第 1 / 18 页

这一页讲的是 AlphaGo 的课程介绍,包括课程名称和讲师信息。
空格=播放/暂停当前页 · Tab=切换 简短/详细/深入 · 红色「深入」为重点页的深度讲解
这一页讲的是 AlphaGo 的课程介绍,包括课程名称和讲师信息。
这一页讲的是 AlphaGo 的课程介绍,属于 University of Auckland 的 COMSPCI 713: AI Fundamentals(人工智能基础)课程。幻灯片标题明确指出本次讲座的主题是 AlphaGo,这是一种基于深度学习和强化学习的人工智能程序,以其在围棋领域的突破性表现而闻名。页面底部还提供了讲座日期(2026年5月4日)和讲师信息(Thomas Lacombe)。这一页主要是课程的开场信息,帮助学生明确学习内容和时间安排,为后续深入探讨 AlphaGo 的技术原理和应用铺垫。

这一页讲的是AlphaGo的学习目标,包括其主要组成部分和训练过程的解释。
这一页讲的是AlphaGo的学习目标,主要分为两个方面:第一,描述AlphaGo的主要组成部分;第二,解释训练AlphaGo的具体过程。AlphaGo是一种基于深度学习和强化学习的人工智能系统,其核心组成包括策略网络(policy network)、价值网络(value network)以及蒙特卡洛树搜索(Monte Carlo Tree Search)。这些组件协同工作,使AlphaGo能够评估棋局并选择最佳动作。训练过程通常分为监督学习(supervised learning)和强化学习(reinforcement learning)两个阶段。监督学习通过人类棋谱训练策略网络,而强化学习则通过自我对弈优化策略和价值网络。通过这些步骤,AlphaGo实现了从初级棋力到超越人类水平的飞跃。理解这些目标有助于深入掌握人工智能的设计和训练方法。

这一页讲的是 AlphaGo 的纪录片活动,重点是通过观看片段回答四个问题,包括训练方式、关键组成部分、预测过程及目标。
这一页讲的是 AlphaGo 的纪录片活动,旨在通过观看选定的片段来探讨 AlphaGo 的核心工作原理。幻灯片列出了四个问题:第一,AlphaGo 是如何训练的?这涉及其使用的机器学习方法,例如监督学习和强化学习。第二,AlphaGo 的三个关键组成部分是什么?可能包括策略网络(policy network)、价值网络(value network)和蒙特卡洛树搜索(Monte Carlo Tree Search)。第三,AlphaGo 如何结合这些组成部分进行预测的过程?这通常是通过策略网络生成动作概率,价值网络评估局面,结合蒙特卡洛树搜索优化决策。最后一个问题是 AlphaGo 在预测时的目标是什么?一般来说,其目标是最大化获胜概率,同时选择最优的棋步。通过这些问题,学生可以更好地理解 AlphaGo 的技术架构及其在人工智能领域的重要性。

