第 1 / 39 页

这一页讲的是关于 Graph Cast 和图神经网络(GNNs)的课程内容,重点是 AI 在可持续发展中的应用。
空格=播放/暂停当前页 · Tab=切换 简短/详细/深入 · 红色「深入」为重点页的深度讲解
这一页讲的是关于 Graph Cast 和图神经网络(GNNs)的课程内容,重点是 AI 在可持续发展中的应用。
这一页讲的是 University of Auckland 的课程内容,主题为 Graph Cast 和图神经网络(Graph Neural Networks, GNNs)。这节课是 COMSPCI 713: AI Fundamentals 的一部分,主要研究 AI 如何应用于可持续发展领域。Graph Cast 是一种基于图结构的预测方法,与 GNNs 紧密相关,GNNs 是处理图数据的深度学习模型,能够捕捉节点间复杂关系。此课程可能会探讨 GNNs 在解决可持续发展问题中的实际案例,例如优化资源分配或环境监测。课程日期是 2026 年 5 月 21 日,由 Thomas Lacombe 教授授课。

这一页讲的是致谢内容,列出了本次课程的参考来源,包括 AI 可持续性、深度学习书籍和斯坦福课程。
这一页讲的是课程的致谢部分,介绍了本次讲座所参考的主要资源。第一部分提到了 Yun Sing Koh 的关于 AI 可持续性(AI for sustainability)的幻灯片,这表明课程内容与人工智能在环境或社会可持续发展方面的应用相关。第二部分引用了《Understanding Deep Learning》一书的第13章及其相关图表,该书由 Prince S.J. 撰写并由 MIT Press 出版,说明课程内容涉及深度学习的理论和实践。最后一部分提到了斯坦福大学的 CS224W 课程,即《Machine Learning with Graphs》,并提供了相关网址(http://cs224w.stanford.edu),表明课程内容与图机器学习(Graph Machine Learning)相关。这些资源为课程提供了理论框架和实践指导,帮助学生理解人工智能技术的前沿应用和研究方向。

这一页讲的是学习目标,涵盖了人工智能与可持续性、图神经网络(GNNs)的原理及应用。
这一页讲的是学习目标,主要包括六个方面。第一,讨论人工智能(AI)在可持续性领域的原则和实际例子,以及AI自身的可持续性问题。第二,介绍Graph Cast作为AI可持续性应用的一个具体案例。第三,举例说明哪些数据可以用图(graph)来表示,例如社交网络、分子结构等。第四,深入解释图神经网络(Graph Neural Networks, GNNs)的工作原理,尤其是图卷积网络(Graph Convolutional Networks, GCN)如何处理图数据。第五,列举一些常见的GNN任务,例如节点分类、链接预测和图生成。第六,讨论在处理图数据时,置换不变性(permutation invariance)和等变性(equivariance)的重要性,这些特性确保了模型对图结构的理解不受节点排列的影响。通过这些学习目标,学生可以全面了解图数据处理的核心概念及其在AI中的应用。

这一页讲的是 AI for Social Impact 的概念及其发展趋势。重点包括人工智能用于解决社会问题的潜力,以及推动可持续发展目标的必要性。
这一页讲的是 AI for Social Impact(人工智能的社会影响)这一领域的兴起及其重要性。首先,这一领域旨在通过人工智能解决重要的社会问题,体现了科学技术在社会层面上的应用潜力。其次,幻灯片提到目前有越来越多的努力将人工智能应用于‘善’的用途,例如支持可持续发展目标(sustainable development goals, SDGs)。然而,作者强调,不仅要关注人工智能的具体应用,还需要进一步探讨开发和使用人工智能系统本身的可持续性。这一观点提醒我们,人工智能不仅是工具,还需要从系统设计和长期影响的角度进行深度思考。例如,在医疗领域,AI可以帮助诊断疾病,但同时也需要考虑其数据处理的能源消耗和伦理问题。

这一页讲的是人工智能的益处与风险平衡。重点提到 AI 的能耗问题可能加剧环境退化,并预测到 2027 年 AI 行业的能耗可能达到荷兰国家的水平。
这一页讲的是人工智能(AI)的益处与风险平衡。虽然 AI 带来了许多好处,但根据世界经济论坛(World Economic Forum, WEF)的观点,如果不加以引导,AI 可能会加速环境退化。这主要体现在 AI 的高能耗上,因为许多 AI 系统需要大量能源来运行。幻灯片提到了一些研究和报告,例如云计算的全球排放量已经超过了商业航空业的碳排放量。此外,一项研究预测,到 2027 年,AI 行业的能源消耗可能等同于一个像荷兰这样国家的规模。这些数据表明,AI 的发展虽然带来了技术进步,但也可能对环境造成显著影响,因此需要在技术提升与环境保护之间找到平衡。举例来说,优化 AI 算法的能效或采用绿色能源可以减少其环境影响。

这一页讲的是机器学习 (ML) 的碳排放研究及优化方法,包括降低成本、能耗和碳足迹的“4Ms”框架:Model、Machine、Mechanization 和 Map。
这一页讲的是研究人员如何优化机器学习 (ML) 的成本、能耗和碳排放问题,提出了“4Ms”框架。第一,Model 指代解决 AI 问题的机器学习算法,算法的设计直接影响计算复杂度和资源消耗。第二,Machine 是运行模型的计算硬件,硬件性能决定了训练时间和能耗,例如 GPU 或 TPU 的选择。第三,Mechanization 涉及数据中心的运行效率,能源如何高效地传递到硬件是关键,比如通过冷却系统优化能耗。最后,Map 强调数据中心的地理位置对能源清洁度的影响,例如选择靠近可再生能源丰富的地区。通过云计算,研究人员可以更方便地选择绿色能源位置。这一框架帮助 ML 实践者从多个角度优化资源使用并减少环境影响。

这一页讲的是 AI 与可持续性之间的关系,包括两个核心概念:AI for Sustainability 和 Sustainability of AI。
这一页讲的是 AI 与可持续性之间的关系,提出了两个重要的概念:AI for Sustainability 和 Sustainability of AI。AI for Sustainability 指的是人工智能如何帮助实现环境、经济和社会的可持续发展目标,例如利用 AI 优化能源使用、减少碳排放或改善资源分配。Sustainability of AI 则关注人工智能自身的可持续性问题,包括 AI 系统的能源消耗、硬件资源的使用,以及如何降低 AI 对环境的负面影响。幻灯片建议用 5 到 10 分钟与同学讨论这两个概念,并思考各自的实际应用场景,例如 AI 在气候变化预测中的作用,或者如何设计更节能的 AI 算法。这些讨论有助于理解 AI 在全球可持续发展中的双重角色和挑战。

这一页讲的是人工智能与可持续性之间的关系,包括两个主要主题:人工智能如何促进可持续发展(AI for Sustainability)和人工智能自身的可持续性(Sustainability of AI)。
这一页讲的是人工智能与可持续性相关的两个重要领域。第一个主题是“AI for Sustainability”,即人工智能如何帮助实现可持续发展目标。例如,AI可以优化能源使用、减少碳排放、改善资源管理,从而支持环境保护和社会经济的可持续性。第二个主题是“Sustainability of AI”,关注人工智能技术本身的可持续性问题。这包括AI系统的能源消耗、硬件制造对环境的影响,以及如何设计更加高效和环保的AI模型。例如,训练大型语言模型可能需要大量计算资源,这对环境造成压力,因此需要探索更节能的算法和技术。这两个主题既相互独立又紧密关联,共同构成了人工智能在全球可持续发展中的关键作用。

这一页讲的是 GraphCast 案例研究,展示 AI 在天气预测中的应用。主要内容包括使用深度学习替代传统的数值天气预测(NWP),与 NWP 数据协作填补空白,以及生成更快、更准确的10天预测。
这一页讲的是 GraphCast,这是 Google DeepMind 于2023年推出的一个天气预测系统。GraphCast 使用深度学习(Deep Learning)来替代传统基于物理方程的数值天气预测(Numerical Weather Prediction, NWP)。这一创新方法通过与 NWP 数据协作,在训练前填补数据中的空白,从而提高数据质量。GraphCast 能够在训练完成后生成更快的10天天气预测,其准确性也优于传统方法。这种改进对于可持续发展意义重大,因为准确的天气预测可以帮助优化农业、能源管理和灾害预警等领域的决策。例如,农民可以根据更精确的降雨预测调整种植计划,从而减少资源浪费。页面右侧的图片强调了 AI 正在改变天气预测的方式,显示 AI 技术在提升效率和精度方面的潜力。

这一页讲的是 GraphCast 的图神经网络架构及其基于历史数据的学习。重点包括图结构在大气过程建模中的应用,以及利用 ERA5 数据进行中长期天气预测的效果。
这一页讲的是 GraphCast 的图神经网络架构(Graph Neural Network Architecture)和基于历史数据的学习(Learning from Historical Data)。首先,GraphCast 使用图结构(graph-based representation)来动态建模大气过程,这种方法能够自然地表示复杂的交互关系,比如区域间的能量和质量传递。这种架构特别适合处理大气系统的复杂性。其次,GraphCast 通过深度学习方法,使用 ECMWF 的 ERA5 数据集,训练了涵盖 40 年的历史天气数据,并填补了数据缺口。这种方法能够捕捉大气模式的空间和时间特征,从而实现准确的中长期天气预测。一个例子是利用这种模型可以更好地预测未来几天甚至几周的全球天气变化,对气象学和相关领域有重要意义。
这一页讲的是 GraphCast 这个系统的整体架构与训练方式。GraphCast 是 Google DeepMind 在 2023 年发布的天气预报系统,核心创新在于用深度学习替代了传统的数值天气预报(Numerical Weather Prediction,NWP)。传统 NWP 通过物理方程(偏微分方程组)模拟大气运动,计算量极大,需要超级计算机跑好几个小时才能出一份 10 天预报。GraphCast 则是先用 40 年历史气象数据训练好一个图神经网络,训练完之后推理速度非常快,准确率还比传统方法更高。有一点容易混淆:GraphCast 并不是完全抛弃 NWP,而是借助 ECMWF 的 ERA5 再分析数据集——那些历史气象观测里的空缺位置,是用 NWP 补全的,所以两者是协同关系而非替代关系。输入方面,它把全球大气划分为 0.25 度经纬度网格,共超过 100 万个格点,每个格点有 227 个变量(5 个地表变量加上 6 个大气变量乘以 37 个气压层)。整体上 GraphCast 是 AI for Sustainability 的典型案例:用机器学习帮助人类更准确地预测极端天气,从而减少自然灾害损失。考试常见考法:问 GraphCast 和 NWP 的关系是什么,以及它为什么用图神经网络而不用普通卷积网络(答案是地球是球面,图结构能自然表达不规则邻域)。易错点:不要说 GraphCast 完全不需要 NWP,它的训练数据本身就依赖 NWP 填补缺口。
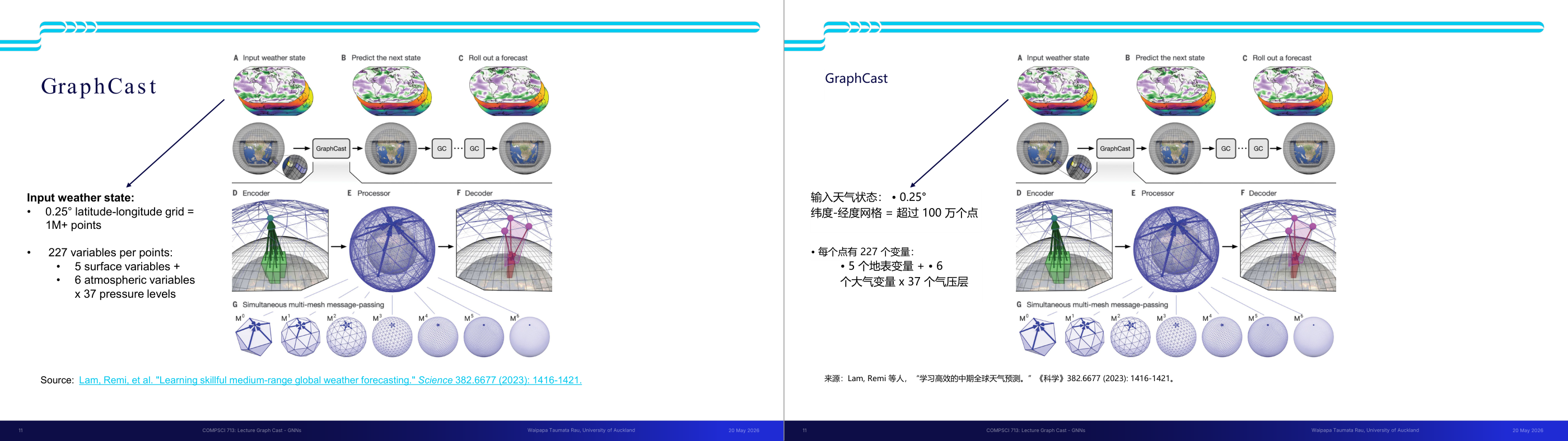
这一页讲的是 GraphCast 模型用于全球中期天气预测的流程。主要包括输入天气状态、预测下一状态以及滚动生成预测结果。
这一页讲的是 GraphCast 模型如何进行全球中期天气预测。首先,输入天气状态是一个基于 0.25° 纬度-经度网格的全球数据集,包含超过一百万个点,每个点有 227 个变量,包括 5 个地表变量和 6 个大气变量,这些大气变量还分布于 37 个压力层。接着,模型通过三个主要步骤完成预测:A 部分表示输入天气状态,B 部分预测下一状态,C 部分将预测结果滚动展开生成完整的天气预报。下方的流程图详细展示了模型的结构:D 是编码器(Encoder),将输入数据转化为图结构;E 是处理器(Processor),通过多网格消息传递机制进行图计算;F 是解码器(Decoder),将图结构转化为预测结果。多网格消息传递机制通过不同分辨率的网格逐步处理数据,提升预测精度。这种方法的重要性在于它能够高效处理复杂的全球天气数据,生成准确的中期天气预测。

