这一页讲的是对抗搜索(Adversarial Search),重点介绍了两种算法:Minimax 和 MCTS(Monte Carlo Tree Search)。对抗搜索是人工智能中用于解决博弈问题的重要技术,尤其在棋类游戏或其他竞争性环境中。Minimax 是一种基于递归的算法,用于在完全信息博弈中寻找最优策略,通过评估每个可能的行动来最大化自己的得分,同时最小化对手的得分。MCTS 则是一种基于统计的搜索方法,通过模拟大量随机样本路径来估计行动的价值,适用于信息不完全或搜索空间较大的问题。这两种方法在游戏 AI 和决策系统中具有广泛应用,理解它们的原理和适用场景对学习 AI 基础非常重要。
第 2 / 34 页
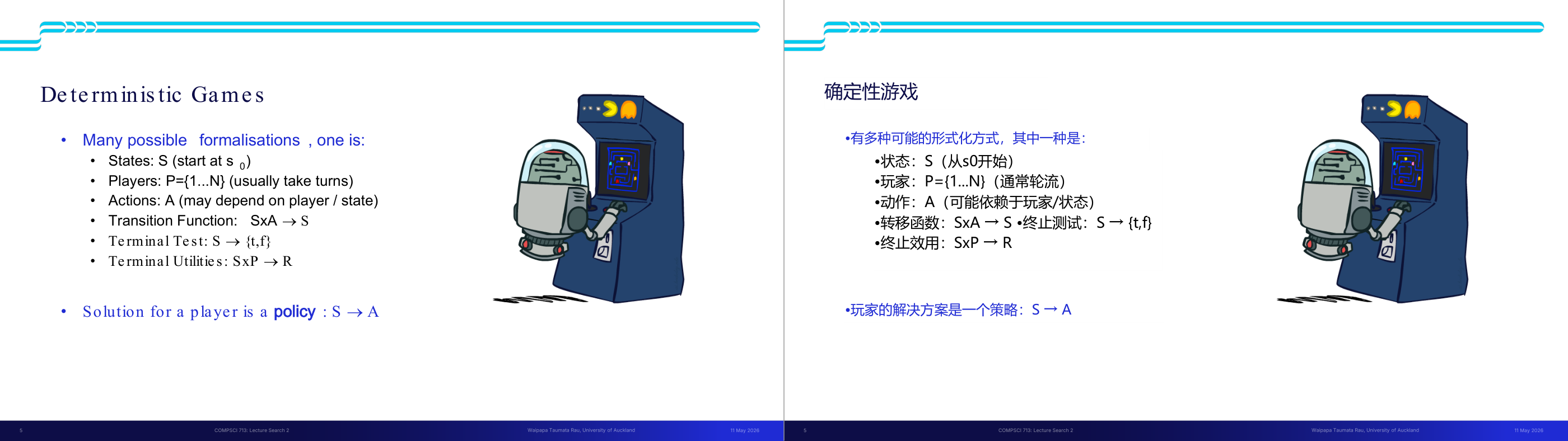
这一页讲的是学习目标,包括游戏问题的特点、对抗性游戏树和搜索算法的应用。
这一页讲的是学习目标,主要围绕对抗性搜索和游戏树展开。首先,要求描述不同类型游戏问题的特点,这可以帮助理解游戏问题的结构和复杂性。其次,学习如何构建对抗性游戏树(adversarial game tree),这种树用于模拟两个玩家的决策过程。接着,重点介绍如何应用极小极大算法(minimax algorithm)来寻找游戏树中的最佳下一步,这是一种常见的对抗性搜索方法。第四个目标是识别在资源有限条件下进行对抗性搜索的策略,这对于实际应用中的效率优化非常重要。最后,学习蒙特卡洛树搜索(Monte Carlo Tree Search)的原理,这是一种基于随机模拟的搜索算法,适用于复杂的决策问题。例如,在棋类游戏中,蒙特卡洛树搜索可以通过大量模拟来评估每一步的潜在价值,从而找到最优解。
第 3 / 34 页
这一页讲的是免责声明 (Disclaimer),说明幻灯片内容的来源。
这一页讲的是免责声明 (Disclaimer),主要强调幻灯片的内容来源于几位学者的工作。具体来说,这些幻灯片改编自 Pieter Abbeel 和 Dan Klein 的 UC Berkeley CS188 课程,以及 Mike Barley 和 Pat Riddle 的工作(来自奥克兰大学 UoA)。此外,幻灯片中的插图也来源于 Pieter Abbeel 和 Dan Klein 的 UC Berkeley CS188 课程。这一页的目的是明确知识产权归属,确保引用的内容具有权威性和可信度。
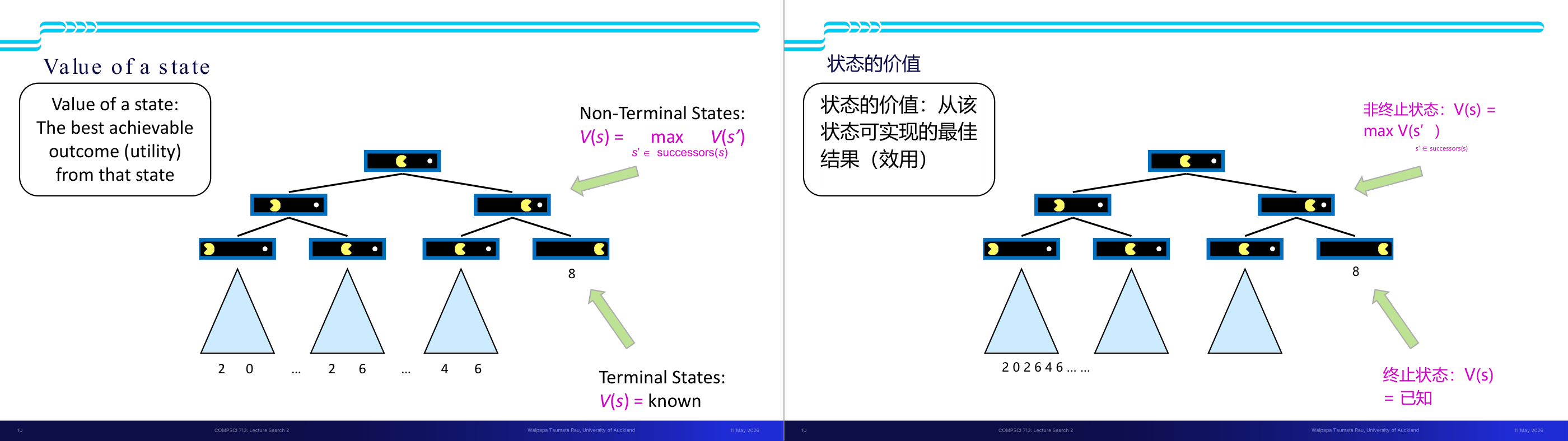
