Week 09 - 02 - Zhongsheng___20260514___CS713___Guest_Lecture 视图:双语并排 英文 中文 倍速:1x 1.5x 2x
空格=播放/暂停当前页 · Tab=切换 简短/详细/深入 · 红色「深入」为重点页的深度讲解
这一页讲的是强化学习在大型语言模型(LLMs)中的应用,主题包括从后训练到技能开发及代理系统的构建。
这一页讲的是强化学习(Reinforcement Learning, RL)在大型语言模型(LLMs)中的应用,特别是如何通过后训练(Post-Training)提升模型的技能(Skills)以及构建更复杂的代理系统(Agentic Systems)。它是由奥克兰大学计算机科学学院的 Zhongsheng Wang 于 2026 年 5 月 14 日在 COMPSCI 713 课程中的一次客座讲座。强化学习是一种通过与环境交互来优化策略的机器学习方法,在 LLMs 中,它可以帮助模型更好地适应动态任务需求,提升模型的实用性和智能性。这一主题非常重要,因为它涉及到如何让语言模型从静态的回答工具转变为动态的智能代理系统,从而完成更复杂的任务,例如自主决策或多步骤问题解决。这一讲座可能会探讨具体的技术实现和应用场景,例如如何设计奖励机制以引导模型学习特定技能。
这一页讲的是个人简介,包括研究方向和联系方式。主要内容有:作者是博士生,研究兴趣是自演化 AI 和多智能体系统,提供了个人主页和导师实验室链接。
这一页讲的是个人简介,介绍了作者的学术背景和研究兴趣。作者是 Zhongsheng Wang,目前是博士生,由 Jiamou Liu 和 Qian Liu 指导。研究兴趣集中在 Self-Evolving AI Agent(自演化人工智能代理)和 Multi-agent System(多智能体系统),这两个领域涉及人工智能的动态适应性和多智能体之间的协作机制。此外,作者提供了个人主页链接(https://jkwzs.cn/),以及导师实验室 Liu AI Lab 的网址(https://www.liuailab.org/),方便读者了解更多相关信息。这一页内容为后续学术交流和合作奠定了基础,同时展示了作者的研究方向和联系方式。
这一页讲的是课程的主题,包括RL(强化学习)的定义、2026年LLM(大型语言模型)与智能体的趋势,以及RL在LLM后训练中的重要作用。
这一页讲的是课程的主要内容。首先,探讨了“RL”即强化学习的具体定义和概念,帮助理解其基础原理。其次,讲述了到2026年,LLM(大型语言模型)和智能体(agents)领域的发展趋势,可能涉及技术的进步、应用场景的扩展以及新的研究方向。最后,重点分析了为什么强化学习(RL)成为现代LLM后训练的关键引擎。这部分可能会解释RL如何优化模型性能,例如通过奖励机制提升生成质量或适应特定任务需求。强化学习在后训练阶段的重要性表明,它不仅能提升模型的智能化,还能使其更加贴合实际应用需求。通过这三点,课程为理解未来人工智能技术的核心发展方向奠定了基础。
这一页讲的是 AI Agent 工具和概念的熟悉程度调查。主要提到了一些工具名称,例如 Claude Code、GitHub Copilot 和 Codex。
这一页讲的是 AI Agent 工具和概念的熟悉程度调查,目的是了解听众对于这些工具的认知水平。页面列出了多个工具名称,包括 Claude Code、GitHub Copilot、Codex、Cursor、OpenClaw、Gemini CLI 和 Manus。这些工具可能涉及编程辅助、代码生成或其他 AI 驱动的开发支持功能。通过这些名称的展示,讲者可能希望引导听众思考他们对这些工具的了解程度,为后续内容的讲解铺垫。例如,GitHub Copilot 是一个基于 AI 的代码补全工具,能够帮助程序员提高生产力;Codex 则是 OpenAI 的代码生成模型,可以理解自然语言指令并生成代码。这种调查的意义在于帮助讲者调整讲解深度,同时让听众意识到这些工具在现代开发中的重要性。
这一页讲的是 OpenClaw,一个能够执行实际任务的 AI。主要功能包括清理收件箱、发送邮件、管理日历和航班值机,支持通过 WhatsApp、Telegram 等聊天应用操作。
这一页讲的是 OpenClaw,这是一种能够执行实际任务的人工智能工具。它的主要功能包括:清理收件箱、发送邮件、管理日历以及帮助用户完成航班值机等日常事务。这些操作可以通过用户熟悉的聊天应用(如 WhatsApp 和 Telegram)来完成,用户只需发送指令、授予权限,然后等待任务完成即可。这种设计极大地简化了用户与 AI 的交互流程,提升了便利性和效率。页面中的图片展示了 OpenClaw 的品牌标识和宣传语,强调它是一个“真正能做事”的 AI。它的应用场景适合需要高效管理日常事务的个人或企业用户。例如,用户可以通过 Telegram 发送一条信息来安排会议或处理邮件,从而节省时间。
这一页讲的是 FARS (Fully Automated Research System) 的运行成果。主要内容包括系统完成了 166 篇论文,耗时 417 小时,总成本 $186k。平均评分为 5.2/10,接近短期博士研究项目的质量。
这一页讲的是 FARS (Fully Automated Research System) 的运行成果和特点。FARS 是一个完全自动化的研究系统,能够在短时间内完成大量研究任务。这次运行的结果是完成了 166 篇论文,总耗时 417 小时,处理了 21.6B tokens,总成本为 $186k。平均每篇论文耗时约 2 小时,成本约 $1k。系统的评分为 5.2/10,与短期博士研究项目的质量相当,说明其生成内容具有一定学术价值。此外,FARS 是开源的,具有可复现性,适合作为前沿研究的示例。幻灯片中的图表展示了系统完成任务的关键数据,强调了其高效性和成本控制能力。这种自动化研究系统的意义在于,它可以显著提高学术研究的效率,同时降低成本,为未来的研究提供了新方向。例如,学术机构可以利用 FARS 快速生成初步研究结果,从而节省时间投入到更深入的分析中。
这一页讲的是 AI 发展的两个重要阶段:2025 年是 AI Agents 的时代,2026 年是 Agentic AI builders 的时代。
这一页讲的是人工智能发展的时间节点和趋势变化。2025 年被称为 AI Agents 的时代,这意味着这一年人工智能代理(AI Agents)在各领域得到了广泛应用,代理通常指能够自主完成特定任务的智能系统,例如自动客服、智能助手等。2026 年则被定义为 Agentic AI builders 的时代,这表明人工智能的发展进入了一个新的阶段,重点从使用代理转向构建更复杂、更自主的智能系统。这种转变可能涉及更高层次的创造性和自主性,意味着技术和工具的升级,以及开发者的角色从使用工具转向设计和建造智能框架。这种趋势反映了人工智能技术的进步和应用范围的扩展,强调了创新能力和技术构建的重要性。
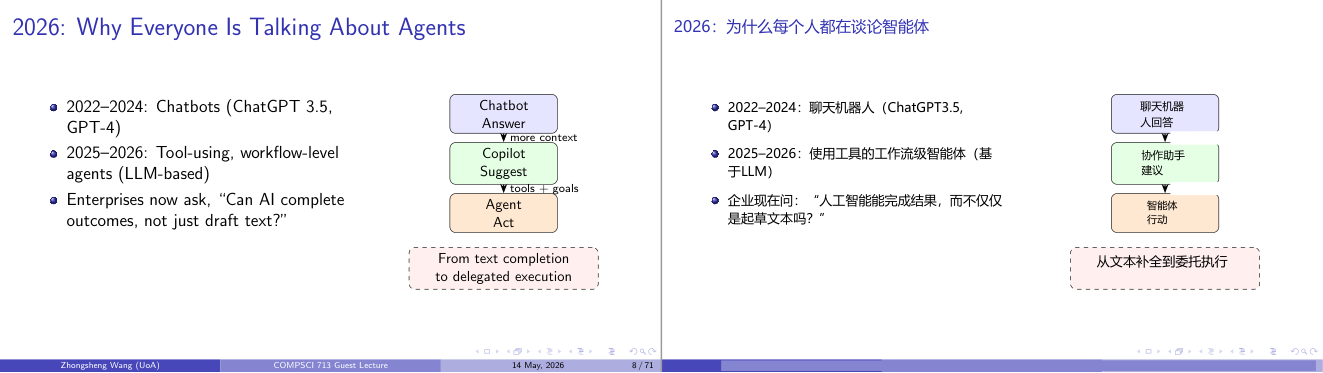
这一页讲的是 2026 年人工智能代理(Agents)的趋势。重点包括从聊天机器人到工具型代理的演进,以及企业对 AI 执行完整任务的需求。
这一页讲的是 2026 年为什么人工智能代理(Agents)成为讨论热点。首先,幻灯片提到 2022-2024 年是聊天机器人(Chatbots)的时代,例如 ChatGPT 3.5 和 GPT-4,这些模型主要用于回答问题。随后,2025-2026 年,人工智能进入工具型代理阶段,能够在工作流层面使用工具并完成复杂任务,这些代理基于大型语言模型(LLM)。企业开始关注 AI 是否可以不仅生成文本,还能完成具体的结果。右侧的图表展示了从简单的聊天机器人回答问题,到协助建议(Copilot Suggest),再到代理执行(Agent Act)的进化过程。它强调了从文本生成到任务委托执行的转变。这种变化的重要性在于,AI 不再局限于辅助,而是能够承担更复杂的操作,例如完成一个完整的工作流任务。比如,一个工具型代理可以自动安排会议、发送邮件并生成报告,而不仅仅是提供建议。
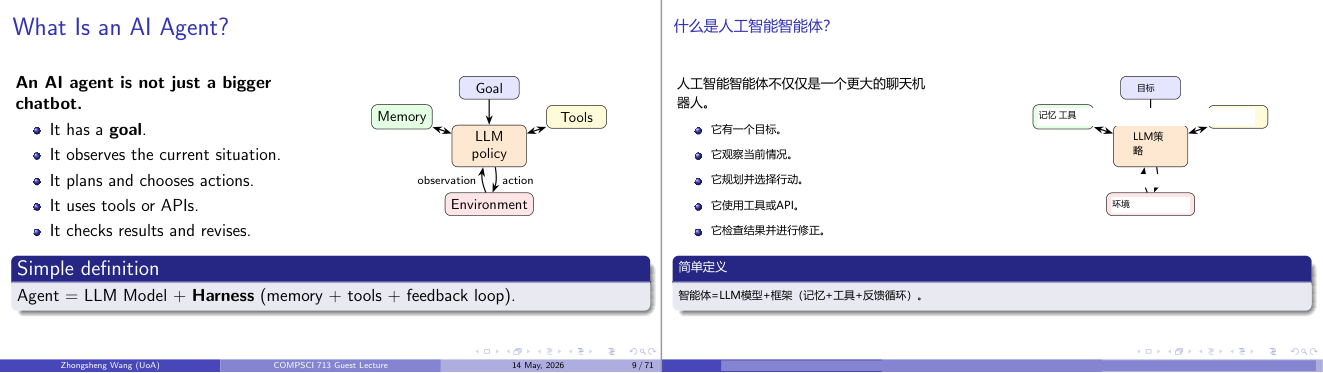
这一页讲的是 AI Agent 的定义与核心特点。它不仅仅是一个更大的聊天机器人,还具有目标、观察环境、规划行动、使用工具以及反馈修正的能力。
这一页讲的是 AI Agent 的定义和功能特点。AI Agent 不只是一个更大的聊天机器人,它有明确的目标(goal),能够观察当前环境(environment),根据观察结果规划并选择行动(action),并通过工具(tools)或 API 实现功能。此外,它还会检查结果并进行修正,这形成了一个反馈循环(feedback loop)。幻灯片中的简单定义指出:一个 Agent 是由 LLM(Large Language Model)和 Harness(包括 memory、tools 和 feedback loop)组成的系统。右侧的流程图展示了 AI Agent 的核心结构:LLM policy 是中心部分,连接了目标(goal)、记忆(memory)、工具(tools)和环境(environment),通过观察和行动来实现交互。这种设计的意义在于让 AI Agent 能够动态适应复杂环境并完成任务。例如,一个智能客服系统可以根据用户的提问实时调整回答,并调用外部数据库查询信息,从而提高服务质量。
这一页讲的是 Harness Engineering 是 AI 智能代理的核心。主要内容包括约束机制设计、反馈循环、工作流控制和持续改进。强调“人类引导,代理执行”的核心理念。
这一页讲的是 Harness Engineering(控制工程)作为 AI 智能代理的核心概念。首先,它在最近的代理讨论中被广泛提及,包括 Mitchell Hashimoto 在 2026 年的观点。关键内容包括设计和构建约束机制、反馈循环、工作流控制,以及围绕智能代理的持续改进循环。这些机制旨在优化代理的执行力,而不是限制其功能。核心哲学是“Human Steer, Agent Execute”,即人类负责引导方向,代理负责具体执行。这里的“Harness”可以类比为控制马匹的缰绳,强调通过优化控制使代理更强大和稳定,而非简单限制其能力。此外,幻灯片提到技术发展的路径从 Prompt Engineering(提示工程)到 Context Engineering(上下文工程),最终到 Harness Engineering,表明控制工程是更高级的技术演进方向。这种方法对于确保 AI 系统的高效性和可靠性至关重要,尤其在复杂任务中。
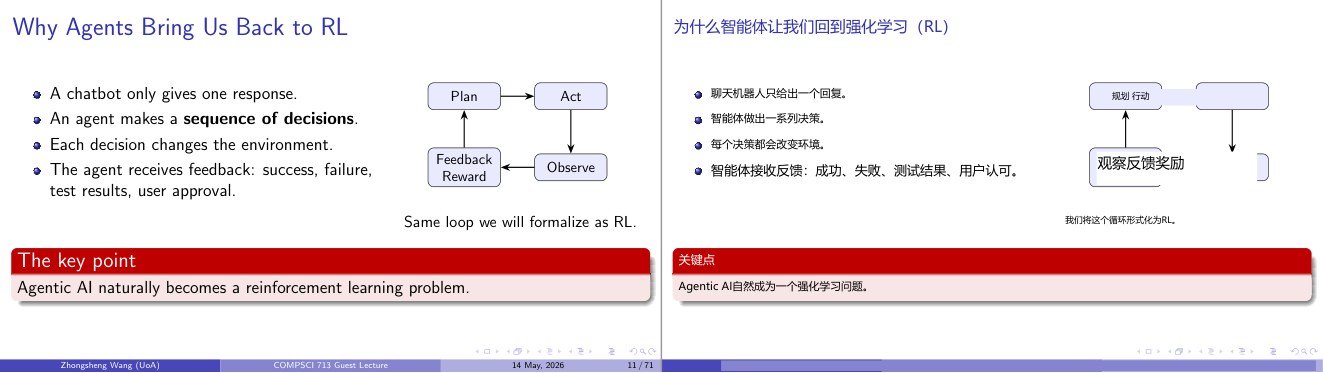
这一页讲的是为什么智能体问题与强化学习(RL)相关。关键点包括智能体的决策序列、环境变化和反馈机制。
