这一页讲的是免责声明和致谢,明确说明幻灯片内容改编自几位学者的工作,包括 Pieter Abbeel 和 Dan Klein 的 UC Berkeley CS188 课程,以及 Mike Barley 和 Pat Riddle 的工作(来自 UoA)。此外,页面还提到图示的来源是 Pieter Abbeel 和 Dan Klein 的 UC Berkeley CS188 课程。这些信息的目的是尊重原作者的知识产权,同时为听众提供背景信息,说明内容的可靠性和学术来源。这种致谢在学术交流中非常重要,能够体现对原始工作的尊重,同时帮助听众了解内容的出处。
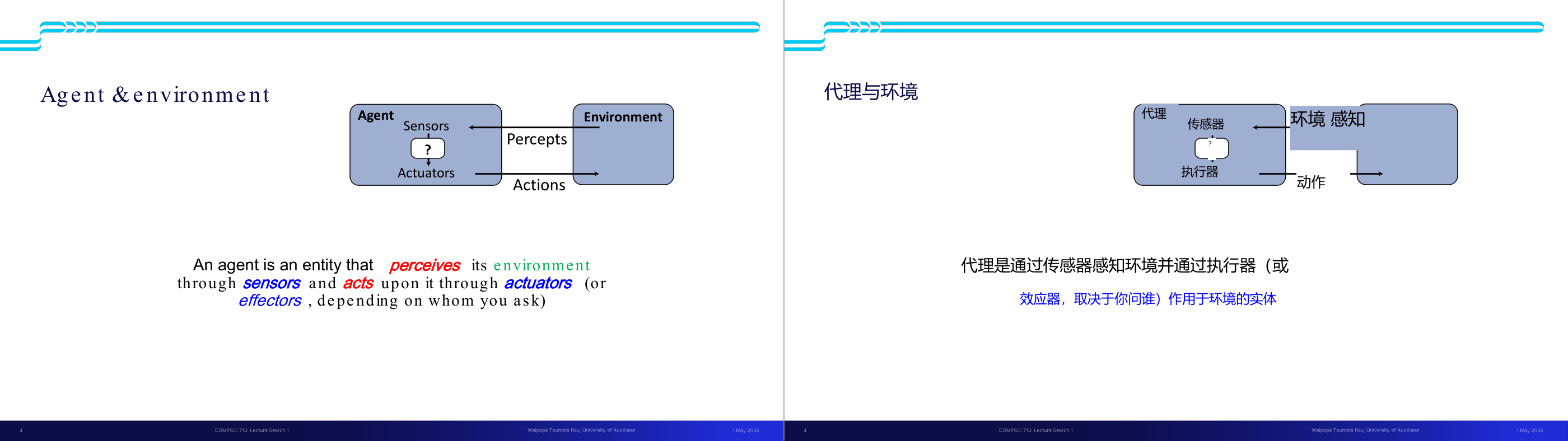
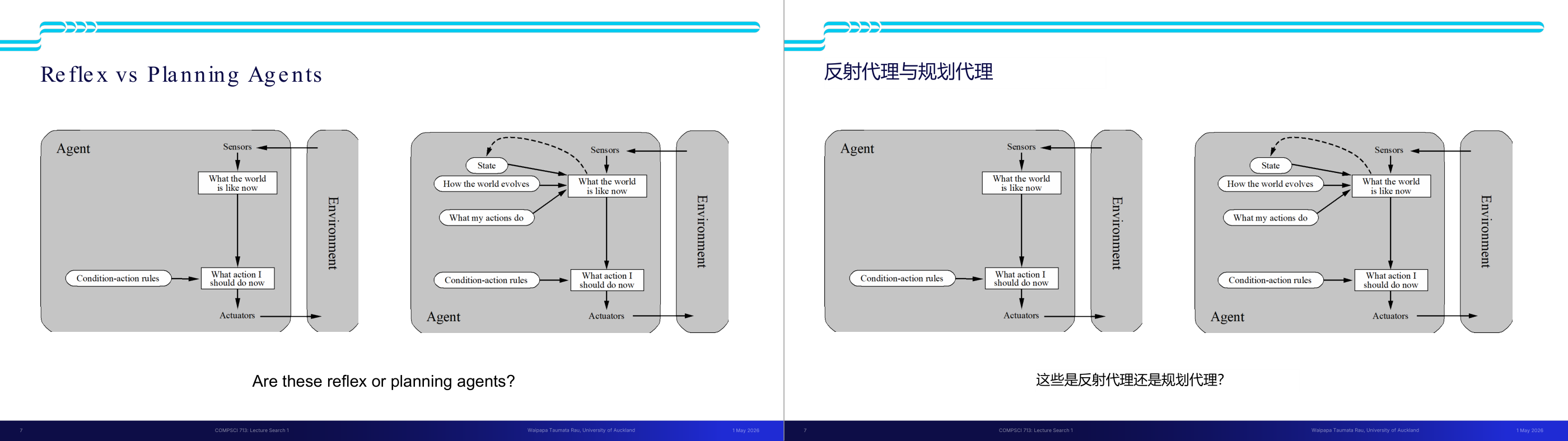
这一页讲的是反射型代理(Reflex Agents)与规划型代理(Planning Agents)的区别。左图中的反射型代理通过传感器(Sensors)感知当前环境状态(What the world is like now),直接依据条件-动作规则(Condition-action rules)选择动作(What action I should do now),然后通过执行器(Actuators)作用于环境。这种代理不考虑未来,只关注当前状态,适合简单任务。右图展示规划型代理的结构,除了感知当前状态,还维护一个内部状态(State),并通过推理了解环境如何演化(How the world evolves)以及动作的影响(What my actions do)。规划型代理基于这些信息选择动作,具有更强的决策能力,适合复杂任务。两者的核心区别在于是否使用内部状态和是否考虑未来。
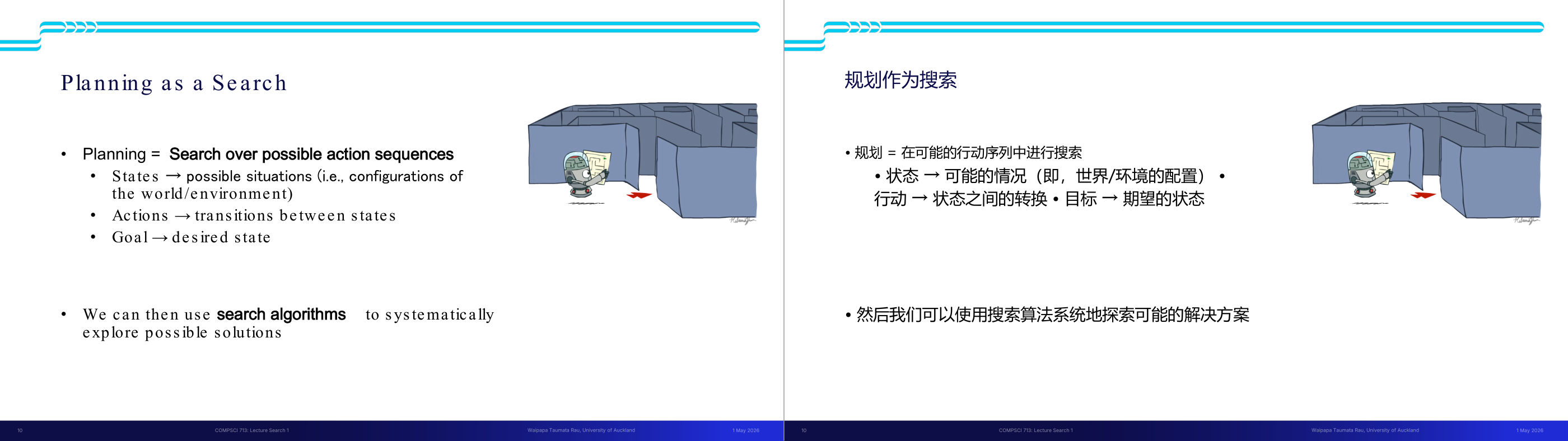
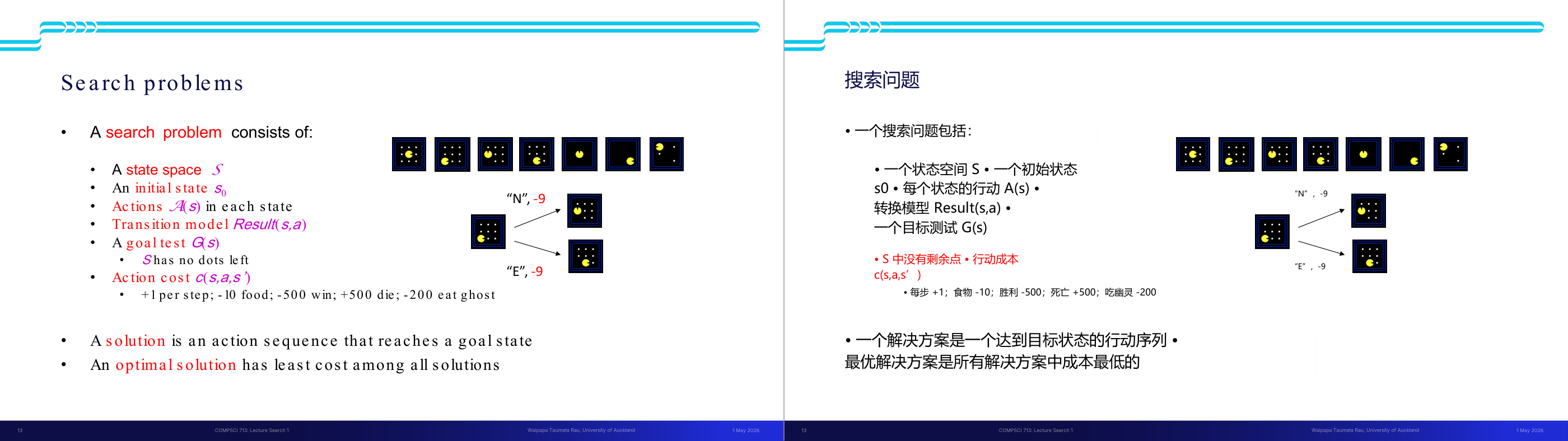
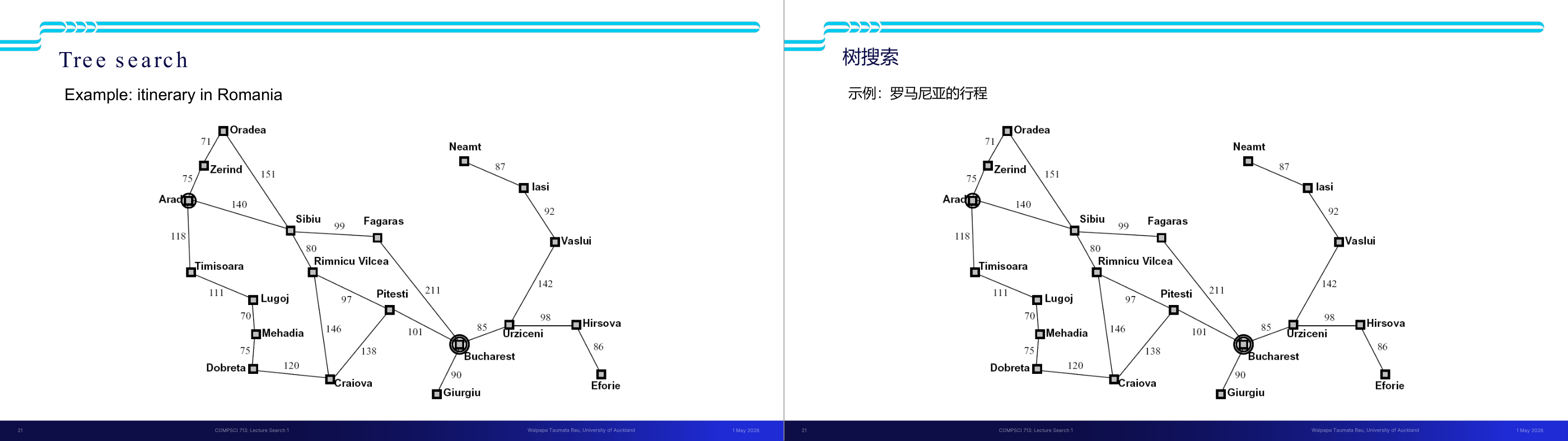
这一页讲的是计划(Planning)可以被看作是对可能的动作序列进行搜索(Search over possible action sequences)。首先,状态(States)指的是世界或环境中的可能情况或配置;动作(Actions)是状态之间的转换;目标(Goal)则是期望达到的状态。通过定义这些元素,我们可以将计划问题转化为搜索问题。接着,幻灯片强调我们可以使用搜索算法(Search algorithms)来系统地探索可能的解决方案。这种方法的重要性在于它为复杂问题提供了结构化的解决思路。例如,一个机器人在迷宫中寻找出口时,可以通过定义状态为每个位置、动作为移动方向、目标为出口位置,使用搜索算法找到最优路径。这种方法广泛应用于人工智能领域的路径规划和问题求解。
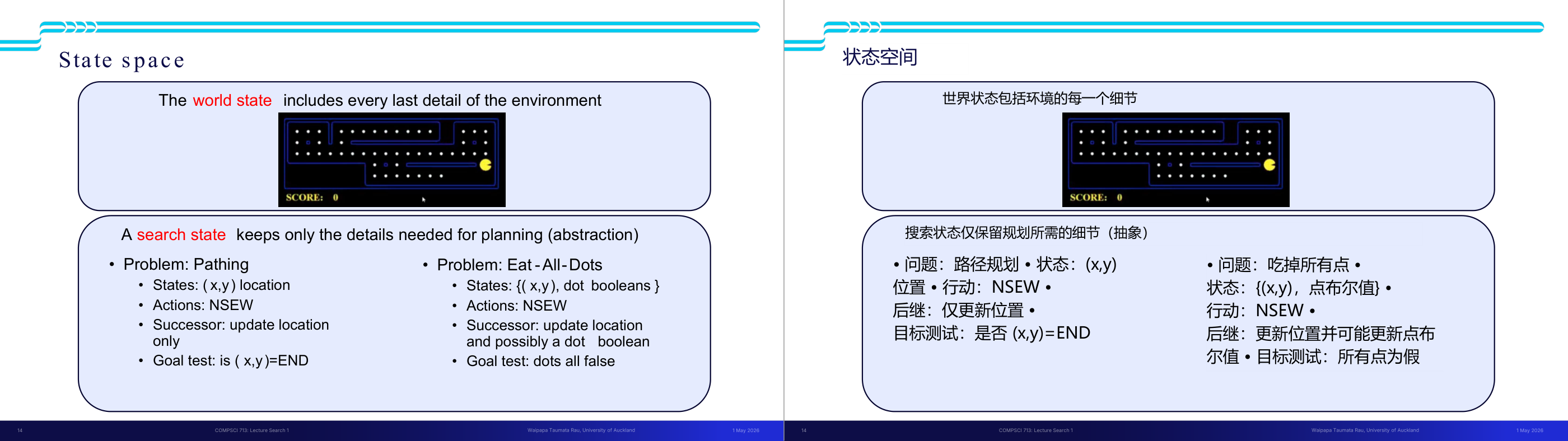
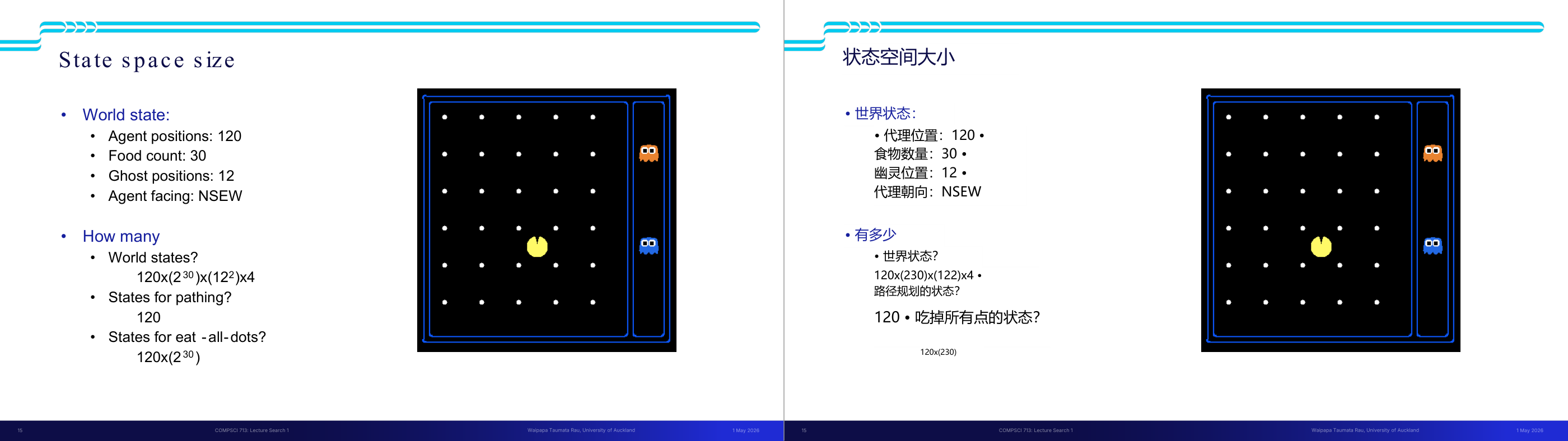