这一页讲的是状态的价值 (Value of a State)。主要内容包括状态价值的定义、终止状态和非终止状态的计算方式,以及树状图示例。
这一页讲的是状态的价值 (Value of a State),即从某个状态出发能够达到的最佳结果或效用 (utility)。幻灯片中定义了两种状态:终止状态 (Terminal States) 和非终止状态 (Non-Terminal States)。终止状态的价值是已知的,直接给出,例如图中底部的三角形标注了具体数值(如 2、0、6 等)。非终止状态的价值通过递归计算,公式为 V(s) = max V(s'),其中 s' 是当前状态的后继状态 (successors)。树状图展示了一个状态空间的结构:从根节点开始,每个非终止状态的价值由其子节点的最大值决定。例如,右侧非终止状态的子节点中有一个终止状态值为 8,因此该非终止状态的价值为 8。这种计算方法在强化学习和搜索问题中非常重要,可以帮助我们找到最优路径或策略。
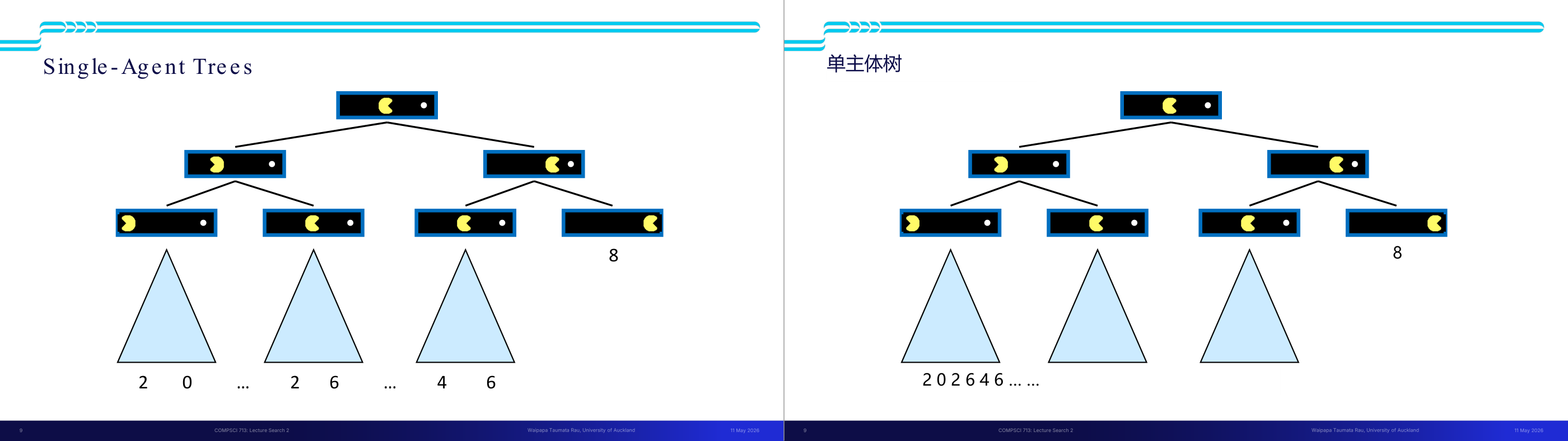
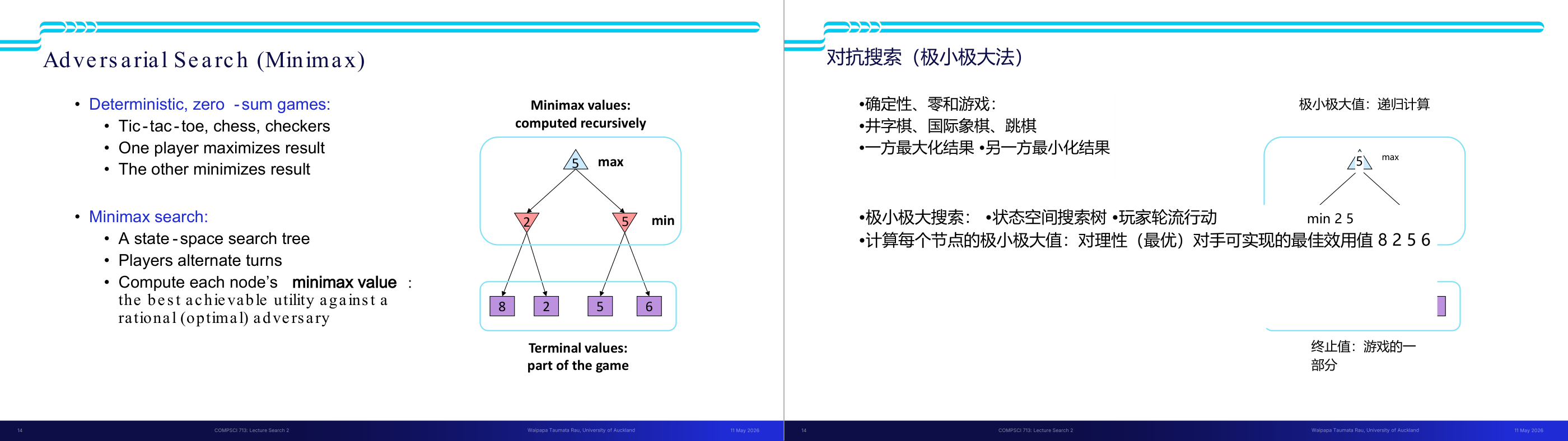
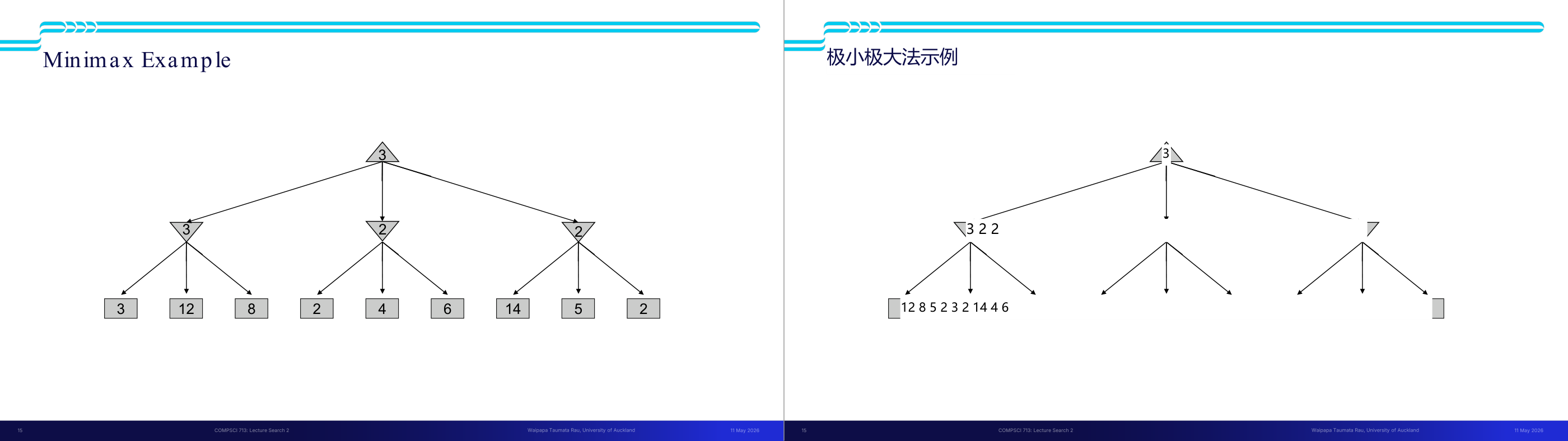
这一页讲的是状态价值函数(Value of a State)在单智能体搜索树中的定义。核心公式是:某个状态 s 的价值 V(s) 等于所有后继状态 s' 中 V(s') 的最大值,即 V(s) 等于对所有 successors(s) 里的 s' 取 max V(s');而终止状态的 V 直接由游戏规则给出。这个定义奠定了整个 minimax 框架的基础。直觉上,「最优价值」就是「如果我从这个状态出发走最聪明的一步,最终能拿到的最好结果」。以图中例子理解:叶节点已知具体数值(如 8、2、0、6 等),父节点取子节点中的最大值向上传播,最终根节点得到的就是整局游戏的最优可达得分。考试常考:能手算一棵给定叶值树的每个节点价值;以及理解 V(s) 是定义在「当前决策者总是做最优选择」这一前提下的——单智能体时只有 max 层,引入对手之后就变成 minimax 的交替 max/min。易错点:很多同学会把「终止状态的 V 是已知的」和「非终止状态需要递归计算」混淆,导致递归基准情况写错。记住:只有叶节点才直接用游戏结果定义值,其他节点全靠递归。
第 11 / 34 页
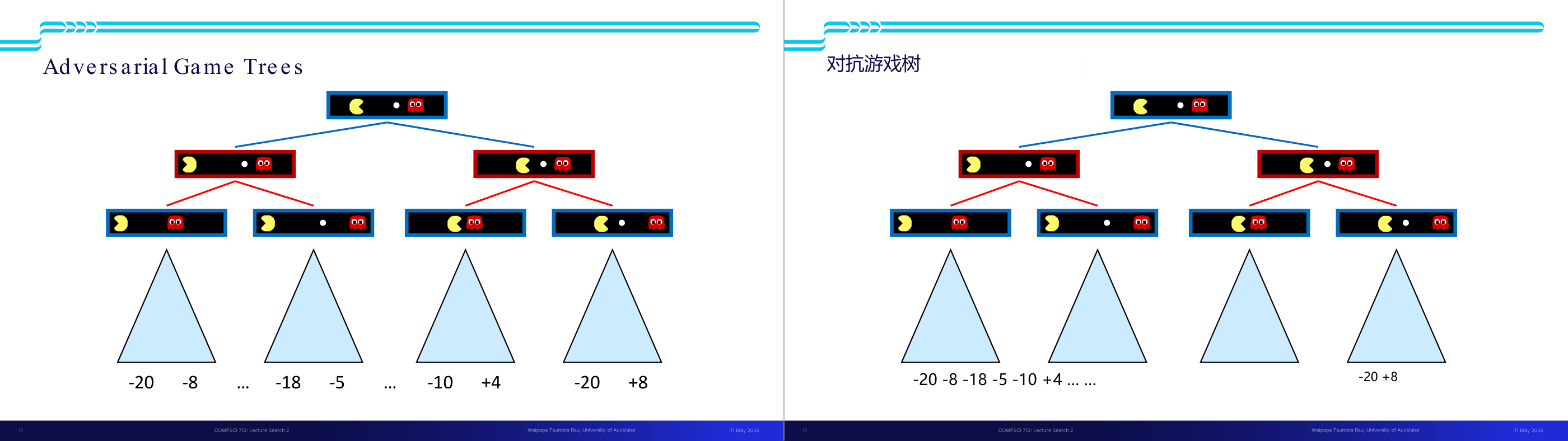