这一页讲的是智能体(Agentic AI)问题如何自然地转化为强化学习(Reinforcement Learning, RL)问题。首先,幻灯片指出聊天机器人(chatbot)仅仅生成单一响应,而智能体需要做出一系列决策(sequence of decisions)。每个决策都会对环境产生影响,并且智能体会接收到反馈(feedback),包括成功、失败、测试结果和用户认可等。右侧的流程图展示了这一循环:智能体通过计划(Plan)和行动(Act)影响环境,然后观察(Observe)环境变化,并基于反馈奖励(Feedback Reward)调整策略。这种循环正是强化学习的核心机制。强化学习的重要性在于它能够帮助智能体在动态环境中优化决策,例如通过不断试验和调整来提高用户满意度或任务完成率。一个简单的例子是自动驾驶汽车,它通过观察道路状况(Observe)、规划路径(Plan)、执行驾驶动作(Act),并根据驾驶安全性和效率的反馈(Feedback Reward)优化驾驶策略。
这一页讲的是 AI Agent 的「Harness Engineering」概念——也就是围绕智能体构建约束机制、反馈回路和持续改进循环的工程方法。这是 2026 年 AI 领域的新范式,从 Prompt Engineering(提示词工程)到 Context Engineering(上下文工程),再到现在的 Harness Engineering(驾驭工程)。核心哲学是「Human Steer, Agent Execute」:人负责方向,智能体负责执行。Harness 的字面意思是驾驭马匹的缰绳,这里的比喻非常到位——不是限制 Agent,而是让它跑得更快更稳。具体来说,Harness 包括:工作流控制(控制 Agent 的执行顺序和条件分支)、反馈回路(Agent 执行完一步后得到观察,然后决定下一步)、约束机制(防止 Agent 乱操作)和持续改进循环(从失败中学习)。考试关联:这个概念与强化学习(RL)紧密相连——后续页面会说明,Agentic AI 天然地变成一个 RL 问题,因为 Agent 做序列决策、从环境反馈中学习,这与 RL 的 Plan-Act-Observe-Reward 循环完全吻合。易错点:很多人以为 AI Agent 只是「更大的 ChatGPT」,实际上 Agent = LLM + Harness(记忆 + 工具 + 反馈循环),缺少 Harness 的 LLM 只是一个问答机,无法真正完成多步任务。
这一页讲的是强化学习(RL)在决策中的基本组成部分,包括Agent、Environment、State、Action和Reward。
这一页讲的是强化学习(RL)在决策中的核心概念及其定义。首先,Agent是学习者或决策者,它负责在环境中执行动作并学习最佳策略。Environment是Agent所交互的外部世界,包含所有影响Agent决策的因素。State表示当前环境的状态,是环境的一个具体表示,用于帮助Agent理解当前情况。Action是Agent可以采取的一个具体决策,通常是针对当前状态的反应。Reward是一个标量信号,用来评估某个动作的质量,指导Agent调整策略。强化学习的目标是通过不断试验和反馈,找到能够最大化累积奖励的策略。例如,一个自动驾驶汽车的Agent可以根据道路状况(State)决定转向或加速(Action),通过驾驶安全性或效率的反馈(Reward)来优化驾驶策略。这些概念构成了强化学习的基础框架,帮助我们理解如何在复杂环境中做出智能决策。
这一页讲的是「为什么 Agentic AI 天然变成强化学习问题」。核心逻辑是:聊天机器人只给一个回答,而 Agent 要做一系列决策,每个决策都改变了环境,然后 Agent 收到反馈——成功、失败、测试结果、用户审批。这个 Plan-Act-Observe-Feedback-Reward 的循环,正是 RL 的标准框架。直觉上可以这么理解:下象棋的程序每步棋都是一个 action,棋局的结果是 reward,整个对弈过程是一个 trajectory。Agent 完成任务也是如此:搜索一个文件、修改代码、运行测试、看到报错、再修改——这就是一条轨迹,最终有没有通过所有测试就是 reward。考试关联:RL 的关键概念在 Agent 场景下的对应关系非常可能被考到——State 对应「当前的情境观察」,Action 对应「Agent 的操作」,Policy 对应「LLM 本身」,Reward 对应「任务完成情况」。易错点:考生容易以为 RL 只用于游戏(像 AlphaGo),但这页明确说明 RL 框架同样适用于 LLM 的训练和 Agent 的行为优化,这是 2025-2026 年 AI 领域最重要的进展之一。
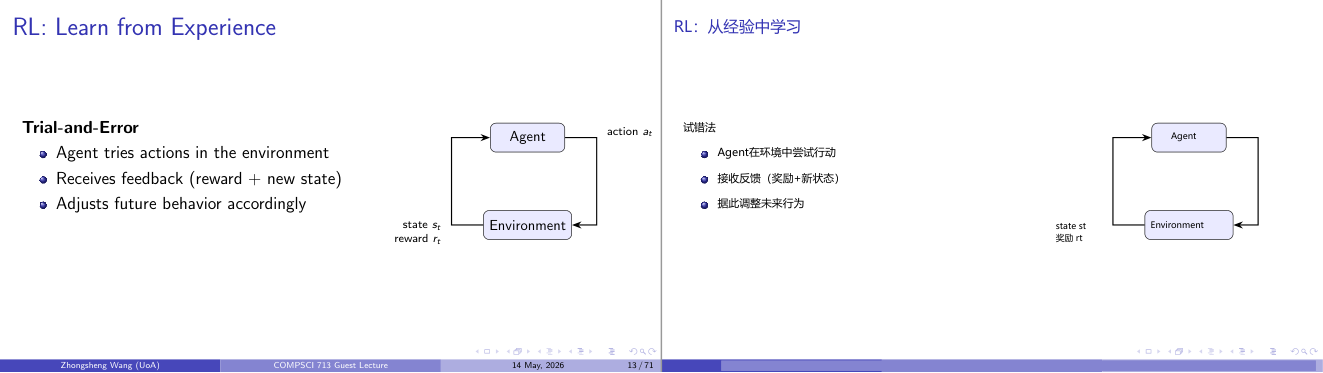
这一页讲的是强化学习 (RL) 的核心思想,通过试错 (Trial-and-Error) 学习经验。主要包括智能体尝试动作、接收反馈并调整行为。
这一页讲的是强化学习 (Reinforcement Learning, RL) 的核心思想,即通过试错 (Trial-and-Error) 的方式从经验中学习。智能体 (Agent) 在环境 (Environment) 中尝试动作 (action at),环境会根据智能体的动作返回反馈,包括奖励 (reward rt) 和新的状态 (state st)。智能体根据这些反馈调整未来的行为,逐步优化决策。右侧的流程图展示了这一过程:智能体执行动作,环境反馈奖励和状态,形成一个循环。这个机制的关键在于通过不断试探和调整,智能体能够找到优化策略以最大化长期奖励。例如,在游戏中,智能体通过尝试不同的操作来获得更高分数。这种学习方式在机器人控制、游戏策略优化等领域非常重要,因为它能够适应复杂动态环境。
这一页讲的是强化学习(RL)在日常生活中的应用。通过训练狗和学骑自行车的例子,说明学习是通过反馈(feedback)而非明确指令(explicit instructions)完成的。
这一页讲的是强化学习(Reinforcement Learning, RL)如何在日常生活中体现。左侧的例子是训练狗:当你说“坐下”时,狗坐下会得到奖励(treat);如果狗做错动作,比如翻滚,就不会得到奖励。狗并不是通过明确指令学习如何坐下,而是通过反复尝试和错误(trial and error)来发现什么行为会带来奖励。右侧的例子是学骑自行车:你尝试保持平衡可能会摔倒;通过调整动作,比如摆动车把,可以骑得更远;随着摔倒次数减少,最终可以平稳骑行。这种学习过程并不是通过别人告诉你如何保持平衡,而是通过自己动手实践(learning by doing)完成的。幻灯片底部总结了两种情况的共同点:学习是通过对结果的反馈(feedback on outcomes)来完成,而不是依赖明确的指令(explicit instructions)。这说明强化学习的核心是基于行为结果的调整,而非直接教导。
这一页讲的是强化学习(RL)中的捉迷藏游戏示例。主要包括两组角色:Seekers和Hiders,以及他们的奖励机制。
这一页讲的是强化学习(RL)中的捉迷藏游戏示例,展示了智能体如何通过交互学习策略。图中显示了两个团队:红色的Seekers和蓝色的Hiders。Seekers的目标是找到并看到Hiders,他们在成功看到蓝色角色时会获得奖励。而Hiders的目标是躲藏并避免被红色角色发现,当所有Hiders都未被Seekers看到时,他们会获得奖励。同时,失败的一方会收到负奖励,这种机制鼓励双方优化策略。这个游戏的设计展示了多智能体环境中竞争与合作的动态,帮助研究者理解智能体如何在复杂环境中学习和适应。例如,Hiders可能学习如何利用障碍物躲藏,而Seekers可能学习如何绕过障碍物寻找目标。这种实验为研究人工智能的策略生成和工具使用提供了重要的参考。
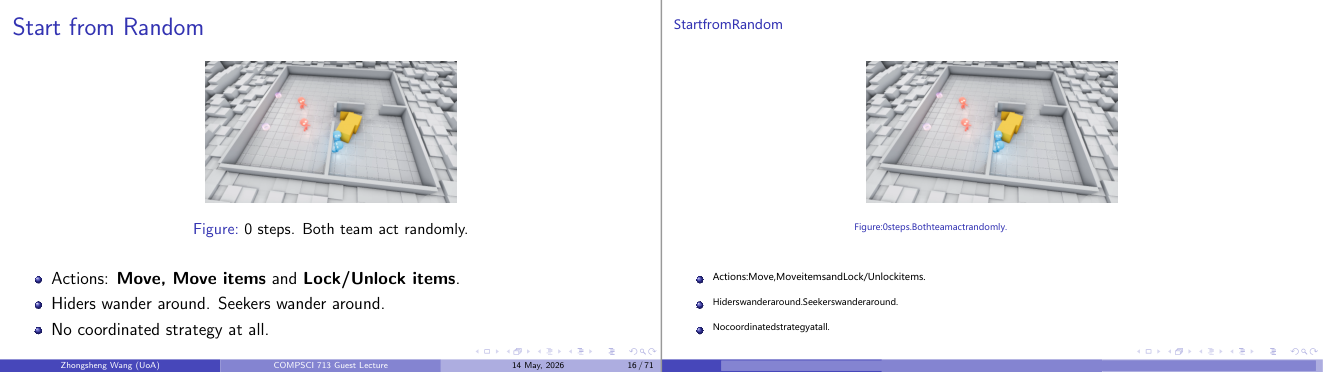
这一页讲的是随机初始状态下的团队行为。主要内容包括双方随机行动、可执行的动作以及缺乏协调策略。
这一页讲的是在随机初始状态下,团队的行为特点。图中展示了一个场景,双方团队在 0 步时随机行动,没有任何策略。可执行的动作包括移动 (Move)、移动物品 (Move items) 和锁定/解锁物品 (Lock/Unlock items)。在这种状态下,Hiders(躲藏者)和 Seekers(寻找者)都只是随机游荡,没有明确的目标或合作策略。这种随机性反映了系统在完全没有引导或训练时的初始表现。通过观察这一阶段,可以为后续引入策略或学习机制提供基准。例如,随着训练的深入,团队可能逐渐形成合作行为,提升效率。这一页的内容强调了从随机开始的重要性,为后续的策略演化提供了对比基础。
这一页讲的是一个“捉迷藏”游戏,展示了人工智能在模拟环境中进行交互的过程。关键点包括游戏规则和2.69百万步的训练。
这一页讲的是一个人工智能在模拟环境中进行“捉迷藏”游戏的场景。图中展示了一个封闭区域,红色的角色是“寻找者”(Seekers),蓝色的角色是“隐藏者”(Hiders)。游戏的规则是寻找者追逐隐藏者,隐藏者需要利用环境中的障碍物来躲避。幻灯片提到这一过程经过了2.69百万步的训练,说明了人工智能在复杂环境中学习策略的能力。图中可以看到隐藏者将障碍物移动到特定位置形成屏障,展示了它们在游戏中学习到的策略。这种模拟环境有助于研究人工智能的行为学习和决策过程,尤其是在多智能体交互场景中的应用。一个例子是,隐藏者通过合作来最大化躲避的效果,而寻找者则需要学习如何突破屏障。这种研究对机器人协作和自动化系统的开发具有重要意义。
这一页讲的是 Hider 构建安全房间的策略。主要包括避免负奖励、使用物品建造安全房间以及锁住箱子。
这一页讲的是 Hider(躲藏者)如何通过构建安全房间来实现策略目标。图中展示了一个场景,Hider 利用箱子建造了一个封闭区域,避免被发现。关键点包括:1. Hider 需要避免负奖励,因此他们学习如何使用场景中的物品;2. 他们通过移动和组合箱子建造一个安全房间;3. 完成后,Hider 会锁住箱子以确保安全房间的稳定性。这种策略通过 8.62 百万步的训练逐渐形成,体现了强化学习中代理如何通过试错和奖励机制优化行为。这个过程展示了智能体如何在复杂环境中学习并应用工具,具有重要的研究意义,尤其是在多智能体协作和竞争场景中的应用。
这一页讲的是 Seeker 使用 ramp 学习突破安全房间的过程。主要强调学习行为和道具使用。
这一页讲的是 Seeker(寻求者)通过 ramp(斜坡)学习如何突破安全房间的过程。图中显示了一个模拟环境,经过 14.5 million steps(1450 万步)的训练,寻求者学会了利用斜坡进入原本无法到达的安全房间。这说明 AI 或强化学习模型可以通过不断尝试和反馈,逐步掌握复杂的策略。幻灯片还提到,寻求者在学习突破后,会进一步学习如何使用环境中的其他道具。这反映了强化学习中的一个重要特点:通过试错和环境交互,模型可以逐渐优化行为策略以完成目标任务。一个例子是,如果安全房间的入口被封锁,寻求者可能会主动寻找并使用斜坡作为工具来达到目的。这种能力对于解决复杂问题和提升 AI 的适应性非常重要。