这一页讲的是 Graphs 和 GNNs 的内容来源和致谢,引用了两本权威资源。
这一页讲的是 Graphs 和 GNNs 的内容来源和致谢部分,明确指出幻灯片中的内容和插图主要来自两本权威资源:一本是《Understanding Deep Learning》一书,由 Prince S. J. 撰写,出版于 MIT Press;另一个是斯坦福大学的课程 CS224W《Machine Learning with Graphs》。这些资源为学习图结构和图神经网络(Graph Neural Networks, GNNs)提供了重要的理论和实践支持。致谢部分强调了这些资源的引用和适配,体现了学术工作的严谨性和对原作者的尊重。了解这些资源的出处有助于学生深入学习相关主题,同时也为进一步阅读和研究提供了方向。
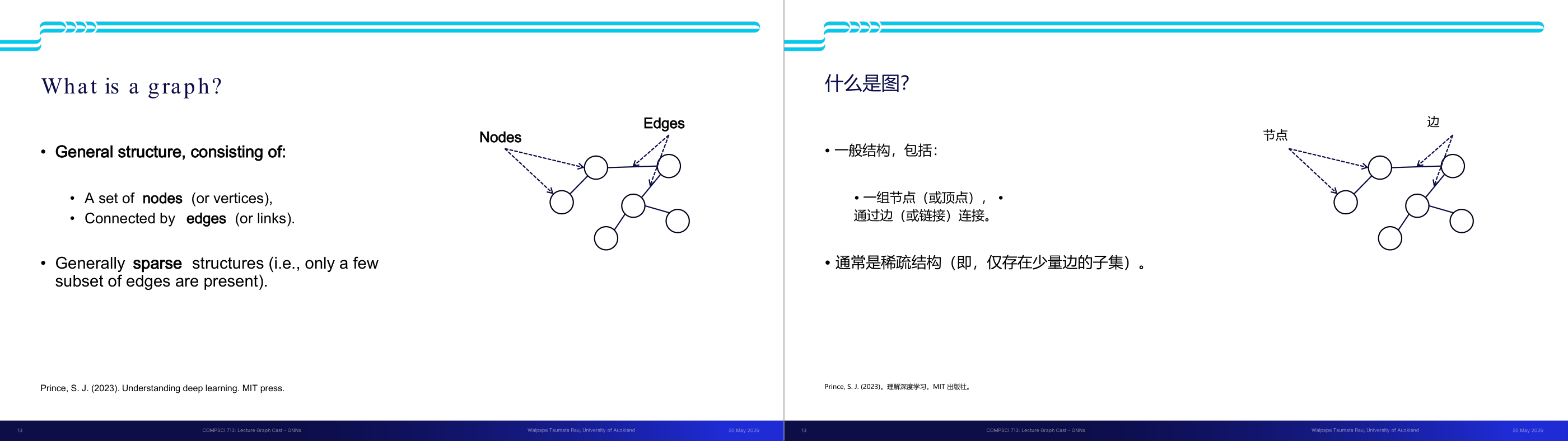
这一页讲的是图 (graph) 的定义和基本结构,包括节点 (nodes) 和边 (edges),以及图通常是稀疏结构。
这一页讲的是图 (graph) 的定义和基本结构。图由节点 (nodes 或 vertices) 和边 (edges 或 links) 组成,节点表示对象,边表示对象之间的关系或连接。图的结构通常是稀疏的 (sparse),即边的数量远少于节点之间可能的最大连接数。这种稀疏性使得图在处理复杂网络关系时更高效。右侧的示意图展示了一个简单的图结构,其中圆形表示节点,箭头表示边,边可以是有向的 (directed) 或无向的 (undirected)。图的应用非常广泛,例如社交网络中的用户关系、知识图谱中的实体连接等。稀疏图的特点在实际中非常重要,因为它减少了存储和计算的复杂度,同时保留了关键的连接信息。
这一页讲的是图(Graph)的基本数学定义。图是一种非常通用的数据结构,由两个核心元素组成:节点(nodes,也叫 vertices)和边(edges,也叫 links)。节点代表实体,边代表实体之间的关系。图的一个重要特性是稀疏性(sparse):真实世界中大多数图的边数远小于节点数的平方,即不是每对节点之间都有连接。理解图结构对 GNN 至关重要,因为 GNN 的所有操作都建立在这个基础上。和数组、序列、矩阵等数据结构相比,图没有固定的空间排列顺序,这也是为什么需要特殊的神经网络架构来处理它。举个例子:在社交网络里,每个用户是一个节点,两个用户互相关注就是一条边;在 GraphCast 里,每个大气格点是一个节点,相邻格点之间的气象相互作用是边。考试里这页通常作为基础概念题出现,考查能否正确区分节点和边,以及为什么图结构是稀疏的。易错点:不要把图(Graph)和统计里的图表(Chart/Plot)混淆,这里的 Graph 是图论中的概念。
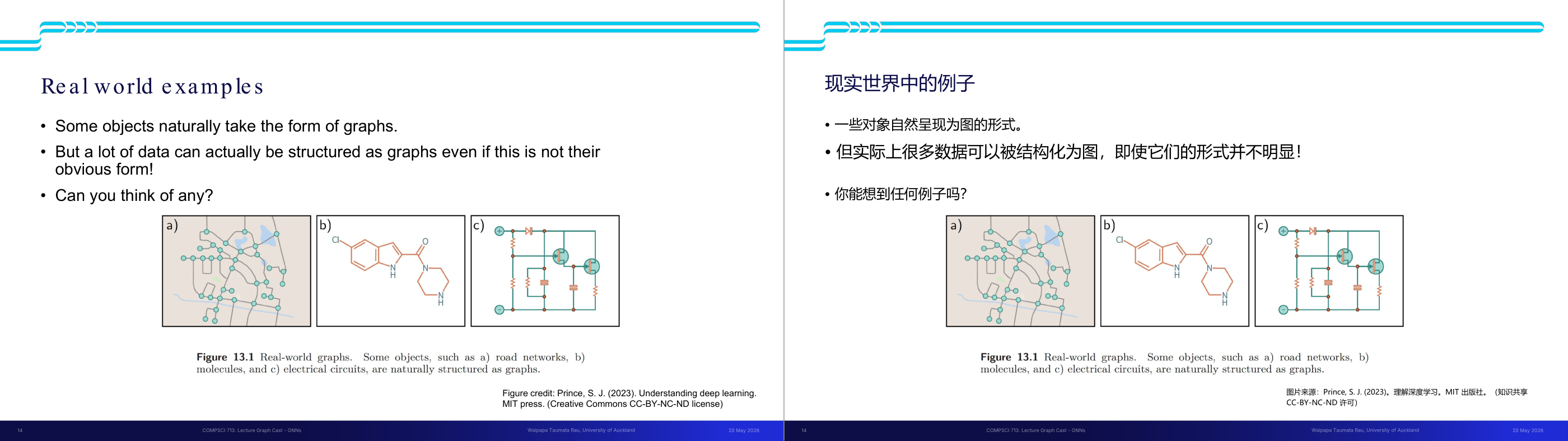
这一页讲的是现实生活中图(graph)的应用示例,包括道路网络、分子结构和电路图。强调许多数据可以被结构化为图,即使它们的形式并不显而易见。
这一页讲的是现实生活中图(graph)的应用示例。图可以用来表示许多自然存在的对象,比如道路网络、分子结构和电路图。幻灯片展示了三个具体例子:a) 道路网络,这是一种典型的图结构,节点表示交叉路口,边表示道路连接;b) 分子结构,化学分子可以用图来表示,原子是节点,化学键是边;c) 电路图,电路中的元件如电阻、电容和晶体管可以作为节点,连接它们的导线是边。这些例子说明了图的广泛应用。图结构的优势在于它能清晰地表示对象之间的关系和连接方式。比如,通过分析道路网络图,可以优化交通流量;通过分子图,可以研究分子特性;而电路图则便于设计和分析电路性能。这些图结构在机器学习中也很重要,尤其是图神经网络(GNNs),可以处理复杂的图数据并提取有用的特征。

这一页讲的是现实世界中图结构的应用。主要例子包括社交网络、科学文献、维基百科等,展示如何用节点和边表示数据关系。
这一页讲的是图结构在现实世界中的应用。首先,许多对象天然可以表示为图结构,例如社交网络中,节点代表人,边代表人与人之间的友谊关系。科学文献中,节点是论文,边是引用关系。维基百科中,节点是文章,边是文章间的超链接。此外,还包括计算机程序,节点表示语法标记或变量,边表示变量间的计算关系;几何点云中,节点是点,边是点之间的连接;场景表示中,节点是场景中的元素,边是元素之间的空间关系。这些例子说明,即使数据的表面形式不是图结构,也可以通过图的方式来建模,从而揭示数据中的关系和结构。例如,研究社交网络中的用户行为可以通过分析节点和边的分布模式来实现。这种方法在数据分析和机器学习中非常重要,因为它能帮助我们理解复杂系统的内部关系。

