第 1 / 14 页

这一页讲的是关于 AlphaGo 的课程介绍。主要内容包括课程名称、编号以及授课老师信息。
空格=播放/暂停当前页 · Tab=切换 简短/详细/深入 · 红色「深入」为重点页的深度讲解
这一页讲的是关于 AlphaGo 的课程介绍。主要内容包括课程名称、编号以及授课老师信息。
这一页讲的是 AlphaGo 的课程概述,属于奥克兰大学的课程 COMSPCI 713: AI Fundamentals(人工智能基础)。课程主要聚焦于 AlphaGo 的相关知识,这是人工智能领域的一个重要里程碑。幻灯片显示课程日期为 2025 年 4 月 28 日,授课老师为 Thomas Lacombe。AlphaGo 是由 DeepMind 开发的一款围棋人工智能程序,它通过深度学习(Deep Learning)和强化学习(Reinforcement Learning)技术,在围棋领域取得了突破性成果。这门课可能会探讨 AlphaGo 的技术原理、训练方法以及它对人工智能发展的影响,例如如何通过神经网络模拟人类决策过程。

这一页讲的是学习目标,包括AlphaGo的主要组成部分和训练过程的解释。
这一页讲的是学习目标,重点是了解AlphaGo的主要组成部分以及训练AlphaGo的过程。AlphaGo是一个基于深度学习和强化学习的人工智能系统,它的核心组件包括策略网络(Policy Network)、价值网络(Value Network)和蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)。策略网络负责预测下一步的行动,价值网络评估当前局面的胜率,而MCTS通过模拟多种可能的棋局路径来优化决策。训练AlphaGo的过程结合了监督学习和强化学习,其中监督学习通过人类棋谱训练模型,强化学习则通过自我对弈不断优化策略。理解这些目标有助于掌握AlphaGo的工作原理及其在人工智能领域的创新意义。

这一页讲的是 AlphaGo 纪录片的内容及其关键问题,包括训练方式、核心组件和预测流程。
这一页讲的是 AlphaGo 纪录片(2017)的内容,重点是通过观看选定片段回答几个关键问题。首先,探讨 AlphaGo 是如何被训练的,这涉及监督学习和强化学习等方法。其次,分析 AlphaGo 的三个核心组件,包括策略网络(policy network)、价值网络(value network)和蒙特卡洛树搜索(Monte Carlo Tree Search)。第三,解释 AlphaGo 在预测时遵循的流程,如何结合策略网络和价值网络进行决策优化。最后,明确 AlphaGo 的目标,即在预测过程中最大化获胜概率。通过这些问题,可以深入理解 AlphaGo 的设计原理及其在围棋领域的突破性表现。例如,AlphaGo 的训练过程通过模拟大量棋局来学习最佳策略,其预测流程则通过搜索和评估来选择最优步骤。

这一页讲的是 AlphaGo 的训练与预测过程,以及小组讨论的流程安排。主要问题包括 AlphaGo 的训练方式、关键组件、预测过程和目标。
这一页讲的是 AlphaGo 的训练和预测机制,同时安排了一个小组讨论活动。首先,幻灯片提出了四个问题:AlphaGo 是如何训练的?它的三个关键组件是什么?在预测过程中如何利用这些组件?以及 AlphaGo 在预测时的目标是什么?这些问题旨在帮助学生理解 AlphaGo 的工作原理,例如监督学习和强化学习的结合、深度神经网络的应用等。此外,右侧列出了讨论的具体流程:先用 5-10 分钟与同学交流答案,然后将小组答案输入 Mentimeter 平台,最后通过 GenAI 汇总讨论结果。这种互动式学习方式不仅能加深对 AlphaGo 的理解,还能促进团队合作和知识分享。