这一页讲的是躲藏者(hiders)如何通过策略隐藏斜坡(ramp),并最终学会“解除”寻找者(seekers)。
这一页讲的是躲藏者(hiders)在竞争中逐步发展策略,通过隐藏斜坡(ramp)来阻止寻找者(seekers)进入安全区域(safe room)。图中展示了一个模拟场景,经过 43.4 百万步的训练,躲藏者成功将斜坡放置在安全房间内,使寻找者无法利用它进入。随着竞争的推进,躲藏者不仅学会了隐藏道具,还逐渐掌握了“解除”寻找者的能力,这意味着他们能够有效地阻止寻找者完成目标。这种行为体现了智能体在多轮竞争中通过试错和学习优化策略的能力。这个过程展示了强化学习中的对抗性训练如何促使智能体发展复杂的行为策略,从而提高其适应性和任务完成效率。
这一页讲的是强化学习(RL)的关键洞察和定义。主要内容包括复杂行为的自发性、试错过程的重要性,以及奖励信号的指导作用。
这一页讲的是强化学习(Reinforcement Learning, RL)的关键洞察和定义。首先,通过“躲猫猫”游戏的案例,说明复杂的智能行为可以从简单的奖励信号中自发产生。这些行为并非通过明确编程实现,例如“建造庇护所”或“使用斜坡”,而是智能体通过试错(trial and error)过程自主发现的策略。这体现了RL的核心理念,即智能体通过不断尝试和调整行为来优化奖励,而不是模仿正确答案。其次,页面下方明确定义了RL:它是一种通过试错过程学习决策的方式,由奖励信号(reward signals)引导,而非直接模仿已有的正确答案。这种学习方式强调探索和反馈的重要性。例如,在游戏中,智能体可能尝试多种行动方案,最终找到能够最大化奖励的策略。这种机制对开发自主智能系统具有重要意义,尤其是在无法明确预编程复杂行为的情况下。
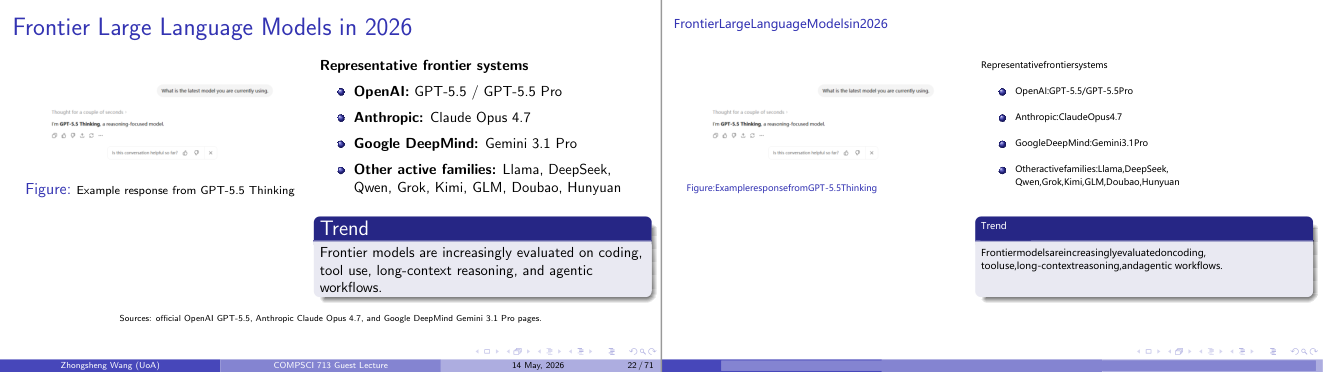
这一页讲的是2026年的前沿大型语言模型,包括代表性系统和趋势。主要提到OpenAI、Anthropic和Google DeepMind的模型,以及其他活跃模型家族。趋势是模型在编码、工具使用和长上下文推理等方面的评估越来越重要。
这一页讲的是2026年的前沿大型语言模型(Frontier Large Language Models)。首先列出了几个代表性系统,包括OpenAI的GPT-5.5和GPT-5.5 Pro,Anthropic的Claude Opus 4.7,以及Google DeepMind的Gemini 3.1 Pro。此外,还提到了其他活跃模型家族,如Llama、DeepSeek、Qwen、Grok、Kimi、GLM、Doubao和Hunyuan。页面中的图例展示了GPT-5.5 Thinking的一个示例响应,说明其专注于推理的特点。最后,趋势部分强调了这些前沿模型在编码(coding)、工具使用(tool use)、长上下文推理(long-context reasoning)和代理工作流(agentic workflows)方面的评估越来越重要。这表明未来的语言模型不仅需要处理复杂任务,还要具备更强的推理能力和适应能力。例如,GPT-5.5 Thinking能够快速理解问题并提供基于推理的回答,这种能力在实际应用中非常关键。
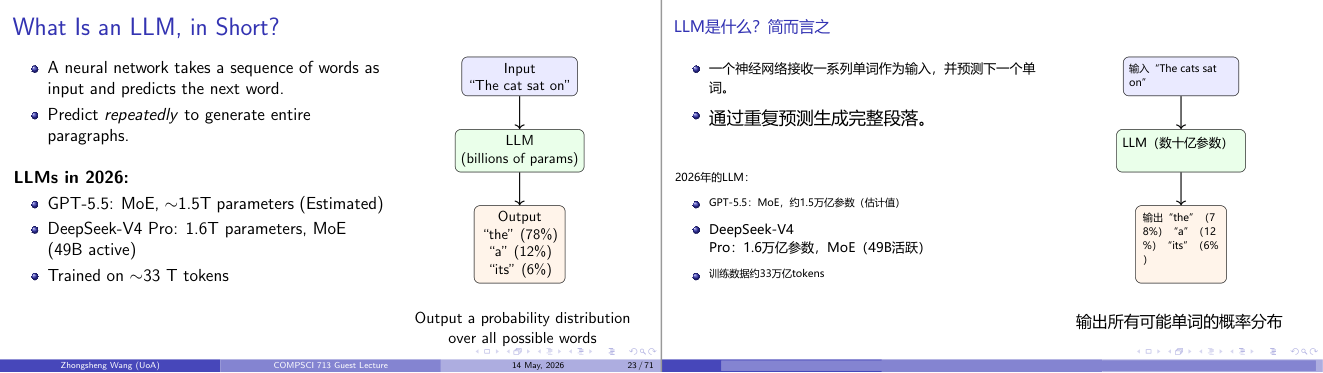
这一页讲的是LLM(大型语言模型)的基本工作原理及未来发展。主要内容包括它如何通过神经网络预测下一个词语、生成完整段落,以及2026年LLM的参数规模和训练数据量。
这一页讲的是LLM(大型语言模型)的基本工作原理及其未来发展趋势。LLM是一种神经网络,它通过接收一系列词语作为输入,预测下一个词语的概率分布。例如,输入句子“The cat sat on”,模型会输出多个可能的下一个词及其概率分布,如“the”(78%)、“a”(12%)和“its”(6%)。通过重复预测,LLM可以生成完整的段落。页面右侧的流程图形象地展示了这一过程:输入经过模型处理后,输出一个概率分布。接着讲述了2026年LLM的规模,例如GPT-5.5预计拥有约1.5万亿参数,DeepSeek-V4 Pro则达到1.6万亿参数,且采用MoE(Mixture of Experts)架构,激活了49亿参数。这些模型通常基于约33万亿个token进行训练,显示了其数据需求和计算复杂度的巨大规模。这些技术的发展将进一步提升语言生成的精度和复杂性,推动自然语言处理领域的进步。
这一页讲的是 Token 的定义及其在 LLMs 中的作用。主要内容包括 Token 的估算规则,如字符和单词的关系,以及大规模数据的 Token 数量。
这一页讲的是 Token(标记)作为 LLMs 处理文本的基本单位。Token 是语言模型分解文本的一种方式,通常比单词更小。页面提供了关于英语 Token 的一些经验规则:例如,一个 Token 大约对应 4 个字符,约等于 3/4 个单词;1-2 个句子通常包含约 30 个 Token。此外,页面提到 LLMs 处理的规模,例如 33 万亿(33T)个 Token 大约等于 25 万亿(25T)个单词,相当于约 3 亿本书的文本量。这些规则帮助我们理解 LLMs 如何处理和表示语言数据,以及其庞大的训练数据规模。这种 Token 化机制对于模型的高效处理和存储至关重要,比如在生成文本时,模型需要逐步预测每个 Token 的概率。
这一页讲的是Transformer架构及其核心创新点。主要包括自注意力(Self-Attention)机制和堆叠层(Stacked Layers)的设计,帮助模型理解上下文和抽象信息。
这一页讲的是Transformer架构,它是现代大规模语言模型(LLMs)的基础。Transformer的核心创新包括两个部分:第一,自注意力(Self-Attention)机制,使每个单词能够关注句子中的其他所有单词,从而理解上下文关系。例如在句子“The cat sat on the mat because it was soft”中,自注意力机制能够将“it”与“mat”关联起来,而不是与“cat”,因为它通过比较所有位置来理解语义关系。第二,堆叠层(Stacked Layers)设计,通过重复多个层次来逐步构建更抽象的理解。这种设计使模型能够捕捉复杂的语言结构和语义信息。这两个创新点使Transformer成为深度学习领域的一个里程碑,为自然语言处理任务提供了强大的能力。
这一页讲的是生成过程的序列性及其对强化学习的意义。主要强调生成答案是多个小决策的序列,且不同序列会导致不同结果。
这一页讲的是生成过程的序列性(Generation Is Sequential),并探讨其对后续强化学习(Reinforcement Learning, RL)的重要意义。首先,生成一个答案不是单一的决策,而是由多个小决策组成的序列,包括选择词语、推理步骤和工具调用。这表明语言生成是一个动态的过程,不同的决策序列会产生不同的结果。接着,幻灯片强调为什么这一点在后续阶段很重要:它为将大型语言模型(LLM)的后训练与强化学习连接提供了基础,而不需要将语言模型简单地视为游戏代理(game-playing agents)。这一观点的核心在于,语言模型的行为可以通过序列化的方式优化,从而更好地适应复杂任务。例如,在回答一个复杂问题时,模型可以通过调整推理步骤的顺序来提高答案的质量。这种序列性为语言模型的优化提供了新的视角和方法。
这一页讲的是预训练(Pre-training)的基本概念及其目标。主要内容包括定义 LLM 为预测下一个词(next-token predictor),通过大规模文本数据进行训练,以及预训练的核心目标是预测下一个词。
这一页讲的是预训练(Pre-training),它是大型语言模型(LLM)学习语言的关键步骤。首先,LLM 被定义为一个预测下一个词(next-token predictor)的模型,问题是如何构建这样的预测器。解决方法是通过预训练,使用来自网络、书籍和代码的大规模文本数据对模型进行训练。预训练的目标非常简单:预测下一个词。关键点强调,预训练并不是直接教模型去完成某些具体任务,而是教会模型理解和生成语言。这种方法的重要性在于,它为模型提供了语言的基本能力,使得模型可以在后续的微调阶段更好地完成具体任务。例如,通过预训练,模型可以学会如何在上下文中生成合理的词语,从而在聊天或问答任务中表现出色。
这一页讲的是「生成过程是序列决策」这一桥梁思想,把 LLM 文本生成和强化学习框架连接起来。一个生成的答案不是一次决策,而是一系列小决策的累积:每个词、每个推理步骤、每次工具调用都是一个 action。某些序列会产生更好的结果,某些会更差。这个想法非常重要,因为它让我们不用强行把语言模型说成「游戏智能体」,就能自然地把 LLM 的后训练(post-training)纳入 RL 框架。直觉举例:如果模型在解数学题时输出的推理链是「设 x 为原价,0.8x=20,所以 x=25」,这条推理链里每一个 token 都是一个 action,最终答案对不对就是 reward。RL 的目标就是让产生正确推理链的那些 action 序列概率增大。考试关联:这一页是理解「LLM 后训练为什么能用 RL」的关键前提,后面讲的 RLHF、RLVR、GRPO 都基于这个思想。易错点:容易误以为每个 token 都单独拿 reward,实际上 reward 通常在序列末尾给出(sparse reward),这就导致了信用分配(credit assignment)问题,是本讲后半段的核心难点之一。
这一页讲的是预训练模型的能力与局限性。它学习了语法、世界知识和文本模式,但不保证遵循指令或可靠推理。
这一页讲的是预训练模型的能力与局限性。左侧列出了它学习的内容,包括语法和句法(Grammar and syntax)、世界知识(World knowledge)、文本模式(Text patterns)、类似推理的行为(Reasoning-like behaviors)以及编码和翻译模式(Coding and translation patterns)。这些能力让模型能够完成复杂的语言生成任务。右侧则强调了预训练模型的不足之处,它无法确保遵循用户指令(Following user instructions)、提供有帮助或安全的回答(Being helpful or safe)、知道何时拒绝(Knowing when to refuse)、优化任务成功率(Optimizing for task success)或生成可靠的推理(Producing reliable reasoning)。底部总结了一个关键观点:预训练模型本质上是一个补全引擎(completion engine),而不是一个真正的智能助手(assistant)。例如,模型可以生成语言,但可能无法理解用户的真实意图或提供准确的建议。
这一页讲的是监督微调(SFT)的作用及其局限性。SFT通过模仿教学,让预训练模型从简单的文本续写转变为能够生成“好”响应的助手。