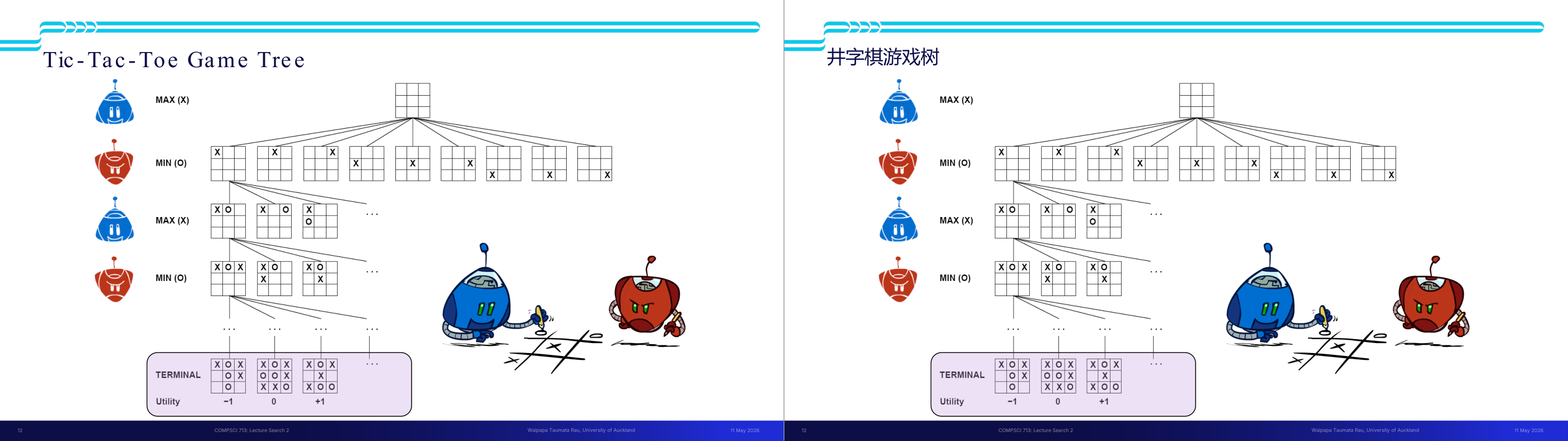
这一页讲的是对抗性游戏树 (Adversarial Game Trees),主要展示了游戏树结构、评分值以及决策过程的层级关系。
这一页讲的是井字棋(Tic-Tac-Toe)的游戏树结构及其终端状态的效用值。主要展示了 MAX 和 MIN 玩家在不同层级的决策过程,以及终端状态的评分规则。
这一页讲的是井字棋(Tic-Tac-Toe)的游戏树结构,重点分析 MAX 玩家(X)和 MIN 玩家(O)在游戏中的决策过程。图中展示了一个完整的游戏树,从初始状态开始,经过每一层的玩家轮流决策,逐步展开所有可能的棋盘状态。每一层由不同玩家控制,MAX 玩家试图最大化效用值,而 MIN 玩家试图最小化效用值。树的底部是终端状态(Terminal),即游戏结束时的棋盘状态。紫色区域列出了几种终端状态及其对应的效用值(Utility):+1 表示 MAX 赢,-1 表示 MIN 赢,0 表示平局。这种评分规则帮助算法评估每个状态的优劣,从而选择最佳策略。通过这种树结构,可以直观理解井字棋的所有可能路径及其结果。举个例子,若某状态下 MAX 玩家能确保胜利,则该路径会被优先选择。
第 13 / 34 页
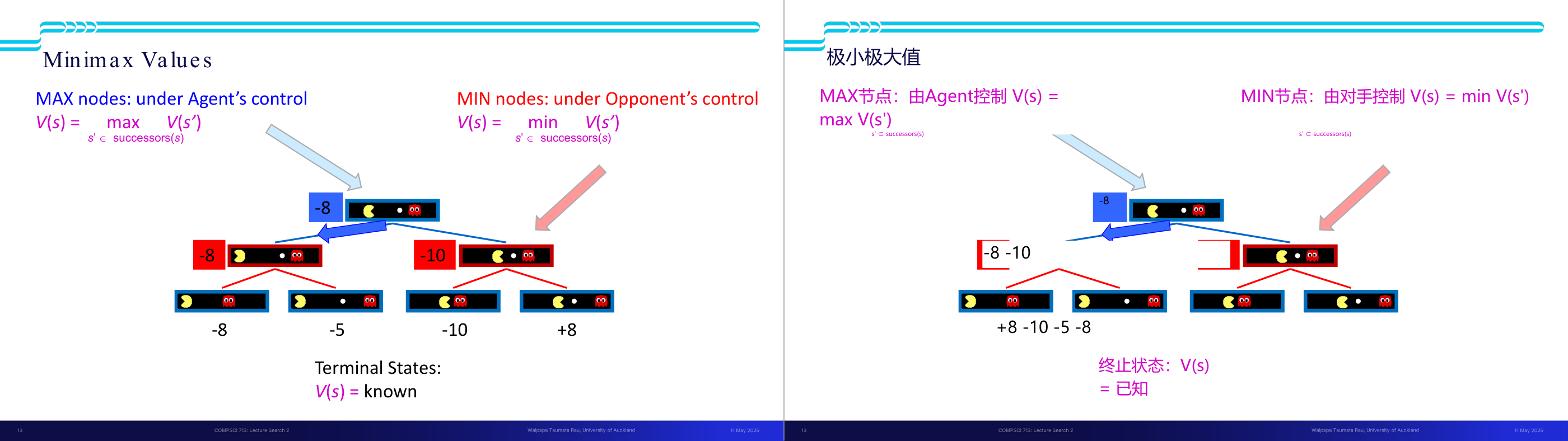
这一页讲的是 Minimax 算法的值计算过程。重点包括 MAX 节点由 Agent 控制,MIN 节点由 Opponent 控制,以及终端状态值已知。
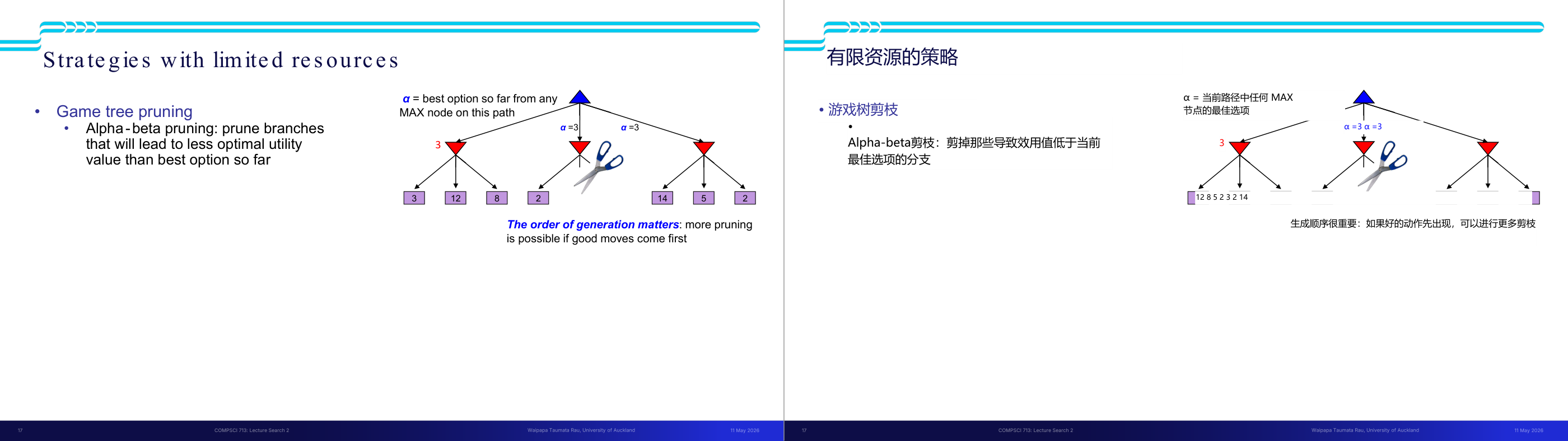
这一页讲的是有限资源下的策略,重点是游戏树剪枝(Game tree pruning)。主要介绍了 Alpha-Beta 剪枝的原理,以及生成顺序对剪枝效果的影响。
这一页讲的是有限资源下的策略,具体是游戏树剪枝(Game tree pruning)。Alpha-Beta 剪枝是一种优化搜索算法的方法,它通过剪掉那些不可能比当前最佳选择更优的分支,减少计算量。在右侧的图中,展示了一个游戏树,红色三角形表示 MAX 节点,紫色方块表示叶节点的效用值(utility value)。Alpha 值表示当前路径上 MAX 节点的最佳选择,例如图中 α=3,表示当前路径的最佳效用值为 3。剪刀图示说明了某些分支被剪掉,因为它们的效用值显然不会超过 α=3。此外,幻灯片强调了生成顺序的重要性:如果好的选择先被生成,剪枝效果会更显著。例如,右侧的分支在 α=3 的情况下,后续的效用值如 14 不会被考虑,因为它已被剪枝。这种方法在减少搜索空间的同时保持了结果的准确性,是人工智能搜索算法中的重要优化策略。