这一页讲的是 AlphaGo 的训练方法、核心组件及预测过程。重点包括初始训练、人类数据与自我对弈结合的学习方式,三大关键组件:Policy Network、Value Network 和 Tree Search,以及预测的具体流程和目标。
这一页讲的是 AlphaGo 的训练过程、关键组件及其预测机制。首先,AlphaGo 的训练分为三个阶段:初始训练阶段通过超过 10 万局人类棋手对弈数据学习基本策略和模式;强化学习阶段通过自我对弈提升策略;最后结合监督学习和强化学习。这种训练方式帮助 AlphaGo 掌握复杂的围棋策略。其次,AlphaGo 的三大关键组件包括:Policy Network(策略网络),预测在当前棋盘状态下最优的下一步棋;Value Network(价值网络),评估棋盘状态并估算不同位置的胜率;Tree Search(树搜索),模拟未来可能的棋局变化以寻找最佳选择。最后,AlphaGo 的预测过程包括分析当前棋盘状态、使用策略网络提出可能的走法、通过树搜索探索所有可能的棋局序列、利用价值网络评估这些走法的胜率,最终选择胜率最高的一步棋。AlphaGo 的目标是最大化获胜概率,而不是考虑获胜的速度或分差。这种设计使其能够在复杂棋局中找到最优解。

这一页讲的是围棋对人工智能的挑战,包括搜索空间巨大、决策复杂以及奖励延迟等问题。
这一页讲的是围棋(Game of Go)对人工智能(AI)提出的挑战。首先,围棋的搜索空间非常庞大,大约有 10 的 170 次方个合法棋盘状态,而国际象棋只有约 10 的 47 次方。这意味着围棋无法通过暴力搜索(brute-force search)解决问题。其次,围棋的平均棋局提供约 200 个合法走法,而国际象棋平均只有约 35 个。这使得每一步决策都非常复杂,需要AI在大量可能性中选择最佳策略。此外,围棋缺乏明确的启发式规则(heuristics),并且奖励通常是延迟的(delayed rewards),这使得评估某一步是否有助于最终胜利变得困难。这张幻灯片右侧的棋盘图展示了围棋的复杂性,棋子分布密集且变化多端,进一步说明了围棋对AI提出的高要求。一个例子是AlphaGo的开发,它需要结合深度学习和蒙特卡洛树搜索等技术来应对这些挑战。
这一页讲的是围棋对 AI 的挑战,以及为什么传统的暴力搜索(brute-force search)在围棋上完全失效。围棋棋盘是 19x19,合法的棋局状态数约为 10 的 170 次方,相比之下国际象棋只有 10 的 47 次方——这个差距是天文数字级别的。更麻烦的是,围棋每一步平均有约 200 种合法走法,而国际象棋只有 35 种,这意味着搜索树在每一层都会爆炸性地增宽。此外,围棋缺乏清晰的局面启发式(heuristics):在象棋里你可以用棋子价值之和来粗估局面优劣,但围棋的局面评估极其困难,而且胜负要到终局才能判断,中间的每一步落子是否有利往往要等几十手才能体现,这就是所谓的「延迟奖励(delayed reward)」问题。这三重困难——搜索空间巨大、分支因子大、无明显启发式——共同说明了为什么在 AlphaGo 出现之前,AI 在围棋上远不如在象棋上表现好。考试易考点:能不能准确说出围棋 vs 象棋的数量级对比(10^170 vs 10^47,分支因子 200 vs 35),以及 delayed reward 的含义。一个容易混淆的地方是:搜索空间大不等于分支因子大,这两个是独立的挑战;而「没有明确启发式」是独立于搜索空间大小的第三个挑战。举例:如果每步有 200 种走法,搜索 5 步深度就要枚举 200^5 = 3200 亿个节点,这根本无法实时完成。
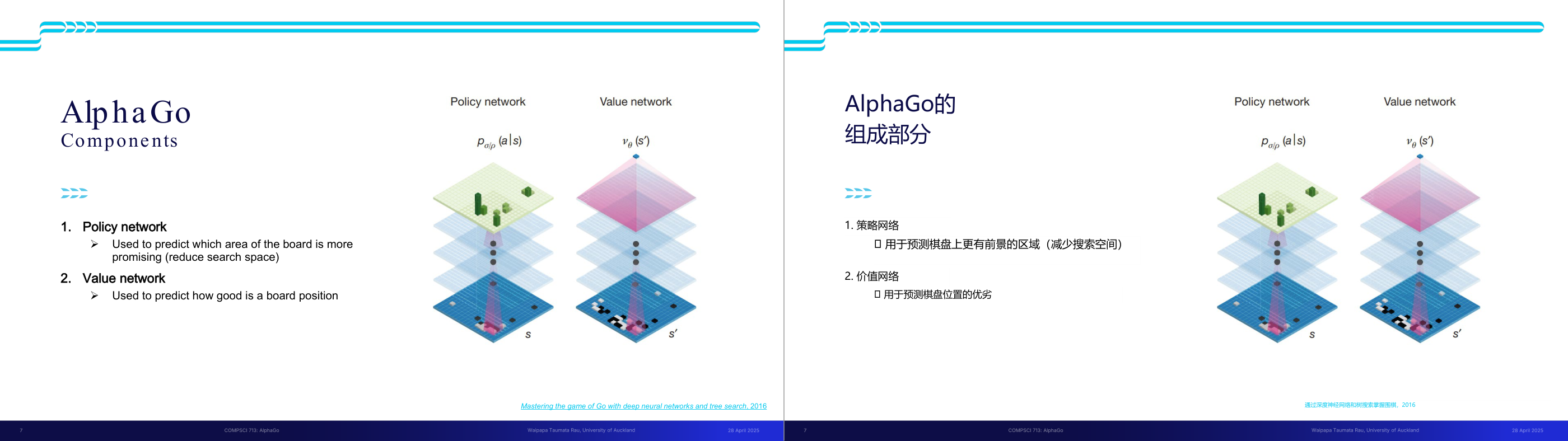
这一页讲的是 AlphaGo 的两个核心组件:Policy network 和 Value network。Policy network 用于预测棋盘上更有潜力的区域,减少搜索空间;Value network 用于评估当前棋盘位置的优劣。
这一页讲的是 AlphaGo 的两个核心组件:Policy network(策略网络)和 Value network(价值网络)。Policy network 的作用是预测棋盘上哪些区域更有潜力,通过减少搜索空间来提高效率。图中绿色的部分代表策略网络对棋盘区域的评估,显示出某些点的优先级更高。Value network 的作用是预测当前棋盘位置的优劣,帮助评估某一局面是否值得继续深入。图中粉色的部分代表价值网络对棋盘状态的评分,显示出当前局面的综合价值。两者结合使 AlphaGo 能够在复杂的围棋局面中进行高效决策。例如,在实际对弈中,策略网络可以快速筛选出潜在的好棋点,而价值网络则进一步评估这些点的长期收益,从而做出最优选择。这种架构体现了深度学习与搜索算法的结合,是 AlphaGo 成功的关键。
这一页讲的是 AlphaGo 的两个核心神经网络组件:策略网络(policy network)和价值网络(value network)。策略网络的作用是预测「哪些区域更值得落子」——它输出的是棋盘上每个位置的概率分布,告诉搜索算法应该优先探索哪些候选走法,从而大幅压缩搜索空间。价值网络的作用是评估「当前局面有多好」——它输入一个棋盘状态,输出一个标量值,表示从这个状态出发最终赢棋的概率。两者分工明确:策略网络回答「走哪里」,价值网络回答「这个局面有多好」。这个设计的核心思想是将「宽度剪枝」和「深度剪枝」分开:策略网络帮助减少每个节点需要扩展的分支数(解决分支因子大的问题),价值网络帮助在不需要搜索到终局的情况下评估局面(解决延迟奖励的问题)。考试常考:区分两个网络的功能——策略网络是 move selector(告诉你往哪里走),价值网络是 position evaluator(告诉你这个位置有多好)。易错点是把两者混淆,或者忘记价值网络输出的是一个标量而策略网络输出的是概率分布。