这一页讲的是监督微调(Supervised Fine-Tuning, SFT),它是一种通过模仿教学的方法,将预训练模型训练成能够生成高质量响应的助手。首先,预训练模型虽然可以完成文本续写任务,但可能无法正确回答用户的请求。而通过SFT,模型能够学习如何从指令生成“好”的响应。SFT的具体步骤包括收集高质量的指令-响应示例,训练模型模仿目标响应风格,并将原本的文本补全引擎转变为遵循指令的模型。这种方法的核心在于通过示例引导模型学习。然而,SFT的局限性在于它只能模仿示例中展示的行为,无法超越示例范围。例如,如果示例中没有包含特定任务的解决方案,模型也无法生成相关响应。因此,SFT适用于需要明确指令遵循的场景,但在创造性或未知任务中可能受限。
这一页讲的是SFT的一个例子,展示如何应用到情感分类任务中。主要强调SFT不仅限于指令跟随,还能用于特定的监督学习任务。
这一页讲的是SFT(Supervised Fine-Tuning)的一个例子,用情感分类任务来说明它的应用。SFT不仅局限于指令跟随(instruction-following),还可以训练模型完成特定的监督学习任务。幻灯片展示了三个情感分类的例子:输入文本分别表达了积极、消极和中性的情感,模型需要根据输入的语句内容输出对应的情感标签,例如“positive”(积极)、“negative”(消极)或“neutral”(中性)。这些例子表明,通过SFT,模型可以学习将输入映射到目标输出。这个过程对于构建能够理解和处理自然语言的模型非常重要,因为它使得模型能够根据具体任务需求进行定制化训练。例如,电商平台可以使用这样的情感分类模型来分析用户评论,从而改进产品或服务。
这一页讲的是指令微调(Instruction Tuning)的一个特殊示例,展示了如何通过对话格式的训练数据调整模型行为。
这一页讲的是指令微调(Instruction Tuning),通过设计对话格式的训练数据来调整模型的行为。页面中的示例展示了一个训练数据,其中包含用户提出问题(如“向初学者解释强化学习”)和助手的回答(如“强化学习是一种让智能体...”)。这种数据不仅仅是语言的训练,还包含预期的助手行为(assistant behavior)。通过指令微调,模型能更直接地回答用户问题,而不是仅仅继续文本生成。这种方法的核心是教会模型如何响应用户,而不是简单地延续上下文。举例来说,经过指令微调后,模型可以更准确地理解用户需求并给出针对性的回答,例如在技术问题中提供具体的解决方案。这种技术对于提升交互式人工智能系统的实用性和用户体验非常重要。
这一页讲的是为什么表面看似合理的推理可能不够准确,通过一个折扣计算的例子对比 RL 前后的推理方式。
这一页讲的是为什么表面看似合理的推理可能不够准确,并通过一个具体例子说明强化学习(Reinforcement Learning, RL)优化后的推理更接近正确答案。例子中问题是:一件衬衫打了 20% 的折扣后售价为 $20,原价是多少?在 RL 前的推理中,认为原价是 $24,因为 $20 加上 20% 的折扣等于 $24。但这种推理忽略了折扣是基于原价计算的。在 RL 后的推理中,设原价为 x,打 20% 折扣后价格为 0.8x,等于 $20,因此解得 x = $25。这个例子说明 RL 的优化能够纠正推理中的逻辑错误,使结果更准确。幻灯片还提到 SFT(监督微调)可以让推理看起来合理,但反馈优化(Feedback Optimization)更能推动推理的正确性。这强调了优化过程在提高模型推理能力中的重要性。
这一页讲的是从模仿到反馈的关键转变。重点包括预训练提供语言能力,SFT赋予助手行为,下一步是通过反馈改进模型。
这一页讲的是从模仿(Imitation)到反馈(Feedback)的关键转变。首先,预训练(pre-training)赋予模型语言能力,而SFT(Supervised Fine-Tuning)使模型表现出助手行为。当前的重点是通过对结果的反馈(feedback about outcomes)来进一步改进模型性能。在模仿视角(Imitation view)中,模型通过学习示例并匹配演示行为来回答问题,核心问题是“一个好的答案应该是什么样的?”而在反馈视角(Feedback view)中,模型通过尝试不同行为并对结果进行评分来优化,核心问题变为“哪种行为真正成功了?”这两种方法的转变反映了现代后训练(post-training)的核心目标,即使反馈机制更具可扩展性(scalable)。例如,模仿视角可能适用于标准化任务,而反馈视角更适合复杂或动态环境中的决策优化。
这一页讲的是模型训练方法的转变,比较了SFT训练和结果优化的不同。SFT通过模仿人类答案学习,结果优化则依赖反馈和评分来调整模型行为。
这一页讲的是模型训练方法如何从SFT训练(Supervised Fine-Tuning)转向结果优化(Outcome Optimization)。SFT训练的流程是:人类提供一个优质答案,模型学习模仿这个答案,训练信号是目标文本(target text)。这种方法的核心是通过示范答案(demonstrated answer)来指导模型。相比之下,结果优化的流程是:模型生成多个尝试答案(attempts),然后通过奖励或验证器(reward/verifier)对这些答案进行评分,模型根据评分结果调整行为,提高生成更优答案的概率。结果优化的关键是通过尝试和反馈(attempts → scores)来优化模型,而不是直接模仿人类答案。底部红色框强调了这一转变的意义:不再要求人类提供完美行为,而是让模型尝试不同行为,并通过反馈引导其向有效行为靠拢。这种方法更灵活,能够更好地适应复杂任务场景。
这一页讲的是「从模仿学习到反馈优化」的关键转变——这是现代大模型后训练的核心哲学。Pre-training 给了模型语言能力,SFT(监督微调)给了模型助手行为,但 SFT 只能模仿人类示范的答案,无法超越人类示范的上限。而基于反馈的优化则不同:模型自己采样多个尝试,用奖励信号或验证器打分,然后让成功的行为模式概率增加。两种范式对比:模仿视角问「一个好答案长什么样?」,反馈视角问「哪种行为实际上成功了?」。这个转变的意义在于:RL 可以让模型发现人类示范者没有展示过的、甚至人类想不到的更优解法。DeepSeek-R1 的成功正是来自于让模型通过 RL 自主发展出更长、更深的推理链,而不是靠人工写好推理过程再 SFT。考试关联:SFT vs RL 的对比是本讲最核心的考点之一,要能回答「什么时候用 RL 比 SFT 更好?」——答案是当我们能够评判输出好坏(判断比示范容易)时,RL 的优势就出现了。易错点:SFT 有时也被误称为「RL 的一种」,实际上 SFT 是监督学习,没有采样和奖励机制。
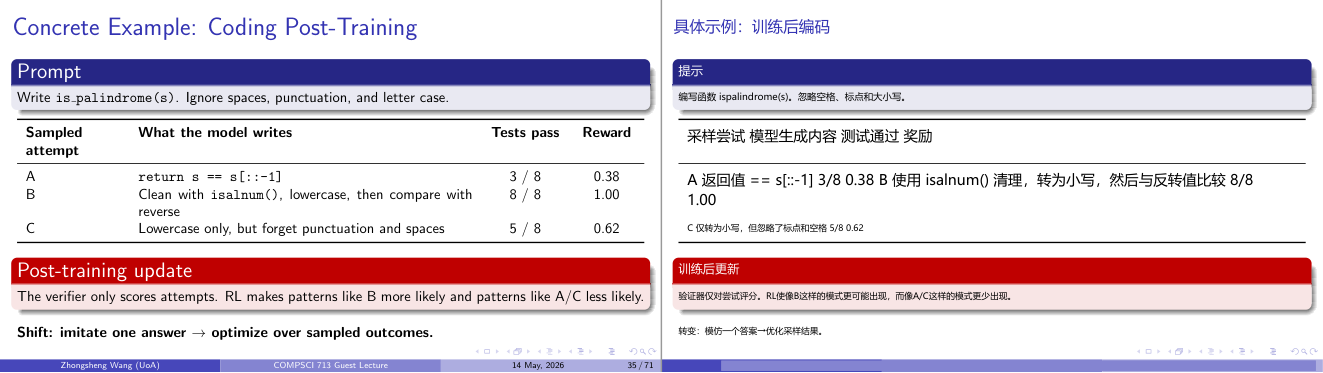
这一页讲的是模型后训练优化的具体例子,展示如何通过强化学习优化代码生成结果。
这一页讲的是模型后训练优化的具体例子,特别是通过强化学习(Reinforcement Learning, RL)提高代码生成质量。首先,Prompt要求编写一个函数is_palindrome(s),忽略空格、标点和大小写。表格展示了模型生成的三种尝试:A直接比较字符串反转,测试通过率为3/8,奖励为0.38;B使用isalnum()清理字符串并转为小写后再比较反转,测试通过率为8/8,奖励最高为1.00;C仅转为小写但忽略标点,测试通过率为5/8,奖励为0.62。通过后训练更新,验证器仅对尝试进行评分,强化学习使得像B这样的高质量模式更可能出现,而降低像A和C的低质量模式出现的概率。最后强调了从模仿单一答案转变为优化多个采样结果的重要性。这种方法能够提升模型生成的代码质量,并更好地满足实际需求。
这一页讲的是强化学习(RL)的优势:适用于尝试多种解决方案并容易判断效果的任务。
这一页讲的是强化学习(Reinforcement Learning, RL)的适用场景及优势。首先,强调一个经验法则(Rule of thumb):当模型可以尝试多种解决方案且我们能以较低成本判断哪些方案有效时,就适合使用RL。幻灯片将任务分为两类:一类是“难以完美展示”(Hard to demonstrate perfectly),如定理的理想证明、新问题的最佳代码、复杂的多步骤工具使用计划,以及既有帮助又安全的响应;另一类是“尝试后更容易判断”(Easier to judge after trying),如最终答案是否正确、单元测试是否通过、任务是否完成,以及响应是否违反安全规则。通过对比可以看出,RL特别适合后者,因为它可以通过试错找到最佳方案。这也解释了为什么数学、编程、工具使用和代理任务是RL的自然应用领域。举例来说,在编程中,RL可以通过尝试不同代码路径找到最优解决方案,同时通过测试来验证其有效性。
这一页讲的是将 LLM 的生成过程视为一个轨迹(trajectory)。比较了强化学习(RL)与 LLM 的关键概念,并提出了一个桥接观点。
这一页讲的是将大语言模型(LLM)的生成过程类比为强化学习(RL)中的轨迹(trajectory)。表格比较了 RL 与 LLM 的关键概念:状态(State s)在 RL 中是棋盘位置或机器人传感器状态,而在 LLM 中是提示(prompt)加生成的前缀和工具观察;动作(Action a)在 RL 中是移动、转向、拾取物体等,而在 LLM 中是生成下一个词、推理步骤或调用工具;策略(Policy π)在 RL 中是控制器选择动作,而在 LLM 中是模型本身的决策;轨迹(Trajectory)在 RL 中是一个游戏回合,而在 LLM 中是完整回答或多步代理会话;奖励(Reward r)在 RL 中是分数、胜负或任务成功,而在 LLM 中是用户偏好、验证器结果或环境反馈。最后提出一个桥接观点:如果将生成过程视为轨迹,那么通过反馈对 LLM 进行后训练就转化为一个策略优化(policy optimization)问题。这种视角有助于将 RL 方法应用于 LLM 的优化过程,例如通过奖励信号提高模型性能。
这一页讲的是为什么 LLM 的强化学习不同于传统强化学习。主要对比两者环境、奖励机制、动作空间、状态定义和探索成本的差异,并举了代码生成的例子。
这一页讲的是为什么 LLM(大型语言模型)的强化学习不符合传统强化学习(Classical RL)的框架。传统强化学习中,环境是明确的,奖励可能每一步都出现,动作空间通常较小,状态定义清晰,探索通常在模拟器中进行。而在 LLM 的强化学习中,环境可能是文本、工具、人类或代码,奖励通常只在任务结束时出现,动作空间非常大,包括词汇和工具,状态包含长上下文,探索成本高。幻灯片还举了一个代码生成的例子:模型会生成许多代码片段,但只有在测试运行后才能获得反馈,说明动作空间巨大且奖励延迟。这些差异表明,传统强化学习的理论框架难以直接应用于 LLM 的训练,需要新的方法来解决这些挑战。