第 18 / 34 页
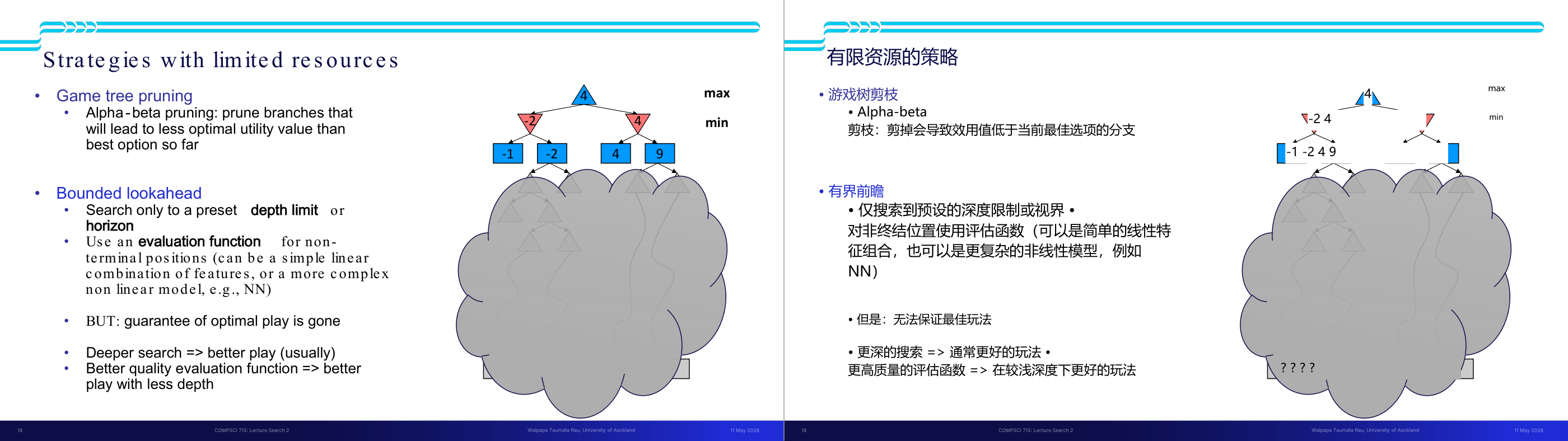
这一页讲的是有限资源情况下的搜索策略,包括游戏树剪枝和有限展望两种方法。
这一页讲的是有限资源情况下的搜索策略,主要包括两种方法:游戏树剪枝(Game tree pruning)和有限展望(Bounded lookahead)。游戏树剪枝中最常用的是 Alpha-Beta 剪枝,它通过剪除那些会导致较低效用值的分支,从而减少计算量,保留当前最优选项。图中展示了一个简单的 Alpha-Beta 剪枝过程,其中最大节点和最小节点交替选择最优值。有限展望策略则是通过设定搜索深度限制(depth limit)或视野范围(horizon),仅搜索到预定的深度。对于非终端状态,使用评估函数(evaluation function)来估计效用值,该函数可以是简单的线性组合,也可以是更复杂的非线性模型(如神经网络)。然而,这种方法无法保证绝对最优的游戏表现。深入的搜索通常能带来更好的结果,而更高质量的评估函数则可以在较浅的搜索深度下实现更好的表现。这两种策略在资源有限的情况下非常重要,能够显著提高搜索效率并优化决策。
第 19 / 34 页
这一页讲的是 Monte-Carlo Tree Search (MCTS)。它是一种用于决策和搜索的算法,特别适合在巨大搜索空间中找到最佳策略。
这一页讲的是 Monte-Carlo Tree Search (MCTS),它是一种基于概率和模拟的搜索算法,常用于解决复杂的决策问题,例如棋类游戏或机器人规划。MCTS 的核心思想是通过模拟未来可能的行动路径,逐步扩展搜索树,并根据模拟结果优化决策。Monte-Carlo 方法利用随机抽样来估算某些状态的价值,而树搜索则通过逐步扩展节点来探索最优路径。这种方法的优势在于它可以在不需要完全搜索整个空间的情况下,找到近似最优解。幻灯片中的图片可能是为了形象化“Monte-Carlo”这一术语,暗示其与概率和随机性相关。一个简单的例子是围棋中,MCTS 可通过模拟不同的落子路径,评估每一步的胜率,从而选择最优策略。
第 20 / 34 页
这一页讲的是 Monte-Carlo Tree Search (MCTS) 的核心思想,包括选择性搜索和通过模拟进行评估。