这一页讲的是集体讨论 AlphaGo 的相关问题及流程。主要包括 AlphaGo 的训练方式、关键组件、预测过程及目标,讨论后用 Mentimeter 和 GenAI 总结答案。
这一页讲的是关于 AlphaGo 的集体讨论任务,重点探讨其训练方式、关键组成部分、预测过程以及目标。幻灯片列出了四个问题:第一,AlphaGo 是如何训练的?第二,它的三个关键组件是什么?第三,它在预测时遵循了哪些过程,如何利用这些组件?第四,它在预测时的目标是什么?此外,右侧描述了讨论的流程:首先,同学们需要花 5-10 分钟与身边的同学讨论这些问题;然后,将小组答案输入到 Mentimeter 平台;最后,利用 GenAI 创建答案的总结。这一页强调了团队合作和技术工具的结合,通过讨论和技术总结可以更好地理解 AlphaGo 的工作原理,例如深度学习和强化学习在其中的应用。
这一页讲的是围棋对 AI 的挑战,包括搜索空间巨大、决策复杂以及奖励延迟等问题。
这一页讲的是围棋对 AI 的挑战。首先,围棋的搜索空间非常庞大,约为 10 的 170 次方,而国际象棋的搜索空间仅为 10 的 47 次方。这意味着无法通过暴力搜索(brute-force search)解决围棋问题。其次,围棋每个位置平均有约 200 个合法走法,而国际象棋只有约 35 个。这使得每一步的决策变得更加复杂,AI 需要在大量选项中快速找到最佳策略。此外,围棋没有明确的启发式规则(heuristics),且奖励通常是延迟的。这意味着很难评估某一步是否会增加获胜的概率。例如,某一步可能在短期内看起来无关紧要,但在长远的局势中可能是关键。这些特点使得围棋成为 AI 研究中的一个重要挑战,也是 AlphaGo 等系统取得突破的原因。
这一页讲的是围棋(Go)对人工智能来说为什么极其困难,是整个 AlphaGo 讲座的动机背景。核心难点有三个。第一,搜索空间巨大。围棋合法棋盘局面数约为 10 的 170 次方,而国际象棋只有约 10 的 47 次方。这个数字已经远超宇宙中的原子数,所以传统国象 AI 常用的「暴力穷举所有走法」在围棋完全不可行——哪怕用超级计算机也算不完。第二,每步分支因子很大。围棋每步平均约有 200 种合法走法,国象只有约 35 种。这意味着搜索树的宽度比国象宽 5-6 倍,深度又非常长,搜索树规模指数爆炸。第三,没有清晰的启发式函数,而且奖励延迟。国象可以靠数子力(车、马、象的分值)粗估局面优劣;围棋「一盘棋最后谁围的地多谁赢」,中途很难用简单规则判断当前局面的好坏,奖励只在游戏结束时才给出。这三点合在一起,解释了为什么传统方法(minimax+alpha-beta 剪枝+手工启发式)在围棋上长期失败。考试常见考法:「为什么传统 minimax 搜索不适合围棋?」答案就是这三点——搜索空间量级、分支因子、以及缺乏有效的中间评估函数。易错点:不要只说「围棋比国象复杂」而忘记说明数量级差异和延迟奖励这两个本质原因。
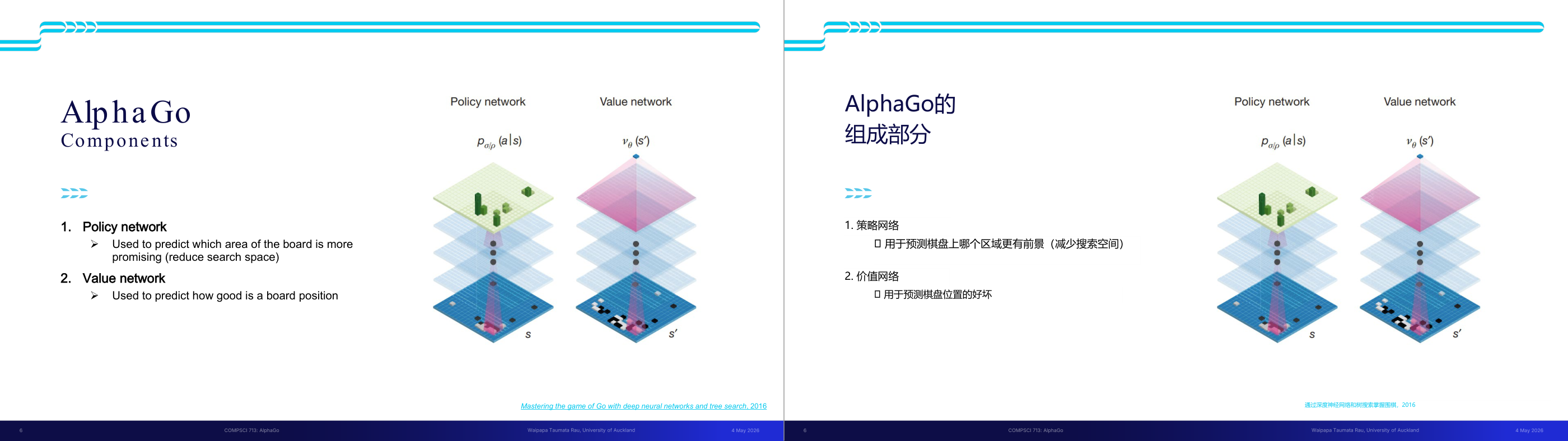
这一页讲的是 AlphaGo 的两个核心组件:Policy network 和 Value network。Policy network 用于预测棋盘中更有潜力的区域,减少搜索空间;Value network 用于评估当前棋盘位置的好坏。
这一页讲的是 AlphaGo 的两个核心组件:Policy network 和 Value network。Policy network(策略网络)主要用于预测棋盘中哪些区域更有潜力,从而减少搜索空间。它通过输入当前棋盘状态 s,输出一个概率分布 p(a|s),表示在给定状态下选择不同动作的可能性。这种方法可以帮助 AlphaGo更快地找到优先考虑的棋盘区域。Value network(价值网络)则用于评估当前棋盘位置的好坏。它通过输入棋盘状态 s,输出一个数值 v(s),表示该状态的优劣程度。图中展示了这两个网络的结构:左侧的绿色图层代表策略网络,右侧的粉色图层代表价值网络。两者通过深度神经网络处理棋盘数据,分别优化决策和评估过程。例如,在围棋比赛中,策略网络可以优先考虑某些关键区域,而价值网络则帮助判断当前局势是否有利于胜利。这两个网络相辅相成,是 AlphaGo 成功的关键。
这一页讲的是 AlphaGo 的两大核心神经网络组件:Policy Network(策略网络)和 Value Network(价值网络),以及它们各自的职责。策略网络的作用是「哪里下更有前途」,也就是给当前棋盘局面的所有合法落子位置各打一个概率分,输出一个概率分布。它的目的是缩减搜索空间——不需要平等地搜索所有 200 种走法,只需要重点搜索策略网络认为概率高的几个走法。价值网络的作用是「当前局面有多好」,输入一个棋盘状态,输出一个标量分数,表示在该局面下当前玩家赢棋的概率有多大。二者的分工非常重要:策略网络负责「广度」——把大量可能的走法压缩到少数有价值的候选;价值网络负责「深度」——不需要把搜索树展开到终局也能估算当前局面的胜率,减少了模拟深度。二者联合配合 MCTS(蒙特卡洛树搜索),让 AlphaGo 在宽广的搜索空间里高效找到强走法。考试常见考法:「AlphaGo 的策略网络和价值网络分别做什么?」要点是:策略网络输出落子概率分布用于剪枝,价值网络输出标量评分用于局面评估。易错点:两个网络的输出类型和职责很容易混淆,策略网络输出的是一个概率向量(softmax),价值网络输出的是单一标量(tanh 压缩到 -1 到 1)。