这一页讲的是图的类型,包括无向图/有向图、异构图/同构图、单图/多图,以及知识图谱、几何图和层次图等。
这一页讲的是图的类型。首先,无向图(Undirected graphs)和有向图(Directed graphs)区别在于边是否有方向,例如图 a 展示了一个社交网络,连接是对称的,属于无向图;而图 b 是一个引用网络,连接是单向的,属于有向图。其次,异构图(Heterogeneous graphs)和同构图(Homogeneous graphs)区别在于节点是否表示不同类型的实体,例如图 c 是一个异构图,节点表示人、地点和公司,边表示不同关系如供应商或居住地。再次,单图(Single graphs)和多图(Multi graphs)区别在于两节点之间是否可以有多条边。最后,知识图谱(Knowledge graphs)、几何图(Geometric graphs)和层次图(Hierarchical graphs)是特定应用中的图类型,例如图 d 是几何图,节点表示空间中的点;图 e 是层次图,展示了房间、桌子和灯的结构关系。这些图的类型在不同领域有重要应用,例如社交网络分析、推荐系统和空间数据处理。
这一页讲的是图数据在真实世界中的广泛例子,以及如何把看似不是图的数据也建模成图结构。这是理解 GNN 应用范围的关键。页面列举了几类经典图数据:社交网络(节点是人,边是朋友关系);科学文献(节点是论文,边是引用关系);Wikipedia(节点是文章,边是超链接);计算机程序(节点是变量,边是涉及这些变量的计算操作);几何点云(节点是空间中的点,边是连接相邻近点的线段);场景表示(节点是场景元素,边是空间关系)。这里的关键洞见是:很多数据「天然就是图」,但更多数据可以被「构造成图」来利用图结构的表达能力。比如图像可以把每个像素当节点,相邻像素之间连边(第 18 页有专门展示);分子可以把原子当节点,化学键当边。这说明 GNN 的应用范围远超「社交网络分析」这一个领域,药物发现、交通预测、推荐系统都可以用 GNN 建模。考试可能会给一个新的应用场景,要求你识别节点和边分别对应什么,以及应该用什么类型的 GNN 任务(节点分类、边预测还是图分类)。

这一页讲的是图(Graph)的表示方法,包括节点和边的嵌入,以及邻接矩阵的定义和作用。
这一页讲的是图(Graph)的表示方法,重点在于如何将图形式化表示以应用于深度学习。首先,节点和边的嵌入(Node and edge embeddings)是图表示的重要部分,节点和边可以包含信息并被编码,例如图中的每个节点和边都可以有特定的特征向量。其次,邻接矩阵(Adjacency matrix)是图表示的核心,它是一个二值矩阵,用来编码节点之间的连接关系。如果矩阵中某元素为1,则表示对应的两个节点之间有边存在。幻灯片中的图例展示了一个包含六个节点和七条边的图(a),并通过邻接矩阵(b)表示节点间的连接关系,同时节点数据矩阵(c)和边数据矩阵(d)分别存储节点和边的嵌入信息。幻灯片还提出了两个问题:邻接矩阵是否总是对称的,以及对角线元素是否总是0。这启发我们思考无向图和有向图的邻接矩阵性质,以及自环的存在对矩阵表示的影响。
这一页讲的是图的几种主要类型,理解这些类型对选择合适的 GNN 变体非常重要。第一种区别是有向图(Directed graph)和无向图(Undirected graph):有向图的边有方向,比如网页之间的超链接(A 链接到 B 不等于 B 链接到 A);无向图的边无方向,比如朋友关系(A 和 B 是朋友是双向的)。第二种区别是同质图(Homogeneous graph)和异质图(Heterogeneous graph):同质图里所有节点代表同一类实体,异质图里节点可以代表不同类型的实体,比如一个图里同时有「用户」节点和「商品」节点,边代表「购买」关系。第三种区别是单图(Single graph)和多重图(Multi graph):多重图允许两个节点之间有多条边,比如两个城市之间既有铁路又有公路。此外还有知识图谱(Knowledge graph)、几何图(Geometric graph)、层级图(Hierarchical graph)等特殊形式。考试里这页考查较轻,但在分析具体应用时需要能识别是哪种类型的图,以及有向/无向对邻接矩阵对称性的影响(有向图邻接矩阵不一定对称,无向图必然对称)。易错点:无向图的邻接矩阵一定是对称的,对角线一般为 0(除非允许自环)。
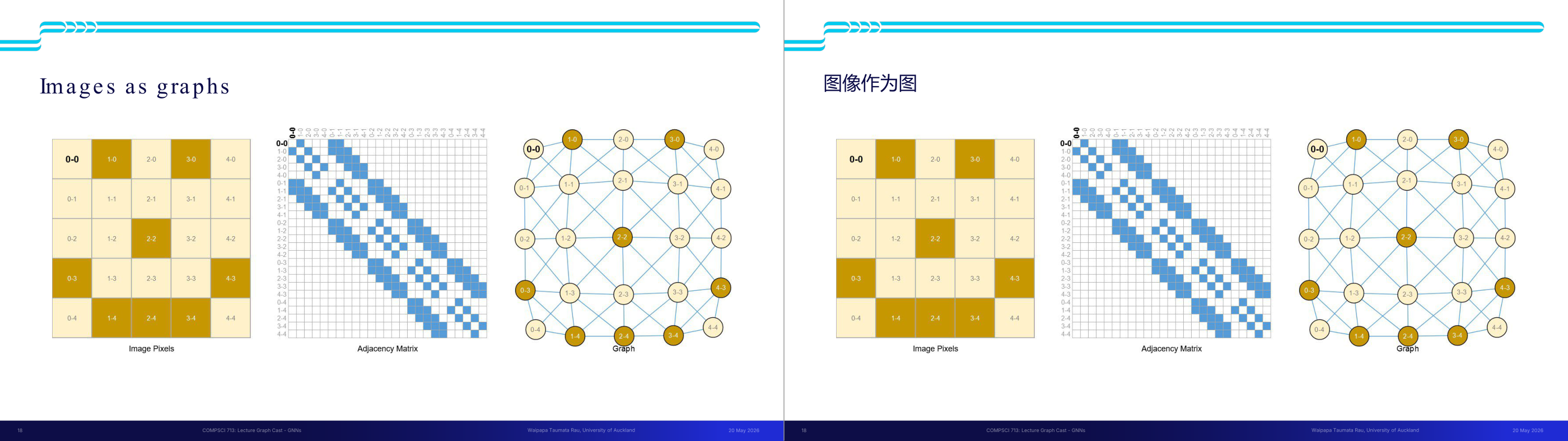
这一页讲的是图像如何被表示为图 (Graphs),包括像素矩阵、邻接矩阵和图结构。
这一页讲的是图像可以被表示为图 (Graphs) 的方法。左侧是一个像素矩阵 (Image Pixels),每个单元格表示图像中的一个像素,位置通过行列坐标标识。中间是邻接矩阵 (Adjacency Matrix),它用来表示像素之间的连接关系,蓝色方块表示两个像素之间存在连接。右侧是图结构 (Graph),将像素作为节点,用边表示像素之间的关系。图结构可以将图像的空间信息转化为节点和边的形式,便于图神经网络 (Graph Neural Networks, GNNs) 处理。邻接矩阵的稀疏性反映了图像中像素的局部连接特点,例如相邻像素更可能有边连接。这种表示方式在图像处理任务中非常重要,尤其是当图像需要结合空间结构信息进行分析时,例如分割或目标检测。
这一页讲的是图的形式化表示方法,这是 GNN 能处理图数据的数学基础。图有两类关键的表示:第一是节点嵌入(node embeddings)和边嵌入(edge embeddings),即用向量来编码每个节点或每条边所携带的特征信息;第二是邻接矩阵(adjacency matrix),用来编码图的连接结构——邻接矩阵 A 是一个 N 乘 N 的矩阵(N 为节点数),若节点 i 和节点 j 之间有边,则 A[i][j] 等于 1,否则为 0。两个关键问题值得记住:邻接矩阵是否对称?对于无向图是对称的,有向图不一定;对角线是否为 0?如果图中没有自环(self-loop)则为 0,但在 GCN 的 Kipf & Welling 公式里会人工加上自环(即让 A 加上单位矩阵 I),使对角线变为 1。节点的特征矩阵通常记作 X,是一个 N 乘 d 的矩阵(d 是特征维度)。这两个输入 A 和 X 合起来就是 GNN 的完整输入。举例:在 GraphCast 里,X 是每个大气格点的气象变量,A 表示哪些格点之间有相互影响的边。考试高频考点:能写出邻接矩阵的含义,能判断对称性,以及理解为什么需要加自环。

这一页讲的是邻接矩阵 (Adjacency Matrix) 在图中作为上下文的作用。邻接矩阵 A 编码了图中节点间步长为 1 的路径频率,A 的高次幂表示步长为 L 的路径频率。通过矩阵与节点表示相乘,可以得到节点与邻居节点的关系信息。
这一页讲的是邻接矩阵 (Adjacency Matrix) 在图中的应用及其作为上下文的作用。邻接矩阵 A 的每个元素表示节点之间步长为 1 的路径频率,而 A 的 L 次幂 (A^L) 表示步长为 L 的路径频率。这种矩阵可以帮助我们理解图中节点之间的连接关系。幻灯片中展示了一个图 (图 a),以及对应的邻接矩阵 A (图 b) 和 A^2 (图 c)。图 b 的矩阵 A 记录了直接相连的节点关系,而图 c 的矩阵 A^2 记录了步长为 2 的路径频率。图 d 和 e 展示了如何通过矩阵乘法将节点表示与邻接矩阵结合,得到节点与其邻居节点的关系信息。例如,图 f 中通过 A^2 与节点 6 的表示相乘,可以得到从节点 6 到其他节点的步长为 2 的路径频率,显示可以通过节点 5、7 和 8 回到原节点。这种方法在图神经网络 (Graph Neural Networks) 中非常重要,因为它能有效捕捉节点的局部上下文和关系结构。
这一页讲的是邻接矩阵作为图上下文信息传递的工具,是理解 GNN 消息传递机制的理论基础。核心结论是:邻接矩阵 A 的一次幂包含长度为 1 的游走(walk)信息,即直接邻居;A 的 L 次幂(A 的 L 次方)包含长度为 L 的游走信息,即 L 跳以内可达的节点信息。因此,将一个节点的表示向量左乘邻接矩阵,等价于把所有直接邻居的信息汇聚到这个节点上——这正是 GNN 消息传递(message passing)的数学本质。直觉上理解:在社交网络里,A 乘以用户特征向量就相当于把每个用户的一阶朋友的信息聚合进来;A 的平方乘以特征向量则相当于把二阶朋友(朋友的朋友)的信息聚合进来。GNN 叠加 K 层就相当于聚合了 K 跳邻域内的所有信息。这一页是理解为什么 GNN 能「感知」图结构的关键。考试可能考:解释一个 K 层 GNN 的感受野(receptive field)是什么,答案是以该节点为中心、K 跳以内的子图。易错点:「游走长度 L」不等于「最短路径长度 L」,游走允许重复经过节点。