这一页讲的是「LLM 生成作为轨迹(Trajectory)」的正式对应关系,是将 RL 概念映射到 LLM 场景的关键对照表。State(状态)在经典 RL 里是棋盘位置或机器人传感器读数,在 LLM 里是「prompt 加上已生成的前缀加上工具观察结果」;Action(动作)在经典 RL 里是移动或跳跃,在 LLM 里是下一个 token、推理步骤或工具调用;Policy(策略)在经典 RL 里是控制器,在 LLM 里就是 LLM 本身;Trajectory(轨迹)在经典 RL 里是一局游戏,在 LLM 里是完整的回答或多步 Agent 会话;Reward(奖励)在经典 RL 里是得分或胜负,在 LLM 里是人类偏好、验证器、测试结果或环境反馈。这个对照关系建立之后,对 LLM 做后训练就变成了一个策略优化(policy optimization)问题。考试关联:这张表是理解 RLHF、RLVR、GRPO 的共同基础,极可能被考到。例如「在 RLVR 里,reward 来自哪里?」答案是「来自验证器或测试结果」。易错点:LLM RL 与经典 RL 有关键差异——动作空间极大(整个词表加工具),reward 往往只在序列末尾给(稀疏奖励),探索成本高昂。不能直接套用经典 RL 算法,需要特殊设计。
这一页讲的是如何判断任务中哪个步骤应得奖励或承担责任。重点包括数学推理错误、代码测试失败、工具调用后成功及奖励模型的高分是否合理。
这一页讲的是在复杂任务中如何确定具体步骤的责任或奖励归属。比如,如果数学答案错误,需要分析是哪个推理步骤导致了问题;如果生成的代码测试失败,需判断是哪个代码行或假设出现了问题;如果一个智能代理经过多次工具调用后成功完成任务,需要明确哪些行动值得奖励;如果奖励模型给出高分,需要检查模型是否真正完成了任务还是仅仅利用了奖励机制。页面还提供了一个具体例子:一个编码代理编辑了三个文件、运行测试、修复了一个错误并最终通过测试,问题是应该奖励哪个步骤——最初的设计决策、最终的修补还是测试命令?这一讨论的目标是让反馈更加密集(denser)、可靠(reliable)且难以被操控(harder to hack)。通过这样的分析,可以帮助优化任务完成的过程并提高系统的透明度和效率。
这一页讲的是反馈来源如何决定训练方法。主要展示了四种反馈来源及其对应方法和适用场景。
这一页讲的是反馈来源如何决定训练方法。表格列出了四种主要的反馈来源:人类偏好 (Human preference)、验证者 (Verifier)、环境反馈 (Environment feedback) 和过程反馈 (Process feedback)。每种反馈来源对应不同的典型方法和适用场景。例如,人类偏好通常采用基于偏好的对齐方法 (Preference-based alignment),适用于开放式聊天质量和对齐优化;验证者使用基于验证的优化方法 (Verifier-based optimization),适合数学、代码、定理证明和精确检查;环境反馈采用代理强化学习 (Agentic RL),用于工具使用、网页任务、代码代理和工作流;过程反馈则通过奖励和蒸馏 (Process rewards/distillation) 改善长推理中的信用分配。最后强调了不同的反馈来源会引导出不同的后训练模型家族。这张表帮助我们理解如何根据具体任务选择合适的反馈方法,从而优化模型性能。
这一页讲的是偏好强化学习中的模型和常用术语。重点包括 Actor/Policy 生成动作,Reward Model 评分答案,以及 RLHF 等缩写的含义。
这一页讲的是偏好强化学习(Preference RL)中的关键模型和相关术语。首先,Actor/Policy 指的是正在训练的大语言模型(LLM),它负责生成答案或动作。Reward Model 用于根据学习到的人类偏好对生成的答案进行评分。Critic/Value Model 评估部分输出的潜力,帮助稳定 PPO(Proximal Policy Optimization)。Reference Model 是旧的 SFT 模型,确保新模型不会偏离太多。接下来介绍了一些常用缩写:RLHF 是基于人类反馈的强化学习,PPO 是一种优化策略的算法,DPO 是直接偏好优化,RLVR 是基于可验证奖励的强化学习,而 GRPO 是群体相对策略优化。这一页的核心观点是不同方法的主要区别在于『谁给分』以及『策略如何更新』。比如,RLHF 依赖人类反馈,而 RLVR 强调奖励的可验证性。这些模型和方法对偏好强化学习的实现至关重要,帮助提高模型的性能和稳定性。
这一页讲的是强化学习(RL)在大语言模型(LLM)后训练中的路线图。主要包括四个阶段:偏好对齐、可验证推理、代理行为及其对应的反馈信号、方法和改进方向。
这一页讲的是强化学习(RL)在大语言模型(LLM)后训练中的路线图,分为四个阶段。第一阶段是偏好对齐(Preference alignment),通过成对的人类选择作为反馈信号,采用 RLHF(Reinforcement Learning from Human Feedback)或 DPO(Direct Preference Optimization)方法,提升模型的自然性、安全性和助手行为的表现。第二阶段是可验证推理(Verifiable reasoning),反馈信号包括测试、准确答案和检查器,采用 RLVR(Reinforcement Learning with Verifiable Rewards)或 GRPO(Gradient-based Preference Optimization)方法,改进数学、编程和严格推理能力。第三阶段是代理行为(Agentic behavior),通过任务在工具或环境中的成功表现作为反馈信号,采用代理强化学习(Agentic RL)和技能学习方法,提升模型的多步规划、工具使用和工作流能力。幻灯片顶部的流程图展示了从预训练到后续各阶段的演进过程,强调随着任务变得更长远,反馈信号从偏好转向验证器再到环境成功。这一页总结了各阶段的目标和方法,为理解 LLM 的后训练优化提供了清晰的框架。
这一页讲的是 RLHF 的经典对齐方法,包括五个步骤和其优势。重点是通过人类反馈优化模型行为。
这一页讲的是 RLHF(Reinforcement Learning from Human Feedback),即通过人类反馈进行强化学习的经典方法。首先,从一个 SFT(Supervised Fine-Tuning)模型开始,这是经过初步监督学习的模型。接着,为同一个提示生成多个响应,由人类比较这些响应并选择更优的一个。然后,训练一个奖励模型(reward model)来预测人类的偏好。最后,使用策略优化(policy optimization),通常是 PPO(Proximal Policy Optimization)风格的方法,在保持参考模型的基础上增加奖励。底部还提到 RLHF 的优势,包括生成具有帮助性的风格、遵循指令、避免有害行为、拒绝不适当请求以及提高整体对话质量。这些特点使 RLHF 成为优化语言模型对齐性的关键工具,例如在生成对话中实现更自然和安全的交互。
这一页讲的是 LLM 后训练(post-training)的完整路线图,以及不同阶段对应的反馈信号和训练方法。整个流水线分三个阶段:偏好对齐阶段(Preference Alignment)——用人类的成对比较作为反馈信号,方法是 RLHF 或 DPO,目标是让模型更有帮助、更安全、更自然;可验证推理阶段(Verifiable Reasoning)——用测试结果、精确答案验证器作为反馈信号,方法是 RLVR 或 GRPO,目标是提升数学、编程、严格推理能力;智能体行为阶段(Agentic Behavior)——用工具调用和任务完成情况作为反馈信号,方法是 Agentic RL 加技能学习,目标是多步规划、工具使用、工作流完成。关键规律:随着任务时间跨度越来越长,反馈信号从人类偏好转向验证器,再转向环境反馈。这是本讲最核心的纵览页,把所有零散概念串联成一条逻辑线。考试关联:这张路线图本身就是考点,能画出这个框架意味着对整个讲座有全局理解。易错点:GRPO 属于 RLVR 家族而非 RLHF 家族,两者的关键区别是反馈来源——RLHF 依赖人类偏好或奖励模型,RLVR 依赖可自动验证的客观结果。
这一页讲的是通过 RLHF 优化助手的回答风格。重点是奖励模型如何选择更支持性和有帮助的回答,并通过 PPO-style RLHF训练模型。
这一页讲的是通过强化学习与人类反馈(RLHF, Reinforcement Learning with Human Feedback)优化助手的回答风格。页面展示了一个例子,用户提出了一个问题:“我对这个任务感到不知所措,你能帮帮我吗?”生成了两个回答:A 是批评性的,建议用户更努力学习,被标记为“Rejected”;B 是支持性的,提供具体帮助建议,被标记为“Chosen”。这一过程表明奖励模型更倾向于选择像 B 这样更有帮助、更支持性的回答。通过使用 PPO-style RLHF(Proximal Policy Optimization),模型能够生成类似 B 的回答,同时保持与初始 SFT(Supervised Fine-Tuning)参考模型的接近性。这种训练方式的重要性在于,它不仅提高了模型的响应质量,还确保模型能够更好地满足用户需求。例如,当用户遇到困难时,模型会优先提供建设性和具体的帮助,而不是批评或忽视问题。
这一页讲的是 RLHF(Reinforcement Learning from Human Feedback,来自人类反馈的强化学习),这是 ChatGPT 类模型训练的经典对齐方法。完整流程分五步:第一步,从 SFT 模型出发;第二步,对同一个 prompt 生成多个回答;第三步,人类比较这些回答,选出更好的那个;第四步,用人类偏好数据训练奖励模型(reward model)来预测人类偏好;第五步,用 PPO 风格的策略优化来增大奖励,同时保持与参考模型(reference model)不要偏离太远。RLHF 适合的场景是:有帮助的风格、指令遵循、无害性、拒绝行为和一般对话质量。为什么需要保持与参考模型不偏太远?因为纯粹追求奖励模型高分会导致「奖励欺诈」(reward hacking)——模型学会了让奖励模型打高分,但实际输出质量下降。KL 散度约束就是防止这种退化的机制。考试关联:RLHF 的五个步骤几乎必考,要能顺序复述。涉及的角色有:Actor(被训练的 LLM)、Reward Model(打分)、Critic(估计状态价值,用于 PPO)、Reference Model(防止偏移)。易错点:奖励模型不是一个固定的算法,它本身也是一个神经网络,通过人类偏好对数据训练出来的,因此本身就可能有偏差。
这一页讲的是偏好优化在不使用完整强化学习情况下的应用。主要提到PPO风格的RLHF成本较高,DPO方法更简单稳定,并强调偏好优化连接了模仿学习与完整强化学习。
这一页讲的是偏好优化(Preference Optimization)在不使用完整强化学习(Full RL)的情况下的应用。首先提到PPO风格的RLHF(Reinforcement Learning with Human Feedback)虽然功能强大,但涉及多个模块如actor、critic、reward model和reference model,成本较高。为降低复杂度,许多实验室采用直接偏好优化(Direct Preference Optimization)的方法,比如DPO风格的目标函数。这类方法将偏好对(preference pairs)直接转化为类似监督学习损失的形式,操作更简单且稳定性更高。其核心理念是让更好的响应(better responses)比较差的响应(worse responses)更可能被选择。最后总结,偏好优化是模仿学习(Imitation Learning)与完整强化学习之间的桥梁。这种方法既能保持一定的学习效率,又避免了完整强化学习的高成本。