这一页讲的是 AlphaGo 的策略网络和价值网络架构及其输入特征。主要内容包括输入数据的结构、策略网络和价值网络的层级设计,以及输入特征的具体描述。
这一页讲的是 AlphaGo 的策略网络(Policy Network)和价值网络(Value Network)的架构及其输入特征。首先,输入数据是一个 19x19x48 的图像堆叠,包含 48 个特征平面,每个平面代表围棋棋盘上的不同信息,例如棋子颜色、自由度(Liberties)、自杀点(Self-atari size)等。右侧的表格详细列出了这些特征平面及其描述,例如 'Stone colour' 有 3 个平面,分别表示棋子、对手棋子和空白点。策略网络是一个包含 13 层卷积神经网络(CNN),第一层使用 192 个 5x5 的滤波器,后续层使用 192 个 3x3 滤波器,最后通过 Softmax 输出 361 个棋盘位置和一个“Pass Move”。价值网络则是一个 15 层的 CNN,前 11 层与策略网络相同,第 12 层增加了一个卷积层,第 13 层使用 1x1 滤波器,第 14 层是一个全连接层,最终输出一个标量值(范围为 -1 到 1)。这些网络架构结合输入特征,帮助 AlphaGo 实现对围棋棋局的深度分析和决策。
这一页讲的是 AlphaGo 中策略网络和价值网络的具体架构细节,这是本讲最有技术含量的一页。输入是一个 19x19x48 的特征平面堆叠(feature planes stack):19x19 是棋盘尺寸,48 是描述每个位置的特征通道数(包括当前颜色的棋子、对手棋子、气数、合法性等)。策略网络(policy network)是 13 层 CNN:第一层用 192 个 5x5 的卷积核(padding=4,stride=1),目的是捕捉较大范围的局部模式;第 2 到 12 层用 192 个 3x3 的卷积核(padding=0,stride=1);每层后面跟批归一化(Batch Normalization,BN)和 ReLU 激活;最后输出层是一个 Softmax 层,输出 361+1=362 个概率值(19x19 个棋盘位置加上一个「过手(pass move)」的选项)。价值网络(value network)是 15 层 CNN:前 11 层与策略网络相同;第 12 层多加一个卷积层;第 13 层用 1 个 1x1 的卷积核后接 ReLU;第 14 层是 256 个单元的全连接层(FC)加 ReLU;输出层是 1 个单元的 FC 加 tanh 激活,输出一个介于 -1 到 1 之间的标量(-1 表示必输,1 表示必赢)。考试易考:为什么价值网络用 tanh 而不是 sigmoid?因为 tanh 输出范围是 [-1,1],可以自然地表示「赢/输」两个极端,而 sigmoid 范围是 [0,1];输出层只有 1 个神经元也需要记住,这与策略网络 362 个输出截然不同。