这一页讲的是节点索引的排列对图结构的影响。重点包括:节点索引是任意的,改变索引不会影响图的本质;图处理应对索引排列不敏感,否则结果会依赖索引选择。
这一页讲的是节点索引的排列(Permutation of node indices)。首先,节点索引在图中是任意的,改变节点的编号顺序不会改变图的结构性质。这与图像中的像素或文本中的单词不同,图的本质由节点间的连接关系决定,而不是节点的编号。幻灯片中展示了一个示例图(a)及其对应的邻接矩阵(Adjacency Matrix,b)和节点数据(Node Data,c)。当节点索引重新排列后(d),邻接矩阵(e)和节点数据(f)也随之变化,但图的结构保持不变。这说明图处理算法应该对节点索引的排列不敏感,以确保结果仅依赖图的结构而不是索引的顺序。如果算法对索引排列敏感,结果可能会因索引选择而发生变化,导致不一致或错误的分析。例如,图神经网络(Graph Neural Networks)设计时需要考虑这一点,以保证模型的泛化性和鲁棒性。
这一页讲的是节点索引的任意性以及置换不变性/等变性需求的直觉来源。在图中,节点的编号是任意的,比如同一张社交网络图,你把张三叫做节点 1 还是节点 3,图的结构没有任何本质改变。这和图像(像素位置固定)或文本(词的顺序有意义)完全不同。因此,一个处理图数据的神经网络,其输出结果不应该依赖于节点的编号方式——换句话说,如果你对节点重新编号(置换 permutation),网络要么给出完全一样的结果(置换不变,permutation invariant),要么给出对应地重排的结果(置换等变,permutation equivariant)。这是设计 GNN 的根本动机。如果网络不满足这个性质,那么同一张图只是因为节点编号不同就得到不同的预测结果,这显然是错误的。这一页是后续两页形式化定义的直觉铺垫。考试常考:为什么普通 MLP 不适合直接用在图上?答案就是 MLP 对输入顺序敏感,不满足置换不变/等变性。
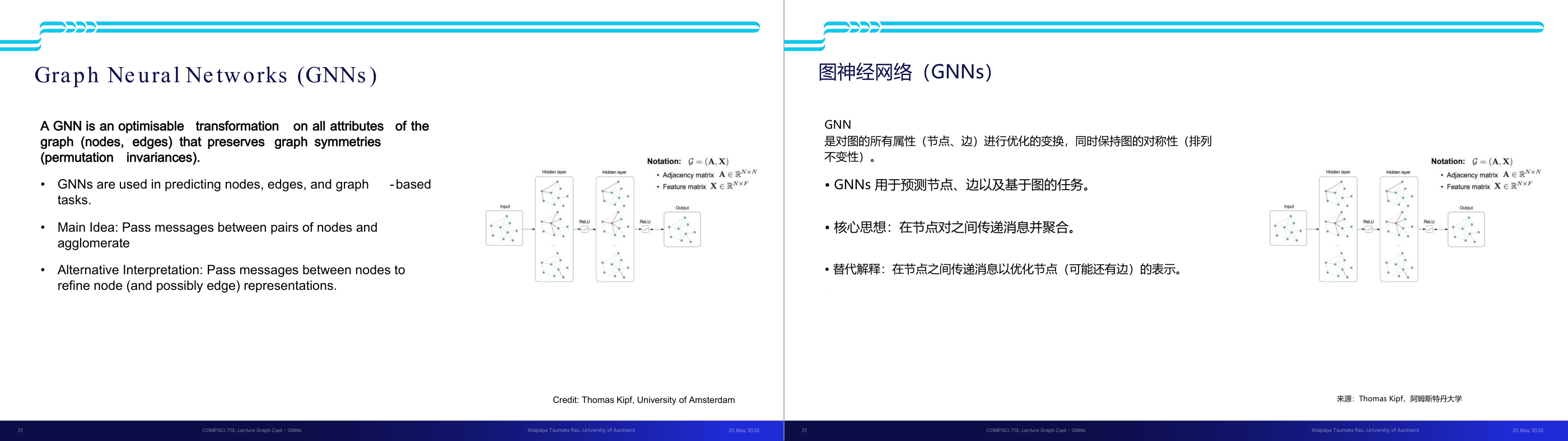
这一页讲的是图神经网络(Graph Neural Networks, GNNs)的基本概念和应用。主要内容包括GNN的核心思想是通过节点间的信息传递来聚合和优化图的特征,同时保持图的对称性(Permutation Invariances)。
这一页讲的是图神经网络(Graph Neural Networks, GNNs)的定义、核心思想及其工作原理。GNN是一种优化图节点和边属性的变换方法,同时保持图的对称性(Permutation Invariances),即图结构在节点排列变化时仍然保持不变。GNN的主要应用包括节点预测、边预测及基于图的任务。核心思想是通过节点间的信息传递(message passing)来聚合图的特征。此外,另一种解释是通过信息传递优化节点和边的表示。右侧流程图展示了GNN的工作流程:输入图包含邻接矩阵(Adjacency Matrix, A)和特征矩阵(Feature Matrix, X),经过多个隐藏层(Hidden Layer)和激活函数(ReLU),最终输出优化后的图表示。这种方法能够有效捕捉图结构中的复杂关系,例如在社交网络中预测用户之间的连接或在分子结构中预测化学性质。
这一页讲的是 GNN 的正式定义和核心原理。GNN 是一种作用于图所有属性(节点和边)上的、可优化的变换,关键要求是它必须保持图的对称性,即置换不变性(permutation invariances)。具体来说:GNN 用于预测节点属性(node-level tasks)、边属性(edge-level tasks)和整图属性(graph-level tasks)。GNN 的主要思想是消息传递(message passing):每个节点收集来自邻居节点的信息,然后聚合(agglomerate)这些信息来更新自己的表示。可以把它类比成 Transformer 里的注意力机制——Transformer 里每个词的表示包含了句子中其他词的上下文;同样地,GNN 里每个节点的表示包含了图中邻居节点的上下文。这一页定义是 GNN 整体框架的总纲。考试会考:GNN 的三类任务(node/edge/graph classification)分别是什么意思,以及消息传递的基本流程。易错点:消息传递里「聚合」和「更新」是两个分开的步骤,聚合是把邻居信息收集起来,更新是用聚合结果修改自己的表示。
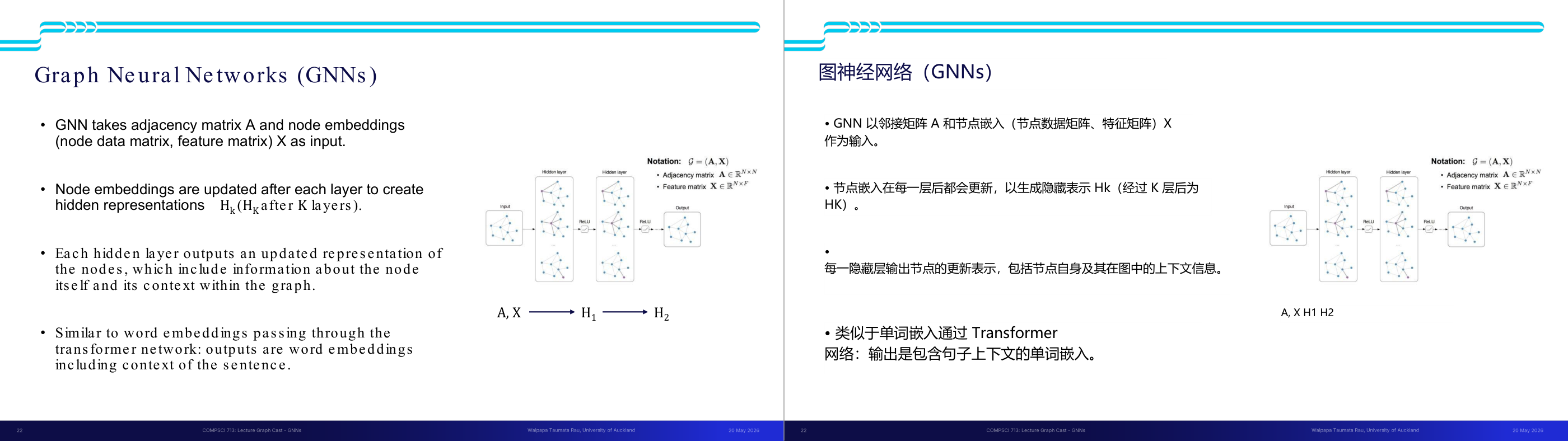
这一页讲的是图神经网络 (GNNs) 的基本原理,包括输入、节点嵌入更新和隐藏层的作用。
这一页讲的是图神经网络 (Graph Neural Networks, GNNs)。GNN 的输入包括邻接矩阵 A 和节点嵌入矩阵 X,其中 A 表示图中节点间的连接关系,X 是节点的特征矩阵。通过多层隐藏层,每一层都会更新节点的嵌入表示 Hk,最终生成包含节点自身信息及其图中上下文关系的嵌入。右侧的流程图展示了 GNN 的处理过程:输入是图结构和特征矩阵,经过两层隐藏层,每层使用 ReLU 激活函数,最终输出更新后的节点嵌入。公式中,A 是 N×N 的邻接矩阵,X 是 N×F 的特征矩阵,N 是节点数,F 是特征维度。类似于 Transformer 网络中的词嵌入,GNN 的输出也能捕捉上下文信息,例如节点在图中的关系。
这一页讲的是 GNN 的计算流程:输入是什么,每一层输出什么,以及和 Transformer 的类比。GNN 接受两个输入:邻接矩阵 A(描述图的连接结构)和节点特征矩阵 X(每个节点的初始特征)。经过第一个 GNN 层后,得到隐层表示 H1;经过第二层后得到 H2;经过 K 层后得到 HK。每一层的输出都是更新过的节点嵌入,这些嵌入不仅包含节点自身的信息,还融合了它在图中邻域上下文的信息。层数越多,每个节点能感知到的邻域范围越大(K 层对应 K 跳邻域)。类比 Transformer:Transformer 输入词嵌入,每一层输出包含句子上下文的词表示;GNN 输入节点特征,每一层输出包含图邻域上下文的节点表示。两者都是逐步将全局信息融入局部表示的过程。考试可能考:GNN 和传统 CNN 的区别(CNN 处理规则网格,GNN 处理任意图结构);K 层 GNN 的感受野大小;以及节点嵌入更新的方向。易错点:GNN 每一层输出的维度仍然是 N 个节点,只是每个节点的表示向量内容变了,不是节点数量减少。