这一页讲的是 AlphaGo 的策略网络 (Policy Network) 和价值网络 (Value Network) 的架构及输入特征。主要内容包括输入数据格式、网络层结构和特征平面的描述。
这一页讲的是 AlphaGo 的策略网络 (Policy Network) 和价值网络 (Value Network) 的架构及其输入特征。输入数据是一个 19x19x48 的特征平面堆叠 (feature planes stack),其中每个平面表示围棋棋盘的不同特征,例如棋子颜色、剩余气数 (liberties)、自杀棋大小 (self-atari size) 等,共计 48 个平面。表格列出了这些特征平面的详细内容,例如“Stone colour”表示棋子颜色,分为玩家的棋子、对手的棋子和空位,共占用 3 个平面。策略网络是一个 13 层的卷积神经网络 (CNN),第一层使用 192 个 5x5 的卷积核,后续层使用 192 个 3x3 的卷积核,每层都包含批归一化 (BN) 和 ReLU 激活函数,输出层使用 Softmax 对 361 个棋盘位置和“pass move”进行概率分布预测。价值网络是一个 15 层的 CNN,前 11 层与策略网络相同,后续包括额外的卷积层、1x1 的卷积层和两个全连接层,最终输出一个标量值,范围在 -1 到 1,用于评估当前棋盘状态的价值。这些网络架构和特征设计是 AlphaGo 实现围棋决策的重要基础。
这一页讲的是 AlphaGo 策略网络和价值网络的具体神经网络架构细节,是本讲技术含量最高的一页。输入是一个 19 乘 19 乘 48 的张量——19 乘 19 对应围棋棋盘的格子,48 是特征平面的数量,包含棋子位置、气数、征子等手工特征。策略网络是一个 13 层 CNN:第一层用 192 个 5 乘 5 的卷积核(padding=2,stride=1),后接 Batch Normalization 和 ReLU;第 2 到 12 层改用更小的 3 乘 3 卷积核(padding=1,stride=1),也是 192 个,同样跟 BN 和 ReLU;输出层是 Softmax,覆盖棋盘上全部 361 个位置(19 乘 19)加上一个「pass」走法,共 362 个输出节点。价值网络是 15 层 CNN,前 11 层与策略网络相同;第 12 层多加一个卷积层;第 13 层是只有 1 个 1 乘 1 卷积核的卷积层后接 ReLU;第 14 层是 256 个单元的全连接层加 ReLU;最后输出层是 1 个单元的全连接层加 tanh,输出 -1 到 1 之间的标量代表胜率。考试常见考法:「为什么价值网络输出用 tanh 而不是 sigmoid?」tanh 把输出压缩到 -1 到 1,对应「-1=必败,+1=必胜」,相当于把结局 reward 直接映射到这个范围,利于训练的数值稳定。另一个常见考点:「为什么策略网络最后用 softmax?」因为要输出落子概率分布,各位置概率之和必须为 1。易错点:策略网络 13 层 vs 价值网络 15 层,输出形式一个是向量一个是标量,要记清楚。