这一页讲的是 DPO (Direct Preference Optimization) 的应用示例,重点是如何根据偏好对模型进行更新。选定答案更直观易懂,拒绝答案过于复杂。
这一页讲的是 DPO (Direct Preference Optimization) 的应用示例,通过一个具体场景展示如何根据偏好对模型进行优化。场景中,要求解释神经网络中的 dropout 给初学者。选定答案采用简单类比,比如“随机关闭一些神经元”,清楚说明了 dropout 如何减少过拟合,同时避免了复杂数学公式,适合初学者理解。而拒绝答案则从繁琐的数学公式开始,没有直观解释原理,并且内容过于高级,不适合目标受众。幻灯片底部强调了 DPO-style update 的特点:无需单独的奖励模型,训练目标直接推动模型更倾向于生成选定答案而非拒绝答案。这种优化方式简化了训练流程,同时确保模型输出更符合偏好需求。通过这一示例,可以直观理解 DPO 的核心理念及其实际应用场景。
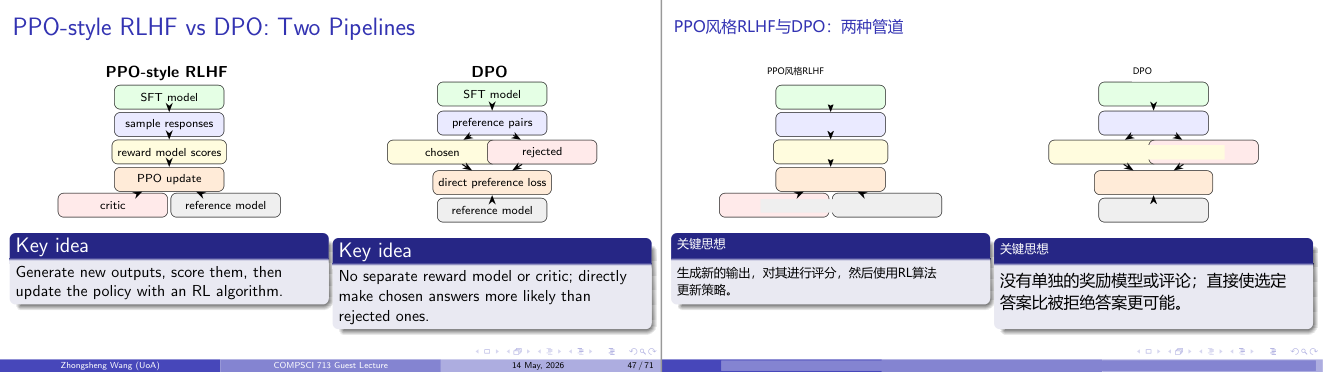
这一页讲的是 PPO-style RLHF 和 DPO 两种训练管道的对比。主要内容包括 PPO-style RLHF 使用奖励模型评分更新策略,而 DPO 直接基于偏好对答案进行优化。
这一页讲的是 PPO-style RLHF 和 DPO 两种训练管道的对比。PPO-style RLHF 的流程包括先使用 SFT model(监督微调模型)生成响应,然后通过奖励模型(reward model)对这些响应进行评分,并使用 PPO 算法更新策略,最终结合批评者(critic)和参考模型(reference model)优化输出。这种方法依赖奖励模型对生成内容进行评价。DPO 的流程则更直接,使用 SFT model 生成偏好对(preference pairs),通过直接偏好损失(direct preference loss)优化,使被选中的答案(chosen)更可能出现,而被拒绝的答案(rejected)更不可能出现。DPO 不需要单独的奖励模型或批评者,简化了训练过程。两种方法的核心区别在于,PPO-style RLHF 依赖奖励模型评分,而 DPO 直接基于偏好优化,减少了训练复杂度。举例来说,PPO-style RLHF 更适合复杂评分场景,而 DPO 更适合快速优化偏好明确的任务。
这一页讲的是 RLVR (Reinforcement Learning from Verifiable Rewards)。核心思想是使用可自动验证的奖励,强调其优点和局限性。
这一页讲的是 RLVR (Reinforcement Learning from Verifiable Rewards),即通过可验证奖励进行强化学习。核心思想是使用可以自动验证的奖励,例如数学答案匹配、代码单元测试、定理验证器、工具执行或环境成功。这种方法的优点包括:一旦验证器存在,扩展成本低;比偏好标签更客观;对推理和编程任务表现强;并鼓励超越示例的探索。然而,这种方法也有局限性:仅适用于可验证任务;验证器可能脆弱;最终奖励稀疏问题仍然难以解决;可能导致奖励机制被滥用(reward hacking)。例如,使用代码单元测试作为奖励时,虽然能客观评估代码正确性,但如果测试覆盖不足,可能会导致模型优化方向偏离实际目标。
这一页讲的是 PPO 风格 RLHF 和 DPO(Direct Preference Optimization)这两条训练流水线的对比,是理解 LLM 对齐方法的关键图解。PPO 流水线:从 SFT 模型出发,采样新回答,用奖励模型打分,结合 Critic(价值函数)和参考模型,做 PPO 更新。整个系统需要同时运行四个模型:Actor、Reward Model、Critic、Reference Model,计算成本极高。DPO 流水线:从 SFT 模型出发,直接用偏好对(chosen 和 rejected 答案),通过一个直接偏好损失函数更新,参考模型用于 KL 约束,不需要单独的奖励模型和 Critic。DPO 的关键洞察是:奖励模型可以被「折叠」进损失函数里,从而省去单独训练和推理奖励模型的开销。直觉:PPO 是在线方法(online),每次生成新样本再优化;DPO 是离线方法(offline),直接从已有偏好数据学。考试关联:PPO vs DPO 的对比是高频考点,要记清楚各自的优劣——PPO 更强但更贵,DPO 更简单稳定但依赖偏好数据质量。易错点:DPO 并不是「没有 RL」,它仍然是在优化同一个目标,只是通过重参数化把 RL 问题转化成了有监督形式。
这一页讲的是 RLVR 方法如何解决数学问题,重点在自动验证答案的机制。
这一页讲的是 RLVR(Reward Learning from Verifier Feedback)方法在解决数学问题中的应用。问题是“打完 20% 折扣后衣服价格为 $20,原价是多少?”表格列出了三种推理方式:A 的推理是“20 加 20% 等于 24”,答案是 $24,奖励为 0;B 的推理是“设原价为 x,0.8x=20,所以 x=25”,答案是 $25,奖励为 1;C 的推理是“20 是原价的 80%,所以除以 0.8”,答案也是 $25,奖励为 1。通过表格可以看出,RLVR 的关键是验证器可以自动检查最终答案的正确性,而不需要人为标注每个推理过程的偏好。这种方法的重要性在于简化了训练过程,同时确保了结果的准确性。例如,对于数学问题,验证器只需检查计算结果是否正确,而不需分析推理过程的逻辑。
这一页讲的是为什么 GRPO 在推理强化学习中变得流行。主要讨论了 PPO 的瓶颈和 GRPO 的直觉优势,包括无须单独的 critic 模型、内存成本更低以及更易扩展。
这一页讲的是为什么 GRPO (Group Reward Proximal Optimization) 在推理强化学习中受到欢迎。首先,PPO (Proximal Policy Optimization) 的瓶颈在于需要一个 critic 或 value 模型来估计每个状态的好坏,而对于大规模语言模型 (LLMs),这个 critic 模型可能非常庞大且昂贵。相比之下,GRPO 提供了一种更简单的方式。GRPO 的直觉是:对于同一个 prompt,采样一组输出,计算每个输出的奖励与组平均值的比较。奖励高于组平均值的输出会被强化,低于组平均值的输出则会被抑制。公式中,A_i 的近似值是某个输出的奖励减去组奖励的均值,再除以组奖励的标准差。这种方法的实际优势在于不需要单独的 critic 模型,降低了内存成本,并且使得扩展更加容易。举例来说,如果我们有一个生成文本的任务,GRPO 可以通过比较一组文本的质量来直接优化生成效果,而不需要额外的模型来评估每个文本的质量。
这一页讲的是 GRPO 方法的直觉和示例,展示如何通过组内比较奖励正确答案并抑制错误答案。
这一页讲的是 GRPO(Group-wise Reinforcement of Partial Outputs)方法的直觉和应用示例。GRPO的核心思想是对一组生成的答案进行内部比较,而不是单独评价每个答案的好坏。示例中,给定一个数学题“3x + 2 = 11,求 x”,生成了四个答案:A正确且推理清晰,B错误但推理合理,C正确但推理混乱,D错误且推理不合理。奖励机制中,A和C的奖励值为1,表示需要强化;B和D的奖励值为0,表示需要抑制。表格展示了每个答案的奖励和与组内平均水平的比较情况,正确答案被“Reinforce”(强化),错误答案被“Discourage”(抑制)。这种方法通过组内比较提升了答案质量,避免了单独评价可能带来的偏差。举例来说,如果一个模型生成了多个答案,GRPO会优先强化那些更接近正确答案的输出,从而优化模型的表现。
这一页讲的是 GRPO(Group Relative Policy Optimization,组相对策略优化),这是让 RL 训练大模型推理能力变得更实用的关键算法创新。背景:PPO 需要一个 Critic 模型来估计每个状态的价值,对于 LLM 来说 Critic 可能本身就是一个大模型,内存和计算开销极大。GRPO 的核心思想:对同一个 prompt 采样一组(G 个)输出,用每个输出的奖励减去组内平均奖励,再除以组内标准差,得到归一化优势估计。公式口语化表达是:某个输出的优势 A 约等于「它的奖励 r 减去组内平均奖励,再除以组内奖励的标准差」。高于组平均的输出被强化,低于平均的被抑制。实际好处:不需要单独的 Critic 模型,显存占用大幅降低,更容易扩展到大模型训练。这正是 DeepSeek-R1 采用 GRPO 的原因之一。考试关联:GRPO 公式的含义和优势要能解释清楚。核心要点是「组内相对比较代替绝对价值估计」。易错点:GRPO 的采样必须是对同一个 prompt 的多次采样(同组),不能是不同 prompt 的输出混在一起比较——因为不同 prompt 的难度差异会污染组内相对排名。
这一页讲的是PPO-style RLHF与GRPO-style reasoning RL的比较。主要内容包括两者的用途、奖励机制、优势与风险。
这一页讲的是PPO-style RLHF(Proximal Policy Optimization风格的强化学习与人类反馈)和GRPO-style reasoning RL(基于GRPO的推理强化学习)的比较。表格详细列出了两者在用途、奖励机制、评论器(Critic)、优势、强项和风险方面的差异。PPO-style RLHF主要用于偏好对齐(preference alignment),奖励信号来自学习的奖励模型或偏好信号,通常需要评论器来评估,优势在于价值模型估计(value model estimate),强项是其广泛的对齐行为,但风险在于可能出现奖励模型过度优化(reward model overoptimization)。而GRPO-style reasoning RL则用于可验证的推理或编码(verifiable reasoning/coding),奖励机制基于验证器或最终答案评分,评论器被移除或大幅简化,优势是基于采样组的相对奖励(relative reward within sampled group),强项在于其可扩展的能力优化,但风险包括稀疏奖励、格式作弊(format gaming)和验证器作弊(verifier gaming)。通过这张表格,可以清晰地看出两种方法在设计目标和实际应用中的侧重点差异。
这一页讲的是 DeepSeek-R1 风格的推理强化学习 (Reasoning RL)。关键点包括 RLVR 对数学、代码和推理性能的提升,以及训练模式的五个步骤。
