Week 11 - 01 - L_SSL 视图:双语并排 英文 中文 倍速:1x 1.5x 2x
空格=播放/暂停当前页 · Tab=切换 简短/详细/深入 · 红色「深入」为重点页的深度讲解
这一页讲的是自监督学习(Self-supervised Learning)与人工智能的可持续性(Sustainability of AI)。
这一页讲的是自监督学习(Self-supervised Learning)与人工智能的可持续性(Sustainability of AI)。自监督学习是一种机器学习方法,它通过利用数据中的内在结构生成标签,减少对人工标注的依赖。这种方法不仅降低了数据标注成本,还能充分利用大量未标注数据,提高模型的训练效率和性能。人工智能的可持续性则关注如何在资源消耗、环境影响和社会责任之间找到平衡点,以确保技术发展对社会和环境的长期积极影响。这一页的内容可能会进一步探讨自监督学习如何帮助实现人工智能的可持续性,例如通过减少计算资源的使用或降低训练成本。
这一页讲的是致谢部分,提到幻灯片主要来源于两处:Prof Yun Sing Koh 和斯坦福大学的 CS231n 网站。
这一页讲的是致谢部分,主要表达对资源来源的感谢。幻灯片的主要内容来自 Prof Yun Sing Koh,同时部分内容引用了斯坦福大学 CS231n 课程网站(https://cs231n.stanford.edu)。这种致谢通常用于学术演示中,目的是尊重原作者的贡献并标明参考来源。这不仅体现了学术诚信,也为听众提供了额外的学习资源。如果观众对幻灯片内容感兴趣,可以进一步参考 CS231n 网站,该网站是一个关于计算机视觉的经典课程资源。
这一页讲的是自监督学习 (Self-Supervised Learning, SSL) 的课程大纲和学习目标,包括定义、技术和现代方法的影响。
这一页讲的是自监督学习 (Self-Supervised Learning, SSL) 的课程大纲和学习目标。课程内容包括四部分:动机 (Motivation)、概述与定义 (Overview & Definitions)、SSL 技术 (Techniques for SSL) 和总结 (Conclusions)。重点讲解了 SSL 的定义及其关键概念,如下游任务 (Downstream tasks) 和前置任务 (Pretext tasks)。学习目标包括三点:第一,定义 SSL 和相关概念;第二,识别并解释各种基于图像的前置任务;第三,讨论现代 SSL 方法(如 MAE 和 CLIP)的影响。这些内容帮助学生理解 SSL 的核心原理及其在图像任务中的应用。此外,页面提供了相关阅读材料,包括 Meta 的博客链接和一篇关于 SSL 的论文,供学生深入学习。
这一页讲的是监督学习 (Supervised Learning) 与无监督学习 (Unsupervised Learning) 的对比。主要内容包括两者的数据类型、目标以及典型应用示例。
这一页讲的是监督学习 (Supervised Learning) 和无监督学习 (Unsupervised Learning) 的区别与应用。监督学习使用标注数据 (x, y),其中 x 是输入数据,y 是真实标签 (ground-truth label)。其目标是通过大量标注样本学习一个函数 f,使得预测值与真实标签之间的误差最小化。典型应用包括分类 (classification)、回归 (regression)、目标检测 (object detection)、语义分割 (semantic segmentation) 和图像字幕生成 (image captioning)。无监督学习则仅使用输入数据 x,没有标签。其目标是发现数据中的隐藏结构或模式。常见应用包括聚类 (clustering)、降维 (dimensionality reduction)、特征学习 (feature learning) 和密度估计 (density estimation)。这一页的表格清晰地比较了两种学习方法的核心特点和应用场景,有助于理解两者的适用范围和技术实现的差异。
这一页讲的是监督学习(Supervised Learning)的成本问题及其替代方案。重点包括监督学习的高成本、半监督学习(SSL)的技术及其优势。
这一页讲的是监督学习(Supervised Learning)的成本问题。监督学习需要大量标注数据,例如标注 100 万张图片的成本可能会非常高,因此寻找更高效的学习方法显得尤为重要。为了解决这个问题,半监督学习(Semi-Supervised Learning, SSL)被提出作为一种替代方案。幻灯片列出了 SSL 的主要技术,包括基于图像的预训练任务(Image-based pretext tasks)和现代半监督学习方法(Modern SSL methods)。基于图像的预训练任务通常通过设计简单的任务(例如预测图像的旋转角度或填补图像缺失部分)来学习数据的特征,而现代方法则结合了更高级的技术,如自监督学习(Self-Supervised Learning)和对比学习(Contrastive Learning)。这些技术能够减少对人工标注的依赖,从而降低成本并提高模型的适应性。总的来说,这一页强调了监督学习的局限性及半监督学习的重要性,鼓励探索更高效的数据利用方式。
这一页讲的是监督学习成本高的问题,以及标注大规模数据集的费用计算。
这一页讲的是监督学习(Supervised Learning)成本高的问题,重点分析了标注大规模数据集的费用。假设需要标注 100 万张图片,计算公式为:图片数量(1,000,000 images)乘以每张图片标注时间(10 seconds/image),再转化为小时(1/3600 hour/second),最后乘以标注员的时薪($15/hour)。从公式可以看出,即使数据集较小且标注速度较快,成本仍然显著,约为 41,667 美元。这突出了监督学习中人工标注的高昂费用问题,成为推动半监督学习(Semi-Supervised Learning, SSL)发展的重要动因。幻灯片还提到后续内容将包括 SSL 的定义、技术方法(如基于图像的预训练任务和现代 SSL 方法)及总结。这一页为后续讨论 SSL 提供了背景,强调了降低标注成本的重要性。
这一页讲的是监督学习的高成本问题。通过计算标注 100 万张图片的费用,展示了数据标注的昂贵性,并引出半监督学习(SSL)的重要性。
这一页讲的是监督学习(Supervised Learning)的高成本问题。幻灯片通过一个例子计算了标注 100 万张图片的费用:假设每张图片需要 10 秒标注,标注员的时薪为 15 美元,总成本约为 41,667 美元。这还未考虑额外费用,例如任务设置时间、众包平台费用等,实际成本可能是计算值的三倍甚至更多。这个例子强调了监督学习需要大量标注数据的现实问题,尤其是对于中小型数据集,标注成本可能成为主要障碍。因此,半监督学习(Semi-Supervised Learning, SSL)作为一种减少标注需求的技术显得尤为重要。幻灯片还提到 SSL 的两种主要方法:基于图像的预训练任务(Image-based pretext tasks)和现代 SSL 方法,这些技术旨在利用未标注数据降低成本并提高学习效率。
这一页讲的是监督学习(Supervised Learning)的高成本问题。重点说明标注大规模数据集需要耗费巨额资金,计算示例显示标注 10 亿张图片可能花费超过 4100 万美元。
这一页讲的是监督学习(Supervised Learning)的高成本问题,尤其是数据标注的费用。假设需要标注 10 亿张图片,每张图片标注耗时 10 秒,标注员的时薪为 15 美元,根据公式计算,整体成本约为 41,666,667 美元。这一计算假设包括:每张图片由一个标注员完成、没有额外的福利或税费、没有考虑任务设置时间等。实际上,真实成本可能更高,甚至达到计算结果的三倍以上。这张幻灯片还提到了半监督学习(Semi-Supervised Learning, SSL)的技术,包括基于图片的预训练任务(image-based pretext tasks)和现代半监督学习方法,这些技术旨在减少对大量标注数据的需求,从而降低成本。这一议题的重要性在于推动研究者寻找更高效的学习方法,以应对大规模数据集标注的挑战。
这一页讲的是监督学习(Supervised Learning)并不是人类学习的方式。主要内容包括动机、定义、SSL技术以及结论。
这一页讲的是监督学习(Supervised Learning)并不符合人类的自然学习方式。幻灯片通过婴儿的例子说明,人类在学习过程中并不会对每件事都获得明确的监督或标注,而是通过观察和探索进行自我学习。这引出了自监督学习(Self-Supervised Learning, SSL)的重要性。主要内容包括:动机部分,提出为什么需要研究SSL;定义部分,介绍SSL的基本概念;技术部分,列举了基于图像的预训练任务(Image-based pretext tasks)和现代SSL方法(Modern SSL methods)。最后是结论部分,强调SSL在模拟人类学习方式中的潜力。通过这页内容,我们可以理解SSL的核心思想是减少对人工标注的依赖,促进机器通过自身数据挖掘学习有用的信息。
这一页讲的是 Self-Supervised Learning(自监督学习)的概念和动机。主要内容包括自监督学习的定义、与无监督学习的区别,以及其技术方法。