这一页讲的是图神经网络 (Graph Neural Networks, GNNs) 的三种主要任务:图分类、节点分类和边预测。图分类通过合并节点嵌入来预测图的类别;节点分类根据节点嵌入预测节点类别;边预测通过邻接节点嵌入判断边是否存在。
这一页讲的是图神经网络 (Graph Neural Networks, GNNs) 的三种主要任务及其应用。首先是图分类 (Graph Classification),它通过处理图的节点嵌入,将这些嵌入合并为一个固定大小的向量,并通过 softmax 函数预测图所属的类别,例如 Class 1、Class 2 或 Class 3。第二个任务是节点分类 (Node Classification),这里每个节点嵌入单独用于分类,图中的节点被分配到不同的类别,例如图中用蓝色和橙色标记的节点分别属于不同类别。最后是边预测 (Edge Prediction),通过计算边两侧节点嵌入的相似性(例如点积),并使用 sigmoid 函数预测边是否存在。这些任务在图数据的分析中非常重要,例如社交网络中的社区检测、分子结构的功能预测以及推荐系统中的关系建模。这张图通过流程图清晰地展示了每种任务的输入、处理过程和输出。
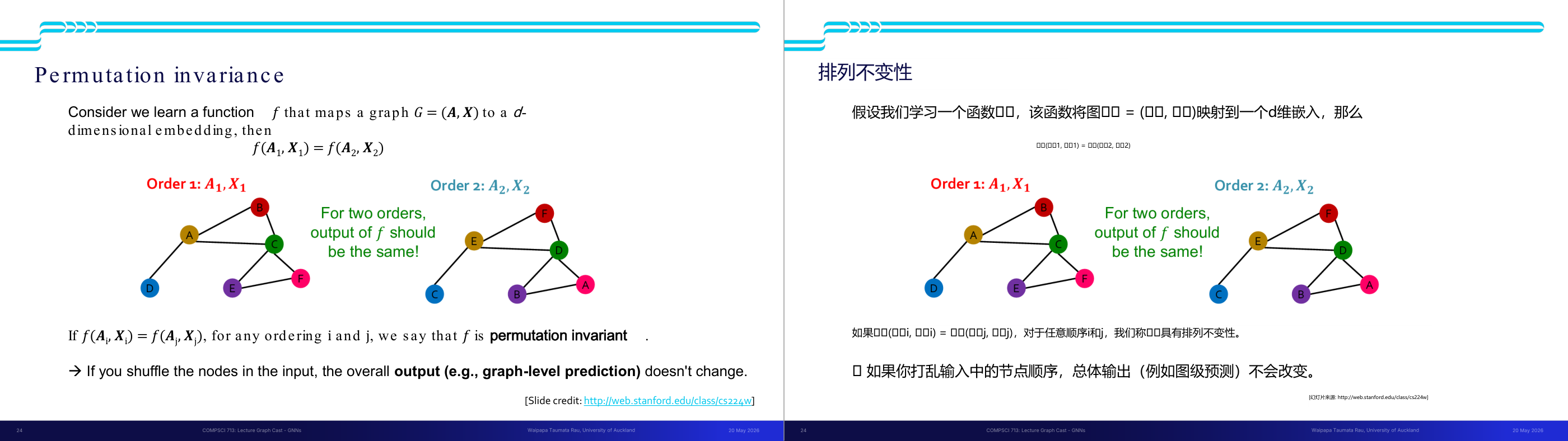
这一页讲的是 Permutation Invariance(排列不变性),重点是函数 f 的输出对于输入节点顺序的排列保持不变。
这一页讲的是 Permutation Invariance(排列不变性),即函数 f 映射一个图 G = (A, X) 到一个 d 维嵌入空间时,输出结果与输入节点的排列顺序无关。这里用两个节点排列顺序的例子(Order 1 和 Order 2)说明这一性质:无论节点被如何重新排列,函数 f 的输出都应该保持一致。这种性质对于图神经网络(Graph Neural Networks)非常重要,因为图的结构本质上是无序的,节点的排列方式不应影响模型的预测结果。图中展示了两种排列方式,A1 和 X1,以及 A2 和 X2,强调了 f(A1, X1) = f(A2, X2)。这意味着即使输入节点被随机打乱,整体输出(例如图级预测)不会改变。这种不变性确保了模型能够正确处理图数据的无序特性,从而提高泛化能力和鲁棒性。
这一页讲的是置换不变性(permutation invariance)的正式数学定义。设 f 是一个把图 G 等于 (A, X) 映射到 d 维嵌入的函数,如果对任意两种节点排序 i 和 j,都有 f(A_i, X_i) 等于 f(A_j, X_j),那么 f 就是置换不变的。用更直白的话说:你把图里的节点随意重新编号,整图级别的输出(比如图分类的类别标签或图的全局嵌入)保持不变。这是图级别任务(graph-level prediction)所需要的性质。直觉:一张分子图,不管你怎么给原子编号,这个分子是「有毒」还是「无毒」的预测结果应该一样。注意置换不变性和置换等变性的区别:不变性是输出完全不变(标量或全局向量),等变性是输出随输入的置换而相应变化(节点级向量集合)。这是 GNN 设计的核心约束,也是考试高频考点。考法举例:给出一个 GNN 的任务(节点分类 vs 图分类),问该任务需要哪种性质(节点分类需要等变性,图分类需要不变性)。易错点:置换不变 ≠ 输出对所有输入都一样,它只是说对节点编号的排列方式不敏感。