这一页讲的是 AlphaGo 的核心组成部分,包括策略网络、价值网络和搜索算法。策略网络预测棋盘上更有潜力的区域;价值网络评估棋盘位置的优劣;搜索算法通过蒙特卡洛树搜索找到最佳下一步。
这一页讲的是 AlphaGo 的核心组成部分及其工作原理。首先,策略网络(Policy network)用于预测棋盘上哪些区域更有潜力,这可以减少搜索空间,从而提高决策效率。其次,价值网络(Value network)用于评估当前棋盘位置的优劣,这为决策提供了质量参考。最后是搜索算法(Search algorithm),它通过构建一个可能棋盘位置的树,从当前状态搜索到最佳下一步。AlphaGo 使用蒙特卡洛树搜索(Monte Carlo Tree Search,MCTS)来实现这一功能。右侧的图展示了搜索算法中树结构的复杂性,节点之间的连接表示不同棋盘状态的搜索路径。这种组合使 AlphaGo 能够在围棋中实现超越人类的表现。例如,当 AlphaGo面对复杂棋局时,策略网络可以快速缩小关注范围,价值网络评估每一步的潜力,最终通过搜索算法找到最优解。
这一页讲的是 AlphaGo 的第三个核心组件:Search Algorithm,即蒙特卡洛树搜索(Monte-Carlo Tree Search,MCTS),也在这里完整列出了 AlphaGo 三大组件。三个组件是:策略网络(Policy Network)、价值网络(Value Network)、以及搜索算法(MCTS)。MCTS 的本质是:从当前棋盘局面出发,通过大量随机模拟来估算每个候选走法的胜率,然后选择访问次数或胜率最高的走法。AlphaGo 对经典 MCTS 的最大改进是把策略网络和价值网络嵌入进去。传统 MCTS 用完全随机的 rollout(随机模拟到终局)来评估局面质量;AlphaGo 用价值网络直接给出局面评分,同时用快速 rollout policy 做短期模拟,两者加权组合。这样既保留了搜索的广度探索,又用神经网络极大缩短了评估深度。三个组件的分工可以用一句话概括:策略网络告诉 MCTS「往哪里搜」(减宽度),价值网络告诉 MCTS「当前局面有多好」(减深度),rollout policy 做快速终局模拟作为补充。考试常见考法:「AlphaGo 如何将深度学习与 MCTS 结合?」答案要包含三个组件的分工以及它们如何在 MCTS 的四个阶段(选择、扩展、评估、反向传播)中发挥作用。易错点:不要把 MCTS 简单说成「随机模拟」,AlphaGo 的 MCTS 是有神经网络引导的智能搜索。

这一页讲的是 AlphaGo 的训练过程,重点是策略网络(Policy Network)。主要包括监督学习用于预测人类专家的下一步棋,以及强化学习用于自我对弈以最大化获胜概率。
这一页讲的是 AlphaGo 的训练过程中的策略网络(Policy Network)。首先,监督学习(Supervised Learning)基于人类专家的棋局数据,目标是预测专家会下的下一步棋,通过分类任务训练策略网络(SL Policy Network)。其次,强化学习(Reinforcement Learning)通过自我对弈(Self-play)优化策略网络(RL Policy Network),目标是最大化获胜概率。幻灯片右侧的流程图展示了数据如何从人类专家棋局(Human expert positions)和自我对弈棋局(Self-play positions)输入到不同的神经网络中。SL策略网络(pσ)通过分类任务学习专家行为,而RL策略网络(pπ)通过策略梯度(Policy Gradient)优化。价值网络(Value Network,vθ)则通过回归任务评估棋局的胜率。这种结合监督学习和强化学习的方法使 AlphaGo 能够在复杂的围棋对局中实现高水平决策。