这一页讲的是 Self-Supervised Learning(自监督学习),强调如何从未标注的原始数据中学习。首先,区分了 Unsupervised Learning(无监督学习)和 Self-Supervised Learning。无监督学习中,模型没有明确的预测目标,这是一种较老的术语,现在使用较少。而自监督学习是通过预测原始数据中的自然信号来训练模型,无需人工标注。幻灯片还提到自监督学习的技术方法,包括基于图像的预训练任务(image-based pretext tasks)和现代的自监督学习方法(modern SSL methods)。这些方法的核心是利用数据内部的结构性信息来设计任务,例如预测图像的某些部分或恢复被遮挡的内容。这种方法的重要性在于减少对人工标注数据的依赖,同时提高模型对未标注数据的学习能力。
这一页讲的是 Self-Supervised Learning(SSL,自监督学习)的核心定义,以及它与 Unsupervised Learning(无监督学习)和 Semi-Supervised Learning(半监督学习)的区别。三者都试图绕开人工标注的瓶颈,但思路不同。无监督学习是最老的说法:模型完全不知道要预测什么,只是去发现数据内部的结构,比如聚类或降维,没有显式的监督信号;这个词如今已经逐渐被 SSL 取代。自监督学习则更聪明——它在原始数据里挖掘「天然存在」的信号当标签,让模型去预测这个信号。比如把图片转 90 度,然后让模型猜原来旋转了多少度;或者把图片一块遮住,让模型猜那块原来长什么样。这些标签完全自动生成,不需要人类标注员。半监督学习则是兼顾两头:用少量有标签数据加上大量无标签数据联合训练,是一种折中方案。考试易错点:很多同学把 SSL 和无监督学习混为一谈。关键区别是:SSL 的训练目标是一个具体的预测任务(pretext task),有明确的 loss 函数和自动生成的伪标签,本质上还是「监督学习的形式」,只是标签来自数据本身而非人工;而无监督学习没有这种显式预测目标。另外注意 SSL 不等于半监督——半监督仍然需要一些人工标注,SSL 的预训练阶段完全不需要。考试如果问「SSL 与 unsupervised learning 的区别」,答案核心是:SSL 有自动生成的监督信号(naturally-occurring signal),用监督目标(如分类、回归)来训练;无监督学习没有这种显式目标。
这一页讲的是自监督学习 (Self-Supervised Learning)。主要内容包括自监督学习的定义、与无监督学习和半监督学习的区别,以及其技术应用方向。
这一页讲的是自监督学习 (Self-Supervised Learning),一种利用未标注数据进行训练的方法。首先,无监督学习 (Unsupervised Learning) 是指模型没有明确的预测目标,通常用于聚类或降维,但现在较少使用。自监督学习的核心思想是从原始数据中提取自然信号作为训练目标,而不依赖人工标注。相比之下,半监督学习 (Semi-Supervised Learning) 则结合了少量标注数据和大量未标注数据进行联合训练。幻灯片还提到自监督学习的技术应用方向,包括基于图像的预任务 (Image-based pretext tasks),如图像修复或拼图,以及现代自监督学习方法,这些技术在处理大规模未标注数据时非常重要。例如,图像预任务可以通过预测遮挡区域的像素值来训练模型,从而学到数据的内在结构。这种方法不仅减少了对人工标注的依赖,还能提升模型在实际任务中的泛化能力。
这一页讲的是 Self-Supervised Learning 的定义与概述。主要内容包括预训练网络的步骤、预文本任务 (pretext task) 的作用,以及编码器和解码器的功能。
这一页讲的是 Self-Supervised Learning(自监督学习)的定义与概述。自监督学习是一种无需人工标注数据的学习方法,利用数据本身的结构生成监督信号。幻灯片展示了预训练网络的第一步:通过一个预文本任务 (pretext task) 来学习特征。输入图像 x 经过编码器 φ 提取出特征 φ(x),然后通过解码器 ψ 生成预测值 y'。最后,通过计算预测值 y' 与真实值 y 的损失 L(y', y),来优化模型。图中的流程图直观地描述了这一过程,强调了编码器和解码器在特征提取和预测中的核心作用。这种方法的优势在于可以利用大量未标注数据进行训练,从而减少对人工标注的依赖。一个例子是利用图像的上下文信息预测遮挡部分,这样的任务可以帮助模型学习有效的特征表示。
这一页讲的是 SSL 的两步训练框架,这是整个自监督学习范式最核心的结构,必须牢牢掌握。第一步叫 pretext task(前置任务/代理任务):用大量无标签数据训练一个 Encoder(编码器)加一个临时 Decoder(解码器)。Encoder 把输入图像 x 映射到特征 phi(x),Decoder 在这个特征基础上做某种预测 y-hat,然后计算预测值和自动生成的伪标签 y 之间的 loss 来更新参数。整个过程不需要任何人工标签。第二步叫 downstream task(下游任务):抛掉 Decoder,只保留训练好的 Encoder,把它迁移到真正关心的任务上(如图像分类、目标检测、语义分割)。在 Encoder 上接一个简单的线性分类器或 KNN,用少量有标签数据微调(finetune)或直接训练顶层。这个框架的核心目标是:预训练加迁移的组合,效果要超过「直接用有标签数据从头训练」。直觉理解:可以把 Encoder 想象成一个「万能视觉理解模块」,pretext task 的作用是逼迫它真正理解图像的语义结构(而不是死记硬背某个具体任务)。考试怎么考:常见题型是「描述 SSL 的训练流程」,回答要包含:pretext task 的定义 + Encoder/Decoder 结构 + 伪标签自动生成 + 下游迁移方式(linear probe / KNN / finetune)。易错点:不要说 SSL 在 downstream task 阶段不需要任何标签,这是错的——下游任务仍然需要少量标签来评估或微调,只是远比从零训练需要的少。
这一页讲的是 Self-Supervised Learning 的概念和流程。主要包括两步:1. 在 pretext task 上预训练网络,2. 将 encoder 转移到 downstream tasks。
这一页讲的是 Self-Supervised Learning(自监督学习)的定义和流程。首先,Step 1 是在 pretext task(预任务)上预训练网络,这种任务不需要监督标签。输入图像 x 经过 encoder(编码器)生成特征表示 φ(x),然后通过 decoder(解码器)预测 y'。预测结果与真实值 y 计算损失函数 L(y', y),从而优化模型。Step 2 是将预训练好的 encoder 转移到 downstream tasks(下游任务),例如图像分类、目标检测和语义分割。此步骤可以通过线性分类器、KNN 或微调实现。图中展示了一个猫的图片作为输入,说明了从特征提取到任务迁移的过程。自监督学习的核心优势是利用无标签数据进行预训练,大幅减少对人工标注的依赖,同时提升模型在下游任务中的表现。
这一页讲的是自监督学习 (Self-Supervised Learning) 的定义与流程。主要包括两步:预训练网络解决无监督任务,以及将编码器迁移到下游任务中。
这一页讲的是自监督学习 (Self-Supervised Learning) 的定义和流程。首先,Step 1 是在一个不需要监督的预文本任务 (pretext task) 上预训练网络。输入图像 x 通过编码器 (Encoder, φ) 提取特征 φ(x),然后通过解码器 (Decoder, ψ) 得到预测结果 y',并计算损失函数 L(y', y)。这种方法的核心是利用数据本身生成监督信号,而不是依赖人工标注。接着,Step 2 是将预训练好的编码器迁移到下游任务 (downstream tasks),通过线性分类器、KNN 或微调 (finetuning) 来完成具体任务。目标是通过预训练和迁移的结合,获得比直接监督预训练或直接训练下游任务更好的效果。图示形象地展示了输入图像如何通过编码器提取特征,并在不同阶段应用于任务。自监督学习的优势在于减少标注数据需求,同时提升模型的泛化能力。
这一页讲的是 pretext-tasks 的类型,分为三类:Generative(生成式)、Discriminative(判别式)和 Multimodal(多模态)。
这一页讲的是 pretext-tasks 的类型,用于自监督学习(SSL)。Generative(生成式)任务是预测或重建输入信号的一部分,包括 Autoencoders(自动编码器,如稀疏、去噪、掩码类型)、Autoregressive(自回归)、GANs(生成对抗网络)、Colorization(图像着色)和 Inpainting(图像修复)。Discriminative(判别式)任务是预测输入信号的某些属性,例如 Context prediction(上下文预测)、Rotation(旋转预测)、Clustering(聚类)和 Contrastive(对比学习)。Multimodal(多模态)任务则结合额外的信号,如视频、3D、声音和语言,与 RGB 图像一起使用。这些任务为自监督学习提供了丰富的训练目标,有助于模型从未标注数据中学习特征。