这一页讲的是 State Space(状态空间)的抽象化设计,核心区别是 World State 和 Search State。World state 包含环境的每一个细节;search state 只保留规划所需的必要信息。以 Pac-Man 为例:如果任务是「找路径」,search state 只需要 (x,y) 坐标,忽略食物分布和幽灵位置;如果任务是「吃掉所有食物」,search state 就必须包含 (x,y) 加上每个食物格子的布尔值(有没有被吃掉)。这就是抽象(abstraction)的思想——用更小的状态表示来降低搜索空间规模。具体计算见下一页:如果有 120 个位置、30 个食物格、12 个幽灵位置和 4 个朝向,世界状态总数是 120 乘以 2 的 30 次方再乘 144 再乘 4,天文数字;而单纯路径规划的 search state 只有 120 个。考试常考:给一个具体问题,要你设计合理的 state representation。易错点是过度包含不必要的信息(导致状态空间爆炸)或遗漏规划必须的信息(导致无法正确求解)。抽象的原则是「规划需要什么,就保留什么」。
第 13 / 56 页
这一页讲的是状态空间大小 (State Space Size)。主要包括世界状态的构成要素、状态数量计算公式,以及不同任务的状态空间规模。
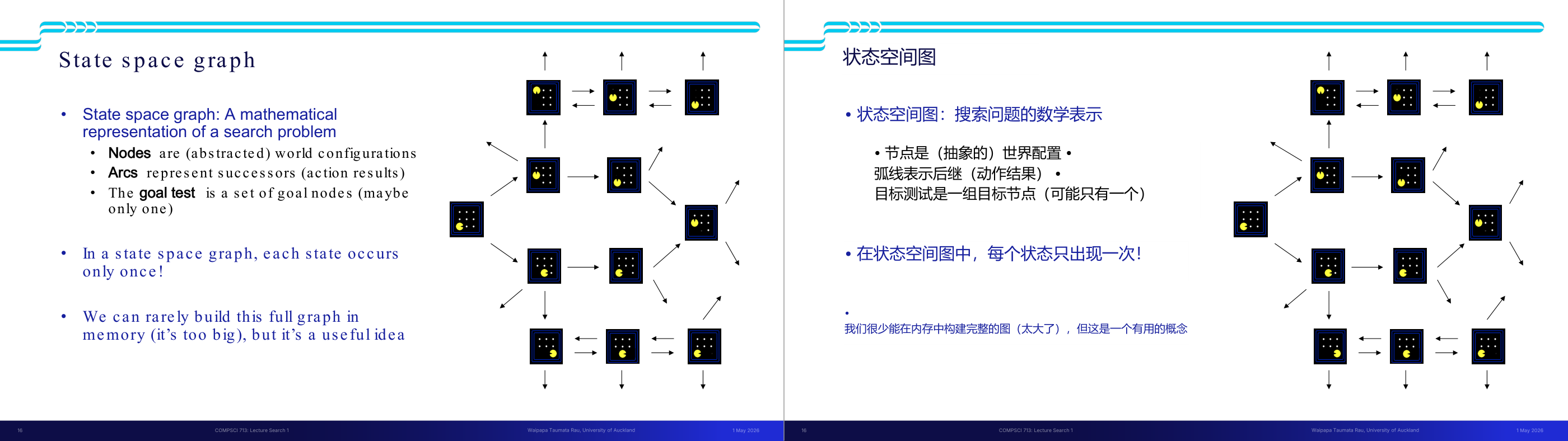
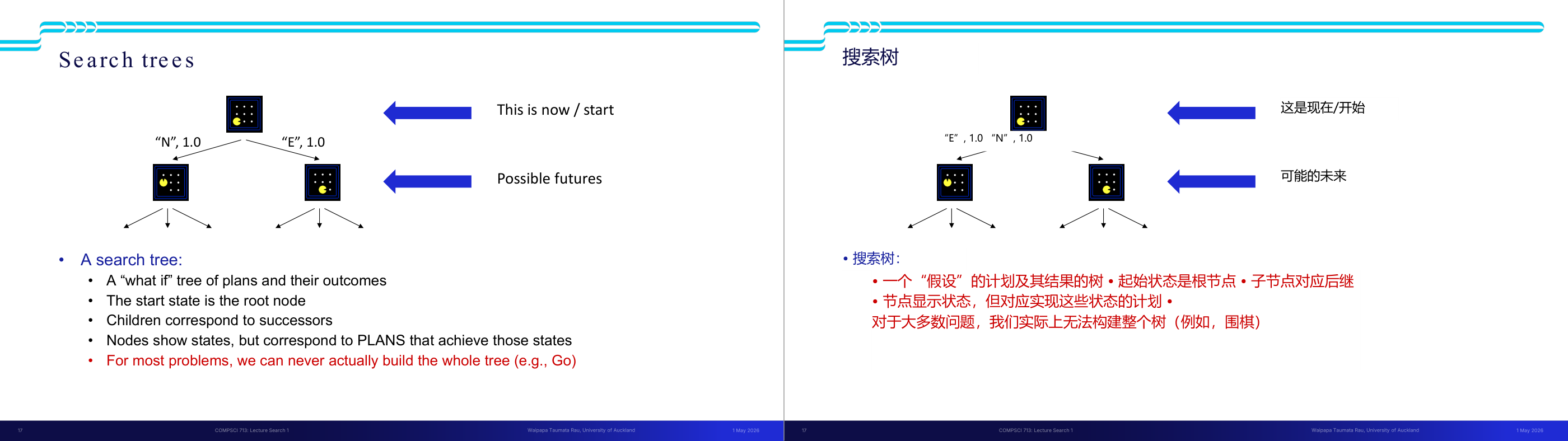
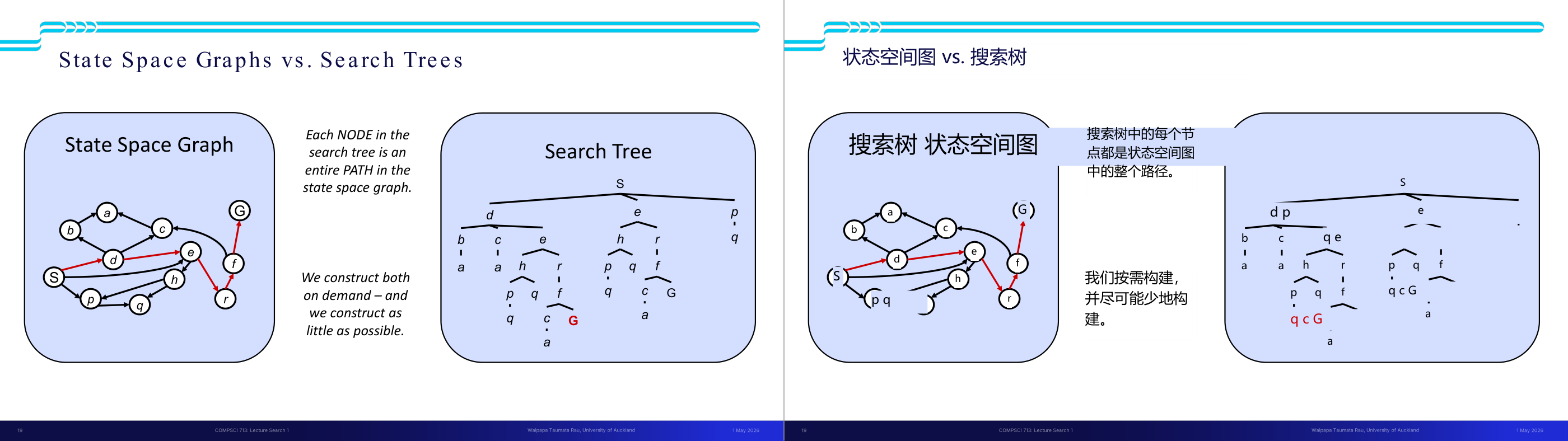
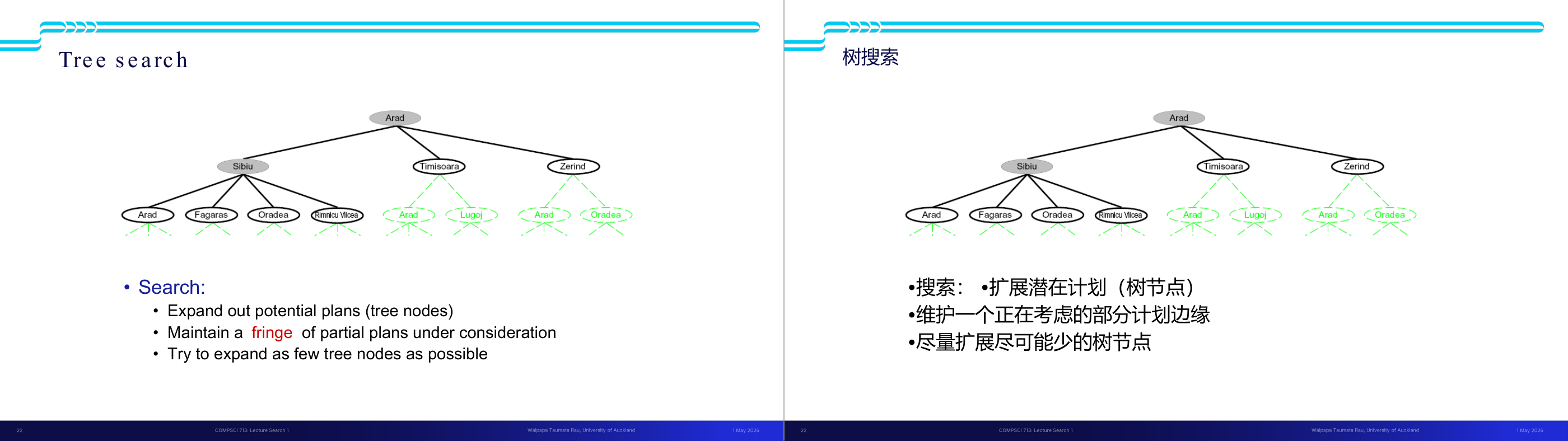
这一页讲的是状态空间图(State Space Graph)与搜索树(Search Tree)的区别。状态空间图展示节点间的关系,而搜索树将路径展开为树结构。
这一页讲的是状态空间图(State Space Graph)与搜索树(Search Tree)的区别及构建方式。左侧的状态空间图展示了从起始状态 S 到目标状态 G 的所有可能状态及它们之间的连接关系。图中的节点代表状态,箭头表示状态之间的转换路径。右侧的搜索树则是基于状态空间图构建的树结构,其中每个节点代表状态空间图中的一条完整路径。搜索树的根节点是初始状态 S,分支代表从一个状态到下一个状态的选择。搜索树的特点是按需构建(on demand),并尽量减少构建的节点数量。通过比较两者可以看出,状态空间图更适合展示整体的状态关系,而搜索树更适合逐步探索路径。举例来说,从 S 到 G 的路径可以通过搜索树逐层展开,最终找到目标状态 G。
第 18 / 56 页
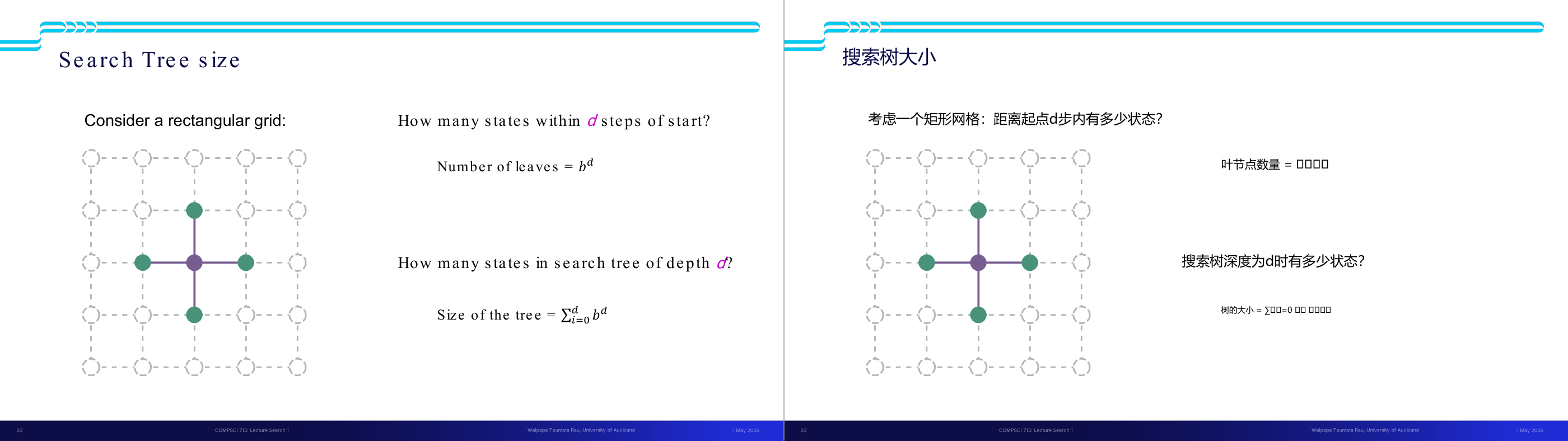
这一页讲的是搜索树的大小及其计算方法,包括叶节点数量和树的总状态数。
这一页讲的是搜索树的大小问题。首先,考虑一个矩形网格(rectangular grid),每个节点可以通过一定步数 d 到达其他状态。搜索树的叶节点数量(Number of leaves)可以通过公式 b^d 计算,其中 b 是每个节点的分支因子(branching factor),d 是搜索树的深度。接着,搜索树的总状态数(Size of the tree)可以通过公式 Σ(b^i, i 从 0 到 d) 求得,即将每一层的节点数量累加。图中展示了一个网格示例,中心节点通过四个方向连接到其他节点,说明了分支因子的概念。这个计算对于估算搜索问题的复杂度非常重要,例如在路径规划或游戏树搜索中,可以帮助我们评估算法的效率和资源消耗。
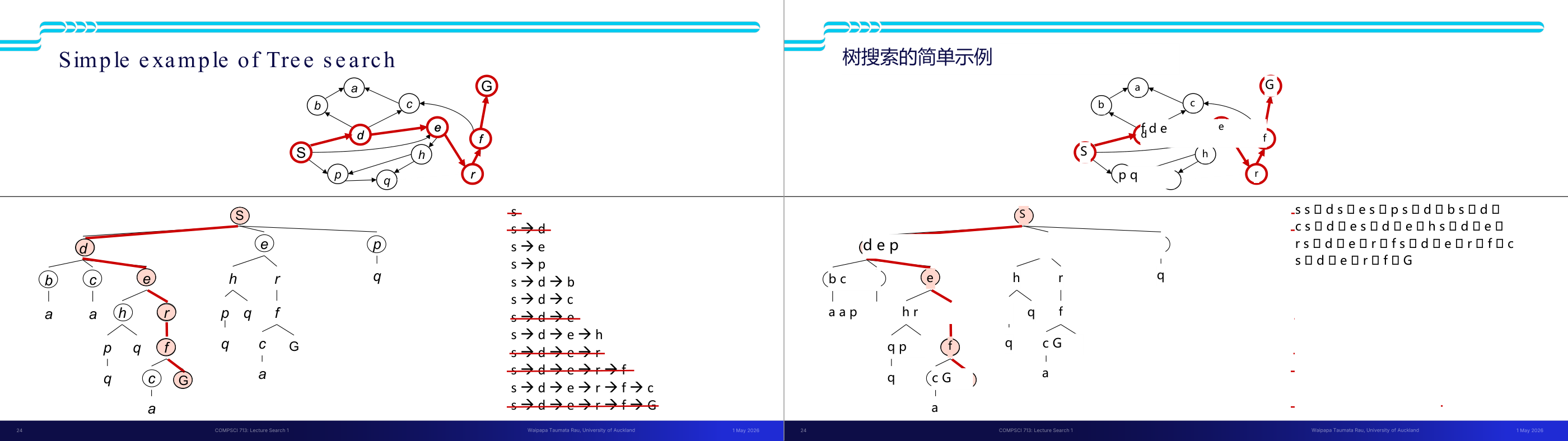
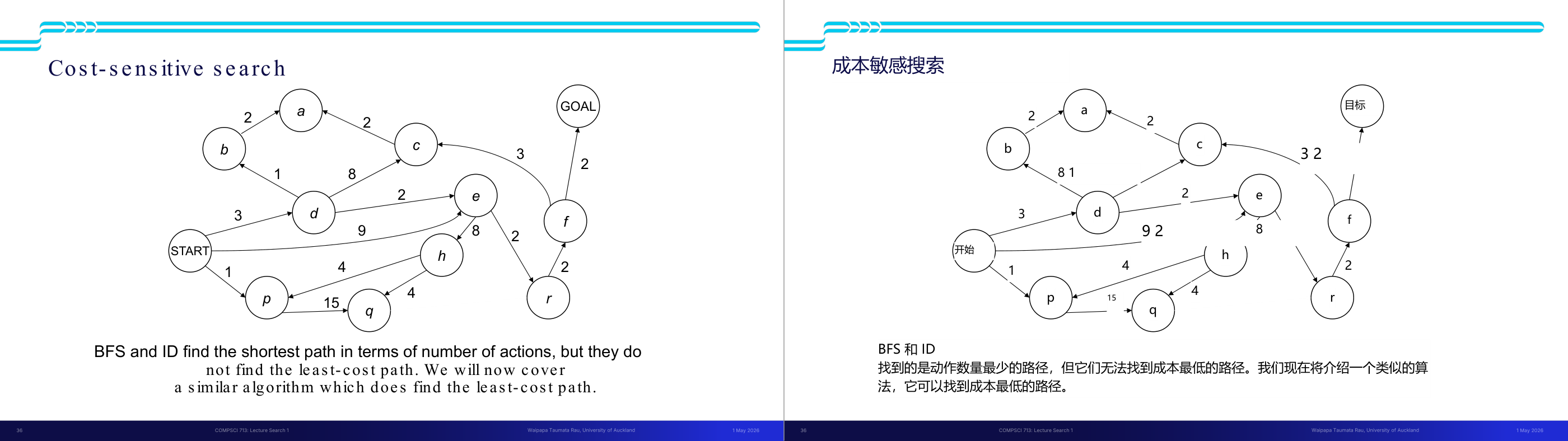