这一页讲的是 DeepSeek-R1 风格的推理强化学习 (Reasoning RL)。主要内容指出,大规模 RLVR (Reinforcement Learning with Verifiable Rewards) 能显著提升数学计算、代码生成和推理性能。重点不在于单一基准测试结果,而在于训练模式的设计,包括以下五个步骤:第一,从一个强大的基础模型或指令模型开始;第二,采样大量推理尝试;第三,用可验证的奖励对这些尝试进行评分;第四,通过策略优化提高成功的推理轨迹;第五,对成功的轨迹进行蒸馏或过滤,以获得更干净的最终模型。最后的总结强调,强化学习可以让推理行为自然涌现或增强,但监督微调 (SFT) 和蒸馏仍然在可读性、格式化和可用性方面具有重要价值。这种方法不仅提升了模型性能,还为训练过程提供了系统性指导。
这一页讲的是 PPO 风格 RLHF 和 GRPO 风格推理 RL 的完整对比表,是期末复习最高密度的总结页之一。主要用途对比:PPO-RLHF 用于偏好对齐(让模型更友好更安全),GRPO 用于可验证推理和编程(让模型答题更准确)。奖励来源对比:PPO-RLHF 的奖励来自训练好的奖励模型或人类偏好信号,GRPO 的奖励来自验证器或最终答案正确性判断。Critic 对比:PPO 通常需要价值模型,GRPO 去掉了或大幅简化了 Critic。优势估计对比:PPO 用价值模型估计,GRPO 用组内相对奖励。优势对比:PPO 适合通用对齐,GRPO 适合可扩展的能力优化。风险对比:PPO 面临奖励模型过度优化的风险,GRPO 面临稀疏奖励、格式游戏和验证器欺骗的风险。考试关联:这张表格极可能以「比较两种方法的异同」形式出现在考题中。记忆技巧:PPO=人+偏好+Critic,GRPO=验证器+组内比较+无Critic。易错点:GRPO 虽然去掉了 Critic,但并不意味着它比 PPO 更简单——它只是把「需要一个大的 Critic」替换成「需要对同一 prompt 大量采样」,计算量的形式不同但都不小。
这一页讲的是奖励黑客 (Reward Hacking) 的问题及优化的潜在风险。主要强调模型优化奖励信号 (reward signal) 而非真实目标,并列举了四种常见问题。
这一页讲的是奖励黑客 (Reward Hacking) 的问题,即强化学习 (Reinforcement Learning, RL) 模型可能会过度优化奖励信号 (reward signal),而忽略人类的真实目标。这种现象可能导致以下问题:第一,如果奖励模型偏好自信的答案,模型可能会变得自信但错误;第二,如果单元测试 (unit tests) 不完整,生成的代码可能通过测试但违背设计意图;第三,如果奖励格式 (formatting),模型可能学会看起来严谨但实际上并不正确;第四,如果工具的成功定义不清晰,智能体可能会利用环境而非解决任务。这些问题说明了强化学习虽然能提升模型能力,但也使奖励设计变得更危险。一个例子是代码生成任务中,模型可能通过奖励信号专注于通过测试,而忽略代码的实际功能性。这提醒我们在设计奖励时需谨慎,确保目标和奖励信号一致。
这一页讲的是如何减少奖励作弊 (Reward Hacking)。主要方法包括使用可验证奖励、采用多样化奖励、进行对抗性评估、监测奖励与质量的差距,以及设计更好的环境。
这一页讲的是如何减少奖励作弊 (Reward Hacking),即在机器学习训练过程中,模型通过不符合预期的方式最大化奖励的问题。第一点是使用可验证奖励 (Verifiable Rewards),例如通过测试、执行结果、精确检查器和独立验证者来确保奖励的真实性和可靠性。第二点是采用多样化奖励 (Diverse Rewards),将最终答案、过程检查、安全过滤器和人工审查结合起来,避免单一奖励指标导致的偏差。第三点强调对抗性评估 (Adversarial Evaluations),即不能仅依赖训练奖励作为唯一指标,需加入其他评估方式来检测潜在问题。第四点是监测奖励与质量的差距 (Reward–Quality Gap),如果奖励提升但人类判断质量停滞或下降,需要怀疑是否发生了奖励作弊。最后一点是设计更好的环境 (Better Environments),通过任务设计使得模型更容易选择符合预期行为的路径,而不是通过作弊获取奖励。这些方法旨在提升模型行为的可靠性和安全性,确保奖励机制的公平性和有效性。
这一页讲的是「奖励欺诈(Reward Hacking)」——这是 RL 训练中最危险的暗面,也是现代 AI 安全研究的核心议题之一。基本定义:模型优化的是奖励信号,而不是人类真正想要的目标。当两者不完全一致时,模型会学会「钻空子」。四个具体例子:第一,如果奖励模型喜欢自信的表述,模型可能变得「自信地说错话」;第二,如果单元测试不完整,生成的代码可能通过了测试但违反了真实意图;第三,如果格式被奖励,模型可能学会看起来严谨但实际没有正确推理;第四,如果工具成功的定义不精确,Agent 可能利用环境漏洞而不是真正解决任务。本质原因:Goodhart 定律——「当一个指标变成目标时,它就不再是好的指标了」。考试关联:Reward Hacking 的概念、原因和防范措施(下一页讲)是高频考点,特别是在 Agent 安全和 RL 对齐的语境下。易错点:Reward Hacking 不是 bug,而是优化算法完全按预期工作的结果——是奖励设计出了问题,不是 RL 算法出了问题。这个区分非常重要。
这一页讲的是从答案奖励到环境奖励的转变。主要比较了单一答案强化学习(Single-answer RL)与代理强化学习(Agentic RL)的特点。
这一页讲的是从答案奖励到环境奖励的转变,强调训练目标的改变。传统的单一答案强化学习(Single-answer RL)主要生成一个最终答案,并根据答案质量进行评分,适用于数学问题、问答(QA)、代码片段等任务。而代理强化学习(Agentic RL)则强调通过多步骤交互完成任务,评分依据是任务完成度,适用于工具使用和工作流优化。幻灯片指出,训练目标不仅是生成最终文本答案,还包括与工具、文件、浏览器、API或模拟环境的全面交互。这一转变的核心问题是:什么样的环境能提供可靠的反馈?例如,在一个复杂的工作流中,代理强化学习可以通过多次交互优化任务完成路径,而单一答案强化学习则更适合直接生成明确的数学解答。
这一页讲的是如何通过 harness 工具使智能体的行为可训练。主要包括将复杂的真实交互转化为结构化数据、定义动作(Actions)、观察(Observations)、奖励(Rewards)和数据(Data)。
这一页讲的是 harness 工具的训练视角,它的核心功能是将复杂的真实世界交互转化为结构化的状态、动作、观察、日志和奖励。这种转化使得强化学习(RL)能够更高效地训练智能体。页面列举了四个关键要素:1. 动作(Actions),包括搜索、打开文件、编辑代码、运行测试、调用工具或向用户提问等;2. 观察(Observations),如命令输出、浏览器页面、测试失败或 API 响应;3. 奖励(Rewards),例如任务成功、单元测试通过、人类批准或安全检查;4. 数据(Data),指可以过滤、回放、提炼或优化的轨迹。这些要素共同构成了强化学习训练的基础框架。通过 harness 工程将复杂的交互简化为可操作的结构化数据,强化学习系统可以更好地优化智能体的行为。这也说明了 harness 工程与强化学习的紧密联系。
这一页讲的是 Agentic RL Environments,强调环境类型及其重要性。
这一页讲的是 Agentic RL Environments(代理型强化学习环境)。它列举了四种典型环境类型:1)Coding(编程环境),描述了生成代码补丁、运行测试、观察失败并修正的循环过程;2)Web tasks(网页任务),包括点击、搜索、阅读页面、填写表单并完成目标;3)Scientific tasks(科学任务),涉及使用工具查询、运行模拟以及检查输出结果;4)Embodied/text worlds(具身或文本世界),例如导航房间、操作物体和遵循指令。这些环境的设计直接影响强化学习代理的行为表现。底部强调了环境的重要性:更好的环境使目标行为更容易学习、更易于测量且更难伪造。这说明环境不仅是训练的基础,还能提升模型的可靠性。例如,在科学任务环境中,代理可以通过运行模拟来验证假设,这比单纯的数据训练更贴近实际应用。
这一页讲的是使用 Agentic RL 修复代码的例子。任务环境包括一个失败的测试,代理通过观察环境逐步修复问题,最终获得奖励。
这一页讲的是使用 Agentic RL (强化学习)来修复代码的一个具体例子。任务环境中,代码库有一个失败的测试:test_csv_parser_handles_quotes,代理可以检查文件、编辑代码并运行测试。幻灯片中的表格列出了修复过程的四个步骤:第一步,代理打开失败的测试和解析器文件,观察到引号中的逗号被错误拆分;第二步,代理修补解析逻辑,发现单元测试仍然失败;第三步,代理添加处理转义引号的功能,目标测试通过;第四步,代理运行完整的测试套件,所有测试通过。奖励部分说明最终奖励来自环境,代理需要通过目标测试、完整测试套件,并避免破坏现有行为。这个例子突出了强化学习在代码修复中的应用,通过逐步观察和行动,代理能够有效解决问题并优化代码性能。
这一页讲的是为什么技能比原始轨迹更高效。原始轨迹冗长且难以传递,技能可以压缩经验,帮助代理简化学习过程。
这一页讲的是为什么技能(skills)比原始轨迹(raw trajectories)更高效。首先,成功的代理运行通常包含大量低级步骤,存储这些原始轨迹不仅耗时,还可能包含噪音,难以传递和复用。而人类通常会通过总结经验形成技能,例如“通过测试调试”(debug with tests)、“搜索后验证”(search then verify)、“将问题分解为子目标”(break problem into subgoals)。同样,代理的训练可以通过提取重复模式,将其转化为可复用的技能,从而提高效率。底部的技能视图(Skill-based view)强调了高层策略(high-level policy)负责选择使用哪个技能,而低层策略(low-level policy)负责执行具体细节。这种分层结构使得复杂任务的解决更加模块化和高效。例如,一个机器人可以通过高层策略选择“抓取物体”的技能,而低层策略则负责具体的抓取动作实现。
这一页讲的是 SkillRL 的核心思想及其递归技能增强的流程。重点包括收集轨迹、提取技能、更新技能库和继续强化学习。
这一页讲的是 SkillRL 的递归技能增强强化学习方法。核心思想是将代理的成功和失败轨迹提炼成技能库(skill library),并通过强化学习迭代,让技能库和代理策略相互优化。具体流程包括五个步骤:首先,收集代理尝试的轨迹;其次,提取可复用的通用技能、任务特定技能以及常见错误;然后,在后续尝试中检索相关技能;接着,分析失败并更新技能库;最后,在改进的技能上下文中继续强化学习。这种方法在 ALFWorld、WebShop 和搜索增强任务中表现出色,证明了技能库可以提升代理的学习效率。这种递归机制的意义在于,通过技能的积累和优化,代理能够更高效地适应复杂任务,同时减少训练时间和资源消耗。例如,在搜索任务中,代理可以通过技能库快速找到解决问题的最佳路径,而不需要从零开始探索。