这一页讲的是 AlphaGo 的训练过程,主要包括 Policy Network 和 Value Network 的作用与训练方法。重点是监督学习、强化学习以及回归分析的应用。
这一页讲的是 AlphaGo 的训练过程,分为两个主要部分:Policy Network 和 Value Network。Policy Network 通过监督学习 (Supervised Learning) 从人类棋局中学习,目标是预测专业棋手的下一步动作;随后通过自我对弈 (Self-play) 进行强化学习 (Reinforcement Learning),以最大化获胜概率。图中展示了 Rollout Policy 和 SL Policy Network 的分类任务,以及 RL Policy Network 的策略梯度训练方法。第二部分是 Value Network,通过回归分析 (Regression) 处理状态与结果对 (State-Outcome Pairs),这些数据来自使用训练好的 Policy Network 进行的自我对弈。目标是最小化预测结果与实际结果之间的均方误差 (Mean Squared Error),即预测胜负的准确性。整体流程图说明了数据从人类棋局到自我对弈的转化,以及神经网络在不同阶段的作用。这种设计使 AlphaGo 能够在复杂棋局中做出近似最优决策。
这一页讲的是 AlphaGo 完整的训练流程,包含策略网络、价值网络以及 Rollout Policy 三个模块的训练方式,体现了监督学习与强化学习的结合。策略网络的训练分两阶段:第一阶段是监督学习(Supervised Learning,SL)——用人类专家棋谱作为训练数据,目标是预测专家的下一步走法,这让网络学到「人类高手怎么下棋」的先验知识,收敛快且初始质量好;第二阶段是强化学习(Reinforcement Learning,RL)——让两个策略网络互相对弈(self-play),以最终赢棋为奖励信号,通过 policy gradient 方法调整参数,目标是最大化赢棋概率。这两阶段串联非常关键:先用 SL 得到一个「会下棋」的初始网络,再用 RL 让它「越下越强」。价值网络的训练是回归任务:用强化学习后的策略网络进行大量自对弈,收集(棋盘状态, 最终输赢结果)对,用均方误差(Mean Squared Error)最小化预测胜率与真实结果之间的差距。Rollout Policy 是一个轻量级线性模型(linear model + softmax),用手工设计特征和计算特征,训练目标是快速预测合法走法的概率分布,用于 MCTS 中快速终局模拟——它不求精准,只求速度快。考试常见考法:「为什么 AlphaGo 训练策略网络要先做监督学习再做强化学习?」先 SL 获得合理的初始策略,否则 RL 从零开始的 self-play 太多是随机乱走,奖励信号太稀疏训练极慢。易错点:价值网络不是直接从人类棋谱学的,而是从 RL 后策略网络的 self-play 中学的,这点经常被遗忘。

这一页讲的是 AlphaGo 的训练过程,主要包括 Policy network、Value network 和 Rollout policy。表格列出了输入特征,右侧图展示了训练流程。
这一页讲的是 AlphaGo 的训练过程,分为三个主要部分:Policy network(策略网络)、Value network(价值网络)和 Rollout policy(模拟对局策略)。表格中列出了 Rollout 和树策略的输入特征,包括特征名称、模式数量以及描述。例如,Response 表示是否匹配响应模式特征,Save atari 表示是否保护棋子免于被吃,Nakade 则是捕捉棋子的特殊模式。表中的关键特征如 Response pattern 和 Non-response pattern 的模式数量较多,说明它们在策略中占重要地位。右侧的流程图展示了 AlphaGo 的训练过程:从人类专家棋局数据中生成 SL policy network(监督学习策略网络),通过自我对弈生成 RL policy network(强化学习策略网络),最终结合 Value network 评估局面价值。Rollout policy 使用线性模型和 softmax 激活函数,基于计算和手工设计的特征生成当前状态下所有合法动作的概率分布,其目标是快速预测动作以便采样。这个训练过程结合了监督学习和强化学习,使 AlphaGo 能够高效地评估和选择最佳棋步。