这一页讲的是 SSL 中 pretext task(代理任务)的分类体系,是本讲的知识地图,分三大类:Generative(生成型)、Discriminative(判别型)和 Multimodal(多模态型)。生成型任务的目标是重建或预测输入信号的一部分,典型例子有:Autoencoder(稀疏/去噪/掩码变体)、自回归模型、GAN、图像着色(Colorization)、图像修补(Inpainting)。这类方法让模型学会"补全"缺失信息,被迫理解图像的局部与全局结构。判别型任务的目标是预测输入信号的某种属性,例子包括:上下文预测(Context prediction)、旋转预测(Rotation)、聚类(Clustering)、对比学习(Contrastive)。这类方法更关注「这个图像属于哪一类变换」而非像素级重建。多模态型任务利用图像之外的额外信号:视频(时序信息)、3D、音频、自然语言文本。CLIP 就是典型的多模态 SSL,用图像-文本对做对比训练。考试怎么考:最常见的题型是「给出一个 SSL 方法,说它属于哪种 pretext task 类别,并解释原因」。比如 MAE 是生成型(重建被遮住的 patch),旋转预测是判别型(4 类分类),CLIP 是多模态型(图文对比)。易错点:对比学习(Contrastive)被归在判别型而非生成型,因为它不重建像素,而是判断两个样本是否匹配。另外要注意「pretext task」和「downstream task」不是同一个层次的分类——pretext 是训练手段,downstream 是评估目标。
这一页讲的是预训练任务(pretext-tasks)的例子及其目标。主要包括图像补全、旋转预测、拼图任务和图像上色。解决这些任务能帮助模型学习有用特征,同时标签可自动生成。
这一页讲的是预训练任务(pretext-tasks)的例子及其目标。预训练任务是自监督学习(SSL)中的一种方法,目标是通过解决特定任务来学习图像的转换或修复损坏的图像。幻灯片列举了四种典型任务:图像补全(image completion)要求模型预测缺失部分;旋转预测(rotation prediction)要求模型判断图像旋转的角度;拼图任务(jigsaw puzzle)要求模型重新排列图像碎片;图像上色(colorisation)则是将灰度图像转换为彩色图像。这些任务的优点在于它们能够帮助模型学习有用的特征(good features),为后续任务提供更好的表示。此外,这些任务的标签可以通过简单的图像操作自动生成,减少了人工标注的成本和复杂性。例如,拼图任务可以通过随机打乱图像块自动生成问题。
这一页讲的是生成式建模 (Generative Modelling)。重点包括学习数据分布 p_data(x),通过模型 p_model(x)生成新样本,并介绍相关目标和方法。
这一页讲的是生成式建模 (Generative Modelling),核心是从训练数据中学习分布 p_data(x),并通过模型 p_model(x)生成与训练数据分布一致的新样本。页面中的流程图展示了两个关键步骤:通过学习过程构建模型 p(x),然后利用该模型进行采样 (sampling),生成新的数据样本。目标包括两点:第一,学习一个模型 p_model(x),使其尽可能接近真实数据分布 p_data(x);第二,从模型 p_model(x)中采样生成新的数据点。这种方法在半监督学习 (SSL) 中非常重要,尤其在图像任务中,常用的技术包括基于图像的预训练任务 (Image-based pretext tasks) 和现代的 SSL 方法 (Modern SSL methods)。例如,给定一些鸟类和飞机的图片,通过生成式建模可以生成新的类似图片,从而扩展数据集。这种技术对于数据稀缺场景以及提升模型泛化能力非常有帮助。
这一页讲的是生成学习 (Generative Learning) 和自监督学习 (Self-supervised Learning) 的区别与定义。主要内容包括两者都从数据中学习,无需人工标注;生成学习关注建模数据分布;自监督学习通过预设任务生成用于下游任务的特征。
这一页讲的是生成学习 (Generative Learning) 和自监督学习 (Self-supervised Learning) 的定义及其主要特点。生成学习的目标是建模数据分布 p_data(x),例如生成逼真的图像。这种方法通过学习数据的统计特性来生成新的样本。相比之下,自监督学习通过解决“预设任务 (pretext tasks)”来生成优秀的特征 (good features),这些特征可以用于下游任务,例如分类或回归。自监督学习的一个关键点是这些预设任务的标签是自动生成的,无需人工标注。举例来说,在图像任务中,可以通过预测图像的旋转角度或填补图像的缺失部分来训练模型。这种方法不仅减少了标注成本,还能为下游任务提供高质量的特征表示。
这一页讲的是生成式学习(Generative Learning)与自监督学习(Self-Supervised Learning)的本质区别,以及「表示学习」(Representation Learning)这个概念的重要性。生成式学习的目标是建模数据分布 p_data(x),使得模型可以从 p_model(x) 中采样出逼真的新数据——核心追求是像素级的真实感。自监督学习则不同:它的终极目标是学出一个好的特征表示(representation),用于下游任务,而非生成逼真图像。页面举了一个非常生动的例子:让人凭记忆画一张美元钞票(左图),再让人对着钞票原件画(右图)。凭记忆画时,人会提取高层语义结构(知道大致布局),但像素细节都错了;对着原件画时,细节精确但并不代表「真正理解了」钞票。这个例子说明:对于分类、检测等下游任务,模型需要的是高层语义特征(high-level semantic features),而不是像素级重建精度。所以 SSL 用 pretext task 来逼迫模型学习有语义含义的表示,而不是追求生成质量。表示学习(Representation Learning)的定义:从原始数据中提取有意义的、抽象的特征,这些特征能捕捉数据的结构、关系和语义,并可以在不同任务中复用。考试易错点:不要把 SSL 和生成模型混淆。生成模型的 loss 关注像素级重建质量;SSL 的 loss 只是手段,目的是特征质量。MAE 虽然也做图像重建,但它是 SSL(重建模糊也没关系,关键是特征好不好用)。
这一页讲的是生成式学习与自监督学习的对比,并用一个简单的例子说明两者的差异。重点包括定义和技术方法。
这一页讲的是生成式学习(Generative Learning)与自监督学习(Self-supervised Learning)的对比,并通过一个例子来说明两者的核心区别。页面上的手绘图展示了一张简单的“美元”图像,并提出问题“Can you recognise this object?”,旨在引导我们思考模型如何理解和生成这样的图像。生成式学习通常关注数据的生成过程,例如从无到有地生成类似图像,而自监督学习则通过设计预训练任务(pretext tasks)来学习数据的结构和特征,比如预测图像的某部分或重建缺失信息。幻灯片还提到自监督学习的技术方法,包括基于图像的预训练任务和现代自监督学习方法,这些技术对提升模型的特征提取能力非常重要。通过这个例子,可以直观理解两种学习方法在任务目标上的差异及其应用场景。
这一页讲的是生成式学习与自监督学习的对比及其示例。主要内容包括高层语义特征的重要性、自监督学习的动机和表示学习的定义。
这一页讲的是生成式学习 (Generative Learning) 与自监督学习 (Self-supervised Learning) 的对比,并通过一个美元纸币的绘图示例来说明这一点。左图展示了从记忆中绘制的美元纸币,右图则是参考真实纸币后绘制的版本。这表明,高层语义特征 (High-level semantic features) 的学习比像素级细节的再现更重要。为了实现这一目标,自监督学习使用预训练任务 (Pretext tasks),例如基于图像的任务,来学习抽象的高层表示。表示学习 (Representation Learning) 的核心是从原始数据中提取有意义的抽象特征,这些特征能够有效捕捉数据的结构、关系和语义,并在不同任务中复用。这种方法不仅提高了模型的泛化能力,还为下游任务提供了更强的支持。例如,在图像分类中,通过自监督学习预训练的模型可以更好地理解图像的语义,而不仅仅是像素的排列。
这一页讲的是如何评估自监督学习方法。重点包括不直接关注自监督任务表现,而是评估特征编码器在下游任务中的表现。
这一页讲的是如何评估自监督学习(Self-Supervised Learning, SSL)方法。首先,评估时通常不直接关注模型在自监督任务中的表现,例如模型是否能完美预测图像旋转并不重要,因为这些任务只是辅助目标,目的是帮助模型学习有用的特征。真正的评估重点是将模型学到的特征编码器(feature encoders)应用到下游任务(downstream target tasks)中,看它们是否能提升这些任务的性能。这种评估方式反映了自监督学习的核心目标,即通过设计预训练任务来学习通用的特征表示,而非完成特定的预训练任务本身。举例来说,如果一个图像分类模型通过自监督学习预训练后能在分类任务中表现更好,就说明其特征编码器是有效的。
这一页讲的是如何评估自监督学习(Self-supervised Learning, SSL)方法。主要内容包括自监督学习的定义、使用无标签数据进行特征提取,以及基于图像的预任务应用。
这一页讲的是如何评估自监督学习(Self-supervised Learning, SSL)方法。自监督学习是一种利用大量无标签数据训练模型的方法,其目标是通过设计预任务(pretext tasks)让模型学习有效的特征表示,例如预测图像的旋转角度。幻灯片中的流程图展示了数据从无标签状态,通过自监督学习生成特征提取器(feature extractor),如卷积神经网络(ConvNet)。此外,图中提到了一种具体的预任务:预测图像旋转角度,这是一种典型的图像预任务方法。通过这些任务,模型可以学习到更好的特征表示,这对于后续的下游任务非常重要。总结来说,评估自监督学习方法的核心是验证其是否能够有效地提取特征并提升模型性能。