这一页讲的是树搜索 (Tree Search) 的简单示例,展示了如何从起始节点 S 开始,通过扩展节点逐步搜索目标节点 G。上方的图是一个有向图,红色箭头表示当前搜索路径。下方左侧是对应的搜索树,展示了节点扩展的层次结构;右侧是搜索路径的记录,显示了每一步扩展的具体路径。搜索过程从 S 开始,逐步扩展到 d、e 等节点,最终找到目标节点 G。树结构中,红色线条表示当前搜索路径,其他节点表示未扩展或已扩展的路径。搜索路径记录通过划线标记已被排除的路径,最终保留了正确的路径 S → d → e → r → f → G。这一页直观地说明了树搜索的工作原理:通过逐步扩展节点,探索所有可能的路径,直到找到目标。
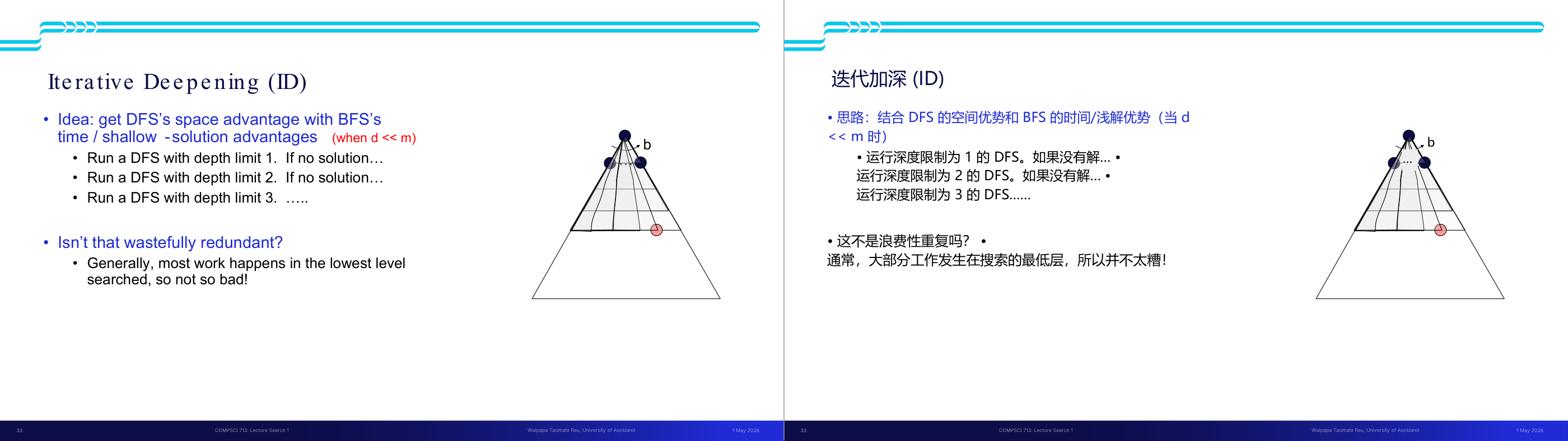
这一页讲的是无信息搜索中的深度优先搜索(Depth-First Search, DFS)。DFS 的策略是优先扩展最深的节点,即沿着树的分支尽可能深入,直到无法继续为止。实现上,DFS 使用的是后进先出(LIFO, Last In First Out)的栈结构来管理 Fringe(边缘节点)。幻灯片中的图展示了一个搜索过程,红色路径表示搜索的顺序,节点从根节点 S 开始,逐步深入到 d、b、c 等子节点,直到找到目标节点 G。下方的树形结构图进一步说明了搜索的展开顺序和路径。DFS 的优点是实现简单,适合空间有限的场景,但缺点是可能陷入无限分支或长时间无法找到解。举例来说,如果目标节点 G 在树的右侧分支,而算法从左侧分支开始搜索,则可能需要较长时间才能找到目标。
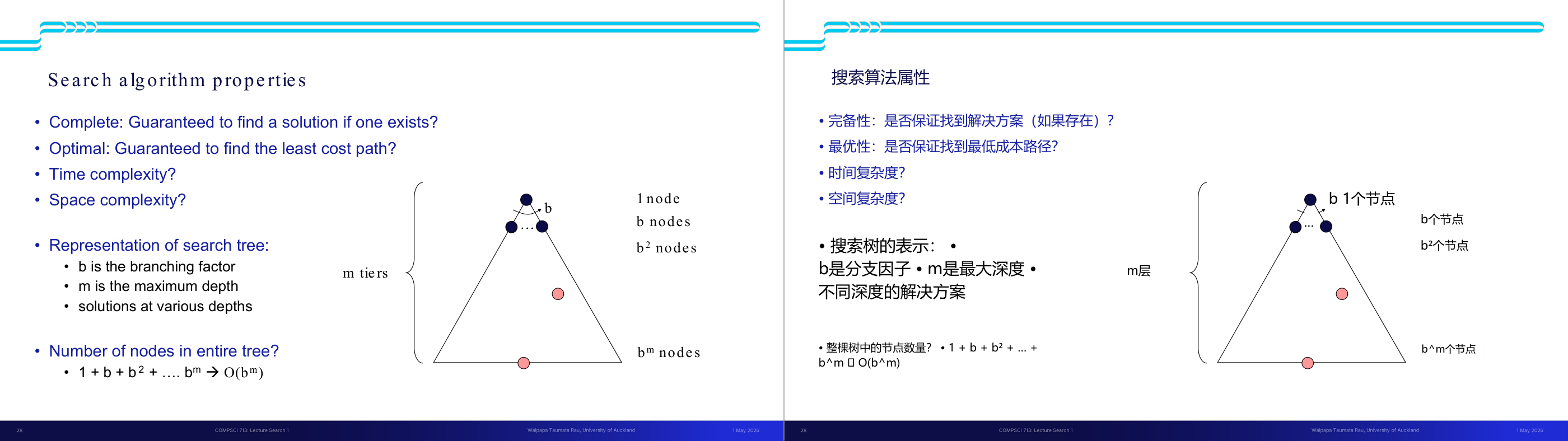
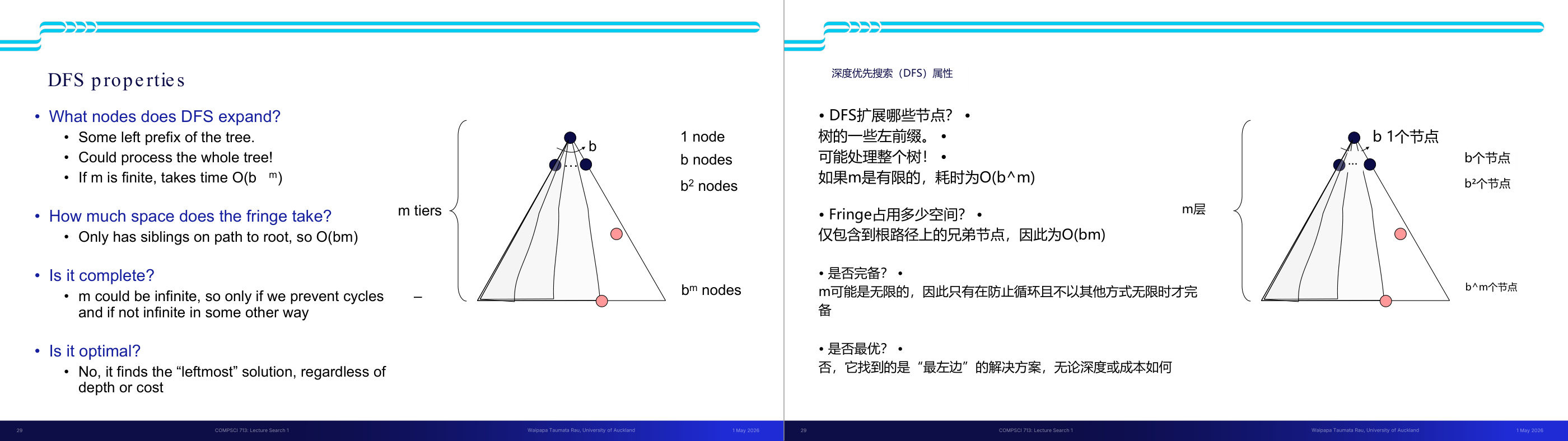
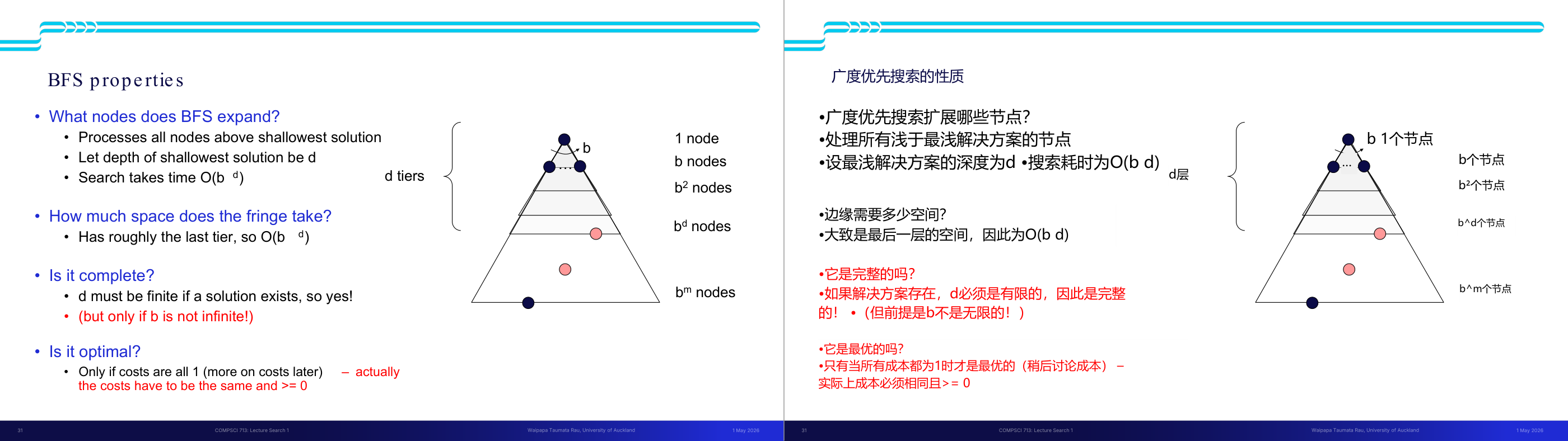
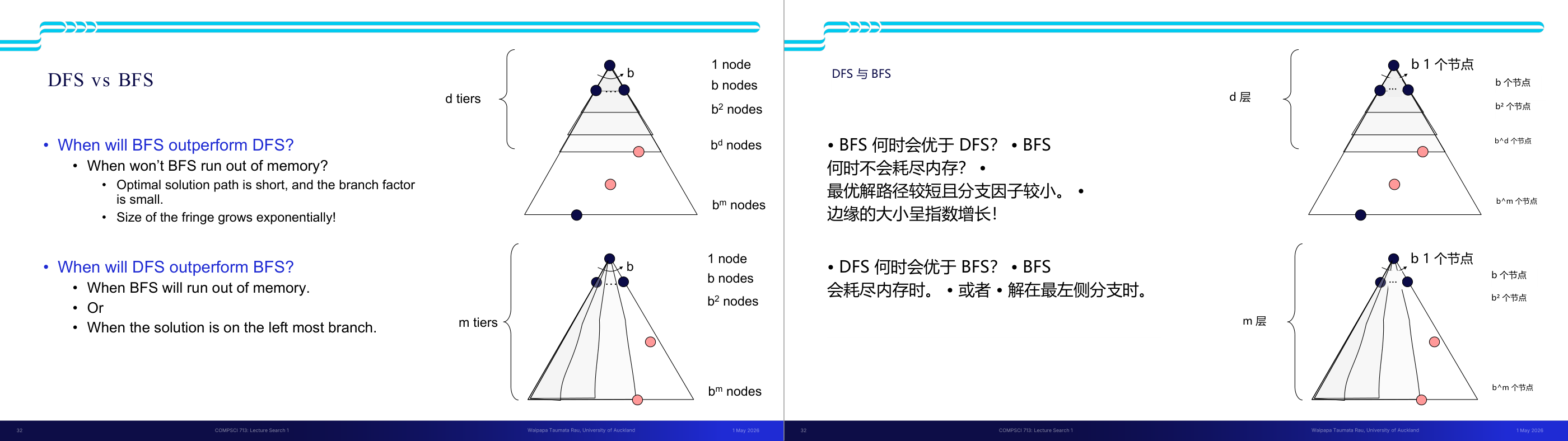
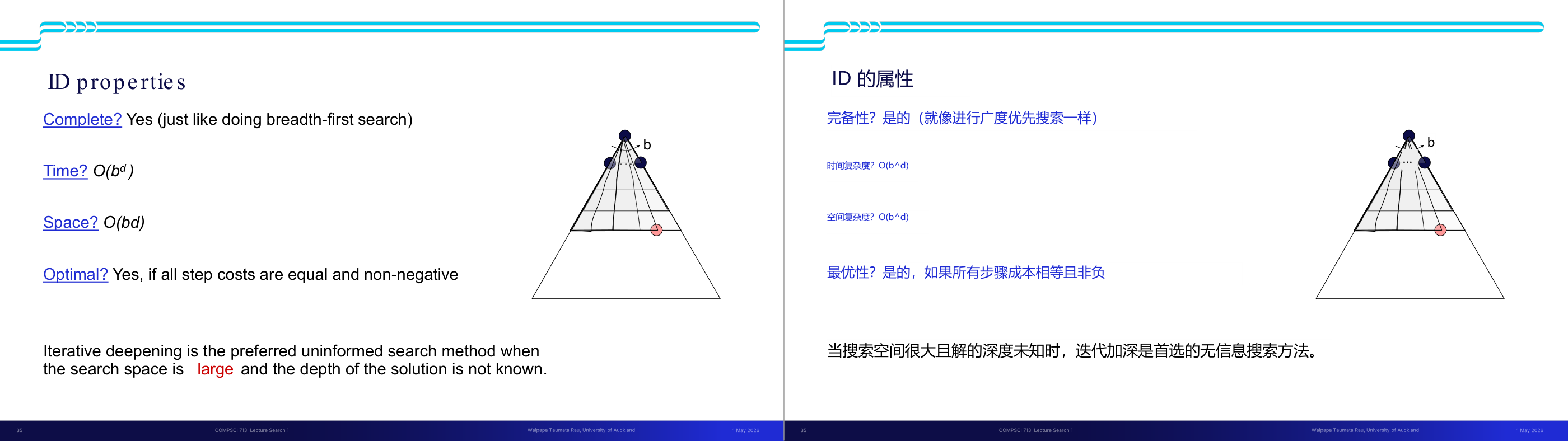
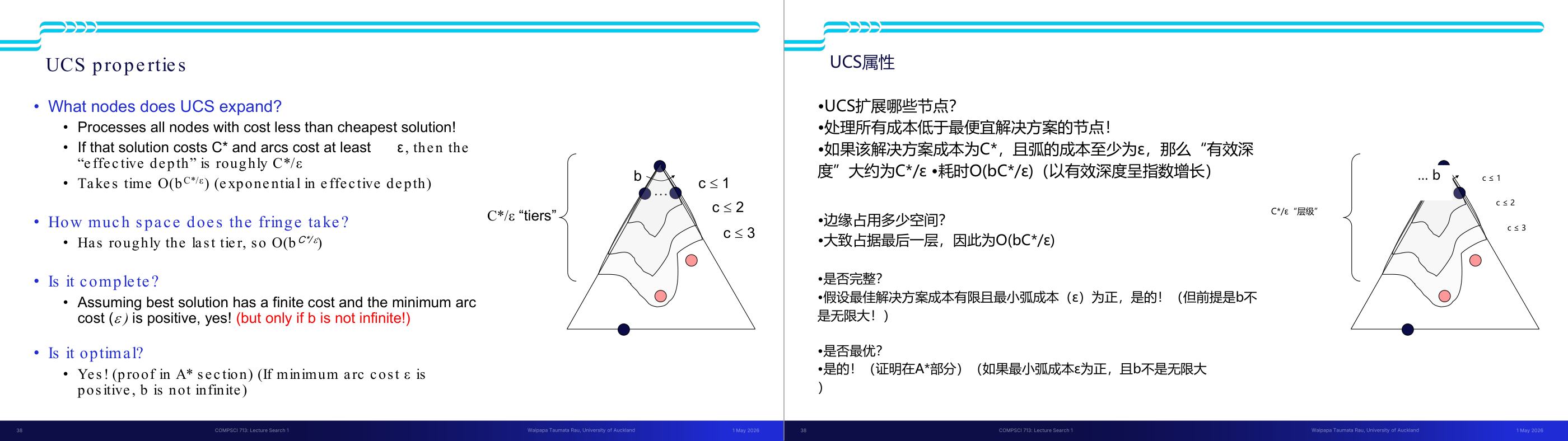
这一页讲的是搜索算法的性质和搜索树的表示。首先,完备性(Complete)指的是算法是否可以保证找到解(如果解存在),而最优性(Optimal)则是算法是否能够找到代价最小的路径。这两个性质是评价搜索算法的重要标准。此外,时间复杂度和空间复杂度是衡量算法效率的关键指标。幻灯片右侧展示了搜索树的结构,树的分层由 m 表示,b 是分支因子(branching factor),即每个节点的子节点数量。树的深度为 m,解决方案可能出现在不同深度。整个树的节点总数可以通过公式计算,1 + b + b² + … + b^m,最终简化为 O(b^m),这表示节点数量随着分支因子和树深度的增长呈指数级增加。这种表示方式帮助我们理解搜索算法的复杂性,例如在广度优先搜索中,空间复杂度可能受节点数量的影响而迅速增长。
第 27 / 56 页
这一页讲的是深度优先搜索(DFS)的性质,包括扩展节点、空间复杂度、完整性和最优性。