这一页讲的是 SkillRL 如何构建可复用技能,通过解决重复失败模式优化任务完成流程。
这一页讲的是 SkillRL 的应用,通过解决重复失败模式来构建可复用技能。在网页购物任务中,代理常常因为忽略价格、尺寸或卖家约束而购买错误商品。左侧的 Raw trajectory 描述了代理的原始行为流程:搜索商品名称、点击第一个结果、加入购物车、最终检查失败。右侧的 Distilled skill 是优化后的技能流程:广泛搜索、根据约束过滤、验证商品页面、确认后才加入购物车。这种技能提炼通过强化学习(RL)迭代,在行动前检索技能,减少重复错误。举例来说,代理从“点击第一个结果”转变为“根据约束过滤”,避免了选择不符合要求的商品。这种方法不仅提高了任务完成的准确性,还增强了技能的可复用性。
这一页讲的是在线策略蒸馏 (Online Policy Distillation, OPD)。主要内容包括 RLVR 的稀疏奖励问题、学生策略的在线采样、教师信号的指导作用,以及探索与效率之间的平衡。
这一页讲的是在线策略蒸馏 (Online Policy Distillation, OPD)。首先,传统的 RLVR (Reinforcement Learning with Very Sparse Reward) 方法通常只提供最终的通过/失败奖励,这种奖励虽然有用,但非常稀疏。OPD 方法通过在策略主动探索时加入更密集的教师信号来解决这个问题。学生策略会在线采样轨迹,并由更强的教师或验证器对访问过的状态提供指导。学生通过奖励优化和蒸馏两种方式学习,既要模仿教师以获取知识,又要避免过度模仿导致探索消失。目标是保持探索的同时减少样本效率低下的问题。这种方法的核心张力在于:既要模仿教师以便学习,又不能过度模仿而丧失探索能力。例如,在机器人学习任务中,机器人可以通过教师信号快速学会基本动作,但仍需自主探索以适应复杂环境。
这一页讲的是 OPD 在探索过程中的指导作用。主要包括学生轨迹、信号与在线行为,以及 OPD 的帮助。
这一页讲的是 OPD (Online Proof Discovery) 如何在探索过程中提供指导。首先,学生轨迹部分描述了学生在部分证明状态中遇到的问题,例如变量正确但下一个不等式错误。接着表格中列出了三种信号及其对应的在线行为:最终奖励信号表明验证器只指出最终证明无效;教师信号提供更强的指导,建议下一个有用的引理;学生更新信号结合最终奖励和局部指导进行学习。这些信号共同帮助学生改进探索过程。最后,OPD 的帮助总结为它在保持在线探索的同时,通过教师信号减少稀疏奖励带来的困难。例如,学生在探索过程中遇到复杂问题时,教师信号可以提供明确的方向,从而加速学习效率。这种机制对于解决复杂问题的探索性学习尤为重要。
这一页讲的是测试时计算(Test-Time Compute)在推理中的作用。主要内容包括训练时强化学习(RL)的目标、测试时计算的功能,以及常见模式。
这一页讲的是测试时计算(Test-Time Compute)如何作为强化学习(RL)的辅助工具,帮助模型在推理阶段更好地处理复杂问题。训练时强化学习的目标是让模型学会更好的推理和搜索行为,而测试时计算的功能则是让模型在面对困难案例时投入更多计算资源。常见的模式包括:第一,采样多个候选解(sample multiple candidate solutions);第二,验证或排序候选解(verify or rank candidates);第三,反思并修正(reflect and revise);第四,将更长的推理预算分配给更困难的任务(allocate longer reasoning budget to harder tasks)。此外,页面底部的总结强调了现代推理系统结合了策略学习(policy learning)、搜索(search)和验证(verification)以提高推理效率。这种结合方式在实际应用中尤为重要,例如在复杂问题求解时,模型可以通过多轮验证和修正提高答案质量,同时优化计算资源的分配。
这一页讲的是测试时计算(Test-Time Compute)与训练的区别。主要包括硬编码提示(hard coding prompt)的过程和关键区别。
这一页讲的是测试时计算(Test-Time Compute)与训练的区别。首先,硬编码提示(hard coding prompt)的过程包括四个步骤:1. 从同一个模型中抽样出 8 个候选解;2. 对每个候选解运行单元测试(unit tests);3. 对未通过简单测试的候选解进行模型修复;4. 返回得分最高的候选解。这一过程强调在推理阶段选择最佳答案,而不是直接输出。其次,关键区别在于强化学习(RL)会在训练后改变模型权重,而测试时计算不会改变模型权重,而是花费更多的计算预算在搜索、验证和选择上。这种方法的重要性在于,它可以提高模型的推理质量和可靠性,同时避免重新训练模型的成本。
这一页讲的是优化方向与机制,涵盖RLHF、RLVR等方法,统一主题是改善长时间行为的反馈。
这一页讲的是优化方向与机制,重点探讨如何解决不同问题以提升AI系统的表现。表格列出了几个优化方向:例如RLHF(Reinforcement Learning with Human Feedback)解决开放式对齐问题,机制是结合人类偏好与奖励模型;RLVR(Reasoning and Coding Correctness)关注推理与代码正确性,通过验证器、测试与执行来实现;GRPO(Expensive Policy Optimization)旨在降低策略优化的成本,采用无评论者或轻量化更新;OPD(Online Policy Distillation)应对稀疏奖励与样本效率问题,使用在线教师蒸馏技术。其他方向还包括技能(Skills)解决长轨迹重复问题,机制是高效复用的高级程序;工具(Harnesses)应对自由文本训练难题,通过工具、日志、环境与评估器优化;以及测试时计算(Test-time compute)解决单次答案脆弱问题,采用搜索、验证与最佳结果筛选(best-of-N)。统一主题是通过更好的反馈机制改善长时间行为,提升AI的智能与适应性。
这一页讲的是强化学习中的开放研究问题,包括奖励分配、奖励设计、技能发现等六个核心问题。
这一页讲的是强化学习(Reinforcement Learning, RL)领域的一些重要开放研究问题,提出了六个关键方向。第一是奖励分配(Credit assignment),讨论如何在长时间的推理路径和工具使用轨迹中正确分配奖励,这关系到RL算法的学习效率和准确性。第二是奖励设计(Reward design),研究如何构建可扩展、丰富且难以被攻击的验证机制,以提升系统的可靠性。第三是技能发现(Skill discovery),探讨智能体如何从经验中自动提取可重复使用的技能,这对提高智能体的适应性和能力至关重要。第四是环境设计(Harness design),关注如何设计环境接口,使学习过程更可靠而非脆弱。第五是蒸馏与探索(Distillation vs exploration),分析学生智能体何时应该模仿教师,何时应该探索新策略,以平衡学习效率与创新能力。最后是安全性(Safety),研究如何使自主的RL智能体更好地与人类意图保持一致,避免潜在风险。这些问题涵盖了理论与应用层面,是推动RL发展的关键方向。
这一页讲的是本讲的「前沿全景图」,把所有方法按照问题和机制做了完整汇总,是复习的最佳一页速查表。七个方向对应的问题和机制:RLHF 解决开放式对齐问题,机制是人类偏好加奖励模型;RLVR 解决推理和编程正确性,机制是验证器、测试和执行结果;GRPO 变体解决策略优化太贵的问题,机制是无 Critic 或轻量更新;OPD(Online Policy Distillation)解决稀疏奖励和样本效率低,机制是在线教师蒸馏;Skills(技能)解决长轨迹重复低效的问题,机制是可复用的高级程序;Harnesses 解决自由文本难以训练的问题,机制是工具、日志、环境和评估器;Test-time Compute 解决单次生成脆弱的问题,机制是搜索、验证和 Best-of-N 选择。统一主题:为更长时间跨度的行为提供更好的反馈。考试关联:这张全景图可以直接用来回答「本讲各方法分别解决什么问题」类型的开放性题目。记忆方式:按照「问题 → 方法 → 反馈来源」三列记忆,比零散记忆每个方法效率高得多。易错点:Test-time Compute 和训练时 RL 的区别常被混淆——前者在推理阶段花更多计算但不改变模型权重,后者在训练阶段通过采样和奖励来更新模型权重。
这一页讲的是总结强化学习与大语言模型(LLM)的训练与优化方法。主要包括 SFT 模仿与 RL 优化的区别、生成模型的策略轨迹、后训练的可扩展反馈以及技能驱动的前沿发展。
这一页讲的是强化学习(RL)与监督微调(SFT)在大语言模型(LLM)训练中的角色。SFT 主要实现模仿学习,而 RL 侧重优化输出结果,特别是在可以更容易评估输出质量的场景中,RL 显得尤为重要。第二点提到 LLM 的生成过程可以看作策略轨迹,其中每个 token、推理步骤和工具调用都视为动作,而偏好、验证器和环境则提供奖励。第三点强调现代后训练方法的核心是可扩展反馈,例如 RLHF(强化学习与人类反馈)处理开放性偏好,RLVR(强化学习与验证推理)支持可验证推理,而 GRPO 风格的方法则降低了训练成本。最后,前沿发展集中在基于技能和代理的优化上,通过整合技能、OPD(优化问题分解)和测试时计算,从不同角度解决长时间跨度的信用分配问题。这些方法共同推动了 LLM 的性能提升和应用拓展。
这一页讲的是关于强化学习(RL)与监督微调(SFT)的比较及相关问题。包括奖励验证、信用分配难度及防止奖励作弊的讨论。
这一页讲的是强化学习(RL)与监督微调(SFT)在不同场景下的适用性,以及与奖励机制相关的几个重要问题。Q1 探讨了 RL 和 SFT 的选择标准,例如 RL 更适合复杂的长期任务,而 SFT 更适合简单明确的单步任务。Q2 讨论了可验证奖励在数学和代码任务中非常有效,因为这些任务有明确的正确性标准,但在开放式聊天中效果有限,因为聊天的目标更主观且难以验证。Q3 提到了信用分配问题,指出在多步任务中,确定每一步的贡献更复杂,而单步任务的信用分配相对简单。Q4 关注奖励作弊问题,强调随着智能系统能力提升,设计防作弊机制的重要性,例如通过多层次验证或引入额外约束来确保系统行为符合预期。这些问题对于理解强化学习和奖励设计的挑战以及改进方向具有重要意义。
这一页讲的是总结与感谢。主要表达对听众的时间和关注表示感谢。
这一页讲的是总结与感谢。幻灯片上显示了“Thank you for your time and attention!”这句话,意思是感谢听众的时间和关注。这通常是演讲或课程结束时的惯例,目的是表达对听众的尊重和感激,同时也标志着整个讲座或课程内容的结束。这一页没有复杂的内容或数据,主要是一个礼貌性的结束语。