这一页讲的是如何评估自监督学习方法。主要内容包括利用大量无标签数据训练特征提取器,以及通过少量有标签数据完成目标任务的评估过程。
这一页讲的是如何评估自监督学习方法。首先,通过自监督学习 (self-supervised learning) 利用大量无标签数据训练一个特征提取器 (feature extractor),例如卷积神经网络 (convnet)。在训练过程中,可以使用预设任务 (pretext tasks),例如预测图像的旋转角度,从而学习到高质量的特征。接下来,在目标任务 (target task) 上使用少量有标签数据进行监督学习 (supervised learning)。具体方法是将一个浅层网络附加到特征提取器上,并用目标任务的少量有标签数据训练该浅层网络,例如分类或检测任务。最后,通过目标任务的性能评估自监督学习方法的效果。图中流程图展示了从无标签数据到目标任务评估的完整过程,并举例说明了图像分类任务中如何使用线性分类器 (linear classifier) 进行评估。这种方法的核心在于减少对大量有标签数据的依赖,同时确保模型在目标任务上的表现。
这一页讲的是自监督学习(SSL)的广泛应用领域,包括计算机视觉、语言建模、语音合成和机器人强化学习。
这一页讲的是自监督学习(SSL)的广泛应用领域,展示了其在多个领域的应用实例。首先,在计算机视觉中,Doersch 等人在 2015 年提出了基于图像的预训练任务,通过预测图像中的局部关系来学习特征。其次,在语言建模领域,GPT-3(Brown 等人,2020)展示了少样本学习的能力,能在极少的训练数据下完成复杂的语言任务。第三,语音合成方面,Wavenet(van den Oord 等人,2016)通过深度神经网络生成高质量的语音,展示了 SSL 在生成任务中的潜力。最后,在机器人强化学习中,Dense Object Net(Florence 和 Manuelli 等人,2018)通过自监督学习建立对象表示,用于机器人操作任务。这些例子表明 SSL 在图像、语言、语音和机器人领域的广泛适用性和重要性,推动了机器学习的前沿发展。
这一页讲的是自监督学习(SSL)中的预训练任务,通过预测图像的旋转角度来训练模型。主要内容包括任务假设和图像示例。
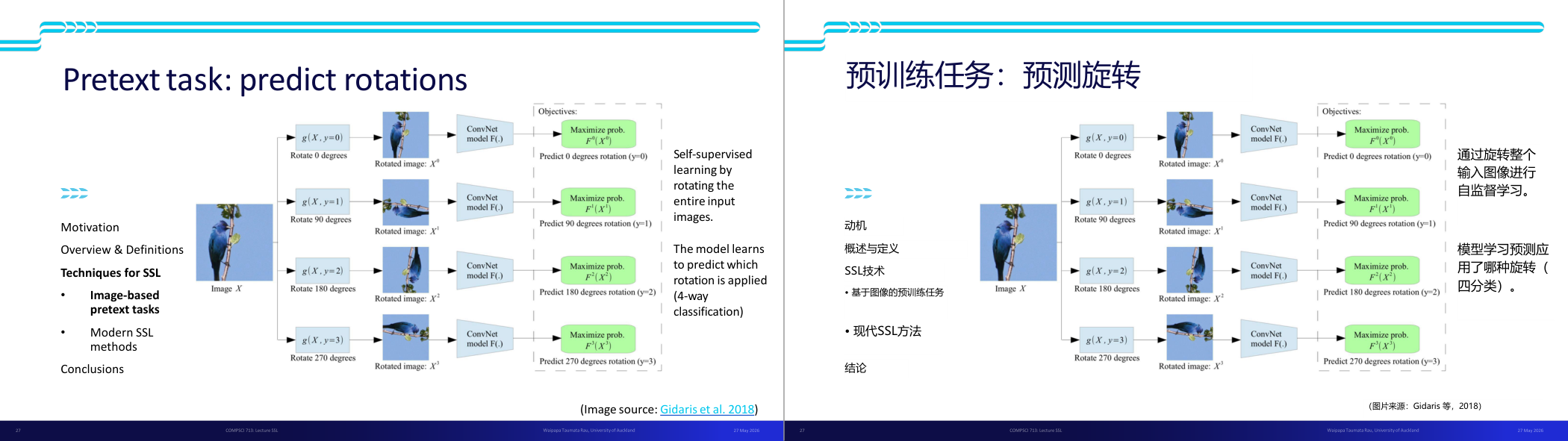
这一页讲的是自监督学习(Self-Supervised Learning, SSL)中的一种预训练任务,称为预测旋转角度(Predict Rotations)。这一任务的核心假设是,模型只有具备对物体在正常状态下的视觉常识(Visual Commonsense),才能正确识别图像的旋转角度。幻灯片中展示了不同旋转角度的图像示例,包括90度、270度、180度和0度旋转。通过设计这样的任务,模型可以学习到图像的结构和语义信息,而无需人工标注数据。这种方法是SSL技术的一部分,目的是通过简单的任务来提取图像特征,为后续的下游任务提供高质量的特征表示。例如,预测图像旋转角度可以帮助模型理解物体的形状和空间关系,从而提高分类或检测任务的性能。这种技术在实际应用中非常重要,因为它能够减少对大规模标注数据的依赖。
这一页讲的是旋转预测(Rotation Prediction)这个经典的 SSL pretext task,来自 Gidaris et al. 2018。思路非常直觉:把输入图像分别旋转 0°、90°、180°、270° 四种角度,让模型做一个 4 分类任务,预测「这张图被旋转了多少」。伪标签完全自动生成——旋转角度本身就是标签,不需要任何人工标注。为什么这个简单的任务能学到有用的特征?关键假设是:要正确判断图像被旋转了多少度,模型必须理解图中物体「正常状态下应该长什么样」。换句话说,模型必须具备一定的视觉常识(visual commonsense),比如狗的头应该朝上、飞机的机翼应该是水平的。这迫使 Encoder 学到语义层面的特征,而不仅仅是低层纹理。实验结果(CIFAR10):SSL 预训练后冻结浅层(conv1+conv2),只用少量有标签数据训练深层(conv3+线性层),分类精度随标签数量提升,证明预训练的特征确实有迁移价值。ImageNet 上的实验也显示,旋转预测 SSL 的迁移效果介于「从头训练(无预训练)」和「有监督 ImageNet 预训练」之间,相当不错。考试怎么考:这个方法代表了判别型 pretext task 的典型思路,考题可能是「解释旋转预测如何成为一个 SSL pretext task」——要答出:自动生成标签 + 4 分类 + 假设模型必须理解物体正常姿态 + 特征迁移到下游。易错点:旋转预测是对整张图做旋转,而非图像局部 patch,这和 jigsaw puzzle 任务不同。
这一页讲的是通过预测图像旋转角度的自监督学习任务。主要内容包括自监督学习的动机、定义,以及一种基于图像的预文本任务:让模型预测图像被旋转的具体角度。
这一页讲的是自监督学习 (Self-Supervised Learning, SSL) 中一种基于图像的预文本任务 (Pretext Task),即预测图像的旋转角度。图中展示了如何通过旋转输入图像来生成不同的训练样本:原始图像 X 被分别旋转 0 度、90 度、180 度和 270 度,生成四种不同的旋转图像 X⁰、X¹、X² 和 X³。模型的任务是通过输入图像预测其被旋转的角度,这实际上是一个四分类问题。这样的设计能够帮助模型学习图像的空间特征和结构信息,而无需依赖人工标注的标签。这种方法的动机是降低对标注数据的依赖,同时提升模型对图像特征的理解能力。举例来说,给定一张鸟的图像,模型需要判断它是原始方向还是被旋转了某个特定角度。这种任务在现代自监督学习中非常重要,能为后续的下游任务提供更好的特征表示。
这一页讲的是自监督学习 (Self-Supervised Learning, SSL) 中的图像预训练任务,通过预测图像旋转角度来训练模型。主要内容包括任务流程和目标。
这一页讲的是自监督学习 (SSL) 的一种预训练任务,称为预测旋转角度 (Predict Rotations)。这一任务的流程是:首先对输入图像进行不同角度的旋转处理(0度、90度、180度、270度),生成四种旋转后的图像。然后将这些图像输入到卷积神经网络模型 (ConvNet model F(.)) 中,模型需要预测每张图像的旋转角度。任务的目标是最大化模型对每种旋转角度的预测概率,例如预测图像旋转为 0 度时的概率最大化。这个任务的核心是通过图像的旋转变换,帮助模型学习图像的特征表示,同时无需使用人工标注的数据,完全依赖输入图像本身的变化。这种方法属于图像预训练任务 (Image-based pretext tasks),是现代自监督学习方法的重要组成部分。图中的流程图清晰展示了从原始图像到旋转图像,再到模型预测的完整过程,并强调了这是一个四分类问题 (4-way classification)。
这一页讲的是在 CIFAR10 数据集上的分类评估,比较了半监督学习和监督学习的表现。图表显示训练样本数量对测试准确率的影响。
这一页讲的是在 CIFAR10 数据集上的分类评估,重点介绍了半监督学习(Self-supervised learning, SSL)与监督学习的对比。右侧的图表展示了随着训练样本数量增加,测试准确率的变化趋势。黄色曲线代表半监督学习方法,蓝色曲线代表监督学习方法。可以看到,半监督学习在样本较少时表现明显优于监督学习,随着样本数量增加,两者的差距逐渐缩小。幻灯片右侧提到,半监督学习冻结了卷积层 conv1 和 conv2,仅对 conv3 和线性层进行训练,并使用部分标注的 CIFAR10 数据进行分类任务。左侧列出了相关技术,包括基于图像的预训练任务(Image-based pretext tasks)和现代半监督学习方法(Modern SSL methods)。这一研究说明了半监督学习在数据不足情况下的优势,并为实际应用提供了指导。
这一页讲的是在 CIFAR10 数据集上的分类性能评估,比较了不同预训练方法对分类、检测和分割任务的影响。
这一页讲的是在 CIFAR10 数据集上的分类性能评估,主要比较了使用 ImageNet 全监督预训练、无预训练以及多种自监督学习(SSL, Self-Supervised Learning)方法的效果。表格列出了不同方法在分类(%mAP)、检测(%mAP)和分割(%mIoU)任务上的性能。表中显示,使用 ImageNet 标签进行全监督预训练的模型性能最高,例如分类任务达到 78.9%。而无预训练的模型(Random 和 Random Rescaled)性能较低,分类任务分别为 53.3% 和 39.2%。此外,多个自监督学习方法(如 RotNet、Jigsaw Puzzles 和 Context Encoders)在性能上介于两者之间,其中 RotNet 的分类性能为 70.87%,表现较为突出。自监督学习的核心思想是通过设计预训练任务(如图像旋转预测)来学习特征,从而减少对人工标注数据的依赖。这张表格说明了自监督学习在减少标注需求的同时,仍能达到较好的性能,是一种重要的研究方向。
这一页讲的是可视化视觉注意力(Visual Attention)的学习结果,比较监督学习模型与自监督学习模型的注意力图。