这一页讲的是 AlphaGo 的核心组成部分,包括策略网络(Policy network)、价值网络(Value network)和搜索算法(Search algorithm)。
这一页讲的是 AlphaGo 的三个核心组成部分及其功能。第一部分是策略网络(Policy network),它的主要作用是预测棋盘上哪些区域更有潜力,从而减少搜索空间,提高计算效率。第二部分是价值网络(Value network),用于评估当前棋盘位置的好坏,帮助系统判断局势。第三部分是搜索算法(Search algorithm),AlphaGo 使用蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS),通过探索从当前棋盘位置出发的可能棋局树,找到最优下一步棋。右侧的图展示了搜索算法的工作原理,节点和连接代表不同棋局及其可能的后续发展路径。这种结合深度神经网络和搜索算法的方法,使 AlphaGo 能够在围棋中实现超越人类的表现。举例来说,当 AlphaGo面对复杂棋局时,策略网络会先筛选出潜力区域,价值网络评估每个位置的优劣,最终通过搜索算法选择最佳落子位置。

这一页讲的是 AlphaGo 的训练过程,重点是策略网络 (Policy Network)。主要包括监督学习预测人类专家的下一步动作,以及通过自我对弈进行强化学习以最大化获胜概率。
这一页讲的是 AlphaGo 的训练过程,核心部分是策略网络 (Policy Network)。策略网络通过两种学习方式进行训练:第一是监督学习 (Supervised Learning),目标是预测人类专家在棋盘上的下一步动作。通过分析专家棋局数据,策略网络能够进行分类任务,从而学习到人类专家的决策模式。第二是强化学习 (Reinforcement Learning),通过自我对弈 (Self-play) 的方式训练,目标是最大化获胜的概率。图中展示了策略网络的不同阶段,包括 Rollout Policy、SL Policy Network 和 RL Policy Network,它们通过不同的学习方法逐步优化策略。图中还提到价值网络 (Value Network),通过回归 (Regression) 方法评估棋盘状态的价值。这一过程结合了神经网络和数据,如人类专家棋局和自我对弈生成的数据,从而实现 AlphaGo 的高效学习和决策能力。这种训练方式的关键在于结合监督学习和强化学习,使系统既能模仿专家,又能通过自我优化提升性能。
这一页讲的是 AlphaGo 完整的三阶段训练流程:策略网络的监督学习、强化学习,以及价值网络的训练。第一阶段,策略网络(policy network)先用监督学习(Supervised Learning,SL)训练:从 KGS 围棋服务器上采集了约 16 万局人类专家棋谱,目标是让网络预测「下一步人类专家会走哪里」,这是一个分类问题,用交叉熵损失。这一步让网络学会了人类棋手的基本策略直觉。第二阶段,同一个策略网络再用强化学习(Reinforcement Learning,RL)继续训练:让网络和自己的历史版本自我对弈(self-play),以「赢得对局」作为奖励信号,目标是最大化赢棋概率。这个过程中网络学会了超越人类思路的策略。注意:两阶段训练是串行的,先 SL 再 RL,RL 是在 SL 得到的网络基础上继续优化的。第三阶段,价值网络(value network)的训练是一个回归任务(regression):用已经训练好的策略网络进行自我对弈,生成大量「状态-结果」对(state-outcome pairs),价值网络的目标是最小化预测结果和真实结果之间的均方误差(Mean Squared Error,MSE),真实结果就是那局棋最终赢了(+1)还是输了(-1)。考试常考:三个网络(SL policy、RL policy、value network)各自的训练目标和损失函数是什么,以及训练顺序的依赖关系——价值网络必须等策略网络训练完才能训练。