这一页讲的是深度优先搜索(DFS)的性质。首先,DFS扩展的节点是树的某个左侧前缀,可能会处理整个树。如果树的深度 m 是有限的,时间复杂度为 O(b^m),其中 b 是每层的分支因子。其次,DFS的边界(fringe)空间复杂度为 O(bm),因为它只存储从根到当前节点路径上的兄弟节点。关于完整性,DFS只有在防止循环并且树深度 m 非无限时才是完整的。最后,DFS不是最优的,因为它总是找到最左侧的解决方案,而不考虑深度或代价。右侧的图展示了树的结构,每层的节点数量依次为 1, b, b^2,..., b^m,说明了分支因子和深度对节点数量的影响。
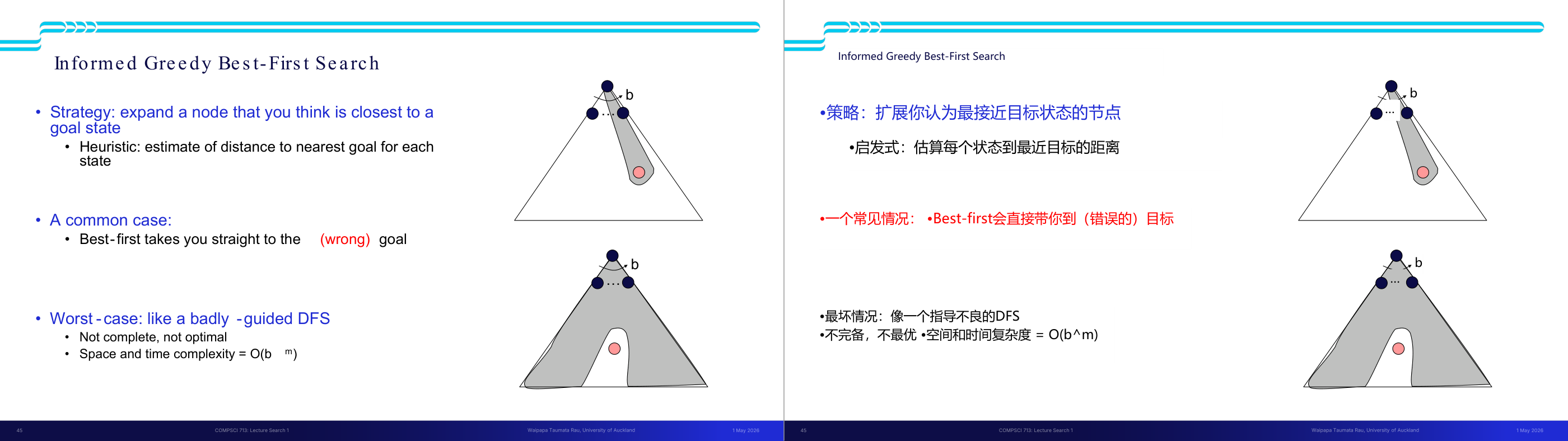
这一页讲的是搜索算法四个核心性质的定义,以及搜索树规模的基本估算,是后面对比所有搜索算法的共同语言。四个性质:Complete(完备性)表示「若解存在,算法是否保证找到」;Optimal(最优性)表示「是否保证找到代价最小的路径」;Time complexity 和 Space complexity 用 Big-O 表示随问题规模增长的上界。搜索树的参数化:b 是分支因子(branching factor,每个节点平均有多少子节点),m 是树的最大深度,d 是最浅解所在深度。整棵树的节点总数是 1 加 b 加 b 的平方一直到 b 的 m 次方,用几何级数公式得到 O(b 的 m 次方)。直觉是:每深一层,节点数就乘以 b,所以深度对复杂度的影响是指数级的。考试常考:给出 b 和 m 的值,计算搜索树规模;或比较不同算法的时间/空间复杂度。易错点是把 m 和 d 混淆——BFS 和 ID 的时间复杂度用 d(浅解深度),DFS 用 m(最大深度);当解在树的很深处时 d 接近 m,但很多实际问题中 d 远小于 m。
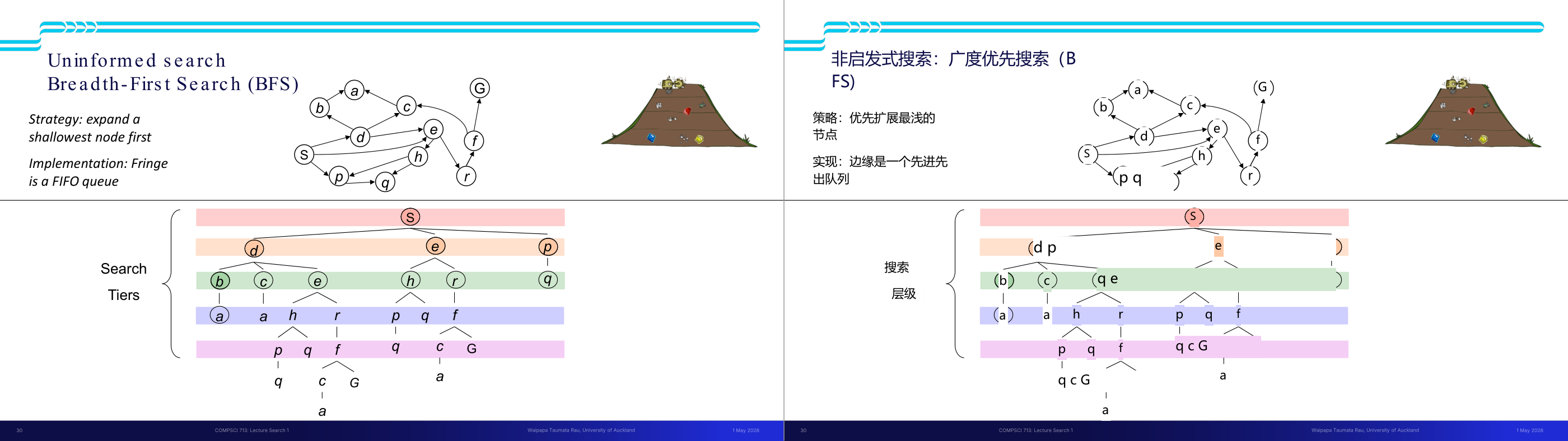
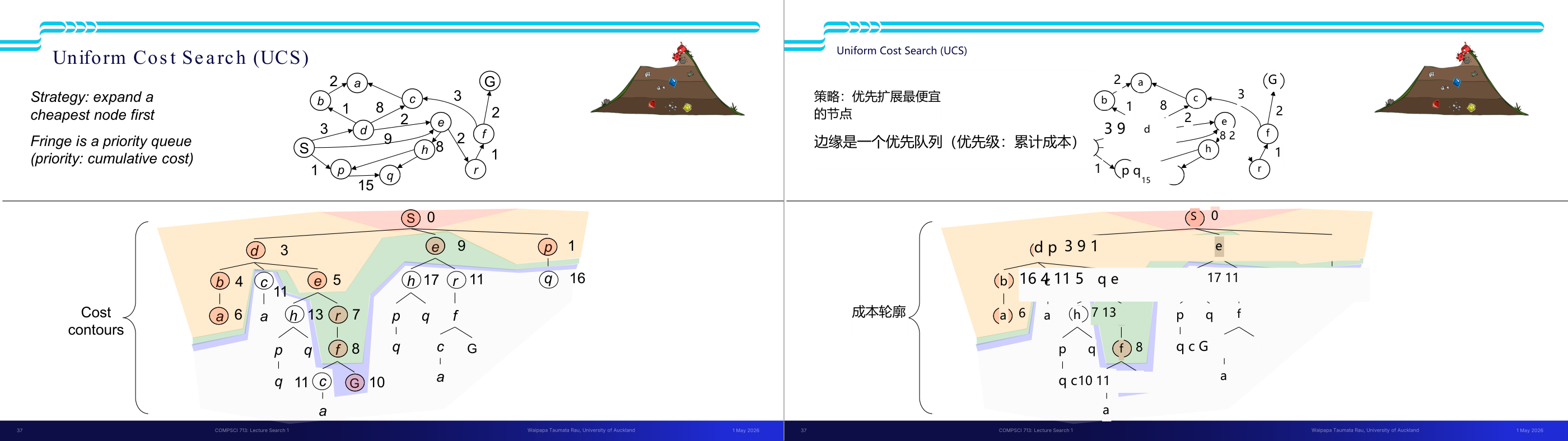
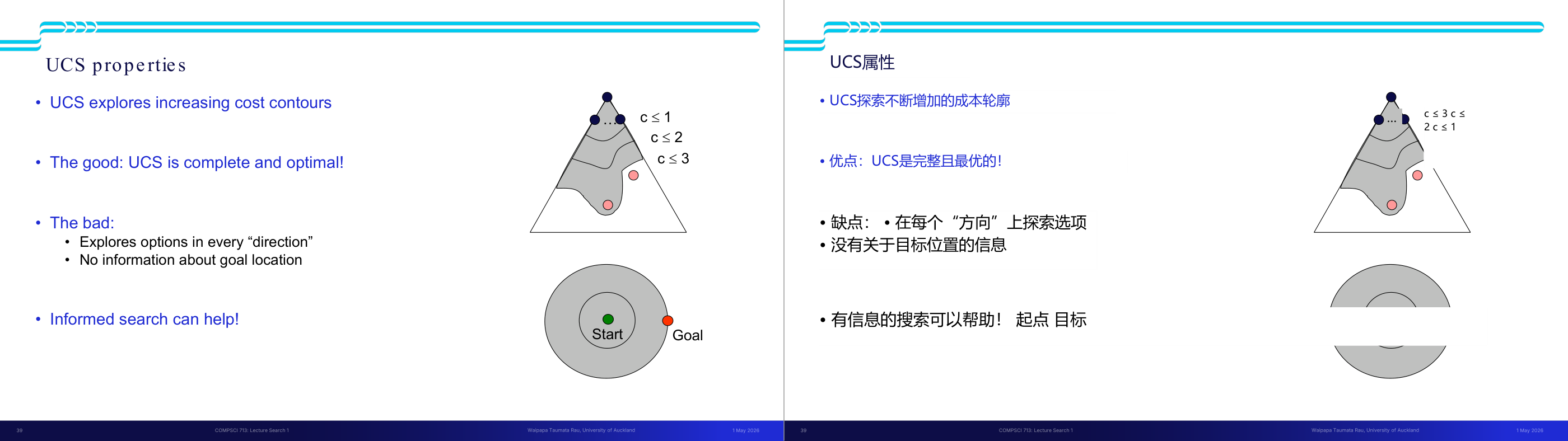
这一页讲的是无信息搜索中的广度优先搜索(Breadth-First Search, BFS)。广度优先搜索的核心策略是优先扩展最浅层的节点,这意味着它会逐层探索图中的节点。实现上,边界节点(Fringe)使用先进先出(FIFO)队列来存储待扩展的节点。幻灯片中包含一个图结构示例和搜索层级(Search Tiers)的可视化。图结构中,从起始节点 S 开始,逐层扩展到节点 d、e,再到 b、c、h、r 等。下方的搜索层级图展示了 BFS 的过程:从最浅层开始扩展,逐步探索更深层的节点。比如,第一层扩展节点 S,第二层扩展节点 d 和 e,第三层扩展节点 b、c、h 和 r,依次类推。这种方法的优点是能够保证找到最短路径,但缺点是可能需要较多的内存来存储队列中的节点。一个例子是,在寻找从 S 到目标节点 G 的路径时,BFS 会先找到从 S 到 G 的最短路径,而不会遗漏任何可能的路径。
这一页讲的是 DFS(深度优先搜索)的性质分析,重点在它的优缺点取舍。DFS 策略是始终展开最深的节点,实现上 fringe 是 LIFO 栈。时间复杂度是 O(b 的 m 次方),因为最坏情况是遍历整棵树。空间复杂度是 O(bm)——这是 DFS 最大的优势:fringe 里只需要保存当前路径上每层的兄弟节点,最多是从根到最深节点的路径长度 m 乘以每层分支数 b。完备性:若 m 有限且能防止循环则完备,但如果图有环或 m 无穷大则不完备。最优性:不保证,DFS 找到的是「最左边」的解而不是代价最小的解。直觉上:DFS 像一个一直往前冲、撞墙才回头的人——省内存但不保证找最优路径。考试常见考法:在给定搜索树上追踪 DFS 展开顺序;或比较 DFS 和 BFS 在什么场景下哪个更好。易错点:DFS 空间复杂度是 O(bm) 而非 O(b 的 m 次方),这和时间复杂度不同,是 DFS 的核心优势,一定要记清楚。