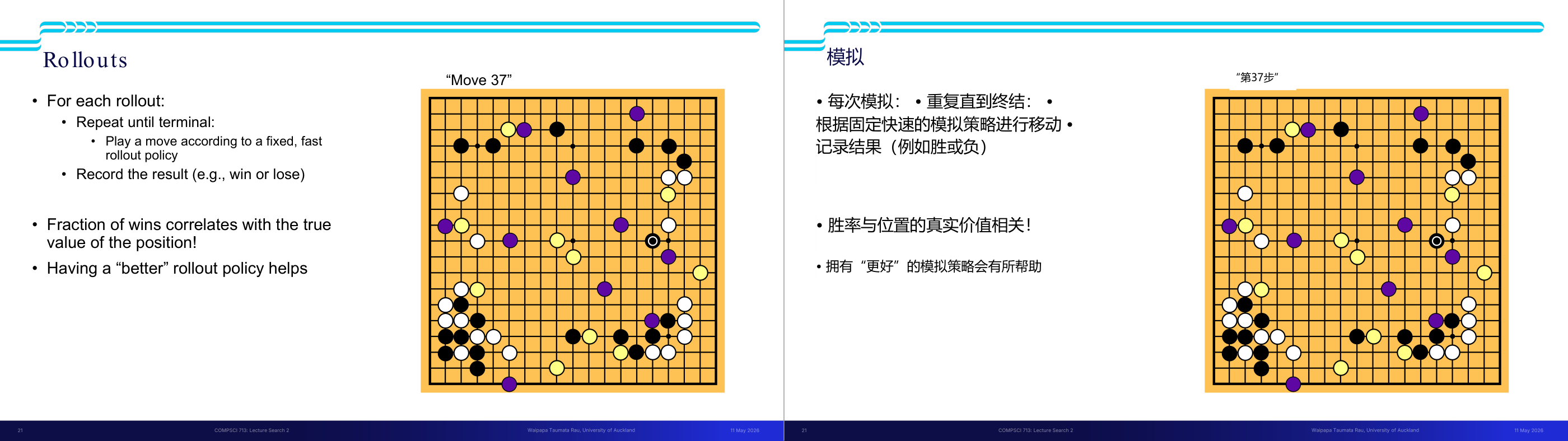
这一页讲的是 Monte-Carlo Tree Search (MCTS),它结合了两个重要的概念:选择性搜索 (Selective search) 和通过模拟进行评估 (Evaluation by rollouts)。选择性搜索的核心是探索树中的部分节点,这些节点能够帮助改进根节点的决策,而不受树深度的限制。这种方法避免了对整个搜索空间的全面探索,提升了效率。通过模拟进行评估的方式是从某个状态 s 开始,使用简单且快速的 rollout 策略,进行多次游戏直到结束,并记录胜负情况。这种评估方法通过统计大量模拟结果来预测某个状态的可能结果,从而为决策提供依据。例如,在棋类游戏中,MCTS可以从当前棋盘状态出发,模拟多次对局来评估每一步的潜在价值。
这一页讲的是蒙特卡洛搜索中的 Rollouts 方法。Rollouts 是一种模拟对局的方法,用于评估棋盘上某个位置的价值。具体来说,每次 Rollout 会重复进行,直到对局结束。在模拟过程中,按照一个固定且快速的 Rollout 策略(rollout policy)进行落子,并记录最终结果,例如胜负情况。通过多次模拟,可以计算胜率(fraction of wins),而这个胜率通常与该位置的真实价值相关联。幻灯片还指出,拥有一个更好的 Rollout 策略可以显著提高模拟的效果。右侧的围棋棋盘图展示了一个特定的棋局位置(“Move 37”),其中紫色和黄色标记可能代表不同策略的模拟结果。通过这种方法,可以帮助人工智能更准确地评估棋盘位置的优劣。例如,如果一个位置的胜率较高,说明它可能是一个更优的选择。这种方法广泛应用于棋类游戏的 AI 中,如 AlphaGo。
第 22 / 34 页
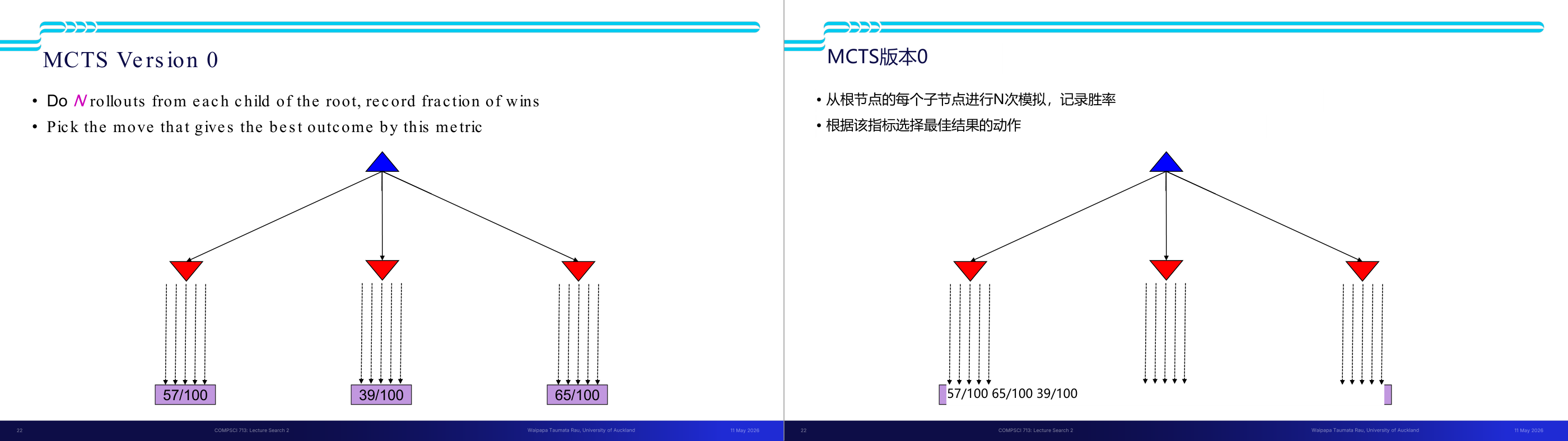
这一页讲的是蒙特卡洛树搜索(MCTS)的基本版本,强调通过模拟选取最佳动作。
这一页讲的是蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)的Version 0版本。主要内容包括两个步骤:第一,从根节点的每个子节点进行 N 次模拟(rollouts),记录胜利的比例;第二,根据胜率选择能够带来最佳结果的动作。图中展示了一个简单的树结构,蓝色三角形代表根节点,红色三角形是子节点。每个子节点下方标注了模拟结果,例如左边子节点的胜率为57/100,中间为39/100,右边为65/100。通过比较这些胜率,可以看到右边子节点的胜率最高,因此在这个版本中会选择右边的动作。这种方法的直觉是通过大量模拟估计每个动作的潜在收益,从而指导决策。虽然简单,但这种方法可能忽略了探索的长期价值,需要进一步优化。