这一页讲的是 Permutation equivariance,重点是节点嵌入函数在不同节点排列下保持不变性,以及图中展示了两种排列的对比。
这一页讲的是 Permutation equivariance(排列等变性),即一个函数 f 能够将图 G 的每个节点映射到一个 d 维嵌入空间,并且这种嵌入对节点排列顺序不敏感。图中展示了两个不同的节点排列顺序(Order 1 和 Order 2),分别对应 A1, X1 和 A2, X2。无论节点排列如何变化,节点在图中的位置所对应的嵌入向量保持一致。这说明函数 f 满足排列等变性。图中用矩阵表示每个节点的嵌入,矩阵中的行对应节点,列表示嵌入的维度。通过箭头连接,明确展示了两种排列下节点嵌入的一致性。这一属性在图神经网络(Graph Neural Networks, GNNs)中非常重要,因为图的结构通常不依赖于节点的排列顺序。例如,如果我们对一个社交网络中的用户进行分析,用户的嵌入结果应该与输入顺序无关。这种特性确保了模型的鲁棒性和泛化能力。
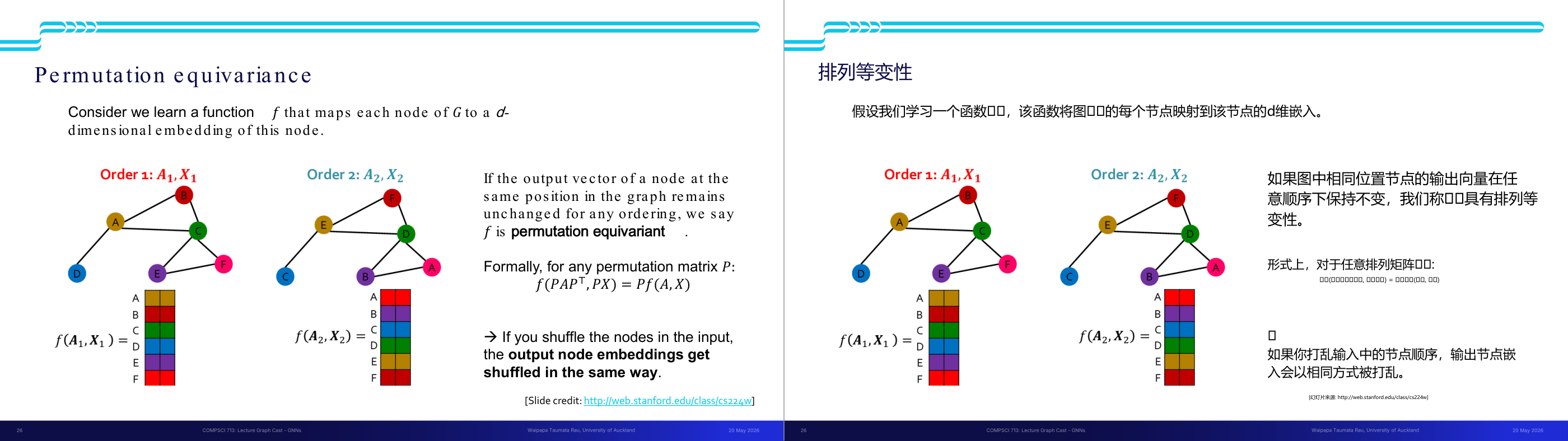
这一页讲的是 Permutation Equivariance(置换等变性)。重点在于节点顺序改变时,输出嵌入保持一致性,以及公式的数学定义。
这一页讲的是 Permutation Equivariance(置换等变性),即一种函数性质:当图中节点的顺序发生变化时,输出的节点嵌入会以相同的方式重新排列。图中展示了两个不同的节点顺序(Order 1 和 Order 2),虽然节点排列不同,但对应的输出嵌入保持了等变性,这说明函数 f 对节点顺序的改变是等变的。公式部分明确了这一性质:对于任意置换矩阵 P,函数 f 满足 f(PAPT, PX) = Pf(A, X)。这意味着输入的节点和图结构被置换后,输出的嵌入也会按照相同的置换规则重新排列。这种性质在图神经网络(Graph Neural Networks, GNNs)中非常重要,因为它确保了模型对图结构的鲁棒性。例如,如果我们将图中节点重新编号,模型的输出不会因为编号方式而改变,而是保持逻辑上的一致性。
这一页讲的是置换等变性(permutation equivariance)的正式数学定义,与置换不变性对应。设 f 把图 G 的每个节点映射到一个 d 维节点嵌入,若对任意置换矩阵 P,都有 f(PAP 的转置, PX) 等于 Pf(A, X),则 f 是置换等变的。用中文口语说就是:左边是先对节点重新编号再计算,右边是先计算再对结果重新排列——两者结果相同。这意味着:如果你把节点 1 和节点 3 互换,那么输出里原本对应节点 1 的嵌入向量会跑到节点 3 的位置,原本对应节点 3 的会跑到节点 1 的位置,但每个节点自身的嵌入内容不会变。这是节点级别任务(node-level prediction,比如节点分类)所需要的性质。公式里 P 是置换矩阵(permutation matrix),P 乘 A 乘 P 的转置是对邻接矩阵做行列同步置换,PX 是对节点特征矩阵做行置换。考试里这两个定义(不变性和等变性)几乎必考,务必能区分:不变性用于图级任务(输出是一个全局值),等变性用于节点级任务(输出是每个节点对应一个值)。
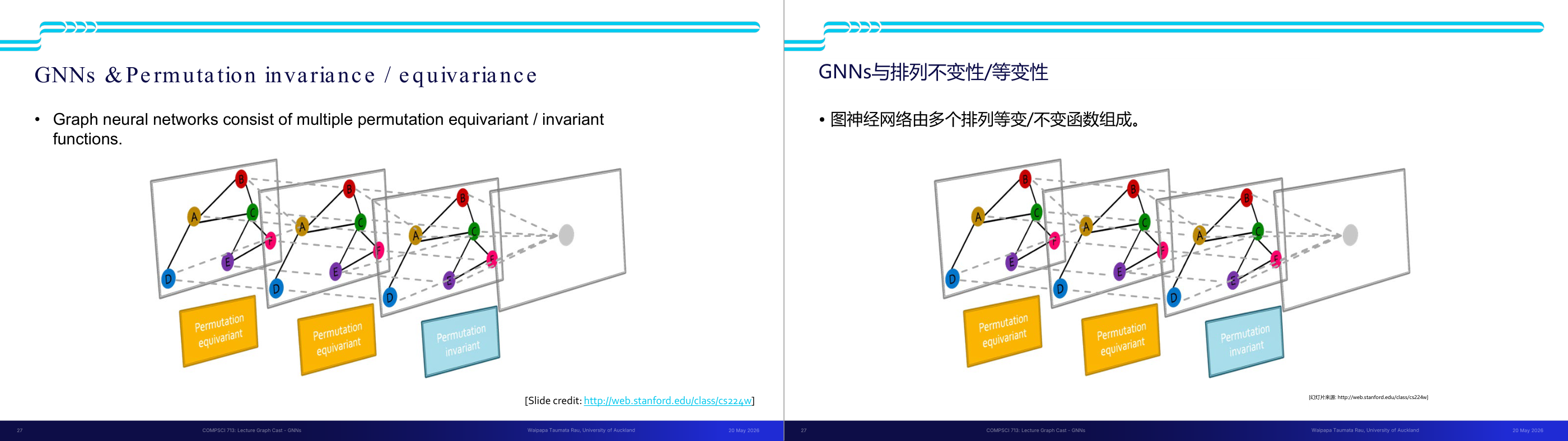
这一页讲的是图神经网络(GNNs)的排列不变性与等变性。主要讨论了它们如何处理图结构数据,保持特定的数学性质。
这一页讲的是图神经网络(Graph Neural Networks, GNNs)中的排列不变性(Permutation Invariance)和排列等变性(Permutation Equivariance)。排列不变性指的是网络输出在节点排列变化时保持不变,而排列等变性则意味着输出会随着输入的排列变化而相应调整。这些性质对于处理图结构数据非常重要,因为图的节点和边没有固定顺序。幻灯片中的图展示了多个图结构在不同排列下的处理过程,强调了 GNNs 能够通过特定的函数保持这些性质。比如,排列等变性可以帮助网络在节点重新编号时仍然正确地捕捉图的结构特征,而排列不变性则确保最终的输出与图的整体性质一致。这些特性使 GNNs 能够在社交网络分析、分子结构预测等任务中表现出色。
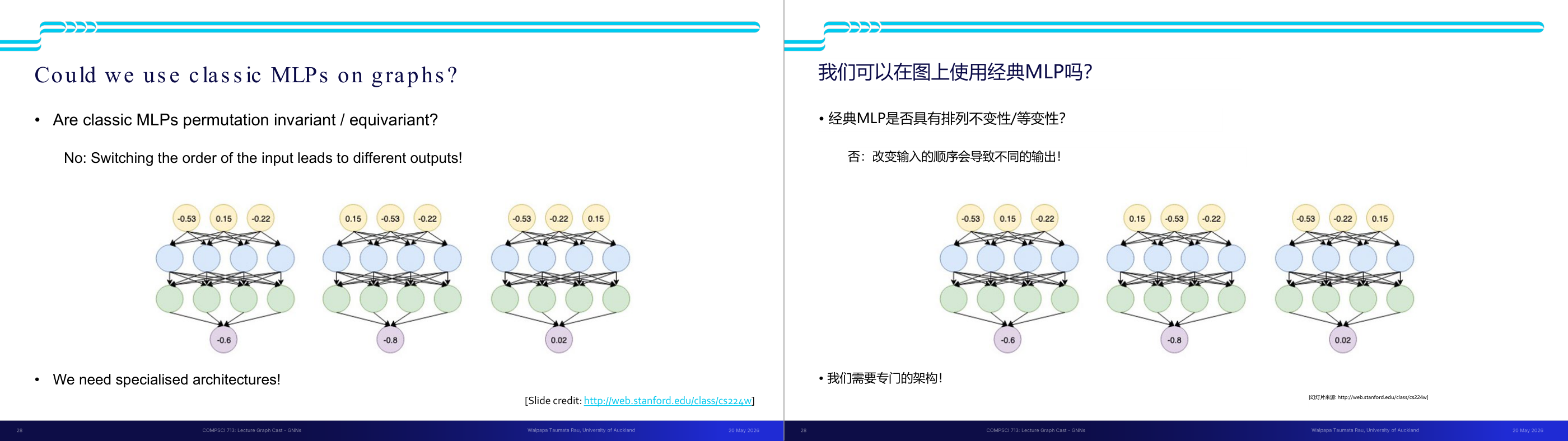
这一页讲的是经典 MLP 是否适用于图结构数据的问题。主要指出 MLP 不具备排列不变性,输入顺序变化会导致输出不同,因此需要专门的架构设计。
这一页讲的是经典 MLP (Multi-Layer Perceptron) 是否适合处理图结构数据。首先,提出了一个关键问题:经典 MLP 是否具有排列不变性 (permutation invariant) 或排列等变性 (permutation equivariant)。答案是否定的,因为当输入节点的顺序发生变化时,MLP 的输出也会随之改变。这一点通过图中的三个示例得到了直观的展示:输入节点顺序不同,最终输出的值也不同,例如从 -0.6 到 -0.8 再到 0.02。图中的黄色节点表示输入,蓝色节点表示隐藏层,绿色节点表示输出层。每个示例展示了输入顺序变化如何影响网络的计算结果。这说明经典 MLP 无法直接处理图数据,因为图数据的节点之间没有固定的顺序。为了适应图结构数据,我们需要设计专门的架构,例如图神经网络 (Graph Neural Networks, GNNs),它们能够处理图的排列不变性问题,更好地捕捉图结构中的关系与特征。
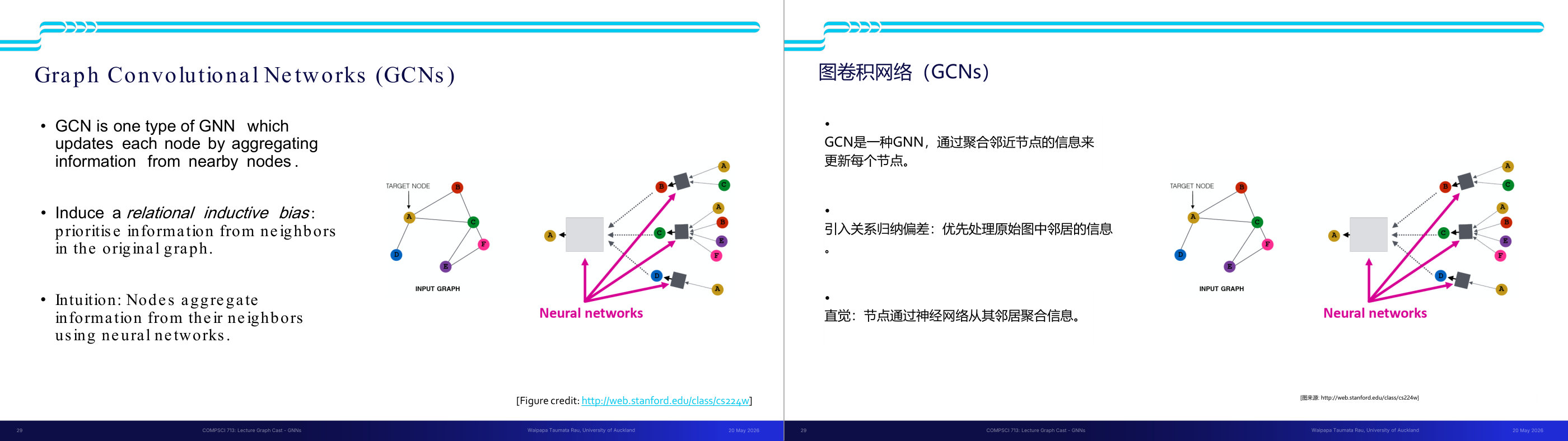
这一页讲的是Graph Convolutional Networks (GCNs)。GCN是一种图神经网络(GNN),通过聚合邻居节点的信息更新目标节点。它强调关系归纳偏差(relational inductive bias),优先处理邻居信息。
这一页讲的是Graph Convolutional Networks (GCNs),它是图神经网络(GNN)的一种。GCN的核心思想是通过聚合邻居节点的信息来更新每个节点的表示。在图中,目标节点会从其邻居节点(如A、B、C等)中提取信息,这些信息通过神经网络进行处理和整合。GCN引入了关系归纳偏差(relational inductive bias),即在图结构中优先考虑邻居节点的信息,从而更好地捕捉局部图的特征。右侧的流程图展示了GCN的工作原理:输入图中的节点通过神经网络聚合邻居节点的信息,生成新的节点表示。例如,节点A会从邻居节点B、C、D等获取信息,经过神经网络处理后更新自己的状态。这种方法在社交网络分析、推荐系统和分子图建模等领域非常重要,因为它能够有效地利用图结构中的关系信息。
这一页讲的是图卷积网络(Graph Convolutional Network,GCN)的基本原理,GCN 是 GNN 中最重要、最经典的一类。GCN 的核心思想是:每个节点通过聚合来自近邻节点的信息来更新自己的表示,这个过程叫做邻域聚合(neighborhood aggregation)。GCN 具有关系归纳偏置(relational inductive bias):它优先考虑原始图中邻居节点的信息,而不是把所有节点一视同仁。这和 CNN 的局部感受野类比:CNN 在图像上只关注像素的局部邻域,GCN 在图上只关注节点的图结构邻域。直觉:在 GraphCast 里,某个大气格点的未来天气状态,主要由它周围格点的当前状态决定,而不是地球另一侧的格点——这正是 GCN 归纳偏置的体现。每一个 GCN 层扩展感受野一跳,K 层 GCN 就能看到 K 跳邻域内的信息。考试常考:GCN 和普通 MLP 的区别(GCN 利用图结构/邻域聚合,MLP 忽略图结构);GCN 的归纳偏置是什么(优先近邻信息)。易错点:GCN 是 GNN 的一个子类,不是所有 GNN 都是 GCN。同时注意为什么 MLP 不适合图任务(不满足置换不变/等变性,而 GCN 通过基于邻域聚合的设计天然满足)。
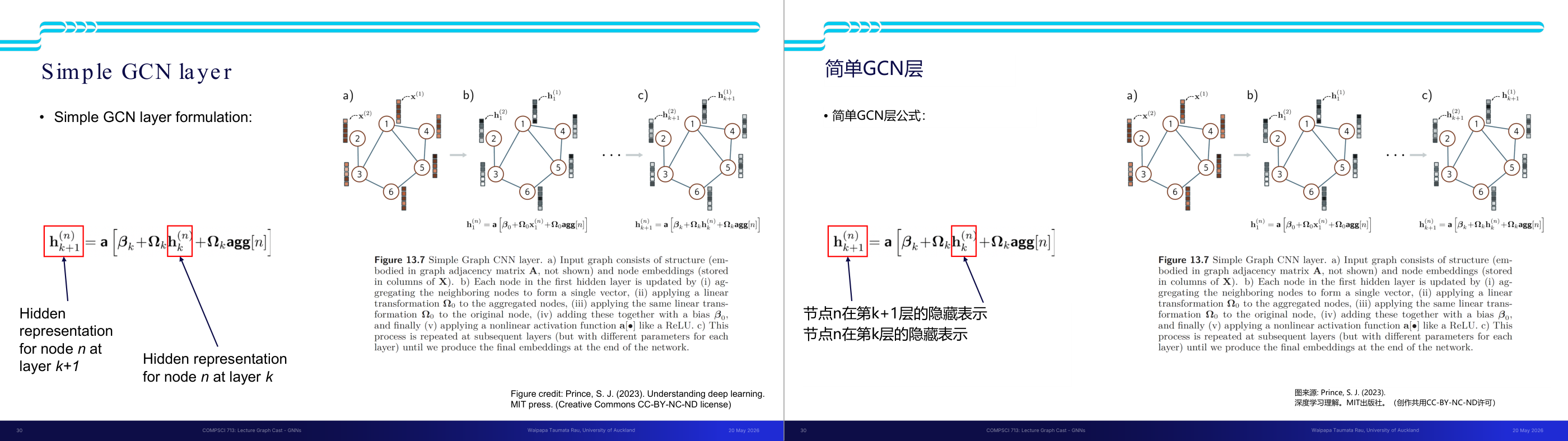
这一页讲的是简单图卷积网络(Simple GCN)的层结构和公式。主要内容包括节点嵌入的更新公式、邻居节点信息的聚合过程,以及图示展示了不同层的计算步骤。
这一页讲的是简单图卷积网络(Simple GCN)的层结构。公式中,节点 n 在第 k+1 层的隐藏表示 h_k+1^(n) 是通过以下步骤得到的:首先,将当前层的节点表示 h_k^(n) 和邻居节点的聚合信息 agg[n] 进行线性变换,分别乘以权重矩阵 Ω_k 和 Ω_kagg,并加上偏置项 β_k;然后通过非线性激活函数 a(•)(例如 ReLU)得到最终的表示。图中展示了 GCN 的计算过程:a) 输入图包含节点嵌入和结构信息;b) 每个节点通过聚合邻居节点信息并应用线性变换得到更新表示;c) 这一过程在后续层中重复,直到最终生成节点的嵌入。这个方法的重要性在于它能够有效捕捉图结构信息并生成节点的高层次表示,用于分类或回归任务。
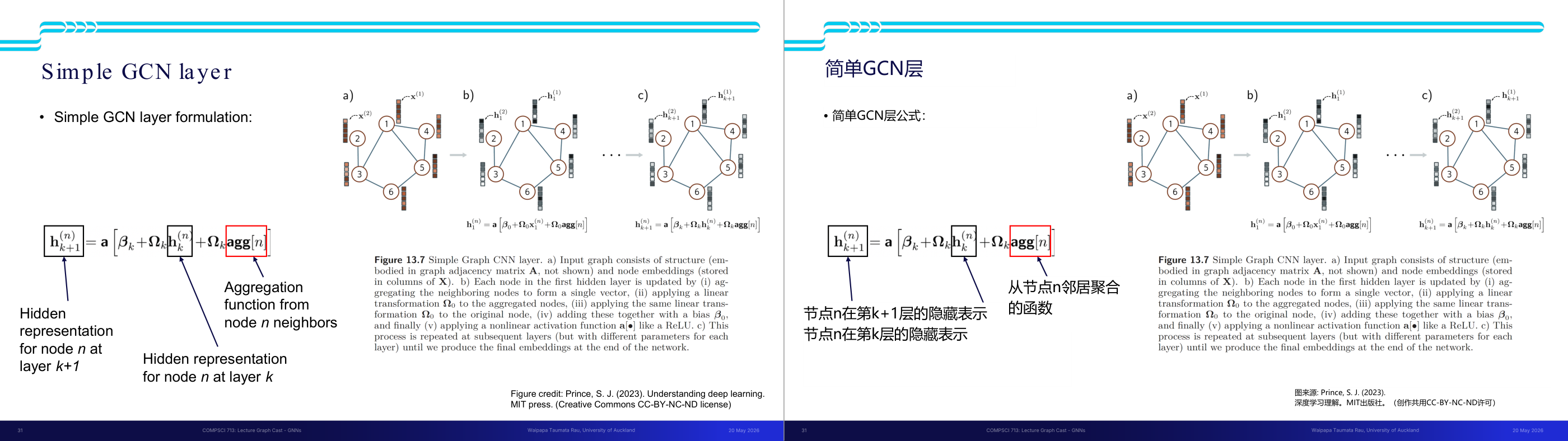
这一页讲的是简单图卷积网络(Simple GCN)的层结构与公式。主要包括节点的隐藏表示更新公式、邻居节点的聚合函数(aggregation function),以及图示展示了公式的应用过程。
这一页讲的是简单图卷积网络(Simple GCN)的层结构,重点是如何通过公式更新节点的隐藏表示。公式中,节点 n 在第 k+1 层的隐藏表示 h^(n)_(k+1) 是通过以下步骤计算的:首先对邻居节点进行聚合(aggregation),然后应用线性变换(Ω_k)到聚合结果与当前层的隐藏表示 h^(n)_k,最后加上偏置项 β_k,并经过非线性激活函数 a(·)。图中展示了公式的应用过程:a) 输入图结构(邻接矩阵 A)和节点嵌入(存储在 X 的列);b) 每个节点通过聚合邻居节点生成一个向量,并应用线性变换;c) 重复这一过程直到生成最终嵌入。聚合过程是图卷积网络的核心,通过邻居的信息整合,捕捉图结构中的关系与特征。这种方法在图数据的任务中非常重要,例如节点分类和图嵌入。
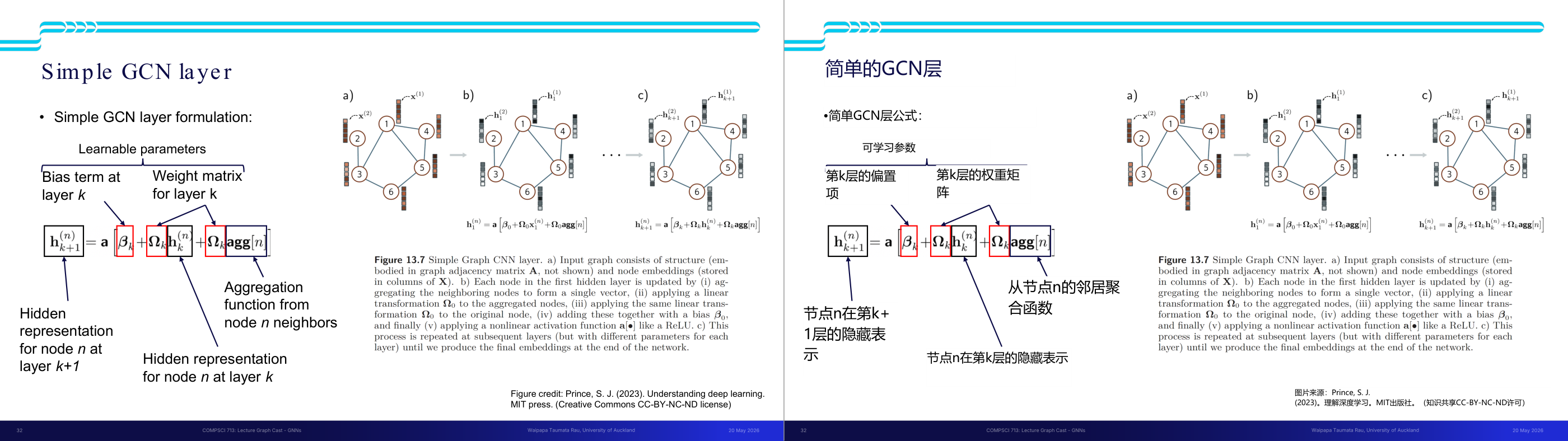
这一页讲的是 Simple GCN layer 的公式和工作原理。主要内容包括公式的组成部分、节点嵌入的更新过程,以及邻居节点的聚合方法。
这一页讲的是 Simple GCN layer 的公式和工作原理。公式表示节点 n 在第 k+1 层的隐藏表示 h(n)k+1 是通过以下步骤计算的:首先,使用邻居节点的嵌入表示进行聚合(aggregation),然后通过权重矩阵 Ωk 对聚合结果进行线性变换,同时加入节点自身的嵌入表示 h(n)k 和偏置项 βk,最后通过非线性激活函数 a(•) 生成最终的嵌入表示。图中展示了节点嵌入的更新过程:a) 输入图包含节点嵌入和结构信息;b) 在第一个隐藏层中,每个节点通过聚合邻居节点的嵌入生成新的表示;c) 更新过程在后续层中重复进行,最终生成网络的嵌入表示。这一方法的核心是通过图结构信息和邻居节点的嵌入来捕获局部图特征,同时通过多层更新逐步提取全局信息。公式中的 learnable parameters 包括权重矩阵 Ωk 和偏置项 βk,它们通过训练优化以适应具体任务。
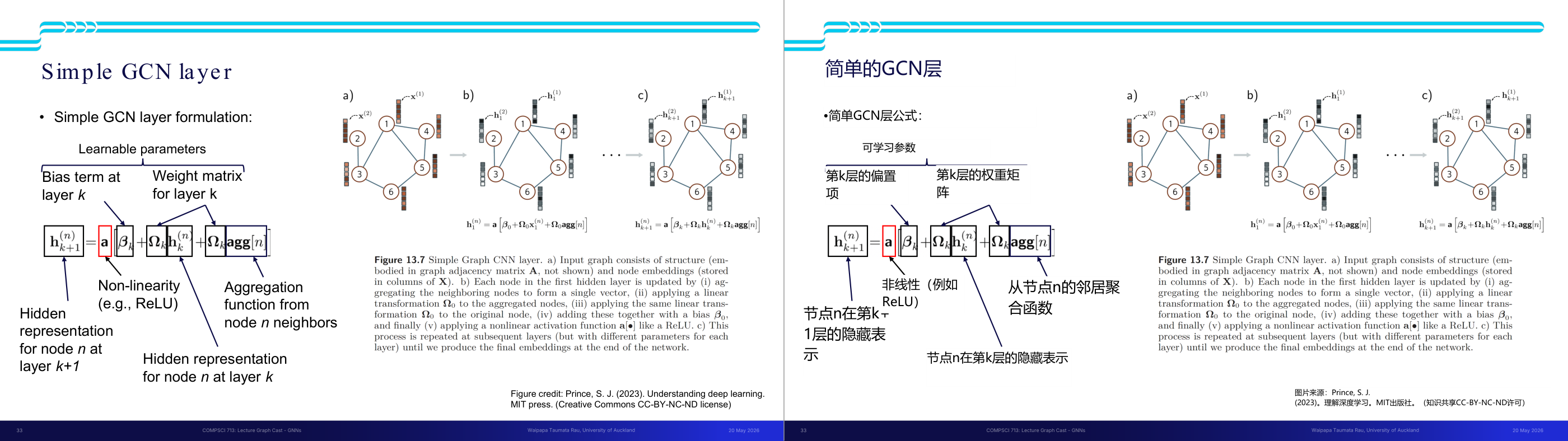
这一页讲的是简单图卷积网络(Simple GCN)的单层结构与公式。主要内容包括公式的组成部分、参数的含义,以及图中节点嵌入的更新流程。
这一页讲的是简单图卷积网络(Simple GCN)的一层结构及其工作原理。公式中,h(n)_k+1 表示第 k+1 层中节点 n 的隐藏表示;β_k 是偏置项,Ω_k 是第 k 层的权重矩阵;agg[n] 是从节点 n 的邻居聚合得到的表示;a 是非线性激活函数,例如 ReLU。公式描述了如何通过线性变换与邻居聚合更新节点嵌入。右侧的图展示了 GCN 的工作流程:a) 输入图由结构信息(邻接矩阵 A)和节点嵌入(存储在 X 的列中)组成;b) 每个节点的嵌入通过聚合邻居节点信息并应用线性变换更新;c) 通过多层递归更新,最终生成网络的嵌入。这个过程在每层重复,但参数不同。简单 GCN 的核心思想是利用图结构和节点特征,通过聚合邻居信息来更新节点表示,从而捕捉图中的局部结构信息。
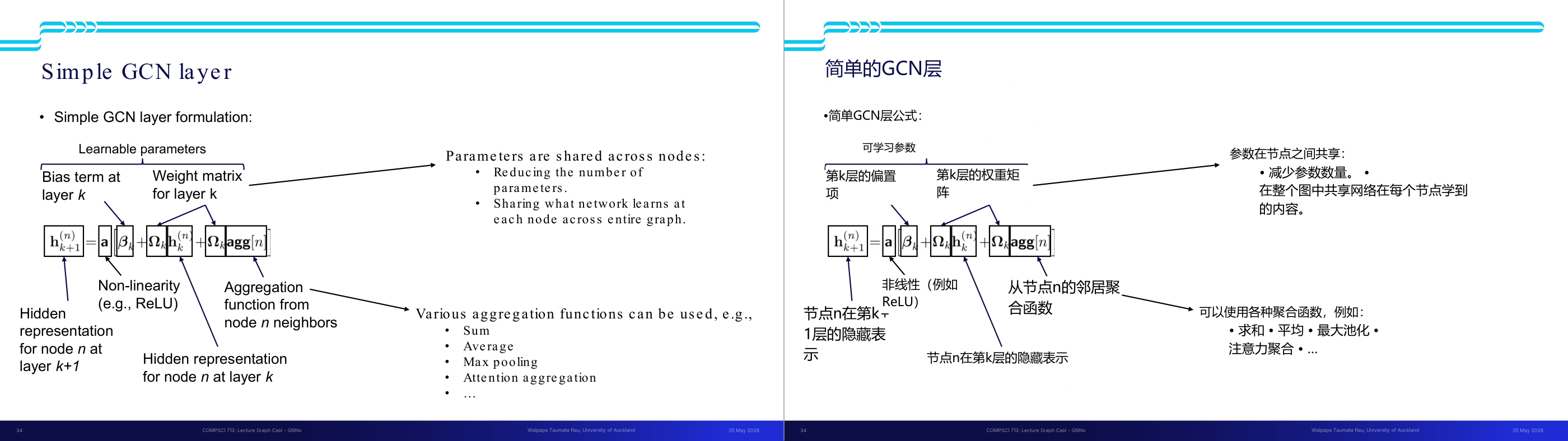
这一页讲的是简单 GCN 层的公式和结构。主要内容包括隐藏表示的更新公式、可学习参数的组成,以及节点间共享参数的优点。
这一页讲的是简单 GCN 层(Graph Convolutional Network layer)的公式和结构。公式描述了如何更新节点 n 在第 k+1 层的隐藏表示 h(n)k+1,它由以下部分组成:节点 n 在第 k 层的隐藏表示 h(n)k、可学习的权重矩阵 Ωk 和偏置项 βk,以及从邻居节点聚合的信息 agg[n]。公式中还包含非线性函数(例如 ReLU)用于引入复杂性和表达能力。聚合函数可以是求和(Sum)、平均(Average)、最大池化(Max pooling)或注意力聚合(Attention aggregation)等多种形式。页面强调了参数在节点间共享的优势,包括减少参数数量和在整个图中共享学习到的特征。此外,这种设计使得模型能够有效处理图结构数据,同时保持计算效率。举例来说,在社交网络中,GCN 层可以帮助预测某个用户的兴趣,通过综合其邻居的兴趣信息来更新表示。
这一页讲的是 GCN 单层的完整公式以及参数共享机制和聚合函数选择,是本讲最核心的公式页之一。GCN 层的更新规则可以用中文口语描述为:节点 n 在第 k 加 1 层的隐藏表示,等于非线性激活函数(比如 ReLU)作用于「节点 n 在第 k 层的自身表示,加上来自所有邻居的聚合表示,然后乘以共享权重矩阵,再加上偏置项」。这里有两个关键设计:第一,参数共享(parameter sharing)——权重矩阵 W 和偏置 b 对图中所有节点是共享的,这大幅减少了参数量,也让网络学到的模式能推广到图的任意部分。这和 CNN 里卷积核在整张图像上共享是同一个道理。第二,聚合函数(aggregation function)可以有多种选择:求和(Sum)、平均(Average)、最大池化(Max pooling)、注意力聚合(Attention aggregation)等。不同聚合方式有不同特性:Sum 对邻居数量敏感,Average 对邻居数量归一化,Max pooling 提取最显著特征,Attention 能学习哪些邻居更重要。考试常考:GCN 参数共享的意义(减少参数量,学到的模式可复用);列举不少于两种聚合函数并说明差异。易错点:参数共享是跨节点共享,不是跨层共享——每一层有自己独立的 W 和 b。