这一页讲的是 AlphaGo 的决策过程,包括编码棋盘状态、初始化搜索树、运行 MCTS 模拟和选择最终动作。
这一页讲的是 AlphaGo 的决策过程。首先,它会对当前的棋盘状态进行编码(encode the current board state),将棋盘信息转化为适合算法处理的形式。接着,初始化搜索树(initialise the search tree),这是为后续的模拟和评估提供结构化的框架。然后,运行大量的蒙特卡洛树搜索(MCTS, Monte Carlo Tree Search)模拟,通过随机采样和概率计算来评估不同动作的潜在结果。最后,根据模拟结果选择最优的最终动作(select the final move)。这一过程结合了深度学习和搜索算法的优势,使 AlphaGo 能够在复杂的围棋局面中做出精准决策。举例来说,在围棋比赛中,AlphaGo 会通过这种流程计算出下一步最佳落子位置,从而提高胜率。

这一页讲的是 AlphaGo 的决策过程,包括棋盘状态编码、搜索树初始化、MCTS 模拟和最终决策。表格展示了用于神经网络的输入特征。
这一页讲的是 AlphaGo 的决策过程,主要分为四个步骤:首先对当前棋盘状态进行编码(encode the current board state),然后初始化搜索树(initialise the search tree),接着运行大量蒙特卡洛树搜索(MCTS simulations),最后选择最终的最佳动作(select the final move)。右侧的表格详细列出了用于神经网络的输入特征(input features),如棋子颜色(stone colour)、空点的自由度(liberties)、捕获大小(capture size)、是否为自提(self-atari size)等。这些特征通过多平面数据表示,帮助神经网络理解棋盘状态。例如,“自由度”特征表示某点周围的空点数量,而“梯形捕获”特征则表示某步是否能成功捕获梯形。总的来说,这些特征的目的是将棋盘状态转化为神经网络可以处理的形式,从而支持 AlphaGo 做出智能决策。这种设计对复杂棋局的分析和策略优化至关重要。

这一页讲的是 AlphaGo 的决策过程,包括 MCTS 搜索和策略网络的作用。重点是减少搜索空间,提高效率。
这一页讲的是 AlphaGo 的决策过程。首先,它会对当前棋盘状态进行编码(encode the current board state),然后初始化搜索(initialise the search)。接下来运行大量的蒙特卡洛树搜索(MCTS simulations),最终选择最佳的下一步棋(select the final move)。 MCTS 树的根节点是当前棋盘状态,策略网络(policy network)在其中起重要作用。它可以生成每一步棋的先验概率(generate prior probabilities for moves),并将搜索集中在更有希望的行动上(focus the search on promising actions)。右侧的图展示了策略网络如何评估状态 s,并生成概率分布 p(a|s)。 这一过程的核心目的是从一开始就减少搜索空间(reduce the search space from the start),从而提高计算效率。例如,通过策略网络,AlphaGo可以优先考虑更可能获胜的棋步,而不是逐一评估所有可能性。