第 23 / 34 页
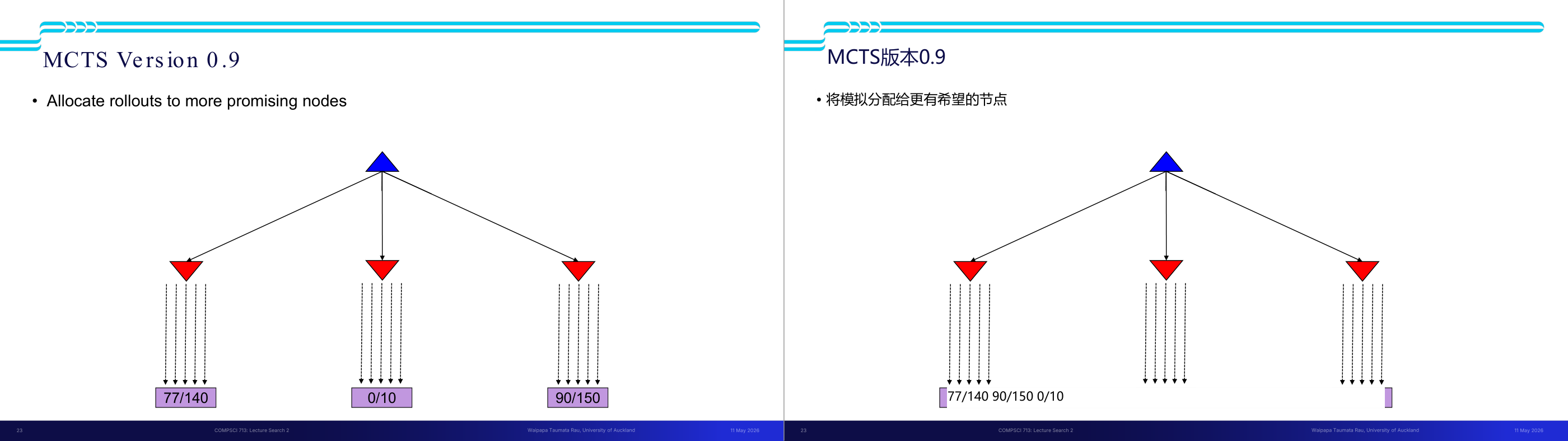
这一页讲的是 MCTS (Monte Carlo Tree Search) Version 0.9 的改进,通过将模拟分配给更有潜力的节点。
这一页讲的是 MCTS (Monte Carlo Tree Search) Version 0.9 的优化方法,其核心是通过分析节点的表现,将更多的模拟次数分配给更有潜力的节点。图中展示了一个树形结构,其中蓝色三角形表示根节点,红色三角形表示子节点。每个子节点下面有一个统计值,例如 '77/140' 表示该节点的成功次数为 77,总模拟次数为 140。通过比较不同节点的统计值,可以看出右侧节点 '90/150' 的成功率更高,因此会被分配更多的模拟次数,而中间节点 '0/10' 的表现较差,可能会被减少分配。这样的方法可以提高搜索效率,集中资源在更可能获得较好结果的路径上。这种机制在实际应用中可以显著提升搜索算法的性能,尤其是在复杂的决策问题中,例如游戏 AI 或路径规划。
第 24 / 34 页
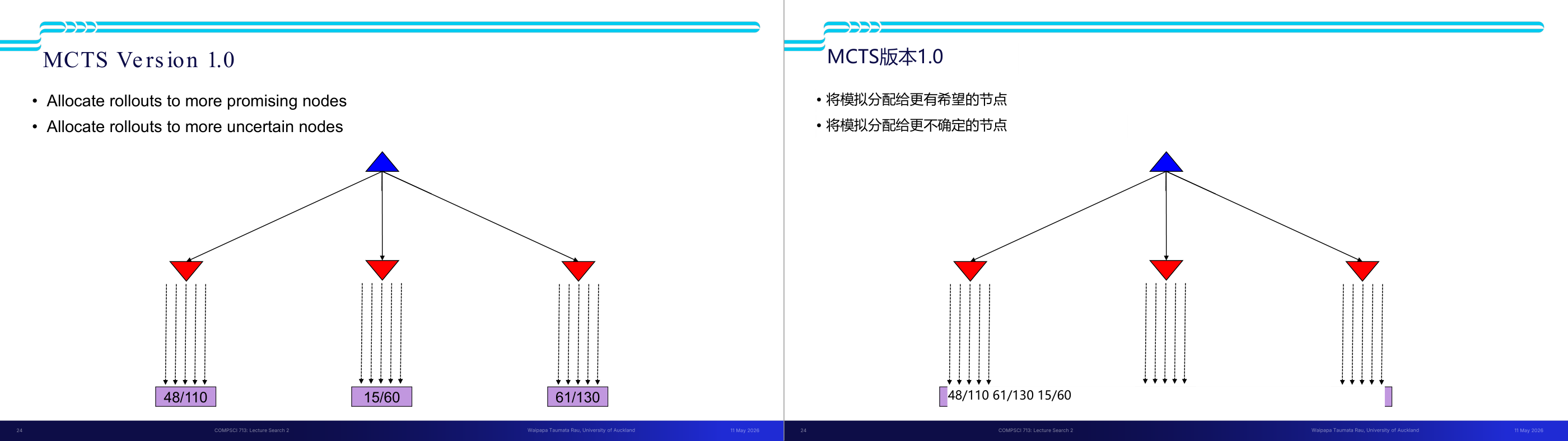
这一页讲的是 MCTS Version 1.0 的节点分配策略,包括分配到更有潜力的节点和更不确定的节点。
这一页讲的是 MCTS Version 1.0(蒙特卡洛树搜索)的节点分配策略。主要讨论如何合理分配模拟次数(rollouts)。第一点是将更多的模拟分配到更有潜力的节点,这样可以集中资源探索可能的最佳路径。第二点是将更多的模拟分配到更不确定的节点,以减少决策中的不确定性。图中展示了一个树结构,顶部蓝色节点通过箭头连接到三个红色子节点,每个子节点下面都有一个紫色框,框内的数字表示该节点的模拟次数和总次数。例如,左侧节点的数字是 48/110,表示该节点已经进行了 48 次模拟,总计分配了 110 次。通过这些数字可以看出,模拟次数的分配是基于节点的潜力和不确定性。这样的策略可以提高搜索效率,找到更优的解决方案。
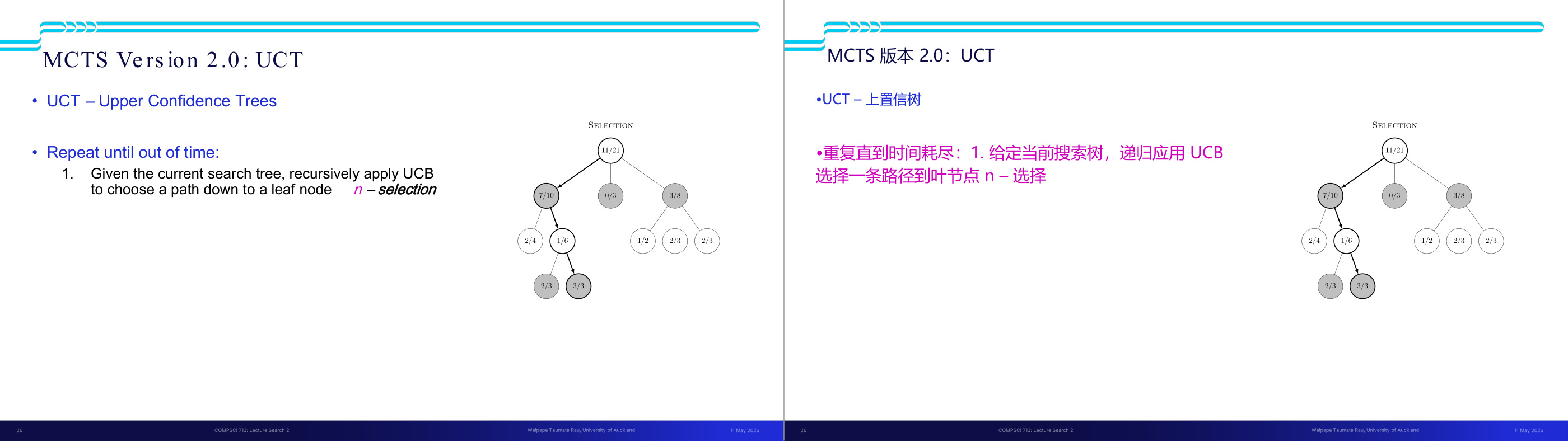
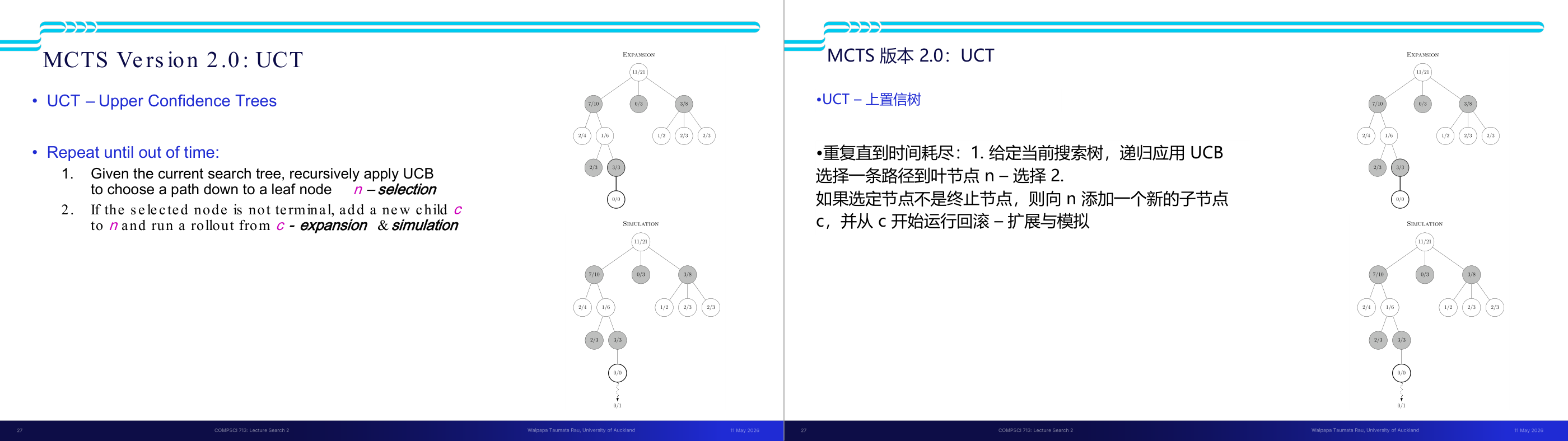