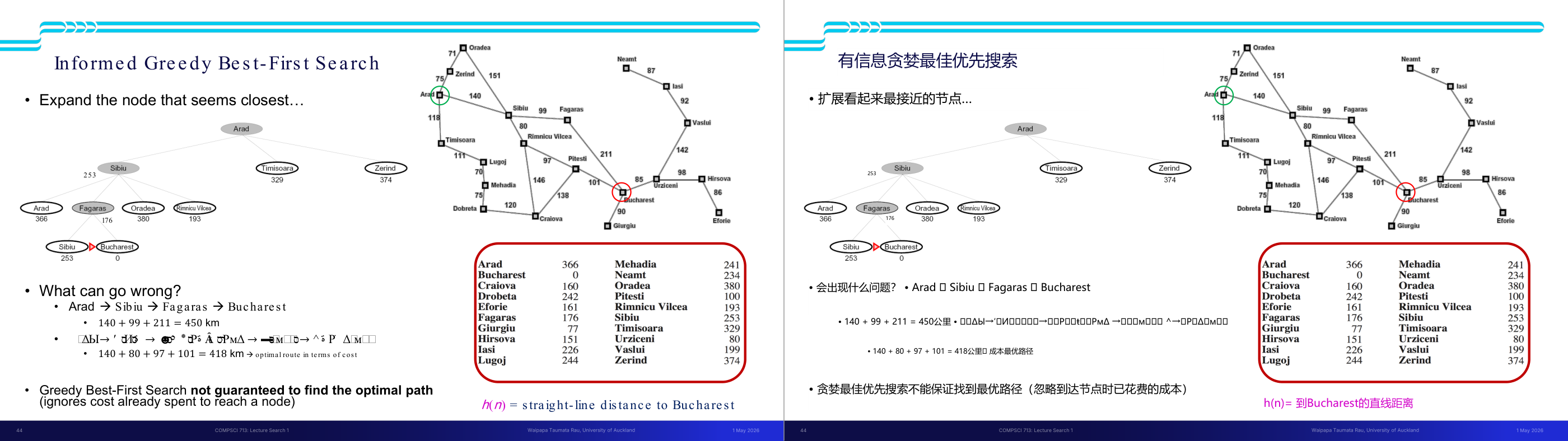
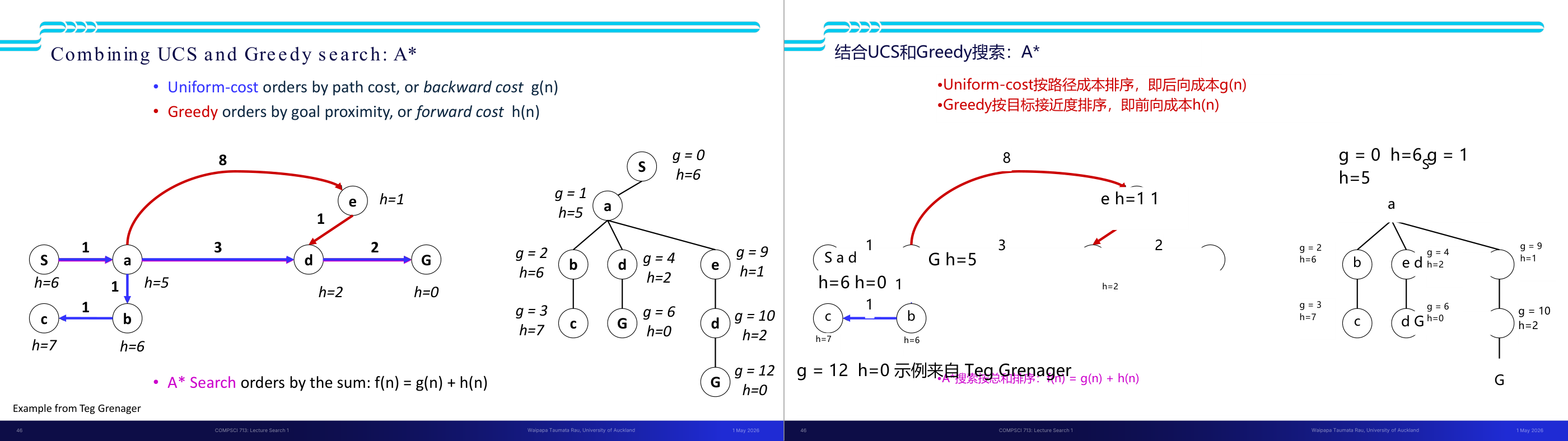
这一页讲的是 A 搜索算法,它结合了两种搜索策略:Uniform-cost search 和 Greedy search。Uniform-cost search 按路径成本 g(n)(即 backward cost)排序,而 Greedy search 按目标接近程度 h(n)(即 forward cost)排序。A 搜索通过 f(n)=g(n)+h(n) 的总和来综合考虑这两种成本,从而实现更高效的路径搜索。幻灯片中的图展示了一个搜索问题的状态图和搜索树。状态图中,节点的 h(n) 表示启发式估计值,边上的数字表示路径成本。搜索树中,每个节点的 g(n) 是从起点到该节点的路径成本,h(n) 是从该节点到目标的估计成本。通过计算 f(n),可以优先选择最优的扩展路径。例如,从起点 S 开始,选择路径时会综合考虑 g 和 h,最终找到到目标节点 G 的最优路径。这种算法在路径规划和人工智能中非常重要,因为它能够有效地平衡搜索效率和准确性。
这一页讲的是 A(A-star)搜索算法的核心思想——将 UCS 的后向代价 g(n) 和贪心最佳优先搜索的前向启发 h(n) 组合成 f(n) 等于 g(n) 加 h(n)。g(n) 是从起始节点到当前节点 n 的实际代价(backward cost,已经花掉的路径代价);h(n) 是从 n 到目标的启发式估计代价(forward cost,对剩余路径的猜测);f(n) 是对「经过 n 的最优完整路径」总代价的估计。A 每次展开 f 值最小的节点,用优先队列实现。直觉上:UCS 只顾「已走了多远」,会在起点附近兜圈;Greedy 只顾「离目标多近」,会走捷径但可能绕远;A 两者兼顾,既考虑已付出的代价又朝着目标方向走。页面给出了一个具体追踪例子,从 S 出发,展开顺序由每个节点的 f 值决定。考试常考:给定图和 h 值表,手动追踪 A 展开顺序;或解释为什么 A 比 UCS 和 Greedy 都好。易错点:A 的终止条件是「从优先队列中取出目标节点时停止」,不是「把目标节点放入队列时停止」——因为放入时的 f 值可能不是最优的,后续可能有更好的路径到达同一目标。
第 44 / 56 页
这一页讲的是 A 算法的核心思想,包括如何选择扩展节点和启发式估计的作用。
这一页讲的是 A 算法的核心思想。A 算法通过扩展最可能在最优路径上的节点来寻找最短路径。具体来说,它会选择满足 f(n) 小于等于最优解成本的节点,其中 f(n) = g(n) + h(n)。g(n) 是从起点到节点 n 的实际成本,而 h(n) 是从节点 n 到目标的启发式估计成本。理想情况下,我们希望使用 h(n),即从 n 到目标的真实最小成本,但通常无法直接获得 h(n),因此用 h(n) 作为近似值。A 算法的关键是使用优先队列,根据 g(n) + h(n) 的值对节点进行排序,从而优先扩展估计成本最低的节点。这种方法结合了深度优先搜索和广度优先搜索的优点,既能保证路径最优,又能提高搜索效率。