这一页讲的是 Kipf 和 Welling 提出的图卷积网络 (GCN) 层的更新规则,重点包括节点嵌入矩阵、归一化邻接矩阵和非线性激活函数。
这一页讲的是 Kipf 和 Welling 提出的图卷积网络 (GCN) 层的更新规则。公式展示了如何从第 l 层的节点嵌入矩阵 H^(l) 更新到第 l+1 层的节点嵌入矩阵 H^(l+1)。关键步骤包括:首先,邻接矩阵 A 被加上自环并归一化为 A~,然后结合度矩阵 D~ 的逆平方根进行标准化以捕捉图结构信息。接着,H^(l) 与共享权重矩阵 W^(l) 相乘以进行线性变换,最后通过非线性激活函数 σ(例如 ReLU)进行处理,生成新的嵌入矩阵 H^(l+1)。这一公式的重要性在于它能够有效地捕捉图结构中的局部信息,同时通过层级传播实现信息的全局聚合。归一化处理确保了节点之间的关系不会因度数差异而过度偏倚。例如,在社交网络中,GCN 可以用于预测用户兴趣,通过邻接矩阵和节点嵌入捕捉用户之间的关系。
这一页讲的是 Kipf 和 Welling 在 2016 年提出的经典 GCN 层更新公式,是整个 GNN 领域引用最多的公式之一,必考。完整公式的中文口语版本是:H 的 l 加 1 层,等于激活函数作用于「D 波浪线的负二分之一次方,乘以 A 波浪线,乘以 D 波浪线的负二分之一次方,乘以 H 的 l 层,乘以 W 的 l 层」。拆解各符号的含义:A 波浪线等于 A 加 I,即原始邻接矩阵加上单位矩阵,目的是给每个节点加上自环(self-loop),保证节点在聚合时也把自身信息算进去;D 波浪线是 A 波浪线对应的度矩阵(diagonal degree matrix),即对角线元素是每个节点的度数(含自环);D 的负二分之一次方乘以 A 波浪线乘以 D 的负二分之一次方是对邻接矩阵做对称归一化(symmetric normalization),防止高度节点的特征值爆炸;H 的 l 层是第 l 层的节点嵌入矩阵;W 的 l 层是第 l 层的可学习权重矩阵;激活函数通常是 ReLU。直觉:加自环是因为「我自己的信息也很重要,更新自己时不能只看邻居」;对称归一化是因为「度数大的节点邻居多,平均下来每个邻居的贡献应该少一点,防止数值爆炸」。考试极高频:能解释公式各项含义;能解释为什么要加自环;能解释为什么要做对称归一化。易错点:D 的归一化是 D 的负二分之一次方而非负一次方,这是对称归一化,区别于只从左边或右边归一化的非对称形式。
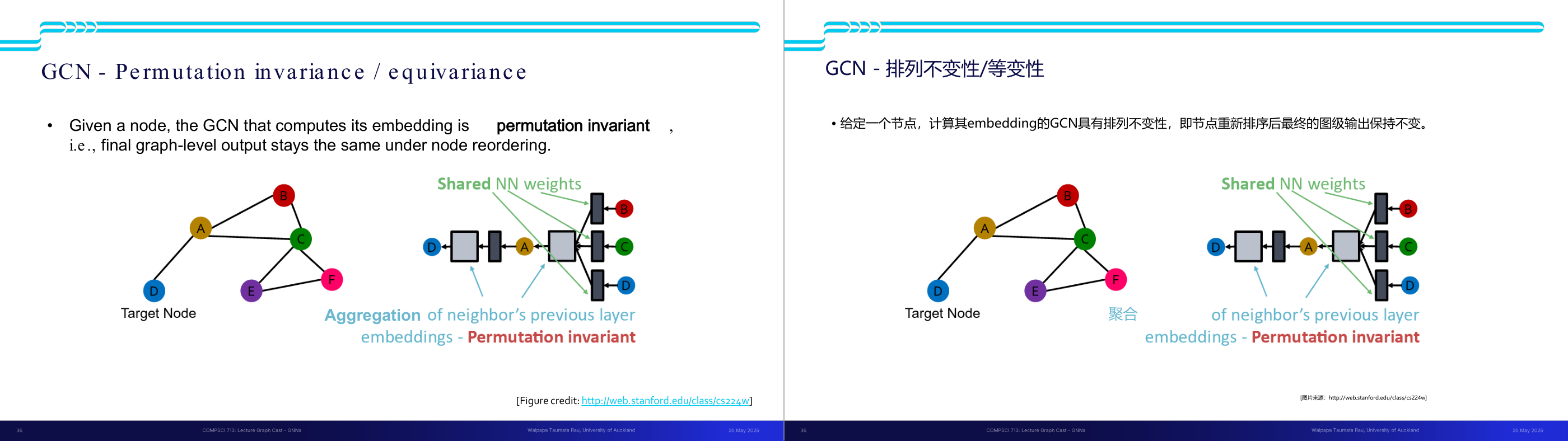
这一页讲的是 GCN 的排列不变性 (Permutation Invariance)。主要内容包括节点嵌入如何保持图级输出不受节点顺序变化的影响,以及邻居嵌入的聚合过程。
这一页讲的是 GCN (Graph Convolutional Network) 的排列不变性 (Permutation Invariance)。关键点是,当给定一个节点时,GCN 计算其嵌入的过程对节点顺序的变化是鲁棒的,即最终的图级输出不会因为节点重新排列而改变。这种特性对于处理图数据非常重要,因为图的结构通常与节点的排列无关。 左侧的图展示了一个目标节点 D 及其邻居节点 (A, B, C, E, F)。右侧的流程图说明了 GCN 如何通过共享的神经网络权重 (Shared NN weights) 来聚合邻居节点的嵌入。这个聚合过程确保了无论邻居节点的排列如何,最终的嵌入结果都是一致的。这种排列不变性是通过对邻居节点的嵌入进行某种无序操作(例如求和或平均)实现的。 例如,在一个社交网络中,如果我们重新排列用户的好友列表,GCN 的输出仍然能够正确反映目标用户的特征。这种不变性使得 GCN 能够更灵活地处理复杂的图数据结构。