这一页讲的是可视化视觉注意力的学习结果,重点比较监督学习模型与自监督学习模型的注意力图。页面右侧展示了两组图像,分别是监督学习模型 (a) 和自监督学习模型 (b) 的注意力图。每组图像包含不同卷积层(Conv1 27×27, Conv3 13×13, Conv5 6×6)的注意力分布。通过这些图可以观察到,自监督学习模型在图像中的注意力分布更集中于关键区域,例如人脸、动物的头部等,而监督学习模型的注意力分布相对较分散。这说明自监督学习模型能够更有效地捕捉图像中的重要特征。幻灯片还提到了自监督学习 (SSL) 的技术,包括基于图像的前置任务 (Image-based pretext tasks) 和现代自监督学习方法 (Modern SSL methods),这些技术是实现注意力优化的重要基础。通过这种可视化对比,可以更直观地了解模型的学习效果及其在图像理解中的表现。
这一页讲的是预训练任务中的相对图块位置预测,属于自监督学习(SSL)的技术之一。重点包括图块划分、相对位置预测以及任务设计的示例。
这一页讲的是预训练任务中的相对图块位置预测(pretext task: predict relative patch locations),这是自监督学习(SSL)中的一种图像任务技术。核心思想是将图像划分成多个区域(如图中红色网格标记的1到8块),然后训练模型预测某一区域相对于另一块的相对位置。例如,图中蓝框选定了一个区域(X),目标是预测另一个区域(Y)的位置关系。右侧的示例展示了如何通过问题设计来实现这一任务:给定一个图块,模型需要判断它与其他图块的相对位置。此任务的设计有助于模型学习图像的空间结构和语义信息,而无需人工标注。通过这种方式,模型可以在无监督环境下获得有效的特征表示。这种方法在现代自监督学习中非常重要,因为它能够显著减少对人工标注数据的依赖,同时提高模型的泛化能力。
这一页讲的是自监督学习 (SSL) 的图像预训练任务,特别是“拼图任务”的方法及其流程。主要内容包括任务定义、拼图排列及模型结构。
这一页讲的是自监督学习 (SSL) 中的图像预训练任务,核心是“拼图任务 (Jigsaw Puzzle Task)”的实现方式及其意义。首先,拼图任务是一种图像预训练的技术,通过将图像划分为多个小块并随机打乱顺序,模型需要学习如何正确排列这些块,从而理解图像的整体结构和语义。幻灯片中展示了具体的拼图生成过程:图像被划分为多个区域,随机选择一种排列方式(例如图中的 9,4,6,8,3,2,5,1,7),然后模型需要根据该排列恢复图像块的正确顺序。右侧的流程图展示了模型的结构,输入是打乱的图像块,经过多层卷积网络处理后,最终输出预测的排列顺序。这个任务的目标是让模型在无监督的情况下学习图像的空间关系和特征表示。拼图任务在早期 SSL 中非常重要,因为它为模型提供了一个明确的学习目标,同时不需要人工标注数据。
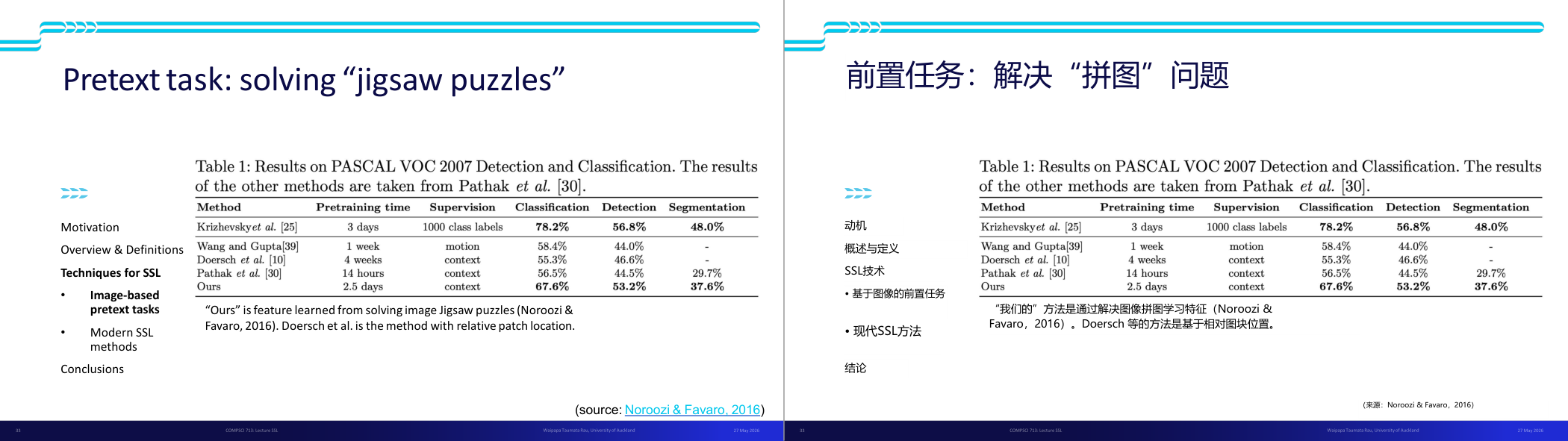
这一页讲的是一种自监督学习(SSL)的预训练任务:拼图问题解决 (jigsaw puzzles)。表格展示了不同方法在 PASCAL VOC 2007 数据集上的分类、检测和分割性能对比。
这一页讲的是自监督学习 (SSL) 中的预训练任务之一——拼图问题解决 (jigsaw puzzles)。这种任务通过打乱图像块并让模型学习如何还原拼图来提取图像的潜在特征。表格展示了几种方法在 PASCAL VOC 2007 数据集上的分类、检测和分割任务性能对比。表格的列包括预训练时间 (Pretraining time)、监督类型 (Supervision)、分类准确率 (Classification)、检测准确率 (Detection) 和分割准确率 (Segmentation)。例如,Krizhevsky et al. 使用了 1000 个类别标签作为监督,分类准确率达到 78.2%,检测为 56.8%,分割为 48.0%。而“我们的方法 (Ours)”通过拼图任务学习特征,预训练时间仅为 2.5 天,分类准确率为 67.6%,检测为 53.2%,分割为 37.6%。相比其他方法,“Ours”在效率和性能之间表现均衡,表明拼图任务是一种有效的图像特征学习方式。这种方法的重要性在于它减少了对标签数据的依赖,同时还能实现较高的任务性能。
这一页讲的是一种自监督学习(SSL)的预训练任务,预测图像中缺失的像素(inpainting)。主要内容包括图像修复任务的原理和其在SSL中的应用。
这一页讲的是一种用于自监督学习(SSL)的预训练任务,即通过预测图像中缺失的像素(inpainting)来学习特征。这种方法属于图像预任务(image-based pretext tasks),其目标是通过填补图像中人为遮挡的区域,迫使模型理解图像的上下文信息,从而学习有用的特征。幻灯片中展示了一个例子:左侧图像中间部分被遮挡,模型通过上下文编码器(Context Encoders)预测并生成完整图像,右侧显示修复后的结果。这种方法的核心在于利用图像上下文关系进行特征学习,而无需大量标注数据。Pathak等人在2016年的研究中提出了这一方法,并证明它在图像生成和自监督特征学习领域的有效性。此类任务为现代SSL方法提供了重要的技术基础,例如用于图像分类、目标检测等任务的预训练。
这一页讲的是预训练任务中的像素预测(inpainting),重点是通过自监督学习(SSL)重建缺失像素。
这一页讲的是预训练任务中的像素预测(inpainting),这是一种用于自监督学习(Self-Supervised Learning, SSL)的图像预训练任务。主要目标是通过模型学习重建图像中缺失的部分。幻灯片中展示了一个典型的编码器-解码器架构:输入图像中有一部分像素被遮挡,编码器提取图像特征,经过通道级全连接层处理后传递给解码器,解码器负责重建缺失的像素部分。图中的流程图表明,模型通过优化重建误差(Loss)来提高预测精度。这种方法的意义在于无需人工标注数据,仅通过图像自身信息即可训练模型,从而有效降低数据标注成本。一个例子是,给定一张部分遮挡的足球比赛图片,模型能够学习还原遮挡区域的内容。这种技术在现代 SSL 方法中具有重要地位,为下游任务提供了高质量的特征表示。
这一页讲的是图像修复评估(Inpainting evaluation),重点包括自监督学习(SSL)中的技术和图像修复的输入与重建过程。
这一页讲的是图像修复评估(Inpainting evaluation),其中包含自监督学习(SSL)的相关技术和图像修复的应用。首先,幻灯片提到图像修复任务通常作为一种 Image-based pretext task,用于自监督学习模型的训练。图像修复的输入是一个带有缺失区域的图像(称为 context),模型的目标是根据上下文信息对缺失部分进行重建。右侧展示了一个具体的例子:左图是输入图像,缺失区域用白色方块表示;右图是模型生成的重建结果,填补了缺失区域。通过这种方式,模型可以学习到图像的结构和语义信息,从而提升其表示能力。此外,幻灯片还提到现代自监督学习方法,这些方法可能结合图像修复任务来进一步优化模型性能。图像修复任务在计算机视觉中非常重要,因为它不仅是一个评估模型能力的工具,还可以应用于实际场景,例如修复损坏的图片或视频。
这一页讲的是通过重建学习图像修复 (inpainting)。重点包括损失函数的定义及其由重建损失和对抗损失组成。
这一页讲的是通过重建学习图像修复 (inpainting)。首先,损失函数 L(x) 被定义为重建损失 L_recon(x) 和对抗损失 L_adv(x) 的结合。重建损失 L_recon(x) 的公式表示为通过掩码 M 选择图像的部分区域,计算原始图像与生成图像之间的差异平方和,目标是让模型生成的图像尽可能接近真实图像。对抗损失 L_adv(x) 的公式则结合了 GAN (生成对抗网络) 的思想,通过最大化判别器 D 对真实图像的预测概率,同时最小化生成器 F 对修复图像的预测概率,使得生成的修复图像更加逼真。页面还提到这属于一种基于图像的预训练任务 (image-based pretext tasks),是现代自监督学习 (SSL) 方法的一部分。这种方法的重要性在于它能够通过无监督学习方式提升模型对图像修复任务的性能,例如填补缺失区域或去除噪声。
这一页讲的是图像修复 (Inpainting) 的评估方法,重点介绍了自监督学习 (SSL) 的技术及其应用。
这一页讲的是图像修复 (Inpainting) 的评估方法,结合自监督学习 (SSL) 技术的应用。首先,幻灯片左侧列出了主要内容,包括动机 (Motivation)、概念定义 (Overview & Definitions)、SSL 技术 (Techniques for SSL),以及结论部分 (Conclusions)。其中,SSL 技术部分特别强调了基于图像的预设任务 (Image-based pretext tasks) 和现代SSL方法 (Modern SSL methods)。右侧的图展示了图像修复的不同方法:输入图像 (Input/context) 是带有缺失区域的图像;重建 (Reconstruction) 是通过传统方法填补缺失区域后的结果;对抗性方法 (Adversarial) 使用生成对抗网络 (GAN) 进行修复;最后是结合重建和对抗性方法 (Recon + Adv) 的结果。从图中可以看出,结合重建和对抗性方法能够生成更自然的修复效果。这些方法对于提升图像修复的质量和自监督学习的应用有重要意义。
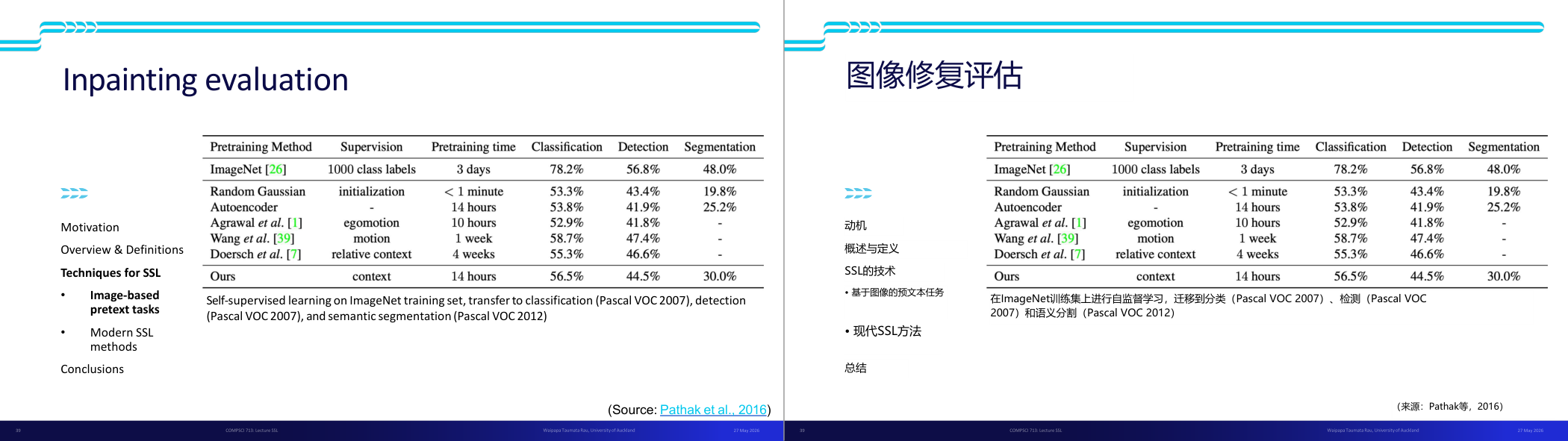
这一页讲的是图像修复评估 (Inpainting evaluation),比较不同预训练方法对分类、检测和分割任务的效果。