第 45 / 56 页
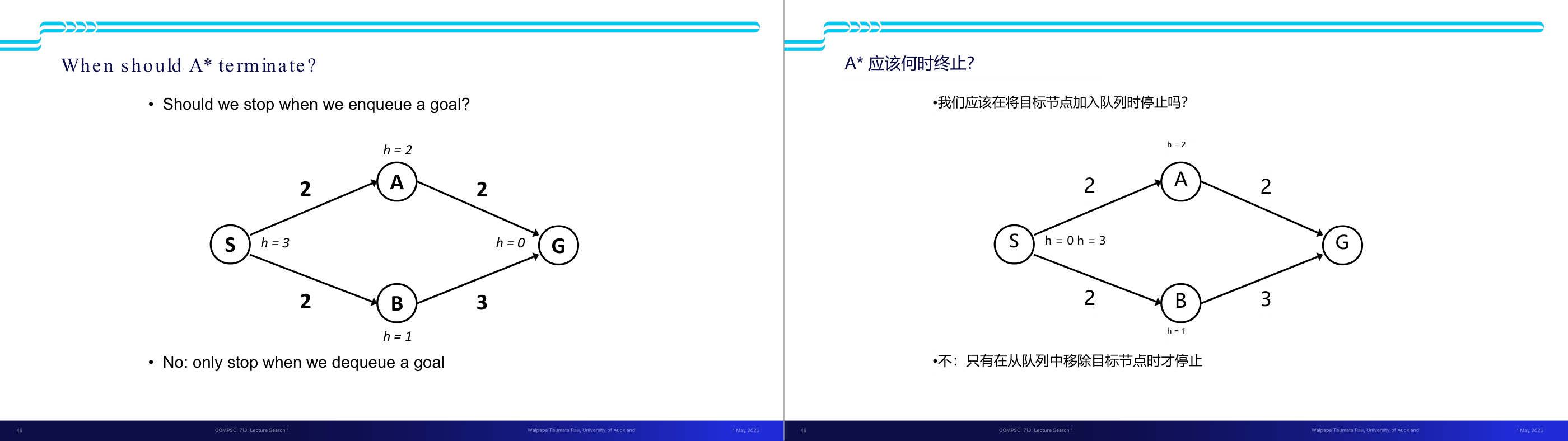
这一页讲的是 A 算法的终止条件,重点讨论是否在目标节点入队时停止搜索,以及建议的正确终止方式。
这一页讲的是 A 算法的终止条件。图中展示了一个简单的搜索图,包含起始节点 S、目标节点 G,以及中间节点 A 和 B。每个节点标注了启发式估计值 h,例如 S 的 h=3,A 的 h=2,等等。边上的数字表示从一个节点到另一个节点的实际代价。幻灯片提出一个问题:当目标节点 G 被入队时,是否应该停止搜索?答案是否定的,建议只有在目标节点 G 被出队时才停止。这是因为 A 算法的优先队列基于 f 值(即 f=g+h,其中 g 是到当前节点的实际代价,h 是启发式估计值),只有在目标节点出队时才能确保找到最优路径。举例来说,从 S 到 G 的路径可以通过两条路线:S-A-G 和 S-B-G。只有在目标节点 G 出队时,才能确定哪条路径的 f 值更小,从而保证搜索的正确性。
第 46 / 56 页
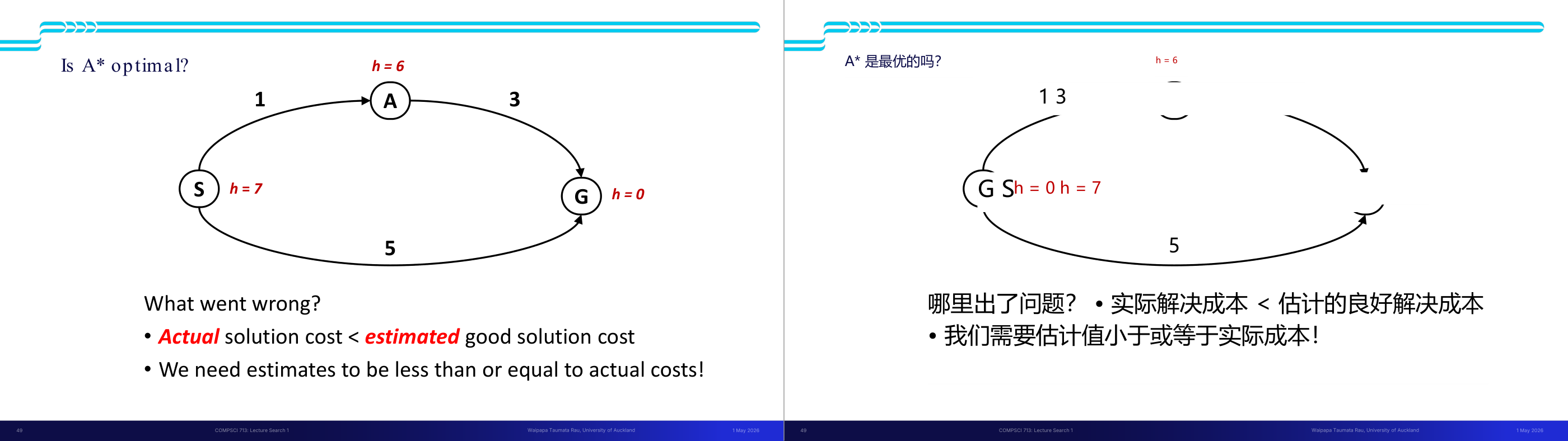
这一页讲的是 A 算法的最优性问题。主要讨论了实际代价与估计代价的关系,以及估计值需要满足的条件。
这一页讲的是 A 算法是否最优的问题。图中展示了一个简单的搜索图,其中节点 S 是起点,节点 G 是目标点,节点 A 是中间节点。每条边的数字表示从一个节点到另一个节点的实际代价,而每个节点的 h 值表示启发式估计代价。问题出在节点 S 的 h 值为 7,而实际从 S 到 G 的最优路径代价是 6(通过 S -> A -> G)。这导致估计值高于实际值,违反了 A 算法的最优性条件。下方文字指出了问题的核心:实际解的代价小于估计的代价,而启发式估计值必须小于或等于实际代价才能保证 A 算法的最优性。这一条件称为启发式的“一致性”或“可接受性”。举例来说,如果 h(S) 改为 5,算法就会选择正确的路径。
这一页讲的是 Admissible heuristics(可接受的启发式)。定义中指出,一个启发式函数 h 是可接受的(admissible)的条件是:对于所有节点 n,h(n) 的值必须满足 0 ≤ h(n) ≤ h(n),其中 h(n) 是从节点 n 到最近目标的真实代价。这意味着可接受的启发式是乐观的,它不会高估实际代价。幻灯片还举了一个例子:在 Pacman 游戏中,曼哈顿距离是一种可接受的启发式,因为它计算的是从当前位置到目标位置的最短路径长度(仅考虑上下左右移动,即 NEWS 方向)。图中展示了 Pacman 从当前位置到目标的路径,曼哈顿距离为 15。最后强调,找到既有效又便宜的可接受启发式是成功的关键。这些启发式在搜索算法中非常重要,例如 A 算法,它依赖于启发式函数来引导搜索方向并优化效率。