这一页讲的是 AlphaGo 的训练过程,包括策略网络 (Policy Network) 和价值网络 (Value Network) 的作用及训练方法。
这一页讲的是 AlphaGo 的训练过程,主要包括两个核心部分:策略网络 (Policy Network) 和价值网络 (Value Network)。策略网络通过两种方式进行训练:第一是基于人类棋谱的监督学习 (Supervised Learning),目标是预测人类专家的下一步棋;第二是基于自对弈的强化学习 (Reinforcement Learning),目标是最大化获胜的概率。图中展示了策略网络的结构和数据流向,从人类专家的棋局到神经网络,最终生成策略概率。价值网络则通过状态-结果对的回归训练 (Regression),利用策略网络生成的自对弈数据,目标是最小化预测结果与实际结果之间的均方误差 (Mean Squared Error),例如预测胜负结果的准确性。图示中展示了神经网络如何处理自对弈数据,通过回归优化预测结果。这两个网络协同工作,帮助 AlphaGo 提升棋力,最终实现对围棋的掌握。

这一页讲的是 AlphaGo 的训练过程,重点包括策略网络 (Policy Network)、价值网络 (Value Network) 和回滚策略 (Rollout Policy)。
这一页讲的是 AlphaGo 的训练过程,分为三个主要部分:策略网络 (Policy Network)、价值网络 (Value Network) 和回滚策略 (Rollout Policy)。首先,策略网络通过监督学习 (SL) 和强化学习 (RL) 来优化棋步选择,分别利用人类专家棋局数据和自对弈数据进行训练。其次,价值网络预测当前棋局的胜率,用于评估棋盘状态的优劣。第三,回滚策略使用线性模型和 softmax 激活函数,结合手工设计的特征,例如棋子响应模式 (Response Pattern)、邻居关系 (Neighbour) 和最后一步距离 (Last Move Distance),生成当前状态下所有合法棋步的概率分布,目标是快速预测棋步以便采样。幻灯片中的表格列出了用于回滚策略和树策略的输入特征,包括特征名称、模式数量和描述,例如 'Save Atari' 表示拯救棋子的特定模式。右侧的流程图展示了策略网络和价值网络的训练流程,数据来源包括人类专家棋局和自对弈棋局。
这一页讲的是 AlphaGo 的第三个训练组件:快速走棋策略(rollout policy),以及它与主策略网络的关系和区别。Rollout policy 是一个轻量级的线性模型(linear model)加 softmax 激活,而不是深度 CNN。它使用的是手工设计的特征(hand-crafted features)和从当前状态直接计算出的特征,而不是通过卷积层自动学习的特征。输出是当前合法走法上的概率分布,目的是做「快速走棋采样(fast move prediction for sampling)」。为什么需要 rollout policy?在 MCTS(Monte-Carlo Tree Search)中,当搜索树达到一个叶节点时,需要进行快速模拟(rollout)来估计局面价值——如果每次都用 13 层 CNN 的策略网络来走完一局,速度太慢。Rollout policy 虽然精度不如主策略网络,但速度快得多,可以在每次搜索中完成数千次快速模拟。这是一个典型的「精度 vs 速度(accuracy vs speed)」的工程权衡。考试易考:三个网络(SL policy network、RL policy network、rollout policy)的对比——rollout policy 是线性模型而非 CNN,使用手工特征,速度快但精度低,专门用于 MCTS 中的快速模拟阶段。易错点是以为 rollout policy 和 policy network 是同一个东西,实际上它们是完全独立的模型,用途也不同。

