和选择最优个体。
这一页讲的是遗传算法(Genetic Algorithm)中的 mutation(变异)操作的主要目的。mutation 是遗传算法中的一个关键步骤,它的主要作用是引入新的变异(Introduce new variations into the population),即通过随机改变个体的基因来增加种群的多样性。这种操作可以防止算法陷入局部最优解,同时为搜索空间带来更多可能性。选项 A 和 C 分别提到保留最佳个体和选择最优个体,这些操作通常由遗传算法中的其他步骤(如选择和交叉)完成,而不是 mutation 的主要功能。mutation 的重要性在于维持种群的进化能力,特别是在种群趋于单一时,它可以帮助恢复多样性。例如,在优化问题中,如果种群中的所有解都趋于相似,mutation 可以随机改变某些解,从而探索新的解空间。
这一页讲的是 NEAT 中加入 recurrent connection 的优势。主要包括三个选项:减少节点数量、记住过去信息、加速交叉操作。
这一页讲的是 NEAT(NeuroEvolution of Augmenting Topologies)中加入 recurrent connection(循环连接)的优势。循环连接允许网络拥有记忆能力,可以存储和使用过去的信息,从而增强模型处理时间序列数据的能力。这在选项 B 中有所体现,即“允许网络记住过去信息”。选项 A 讨论了减少节点数量,但这并不是循环连接的主要功能;选项 C 提到加速交叉操作,这也不是循环连接的核心优势。因此,正确答案是 B。这一功能在处理动态环境或序列数据时非常重要,例如自然语言处理或时间序列预测。
这一页讲的是 NEAT 中 speciation 的目的,包括保护新结构免于过早淘汰。
这一页讲的是 NEAT (NeuroEvolution of Augmenting Topologies) 中的 speciation(物种划分)机制。其主要目的是保护新结构免于过早淘汰,从而促进多样性和创新。在进化算法中,新的结构可能在初期表现较差,但有潜力随着进化而优化。如果没有物种划分,这些结构可能会因竞争力不足而被淘汰。通过将个体分成不同的物种,NEAT 能够减少直接竞争,允许新结构在较小的群体中慢慢发展。此外,speciation 还能帮助维持种群的多样性,避免整个种群陷入单一解决方案的局限性。选项 B 是正确答案,因为它强调了保护新结构的重要性。
这一页讲的是结束语和问答环节。感谢听众参与,并开放提问。
这一页讲的是幻灯片的结束部分,表达了对听众的感谢,并邀请大家进行问答交流。这通常是一个总结和互动的环节,讲者可以回答听众的问题,澄清内容,或者针对具体问题进行深入讨论。这种设计有助于强化讲座的效果,同时增进讲者与听众之间的互动。问答环节可以帮助听众解决疑问,加深对内容的理解,也能让讲者了解听众的关注点和反馈,从而进一步优化内容。