这一页讲的是图像修复评估 (Inpainting evaluation)。表格列出了几种预训练方法,包括传统的 ImageNet 预训练和几种自监督学习 (Self-supervised Learning, SSL) 方法。表格中比较了这些方法的监督类型 (Supervision)、预训练时间 (Pretraining time)、以及在分类 (Classification)、检测 (Detection) 和分割 (Segmentation) 任务上的表现。比如,ImageNet 使用 1000 类标签进行监督,预训练时间为 3 天,分类准确率达到 78.2%,检测和分割分别为 56.8% 和 48.0%。相比之下,SSL 方法中,使用随机高斯初始化 (Random Gaussian) 的分类准确率仅为 53.3%,而基于上下文 (context) 的方法表现较好,分类准确率为 56.5%。这一页强调了自监督学习的潜力,尤其是通过减少监督信息需求来实现较好的性能,同时也展示了不同方法在预训练时间和任务表现上的权衡。
这一页讲的是自监督学习中的预训练任务——图像上色 (image colouring)。主要内容包括利用灰度图像预测颜色信息,以及相关的技术框架。
这一页讲的是自监督学习 (SSL) 中的预训练任务之一:图像上色 (image colouring)。这种任务的目标是通过模型从灰度图像 (L channel) 预测颜色信息 (ab channels),从而学习图像的语义特征。图中展示了一个典型的流程:输入灰度图像 X (属于 R^(H×W×1)),通过一个函数 F 转换后,输出预测的颜色信息 Ŷ (属于 R^(H×W×2))。这种任务的意义在于,它能够以无监督方式构造标签,帮助模型学习丰富的特征表示,而无需人工标注数据。图像上色任务属于 image-based pretext tasks 的一种,广泛应用于现代 SSL 方法中。举例来说,给定一张灰度的鱼类图像,模型通过训练可以预测其真实的色彩分布,从而掌握图像内容的上下文信息。
这一页讲的是图像着色 (image colourisation) 的预任务,用于自监督学习 (SSL)。重点包括通过灰度图像预测彩色图像的技术。
这一页讲的是图像着色 (image colourisation) 的预任务,这是自监督学习 (SSL) 中的一种图像任务。预任务的目标是从灰度图像的 L 通道预测彩色图像的 ab 通道。左侧展示了输入的灰度图像,它仅包含 L 通道,表示亮度信息,形状为 H×W×1。通过模型 F,预测彩色图像的 ab 通道,然后将 L 通道与预测的 ab 通道拼接,生成完整的彩色图像 (L, ab)。这种任务的意义在于无需人工标注数据,通过图像本身的结构信息学习特征。图中的流程图清晰展示了从输入到输出的过程,强调了模型 F 的作用。一个例子是给定一张灰度鱼的图像,模型可以预测其真实的彩色版本。这种方法常用于训练深度学习模型以提取图像特征,从而为后续任务提供更好的初始表示。
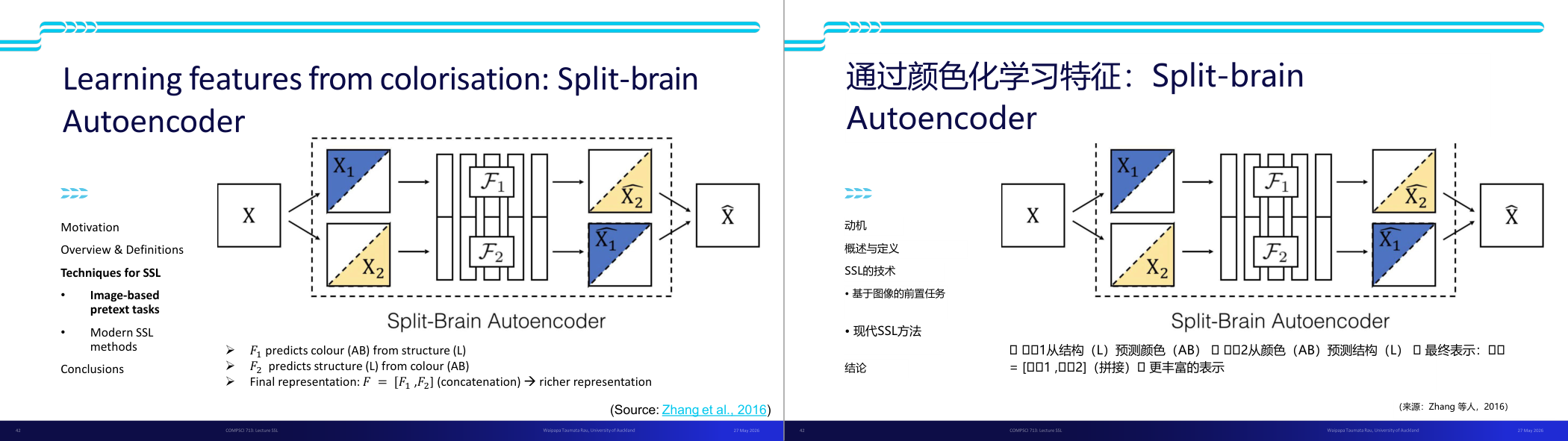
这一页讲的是通过颜色化学习特征的 Split-brain Autoencoder 方法。主要内容包括技术动机、图像预训练任务以及最终特征表示的丰富性。
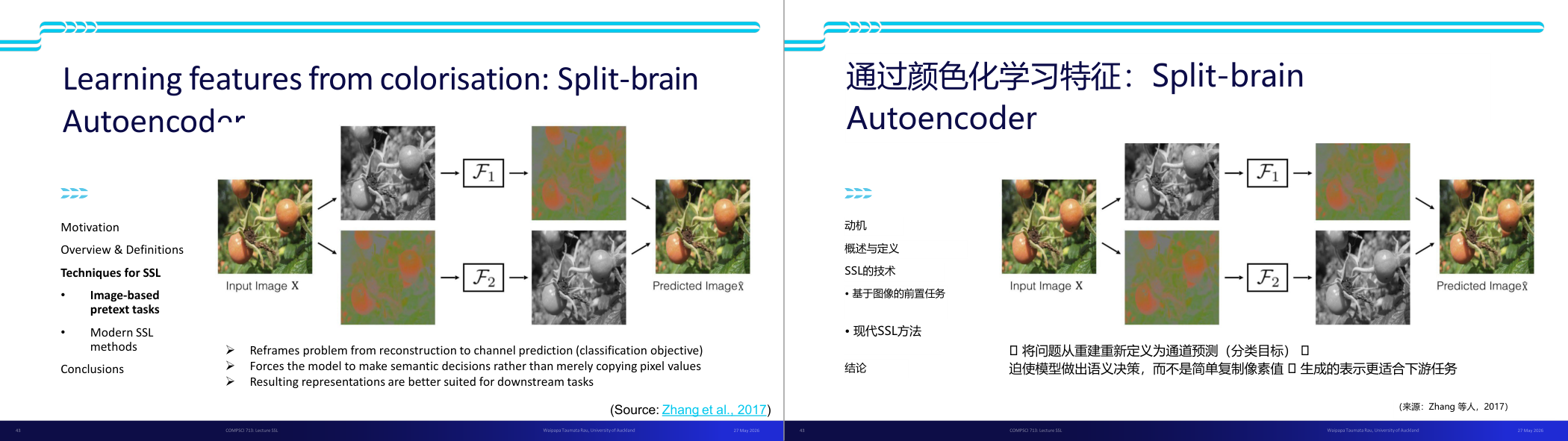
这一页讲的是通过颜色化学习特征的 Split-brain Autoencoder 方法。首先,输入图像 X 被分为两部分 X1 和 X2,分别代表不同的信息特征。然后,两个独立的网络 F1 和 F2 分别处理这些部分:F1 从结构信息(L)预测颜色信息(AB),而 F2 从颜色信息(AB)预测结构信息(L)。最终,这两个网络的输出通过连接(concatenation)形成一个更丰富的特征表示 F。图中的流程图展示了这一过程,从输入到分割,再到特征预测和最终的重构。该方法属于自监督学习(SSL)的技术,尤其是基于图像的预训练任务,旨在通过分割和预测不同特征来提升表示能力。这种方法的优点是能够在无标签数据上学习到更丰富的特征,为后续任务提供更好的基础。
这一页讲的是 Split-Brain Autoencoder(分裂脑自编码器)——一种利用图像着色(Colorization)做 SSL 的方法,来自 Zhang et al. 2017。背景知识:图像可以用 LAB 颜色空间表示,其中 L 通道代表亮度/结构信息,AB 通道代表色彩信息。Split-Brain 的核心想法是把一个 Encoder 拆成两个互相预测的子网络:F1 从结构通道 L 预测色彩通道 AB;F2 从色彩通道 AB 预测结构通道 L。最终的表示是 F 等于 F1 和 F2 的拼接,也就是 [F1, F2],形成更丰富的联合表示。关键设计选择:把任务从「重建像素值」改成「通道预测的分类问题」(classification objective)。这迫使模型做语义决策,而不是简单地复制相邻像素值。比如预测草地颜色时,模型必须先「认出」这是草地,再给出绿色,而不能只靠局部纹理插值。这个方法的优势还在于它可以推广到多模态数据(任何两个相关但不同的数据通道之间都可以互相预测)。实验结果:在 ImageNet 上做 SSL 预训练,用 Places 数据集的标签测评,结果接近有监督上界。考试怎么考:Split-Brain 是「生成型 SSL + 多通道互预测」的代表方法。常见问题是「为什么用分类目标比重建目标更好」——答案是分类目标强制语义决策,避免模型走捷径(直接复制像素)。易错点:不要说 F1 和 F2 是独立的网络,它们共享 Encoder 骨干但做不同的预测头;最终拼接两个特征向量是关键。
这一页讲的是通过颜色化任务学习特征的 Split-brain Autoencoder 方法。重点包括将问题转化为通道预测、强制模型进行语义决策,以及提升特征在后续任务中的表现。
这一页讲的是通过颜色化任务学习特征的 Split-brain Autoencoder 方法。首先,输入图像 X 被分解为两个部分,分别通过两个不同的函数 F1 和 F2 处理。F1 专注于处理图像的一个通道,而 F2 处理另一个通道。最终,两个通道的预测结果被组合起来以生成预测图像。这个方法的核心思想是将传统的图像重建问题重新定义为通道预测问题(分类目标),从而迫使模型做出语义决策,而不是简单地复制像素值。这样的设计能够更好地提取高质量的特征,使其更适合后续的任务,如分类或检测。幻灯片右侧的流程图展示了这一过程:从输入图像到分离通道,再到预测图像的生成,直观地说明了 Split-brain Autoencoder 的工作机制。这种方法在半监督学习(SSL)中非常重要,因为它提供了一种利用未标注数据的创新方式。
这一页讲的是通过颜色化学习特征的 Split-brain Autoencoder 方法。重点包括图像预处理任务、现代自监督学习(SSL)技术,以及该方法如何处理多模态数据。
这一页讲的是通过颜色化学习特征的 Split-brain Autoencoder 方法。Split-brain Autoencoder 是一种自监督学习(SSL, Self-Supervised Learning)技术,主要用于图像预处理任务。幻灯片中展示了输入的 RGB-HHA 图像,其中 RGB 表示颜色通道,HHA 表示深度信息通道。该方法将输入图像分为两部分:RGB 通道和 HHA 深度通道,分别通过两个函数 F1 和 F2 进行处理,最终预测出完整的 RGB-HHA 图像。这种方法的核心思想是利用图像的不同模态信息进行特征学习,从而实现多模态数据的融合。图中的流程图清晰地展示了输入图像如何被分解、处理并重新组合的过程。这种技术不仅适用于单模态数据,还可以扩展到多模态数据的处理场景,例如结合视觉和深度信息进行复杂任务。
这一页讲的是使用 Split-brain Autoencoder 从图像着色中学习特征。重点包括自监督学习方法、实验结果对比,以及使用 F1 和 F2 特征的连接。
这一页讲的是通过 Split-brain Autoencoder 从图像着色任务中学习特征的研究。首先,介绍了自监督学习(Self-supervised Learning, SSL)的背景,强调其在 ImageNet 数据集上的应用。图中的折线图展示了不同方法在多个卷积层(conv 和 pool 层)上的 Top-1 准确率表现。这篇论文使用了 Places 数据集(Zhou 2016)中的标注数据,并通过连接特征 F1 和 F2 提升了模型性能。图中的黑色折线代表监督学习的结果,表现最好;而 Split-brain Autoencoder 方法(蓝色折线)在自监督学习方法中表现突出,尤其是在较深的卷积层(如 conv5 和 pool5)。这说明该方法能够有效捕捉图像的高级特征。一个例子是,通过将图像分为两个部分并分别预测颜色信息,模型可以学到更丰富的特征表示。这种方法对于图像分类和其他视觉任务具有重要意义。
这一页讲的是视频上色的预训练任务,核心是利用视频中颜色的时间一致性。主要内容包括任务的定义和技术背景。
这一页讲的是视频上色(video coloring)的预训练任务,重点是通过建模视频中颜色的时间一致性(temporal coherence)来实现自监督学习(SSL)。页面展示了一个参考帧(reference frame),即 t=0 的彩色图像,以及后续时间帧(t=1, t=2, t=3)的黑白图像,提出问题:如何根据参考帧为这些后续帧上色?这种任务利用了视频中连续帧之间的颜色变化规律,作为学习的监督信号。左侧列出了相关内容:首先是动机(Motivation),即为什么研究这种任务;其次是定义和技术背景(Overview & Definitions),包括基于图像的预训练任务(Image-based pretext tasks)和现代自监督学习方法(Modern SSL methods)。这种方法的重要性在于,它可以在无需人工标注的情况下,从视频的内在结构中提取信息,用于模型训练。例如,通过学习颜色的时间一致性,模型可以提升对时序数据的理解能力,应用于视频处理或预测任务。