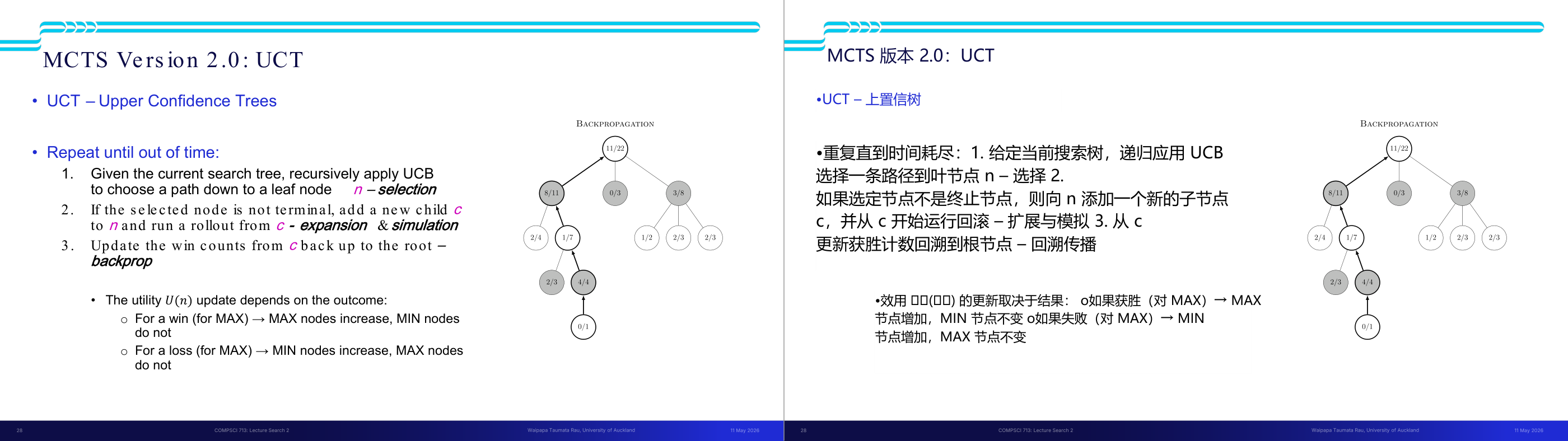
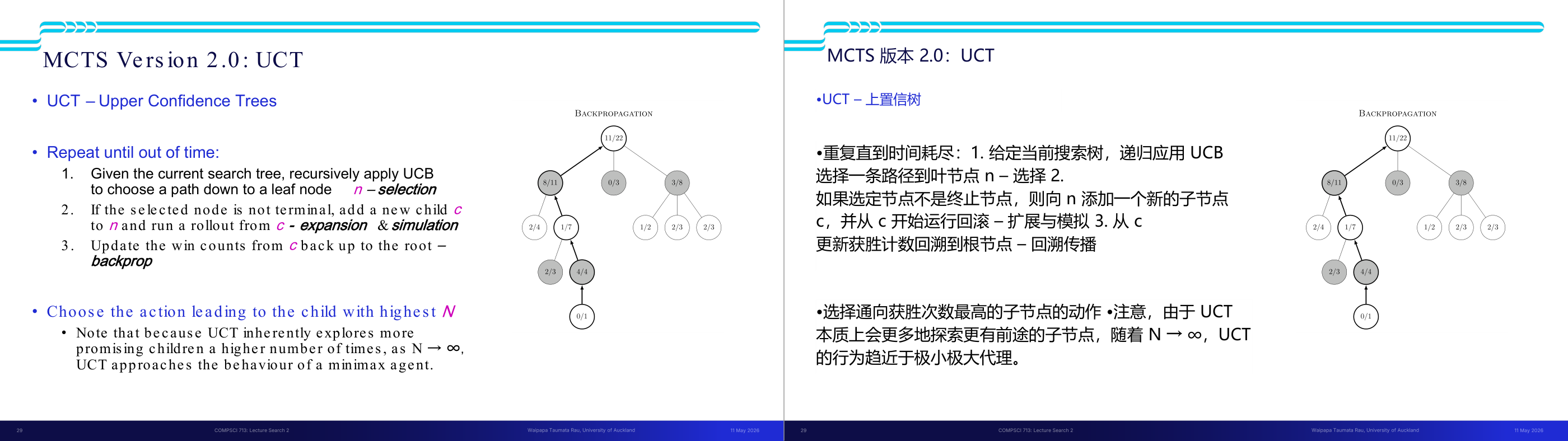
这一页讲的是 MCTS 的完整版本 UCT(Upper Confidence Trees)算法的四个步骤及其终止条件,是 MCTS 考试中最常考的流程题。UCT 的循环直到时间耗尽为止,每次迭代包含三步。第一步 Selection(选择):从根节点出发,递归应用 UCB 公式选择分值最高的子节点,一路向下直到达到叶节点 n。第二步 Expansion and Simulation(扩展+模拟):若 n 不是终止节点,为 n 新增一个子节点 c,并从 c 出发用快速随机的 rollout 策略模拟对局直到终局,记录结果(胜或负)。第三步 Backpropagation(反向传播):将模拟结果从 c 沿路径回传到根节点,更新路径上每个节点的 N(n) 和 U(n)。更新规则是不对称的:若 MAX 赢了,则路径上的 MAX 节点 U 加一,MIN 节点不加;反之亦然——这体现了对抗搜索中两方利益相反的本质。最终决策:时间到后,选择根节点中访问次数 N 最高的子节点对应的动作(注意:不是 UCB 分最高,而是 N 最高,因为 N 高意味着被充分验证过)。当 N 趋向无穷时,UCT 的行为逼近 minimax 的结果。考试常考:能写出或描述 UCT 四步流程;能解释 backprop 时 MAX/MIN 节点更新规则不同的原因。易错点:把最终决策误认为选 UCB 最高的孩子,正确答案是选 N 最高的孩子。
这一页讲的是 MCTS Version 2.0 中的 UCT (Upper Confidence Trees) 算法,它是一种基于蒙特卡洛树搜索的改进方法。主要流程包括三个步骤:第一,使用 UCB (Upper Confidence Bound) 算法递归选择路径,找到叶节点 n,这一步称为 selection;第二,如果 n 不是终止节点,则扩展一个新的子节点 c,并从 c 开始进行模拟,这一步是 expansion 和 simulation;第三,使用 backpropagation 从 c 回溯更新胜率到根节点。页面右侧的树状图展示了回溯更新的过程,节点中的数字表示胜率和访问次数,例如根节点显示 11/22,表示 22 次访问中有 11 次胜利。此外,页面还提到效用函数 U(n) 的更新规则:如果是 MAX 节点胜利,MAX 节点胜率增加,MIN 节点不变;如果是 MAX 节点失败,则 MIN 节点胜率增加,MAX 节点不变。这个算法通过平衡探索与利用,提高了搜索效率和决策质量。