这一页讲的是 AlphaGo 的训练方式、核心组成部分及预测过程。主要包括监督学习和强化学习训练;核心组件有 Policy network、Value network 和 Search algorithm;预测过程通过构建搜索树、评估棋局获胜概率来选择最佳下一步。
这一页讲的是 AlphaGo 的训练方式、核心组成部分及预测过程。首先,AlphaGo 的训练方式结合了监督学习 (Supervised learning) 和强化学习 (Reinforcement learning),通过学习人类棋手的对局数据以及自我对弈不断优化策略。其次,AlphaGo 的三个核心组成部分包括:Policy network(策略网络),用于建议下一步的棋子移动;Value network(价值网络),评估当前棋局状态的获胜概率;以及 Search algorithm(搜索算法),结合 rollout policy(展开策略)探索棋局的潜在发展。最后,AlphaGo 的预测过程分为五步:1. 搜索算法开始构建搜索树以探索未来的棋局变化;2. 策略网络建议可能的下一步棋子移动;3. 价值网络评估当前棋局状态的获胜概率;4. 根据评估结果更新搜索树;5. 重复步骤 2 至 4 多次后,搜索算法选择最佳下一步棋子移动。AlphaGo 的目标是在预测时最大化获胜概率,而不是追求获胜分差。这种方法使其能够在复杂棋局中做出高效决策,例如在围棋比赛中实现超越人类的表现。
这一页讲的是 AlphaGo 进行预测时的完整推理流程,也就是它如何把策略网络、价值网络和搜索算法三个组件整合起来,在实际对局中选出最优走法。整个流程可以分为五步:第一步,接收当前棋盘状态作为输入。第二步,策略网络(policy network)被用来提议有希望的候选走法——它输出一个概率分布,搜索算法优先扩展概率高的分支,从而避免浪费时间在明显不好的走法上。第三步,搜索算法(MCTS)以当前局面为根节点,开始构建搜索树,沿着策略网络推荐的方向扩展节点。第四步,价值网络(value network)对搜索树中的局面进行评估,给出赢棋概率估计,同时 rollout policy 也会快速模拟出对局结果,两者结合得到最终的局面评分。第五步,重复步骤 2-4 若干次(通常是数千次模拟)之后,搜索算法根据访问次数和评估值选择最终落子位置——目标是最大化赢棋概率(而不是最大化领先优势)。一个重要细节:AlphaGo 的目标是 maximise win probability,而不是最大化吃子数或领先分数,这意味着它会选择「最稳妥赢」的下法,而不是「赢得最多」的下法。考试易考:能完整描述这五步预测流程,以及「最大化赢棋概率而非赢棋幅度」这个关键设计选择。整合考查:能把训练流程(SL+RL+价值网络回归+rollout policy)和推理流程(五步预测)串联起来描述,是回答大题的关键。

这一页讲的是接下来两周的课程安排,主题包括搜索算法和强化学习。
这一页讲的是接下来两周的课程内容安排,重点围绕 AlphaGo 的相关技术展开。第八周的主题是树搜索 (Tree Search) 和搜索算法 (Search Algorithms),其中包括蒙特卡洛树搜索 (Monte Carlo Tree Search, MCTS)。树搜索是一种重要的搜索技术,广泛应用于游戏和决策问题中,而 MCTS 是一种基于随机采样的优化方法,可以有效地探索大型搜索空间。第九周的主题是强化学习 (Reinforcement Learning),这是一种通过与环境交互来学习策略的机器学习方法。强化学习在 AlphaGo 中扮演了关键角色,它帮助模型通过试错学习如何在复杂的棋局中做出最优决策。这两周的内容对于理解 AlphaGo 的核心技术非常重要,既涉及搜索算法的优化,也涵盖了学习策略的构建原理。