这一页讲的是视频着色的预训练任务 (pretext task)。主要内容包括通过视频帧间颜色的时间一致性 (temporal coherence) 来训练模型,以及这种方法如何帮助模型学习无标签的区域或物体。
这一页讲的是视频着色的预训练任务 (pretext task)。核心思想是利用视频帧间颜色的时间一致性 (temporal coherence),即在视频中,某一物体的颜色在连续帧之间应保持一致。页面中的图示展示了一个参考帧 (t=0) 和后续帧 (t=1, t=2, t=3),通过箭头指示同一物体在不同时间点的位置,并强调颜色应保持一致。假设是:通过学习视频帧的着色,模型可以在没有标签的情况下学习追踪区域或物体。这种方法属于自监督学习 (Self-Supervised Learning, SSL) 的技术之一,特别是基于图像的预训练任务 (image-based pretext tasks)。它的意义在于减少对人工标注数据的依赖,同时提升模型的泛化能力。例如,一个模型可以通过学习视频中汽车的颜色变化,自动识别并追踪汽车位置,而无需明确标注。
这一页讲的是视频上色的学习方法,重点在于通过自监督学习(SSL)技术建立参考帧与目标帧之间的映射关系,并利用这些映射来复制正确的颜色信息。
这一页讲的是视频上色的学习方法,核心目标是通过自监督学习(SSL)技术,在学习的特征空间中建立参考帧(Reference Frame)与目标帧(Input Frame)之间的映射关系。图中展示了两个关键步骤:首先通过“Pointer”机制在参考帧和目标帧之间建立颜色信息的对应关系;然后通过“Copy”机制将参考帧中的颜色(Reference Colors)复制到目标帧中的颜色(Target Colors)。这种方法的学习目标是使用这些映射作为指针来复制正确的颜色信息(例如 LAB 色彩空间)。幻灯片还提到两种 SSL 技术:基于图像的预设任务(Image-based pretext tasks)和现代 SSL 方法,这些技术为解决视频上色问题提供了技术支持。这种方法的重要性在于它可以减少人工标注的需求,同时提高视频上色的自动化程度。例如,在黑白视频中,系统可以通过参考帧的颜色信息自动生成目标帧的彩色版本。
这一页讲的是 Pointer Network 的注意力机制在图像处理中的应用,重点包括图像预训练任务和现代自监督学习(SSL)方法。
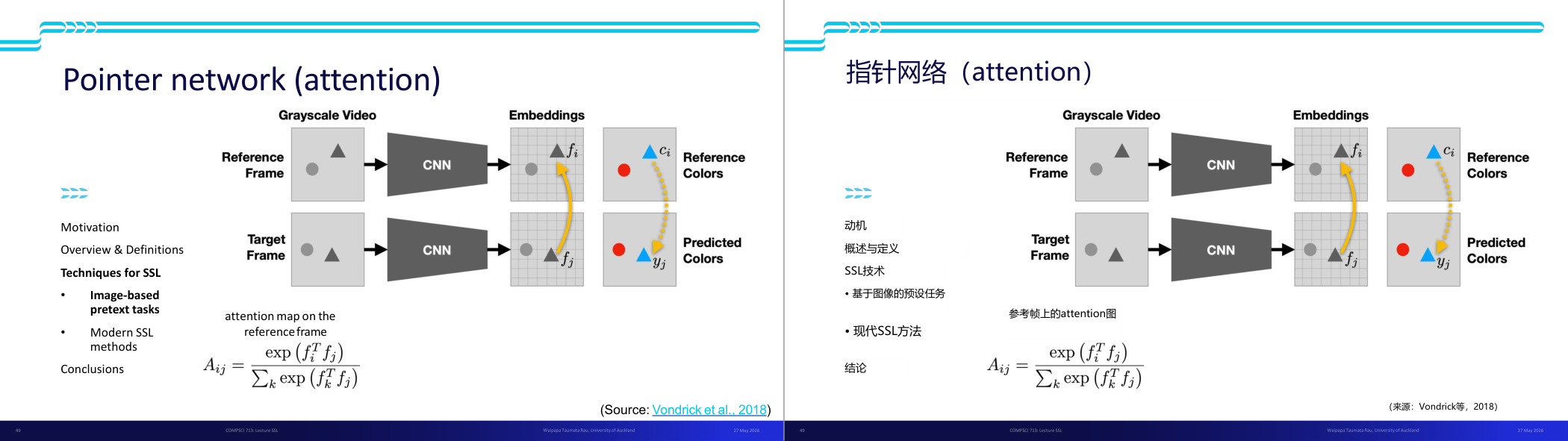
这一页讲的是 Pointer Network 的注意力机制如何用于图像处理,特别是在自监督学习(SSL)中的应用。幻灯片展示了一个流程图,描述了如何从灰度视频中提取特征并预测颜色。首先,参考帧和目标帧通过卷积神经网络(CNN)提取特征嵌入(Embeddings),分别表示为 f_i 和 f_j。接着,利用注意力机制计算参考帧和目标帧之间的注意力映射,公式为 A_ij = exp(f_i^T f_j) / Σ_k exp(f_k^T f_j)。这个公式表示目标帧的特征如何与参考帧的特征匹配,从而实现颜色预测。右侧的图示进一步说明了如何从参考帧的颜色 c_i 映射到目标帧的预测颜色 y_j。这个方法对图像预训练任务和现代 SSL 方法非常重要,因为它能够通过注意力机制有效地捕捉帧间关系,从而提升模型的学习能力。例如,在视频中的某个灰度场景中,模型可以通过学习参考帧的颜色信息准确预测目标帧的颜色。
这一页讲的是 Pointer Network 的注意力机制应用,主要用于图像预处理任务。重点包括注意力映射公式和预测颜色的计算方法。
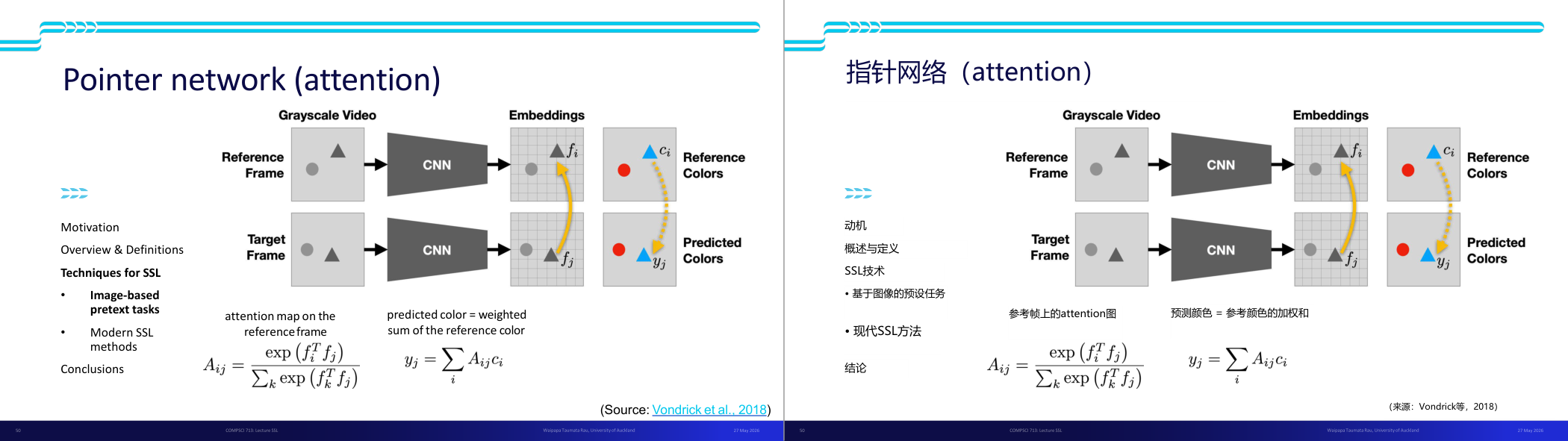
这一页讲的是 Pointer Network 的注意力机制应用,特别是在图像相关的自监督学习(SSL)任务中的使用。幻灯片展示了一个处理灰度视频的流程:首先将参考帧和目标帧通过卷积神经网络(CNN)提取特征嵌入(embeddings),分别表示为 f_i 和 f_j。通过注意力映射公式 A_ij,可以计算目标帧中每个像素与参考帧中像素的相似度,公式中使用了 softmax 操作来归一化相似度分数。随后,预测颜色 y_j 是参考帧颜色 c_i 的加权和,其中权重由 A_ij 决定。图示清晰地展示了从参考帧到目标帧的颜色映射过程,黄色箭头表示注意力权重的流动。这个方法在图像预处理任务中非常重要,因为它能有效利用参考帧信息预测目标帧的颜色分布,从而提高模型的学习效率。
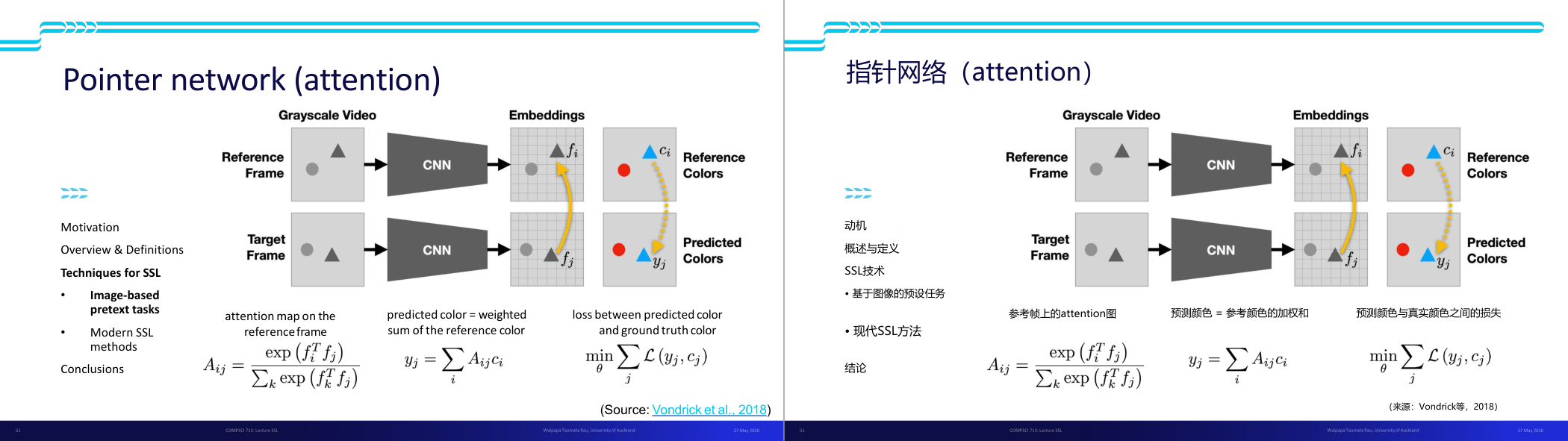
这一页讲的是 Pointer Network (Attention) 在图像任务中的应用,重点包括注意力机制、颜色预测以及损失函数的定义。
这一页讲的是 Pointer Network (Attention) 的工作原理及其在图像任务中的应用。首先,输入为灰度视频的参考帧和目标帧,通过 CNN 提取特征嵌入 (Embeddings),分别表示为参考帧的特征 f_i 和目标帧的特征 f_j。接着,注意力机制计算注意力图 (Attention Map),公式为 A_ij = exp(f_i^T f_j) / Σ_k exp(f_k^T f_j),表示目标帧中某点与参考帧中各点的相似度。然后,用注意力权重对参考帧的颜色 c_i 加权求和,预测目标帧的颜色 y_j,公式为 y_j = Σ_i A_ij c_i。最后,通过损失函数 L(y_j, c_j) 来衡量预测颜色与真实颜色的差异,并优化网络参数 θ。图中展示了从参考帧到目标帧颜色预测的流程,强调了注意力机制在信息关联中的作用。这种方法在自监督学习 (SSL) 中非常重要,特别是用于图像任务的预训练。
这一页讲的是基于 DAVIS 2017 数据集的预测跟踪示例,重点介绍 SSL (Self-Supervised Learning) 技术在对象跟踪中的应用。
这一页讲的是基于 DAVIS 2017 数据集的预测跟踪示例,展示了如何通过自监督学习 (SSL) 技术实现对象跟踪。幻灯片提到,模型需要学会准确传播颜色,这要求它能够识别跨时间一致的对象或区域,并理解运动和时间关系。通过这些学习过程,对象跟踪可以自然地出现,而无需显式监督。页面还列出了 SSL 的两种技术:基于图像的前置任务 (Image-based pretext tasks) 和现代自监督学习方法 (Modern SSL methods)。右侧的三张图片展示了不同场景中的对象跟踪结果,例如赛车、树后的小动物以及空手道训练中的人物。这些例子说明了模型如何在动态场景中保持对目标的准确跟踪,从而验证了 SSL 的有效性。这种技术在视频分析、自动驾驶等领域具有重要意义。
这一页讲的是 Masked Autoencoders (MAE),一种现代自监督学习方法。重点包括其核心思想:通过遮盖图像部分并要求模型重建缺失部分,从而学习有用的特征。
这一页讲的是 Masked Autoencoders (MAE),它是一种现代自监督学习 (Self-Supervised Learning, SSL) 方法,特别适用于大规模视觉模型,比如 Vision Transformers (ViTs)。核心思想是通过遮盖输入图像的大部分内容并让模型重建缺失部分,来训练模型。这种方法通过处理不完整信息,迫使模型捕获图像中的有意义结构,其目标是学习对后续任务有用的特征,而不是生成图像。这种方法扩展了重建的概念,强调了在视觉任务中学习结构化信息的重要性。比如,在一个遮盖了大量像素的图像中,模型需要推测缺失部分的内容,这不仅训练了模型的重建能力,还能让模型更好地理解图像的整体语义结构。
这一页讲的是 Masked Autoencoders(MAE,掩码自编码器),来自 He et al. CVPR 2022,是目前最重要的现代 SSL 方法之一,属于考试高频考点。MAE 的核心思想:把输入图像切成若干不重叠的 patch(类似拼图块),随机遮住其中大部分(论文中遮 75%),只把剩下的可见 patch 送入 Encoder(使用 Vision Transformer,ViT),然后用一个轻量级 Decoder(小 ViT)来重建被遮住 patch 的像素值,用重建误差作为 loss 驱动训练。为什么遮 75% 这么高的比例有效?遮掉太少的话,模型可以靠局部相邻像素插值「作弊」;遮掉 75% 后,模型必须真正理解图像的全局结构和物体语义,才能合理补全大面积缺失区域。这与 NLP 中的 BERT(遮住文字预测)如出一辙,只是把文字换成了图像 patch。架构细节:Encoder 只处理可见 patch(提高效率),Decoder 接收 Encoder 输出 + mask token(占位符)一起重建所有位置。重建结果可能模糊,但这不重要——目标是特征质量,不是图像质量。评估结果:在 ImageNet 上,MAE 预训练后 finetune,ViT-H 模型达到 87.8% Top-1 精度,超过从头训练(83.1%)和 MoCo-v3(86.9%),且随模型规模扩大持续提升。考试怎么考:「MAE 是什么类型的 SSL,原理是什么,为什么遮住比例要高,重建模糊是否是缺陷?」易错点:MAE 的目标是 SSL pretext task 而非图像生成,重建模糊不是失败——只要特征好就算成功。
这一页讲的是 Masked Autoencoders (MAE) 的概念及其在自监督学习 (SSL) 中的应用。主要内容包括将图像分割成不重叠的小块并丢弃大部分信息,以及现代 SSL 方法的特点。