这一页讲的是 GCN 的置换不变性与置换等变性。主要内容包括节点特征与嵌入的对齐关系,以及输入节点顺序变化时输出嵌入的对应变化。
这一页讲的是 GCN(Graph Convolutional Network)的置换不变性(Permutation Invariance)和置换等变性(Permutation Equivariance)。GCN 的嵌入计算具有一个重要性质:当图中的输入节点顺序发生置换时,输出嵌入的顺序也会相应置换。这种性质被称为置换等变性。详细推理包括以下几点:第一,输入节点特征矩阵的行与输出嵌入矩阵的行是对齐的;第二,GCN 对某个节点的嵌入计算是位置不变的,即无论节点在输入矩阵中的位置如何,其嵌入计算结果保持一致;第三,当输入节点矩阵发生置换时,输出嵌入矩阵的行也会相应置换,但嵌入内容保持不变。这张幻灯片通过两个示例图展示了这一性质:当节点特征矩阵和邻接矩阵从 X1 和 A1 变为 X2 和 A2 时,嵌入矩阵从 H1 变为 H2,节点的嵌入顺序改变但嵌入内容保持一致。这一性质确保了 GCN 在处理不同节点排列的输入时,能够保持一致性和可靠性。

这一页讲的是 GNN/GCN 的额外学习材料,包括经典论文、综述和课程资源。主要内容包括 GCN 的手动示例、原始论文和全面综述。
这一页讲的是 GNN(Graph Neural Network)和 GCN(Graph Convolutional Network)的额外学习资源,适合深入了解图神经网络的基础和应用。首先,提供了一个 GCN 的手动计算示例链接,展示了原始论文中 GCN 层的公式实现。其次,列出了几篇重要的参考文献:包括 Kipf 和 Welling 在 2016 年提出的 GCN 原始论文,Scarselli 等人在 2008 年提出的 GNN 原始模型论文,以及 Wu 等人在 2020 年发表的关于 GNN 的全面综述,这些文献分别涵盖了图神经网络的基础理论和最新进展。此外,还推荐了 2024 年发表在《Nature Reviews Methods Primers》上的 GNN 专题文章,适合了解最新的研究方法和趋势。最后,提到了斯坦福大学的 CS224W 课程,该课程专注于图机器学习,提供了在线幻灯片和实践笔记本资源。通过这些材料,学生可以系统性地学习图神经网络的理论和实践。

这一页讲的是 AI 与可持续性相关的应用与技术,包括 GraphCast、图结构和图神经网络的作用。
这一页讲的是 AI 在可持续性领域的应用与技术。首先,AI for sustainability 是指利用人工智能解决可持续性问题,例如通过 GraphCast 进行天气预测或极端事件预测。其次,Sustainability of AI 强调开发更加高效、能耗更低的 AI 算法,以应对可持续性挑战。GraphCast 是一种天气预测系统,它通过整合历史数据和图神经网络(Graph Neural Networks)改进传统物理模型的预测效果。图(Graphs)是一种数据结构,通过节点和边连接来表示数据,并且可以通过图嵌入(graph embeddings)进行表示。最后,图神经网络(Graph Neural Networks)可以学习不变性和等变性函数,将图嵌入转换为解决任务的能力,例如图分类、节点分类或边预测。这些技术在提升 AI 应用效率和解决复杂问题方面具有重要意义,例如通过 GraphCast 预测天气可以更好地应对气候变化带来的挑战。