这一页讲的是 AlphaGo 的决策过程,包括编码棋盘状态、初始化搜索树、运行多次 MCTS 模拟,并选择最终动作。
这一页讲的是 AlphaGo 的决策过程。首先,AlphaGo 会对当前棋盘状态进行编码(encode the current board state),然后初始化搜索树(initialise the search tree),接着运行大量的蒙特卡洛树搜索(MCTS simulations),最后选择最佳动作(select the final move)。在探索每一个可能的棋盘位置时,AlphaGo 结合三个神经网络的功能:策略网络(policy network)用于推荐下一步的可能动作;价值网络(value network)用来评估当前棋盘位置的好坏;快速模拟策略(rollout policy)则快速模拟游戏可能的结束方式。这些步骤的目的在于通过神经网络和快速模拟,判断哪些动作最可能带来胜利,而无需逐一分析所有可能性。这种方法极大提高了决策效率,同时保持了高准确性。图中展示了 AlphaGo 的搜索树结构,体现了其探索不同棋局的能力。
这一页讲的是 AlphaGo 在实际落子时的完整决策流程,把策略网络、价值网络、Rollout Policy 和 MCTS 四者的协作机制讲得最清楚。决策流程分四步。第一步是编码当前棋盘状态:把实时棋盘局面转换成 19 乘 19 乘 48 的特征张量,这是神经网络能理解的格式。第二步是初始化搜索树:把当前局面设为 MCTS 树的根节点,用策略网络为根节点所有合法走法生成先验概率(prior probability),这些先验概率告诉 MCTS 应该优先探索哪些分支,从一开始就把搜索集中在有价值的区域。第三步是运行大量 MCTS 模拟:每一次模拟从根节点出发,沿着 UCB(置信上界)策略选择节点,遇到未展开的节点时用策略网络估算其子节点的先验概率(扩展),然后用价值网络直接给这个新节点的局面评分,同时用 rollout policy 快速模拟到终局得到另一个评分,两者加权平均作为该节点的价值估计,最后把这个价值反向传播回根节点更新各节点的统计数据。第四步是选择最终走法:选择访问次数最多的走法作为实际落子。用访问次数而不是胜率的原因是:高访问次数代表这个走法经过了大量模拟的验证,更可靠。考试常见考法:「MCTS 模拟中价值网络和 rollout policy 如何协同工作?」两者加权——价值网络慢而精,rollout policy 快而粗,结合使用在速度和精度之间取得平衡。易错点:选最终走法时用的是「访问次数最多」而不是「Q 值最高」,这是 AlphaGo 的工程设计选择,要注意区分。

这一页讲的是 AlphaGo 的决策过程,包括编码棋盘状态、初始化搜索树、进行多次 MCTS 模拟,最终选择访问次数最多的动作。
这一页讲的是 AlphaGo 的决策过程,展示了如何通过搜索和模拟选择最佳动作。首先,系统会对当前的棋盘状态进行编码(encode the current board state),将其转化为模型可以理解的数据格式。接着,初始化搜索树(initialise the search tree),为后续模拟提供结构基础。然后,运行大量蒙特卡洛树搜索(MCTS, Monte Carlo Tree Search)模拟,以评估不同动作的潜在价值。最后,选择访问次数最多的动作(select the final move),即搜索中被认为最优的动作。这一过程的目的是挑选一个强且通过搜索充分支持的动作(pick a move that is strong and well supported by search)。右侧的图展示了搜索树的结构,每个节点代表一个可能的棋步,分支反映了不同的模拟路径。通过这种方法,AlphaGo 能够高效地评估复杂的棋局并做出决策。

这一页讲的是接下来两周课程的安排,重点是树搜索(Tree search)、搜索算法(Search algorithms)和强化学习(Reinforcement Learning)。
这一页讲的是课程的未来安排,特别是围绕 AlphaGo 的搜索与强化学习主题展开。第 8-9 周将重点讲解树搜索(Tree search)和搜索算法(Search algorithms),其中包括蒙特卡罗树搜索(MCTS)。树搜索是一种在决策树中寻找最优路径的技术,广泛应用于游戏 AI 和规划问题。MCTS 是一种基于随机模拟的树搜索方法,能够有效处理复杂的决策空间。第 9 周还安排了一次关于强化学习(Reinforcement Learning)的客座讲座。强化学习是一种通过试错法让智能体在环境中学习最佳策略的机器学习方法,在 AlphaGo 中起到了关键作用。通过这些内容,学生将深入理解搜索算法与强化学习如何结合,推动人工智能在复杂任务中的表现。

这一页讲的是课程结束前的计划安排,涵盖第10到12周的内容。重点包括AI可持续性、持续学习以及研讨论文展示。
这一页讲的是课程结束前的计划安排,共分为三周内容。第10周主题是AI for Sustainability(人工智能的可持续性),周一安排了关于AI/ML for Good(人工智能/机器学习的公益应用)的嘉宾讲座,周四介绍了GraphCast(图神经网络,GNNs)的相关内容。第11周主题是Sustainability of AI(人工智能的可持续发展),周一学习Self-supervised learning(自监督学习),周四探讨Continual learning(持续学习)的概念。第12周没有正式授课,因为周一是King's Birthday(国王生日),周四则安排了Seminar papers presentations showcase(研讨论文展示)。这一安排不仅涵盖了技术主题,还提供了实践和展示机会,帮助学生更好地理解人工智能的应用及其未来发展方向。