这一页讲的是 Admissible heuristic(可采纳启发函数)的定义及其与 A 最优性的关系,这是 713 搜索模块最核心的考点。定义:启发函数 h 是 admissible 的,当且仅当对所有节点 n,有 0 小于等于 h(n) 小于等于 h(n),其中 h(n) 是从 n 到最近目标的真实最优代价。换句话说,admissible heuristic 是「乐观的」——它从不高估剩余代价。经典例子:Pac-Man 问题中 Manhattan distance(曼哈顿距离)是 admissible 的,因为实际路径永远不会比直线格距更短(Pac-Man 只能走上下左右四个方向);Euclidean distance(欧氏距离)也是 admissible 的,因为直线距离永远不超过实际路径长度。为什么 admissibility 保证 A 最优?直觉是:如果 h 从不高估,那么当 A 展开一个次优解时,optimal 解的某个祖先节点在 fringe 上的 f 值一定更小,所以 optimal 解的路径会先被展开。考试常考:判断给定的 h 是否 admissible;设计一个 admissible heuristic;或解释反例(如果 h 高估了某节点会导致什么错误)。易错点:admissible 只要求「不高估」,并不要求精确——h 可以是 0(永远不高估,但也没什么用),那是 admissible 但 inefficient 的极端情况。
第 48 / 56 页
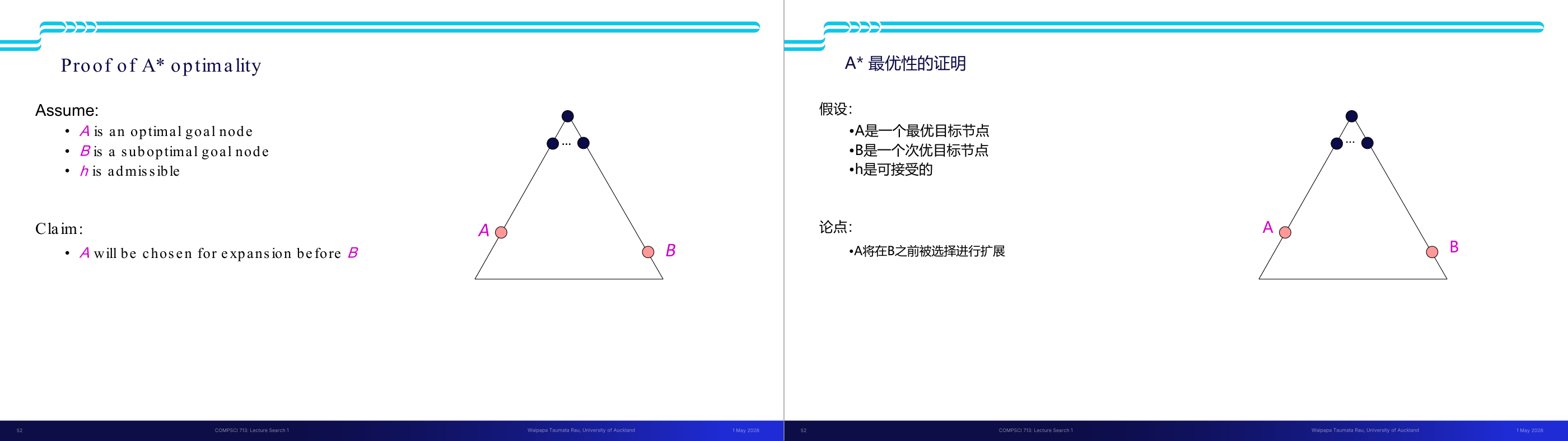
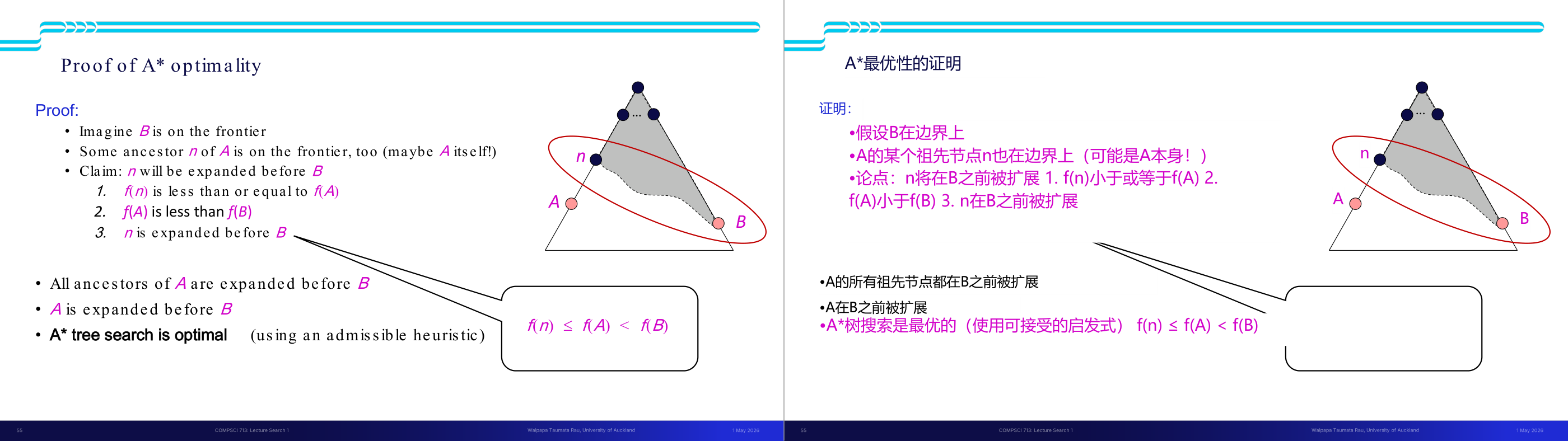
这一页讲的是 A 算法的最优性证明,假设 h 是可接受的启发式函数,A 是最优目标节点,B 是次优目标节点。结论是 A 会优先于 B 被扩展。
这一页讲的是 A 算法的最优性证明。首先假设 h 是可接受的启发式函数(admissible),即它从不高估到目标节点的实际代价;同时假设 A 是最优目标节点,B 是次优目标节点。基于这些假设,提出的结论是:在搜索过程中,A 会优先于 B 被选择进行扩展。这是因为 A 算法通过 f(n) = g(n) + h(n) 来评估节点,其中 g(n) 是从起点到当前节点的实际代价,h(n) 是启发式估计代价。由于 h 是可接受的,A 的 f 值会小于或等于 B 的 f 值,从而确保 A 算法总是优先扩展最优路径上的节点。图中展示了一个简单的搜索树结构,A 和 B 分别位于不同的分支上,说明了算法如何选择扩展路径。这个证明对于理解 A 算法的效率和准确性至关重要,确保它能够找到全局最优解。
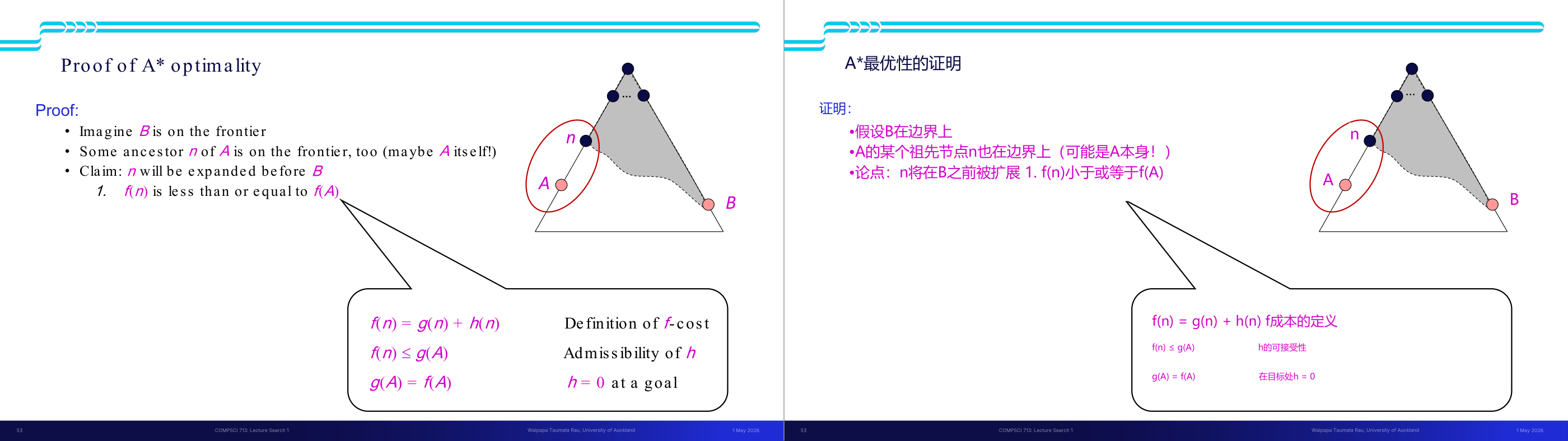
这一页讲的是 A 最优性的完整证明,分三步推导,考试可能要求你复述证明思路。设定:A 是最优目标节点,B 是次优目标节点,h 是 admissible 的。我们要证明 A 一定在 B 之前被展开。第一步:fringe 上 A 的某个祖先节点 n 满足 f(n) 小于等于 f(A)。推导:f(n) 等于 g(n) 加 h(n),由 admissibility 知 h(n) 小于等于 h(n),而 g(n) 加 h(n) 等于 g(A)(n 到 A 的路径代价),所以 f(n) 小于等于 g(A);又因为 A 是目标节点 h(A) 等于 0,所以 g(A) 等于 f(A);综合得 f(n) 小于等于 f(A)。第二步:f(A) 小于 f(B)。推导:B 是次优节点所以 g(A) 小于 g(B);B 是目标节点所以 h(B) 等于 0,因此 f(B) 等于 g(B);综合得 f(A) 小于 f(B)。第三步:由一和二可得 f(n) 小于等于 f(A) 小于 f(B),所以 n 在 B 之前被展开,A 的所有祖先都在 B 之前被展开,最终 A 在 B 之前被展开。结论:使用 admissible heuristic 的 A tree search 是最优的。考试要点:能写出三步骤的关键不等式;理解每一步用到了哪个前提(admissibility 和 B 次优)。易错点:这个证明针对 tree search——graph search(避免重复展开状态)需要更强的 consistent heuristic 才能保证最优性。