第 29 / 34 页
这一页讲的是 MCTS Version 2.0 的 UCT算法。主要包括 UCT 的执行步骤:选择、扩展与模拟、回溯,以及如何选择最优动作。
这一页讲的是 MCTS Version 2.0 的 UCT (Upper Confidence Trees) 算法。UCT 是一种基于蒙特卡洛树搜索的优化方法,核心思想是通过 UCB (Upper Confidence Bound) 策略选择路径并不断更新节点信息。执行步骤包括:第一,选择 (selection),从当前搜索树中递归应用 UCB 策略,找到一个叶节点 n;第二,扩展与模拟 (expansion & simulation),如果 n 不是终止节点,则添加一个新子节点 c 并从 c 开始进行模拟;第三,回溯 (backpropagation),将 c 的胜率信息更新回根节点。右侧的树图展示了回溯过程,节点的分数表示胜率与总模拟次数的比值。最后,UCT 会选择胜率最高的子节点作为最优动作。随着模拟次数 N 增加,UCT 会逐渐收敛到类似极小极大 (minimax) 算法的行为。这种方法对探索和利用之间的平衡非常重要,例如在博弈中选择下一步动作时,可以通过 UCT 更有效地评估策略。
第 30 / 34 页
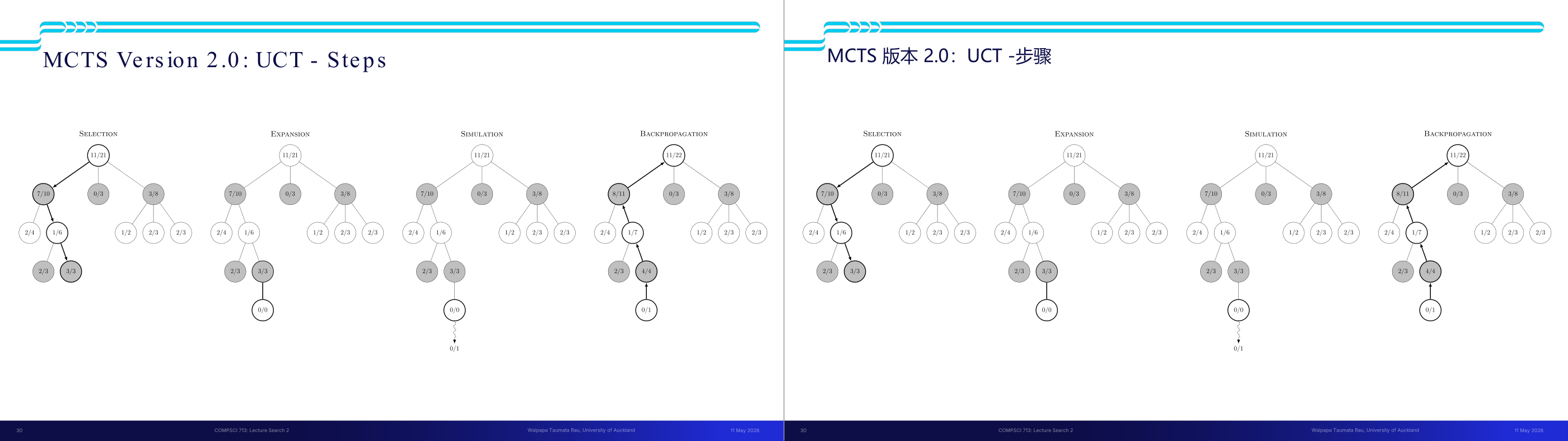
这一页讲的是蒙特卡洛树搜索(MCTS)中的UCT算法步骤,包括选择、扩展、模拟和回溯。
这一页讲的是蒙特卡洛树搜索(MCTS)中的UCT(Upper Confidence Bound for Trees)算法的四个主要步骤:选择(Selection)、扩展(Expansion)、模拟(Simulation)和回溯(Backpropagation)。首先,选择阶段通过UCT公式选择当前树中最优的节点进行探索。接着,在扩展阶段,算法会为选中的节点添加新的子节点,扩展搜索空间。然后,在模拟阶段,算法从新节点开始进行随机模拟,评估可能的结果。最后,在回溯阶段,模拟结果会向上回传到根节点,更新各节点的统计数据(如胜率)。图中展示了这四个阶段的树结构变化,例如在回溯阶段,根节点的统计数据从11/21更新为11/22,反映了模拟结果对整体树的影响。这些步骤确保了算法可以在有限时间内有效探索搜索空间,并逐步优化决策。