第 49 / 56 页
这一页讲的是 A 算法的最优性证明,重点在于路径节点的扩展顺序和 f(n) 的定义与性质。
这一页讲的是 A 算法的最优性证明。首先假设节点 B 在边界上,同时某个节点 n 是目标节点 A 的祖先,也在边界上。证明的关键是节点 n 会在 B 之前被扩展,因为 f(n) 的值小于或等于 f(A)。其中,f(n) 是由 g(n) 和 h(n) 组成的代价函数,公式为 f(n) = g(n) + h(n)。这里 g(n) 表示从起点到节点 n 的实际代价,而 h(n) 是从 n 到目标节点的估计代价。为了保证 A 算法的最优性,h(n) 必须是可接受的(admissible),即 h(n) 在目标节点处为 0,并且不会高估实际代价。图中展示了节点 A 和 B 的位置关系,以及边界上节点的扩展顺序。这个证明说明了 A 算法能够优先扩展具有最低 f 值的节点,从而保证找到最优路径。
第 50 / 56 页
这一页讲的是 A 算法的最优性证明。关键点包括边界节点的扩展顺序、f(n) 和 f(A) 的关系,以及 f(A) 与 f(B) 的比较。
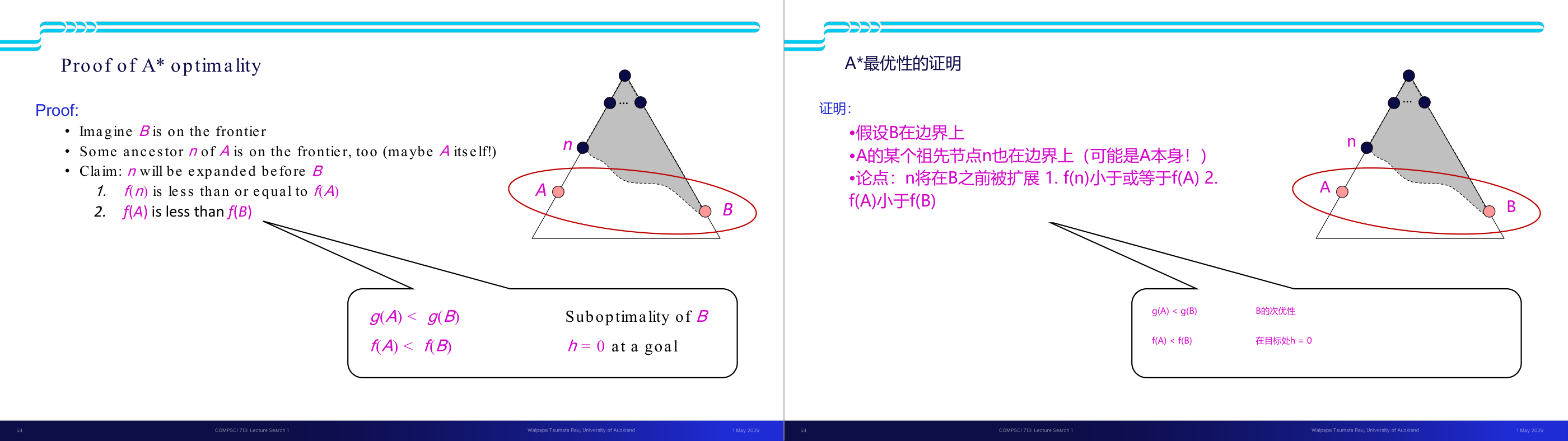
这一页讲的是 A 算法的最优性证明。首先,假设节点 B 在边界 (frontier) 上,同时节点 A 的某个祖先 n 也在边界上(可能是 A 本身)。根据证明,n 会在 B 之前被扩展。原因是 f(n) 的值小于或等于 f(A),而 f(A) 的值又小于 f(B)。图中展示了边界上的节点分布,其中 n 是 A 的祖先,A 和 B 被标记为粉色节点,边界用红色椭圆圈出。关键公式包括 g(A) < g(B),以及 f(A) < f(B)。此外,图中提到目标节点的 h 值为 0,这进一步支持 A 算法的最优性,因为它总是优先扩展估计代价最小的路径。这一证明的重要性在于,确保 A 算法在启发函数 h(n) 是可接受的情况下能够找到最优解。
第 51 / 56 页
这一页讲的是 A 算法的最优性证明,重点在于解释为什么 A 搜索是最优的。要点包括 f(n)、f(A)、f(B) 的关系,以及节点扩展顺序的逻辑。
这一页讲的是 A 算法的最优性证明,强调了使用可接受启发式(admissible heuristic)时,A 搜索能够保证最优解。证明的核心逻辑是:假设目标节点 B 在边界上,同时 A 的某个祖先节点 n 也在边界上(可能是 A 本身)。根据 f(n) ≤ f(A) < f(B) 的关系,可以得出 n 会在 B 之前被扩展。进一步推导出所有 A 的祖先节点都会在 B 之前扩展,因此 A 本身也会在 B 之前扩展。这种扩展顺序确保了 A 算法的最优性。右侧的图形展示了节点之间的关系,其中灰色区域表示搜索空间,红色椭圆圈出边界节点 A 和 B,强调了 f 值的比较关系。通过这些逻辑,可以得出结论:A 算法在使用可接受启发式时是最优的。