这一页讲的是 Masked Autoencoders (MAE),它是一种现代自监督学习 (SSL) 方法,用于图像处理任务。MAE 的核心思想是将输入图像分割成不重叠的小块 (patches),然后随机丢弃大部分小块,仅保留少量信息。这种方法的目的在于通过重建丢失的图像内容来训练模型,从而学习到图像的结构化表示。幻灯片中提到两种 SSL 技术:基于图像的预训练任务 (image-based pretext tasks) 和现代 SSL 方法,其中 MAE 属于后者。右侧的示例图展示了图像被分割成多个小块,部分区域被遮盖,模型需要通过学习填补这些遮盖区域。这种方法的优势在于它能够高效地利用未标注数据进行训练,同时提升模型对图像内容的理解能力。MAE 在计算机视觉领域具有重要意义,尤其是在需要处理大规模数据集的场景中。
这一页讲的是 Masked Autoencoders (MAE) 的工作原理和在自监督学习 (SSL) 中的应用。主要内容包括图像分块与掩码处理,以及使用 ViT 进行编码的过程。
这一页讲的是 Masked Autoencoders (MAE) 的工作原理和其在自监督学习 (Self-Supervised Learning, SSL) 中的应用。MAE 的核心思想是将输入图像划分为多个不重叠的块(patch),并随机丢弃大部分块,只保留少量块进行后续处理。然后,这些保留的块会通过一个视觉变换器 (Vision Transformer, ViT) 进行编码,生成对应的特征表示。图中的流程图展示了这一过程:左侧是输入图像被分块并掩盖大部分块,右侧是通过编码器处理后的剩余块。MAE 的优势在于减少计算量,同时保留图像的核心信息。幻灯片还提到 MAE 属于现代自监督学习方法的一部分,与传统的基于图像的预训练任务相比,具有更高的效率和灵活性。这种方法在计算机视觉领域中非常重要,因为它能够有效利用未标注数据进行模型训练,从而降低对大规模标注数据的依赖。
这一页讲的是 Masked Autoencoders (MAE) 的工作原理。主要内容包括将图像分块并掩盖大部分块、使用 ViT 编码剩余块,以及通过解码器预测掩盖块的像素值。
这一页讲的是 Masked Autoencoders (MAE) 的工作原理和技术细节。MAE 是一种用于自监督学习 (Self-Supervised Learning, SSL) 的现代方法。首先,输入图像被划分为不重叠的小块 (patches),并随机掩盖大部分块,仅保留少量块进行后续处理。接着,使用一个视觉变换器 (Vision Transformer, ViT) 对剩余的块进行编码,生成紧凑的特征表示。最后,解码器作为一个较小的 ViT,负责预测被掩盖块的像素值,从而重建完整图像。这种方法的核心思想是通过掩盖部分信息来迫使模型学习图像的全局结构和语义信息。图中展示了 MAE 的流程:从输入图像到编码器处理未掩盖块,再到解码器预测掩盖块的像素值并重建目标图像。这个过程对提升自监督学习的效果非常重要,因为它能够有效地利用未标注数据进行训练。
这一页讲的是 Masked Autoencoders (MAE) 的图像重建过程,展示输入图像的部分遮挡、重建结果和原始图像对比。重点包括 MAE 的技术特点及其在现代自监督学习 (SSL) 中的应用。
这一页讲的是 Masked Autoencoders (MAE) 的图像重建过程及其在自监督学习 (SSL) 中的应用。MAE 是一种现代 SSL 方法,利用图像遮挡作为预训练任务。左侧展示的是输入图像的部分遮挡 (Input patches),即通过随机遮盖部分图像块来生成不完整的输入;中间部分是模型对图像的重建结果 (Reconstruction),它尝试恢复被遮挡的区域;右侧为原始图像 (Actual Image),用于对比验证模型的重建效果。这种方法的核心思想是通过遮挡图像块,迫使模型学习全局图像结构和语义信息,从而提升其特征提取能力。这种技术在计算机视觉领域具有重要意义,因为它能有效降低对标注数据的依赖,同时提高模型的泛化能力。例如,MAE 可以应用于图像分类或目标检测任务的预训练阶段,从而显著提升下游任务的性能。
这一页讲的是 Masked Autoencoders (MAE) 的重建过程,重点介绍自监督学习 (SSL) 技术中的图像预处理任务和现代方法。
这一页讲的是 Masked Autoencoders (MAE) 的重建过程,展示了输入图像的部分遮挡 (Input patches)、模型重建 (Reconstruction) 和原始图像 (Actual Image) 的对比。MAE 是一种用于自监督学习 (Self-Supervised Learning, SSL) 的方法,利用图像遮挡作为预处理任务,让模型通过学习重建缺失部分来理解图像的全局信息。左侧的输入图像经过遮挡处理,只保留部分图像块;中间展示了 MAE 模型对遮挡图像的重建结果;右侧则是原始图像,用于对比重建质量。通过这种方式,模型可以有效地学习图像的语义信息。这种技术被认为是现代 SSL 方法中的重要创新,解决了传统方法对大量标注数据的依赖问题,同时提升了模型的泛化能力。比如,在实际应用中,MAE 可以用于图像分类或目标检测任务,通过预训练获得更好的性能。
这一页讲的是 Masked Autoencoders (MAE) 的重建过程。重点包括 MAE 的输入、输出模糊但能捕捉全局结构,目标是学习强表示而非生成图像。
这一页讲的是 Masked Autoencoders (MAE) 的重建过程,属于自监督学习 (SSL) 的一种方法。MAE 的输入是经过遮罩的图像块 (Input patches),模型通过重建这些遮罩区域来学习图像的全局结构和对象布局。重建结果 (Reconstruction) 虽然模糊,但能够反映图像的整体内容和布局,而不追求完全精确的重建。右侧展示的是原始图像 (Actual Image),用于对比模型的输出效果。重点在于,这种方法是一个前置任务 (pretext task),目的是学习强大的图像表示,而非生成真实图像,因此它不是生成任务 (generative task)。这种技术在现代自监督学习方法中非常重要,因为它能够有效地提取图像的语义信息,为后续任务提供更好的特征。比如,在图像分类任务中,使用 MAE 学到的表示可以显著提高模型的性能。
这一页讲的是 Masked Autoencoders (MAE) 的评估,重点是其在 ImageNet 分类任务中的表现。图表显示 MAE 预训练显著优于从零开始训练,并支持更大规模的 ViT 模型。
这一页讲的是 Masked Autoencoders (MAE) 的评估,主要探讨其在 ImageNet 分类任务中的表现。幻灯片中的柱状图比较了不同训练方法(从零开始训练 Scratch、MoCo-v3 和 MAE 预训练)在四种 Vision Transformer (ViT) 模型上的 Top-1 准确率表现,包括 ViT-B、ViT-L、ViT-H 和 ViT-H-448。图表显示,MAE 预训练在所有模型上都显著优于从零开始训练和 MoCo-v3 方法。例如,在 ViT-H-448 模型上,MAE 的准确率达到 87.8%,而从零开始训练仅为 83.1%。这一结果表明 MAE 能有效减少对标注数据的依赖,同时支持更大规模的模型扩展。MAE 的优势在于其现代化的自监督学习(SSL)方法,尤其是基于图像的预训练任务。这种方法不仅提升了模型性能,还为大规模视觉任务提供了更高效的解决方案。
这一页讲的是 CLIP 模型如何匹配图像与文本。重点包括模型的动机、SSL技术及图像与文本编码器的交互。
这一页讲的是 CLIP (Contrastive Language-Image Pretraining) 模型,它通过对比学习方法将图像和文本进行匹配。首先,动机部分说明了 CLIP 的目标是解决视觉-语言任务中的表征学习问题。接着,图中展示了两个核心模块:文本编码器和图像编码器。文本编码器将输入的文本转化为向量表示(如 T1, T2…),图像编码器将图像转化为向量表示(如 I1, I2…)。这两个编码器的输出通过点乘计算相似度,生成一个矩阵,其中每个元素代表某个图像与某个文本的匹配程度。通过这种方式,模型可以学习图像与文本之间的关联。幻灯片还提到现代自监督学习(SSL)的技术,包括基于图像的预训练任务以及更先进的 SSL 方法。总结部分强调了 CLIP 的重要性,它使得视觉-语言任务的迁移学习更加高效。例如,给定一张狗的图片和描述“pepper the aussie pup”,CLIP 可以准确匹配二者。
这一页讲的是 CLIP 模型如何通过对比损失 (contrastive loss) 实现图像与文本的匹配。重点包括使用文本编码器和图像编码器生成共享表示空间,以及对比损失的作用。
这一页讲的是 CLIP (Contrastive Language–Image Pretraining) 模型,它通过对比损失来实现图像与文本的匹配。CLIP 的核心是两个编码器:文本编码器和图像编码器,分别将文本和图像转化为共享表示空间中的向量。图中展示了文本和图像分别经过编码器后生成的向量矩阵,矩阵中的元素表示图像和文本的匹配程度。对比损失的作用是将匹配的图像/文本对拉近,同时将不匹配的对拉远,从而优化模型的表示能力。比如,'pepper the aussie pup' 的文本描述和对应图片会在共享空间中靠近,而与其他不相关的文本或图片会被推远。此方法利用了现代自监督学习 (SSL) 技术,特别是基于图像的预训练任务,提升了模型在跨模态任务中的表现。这种方法的重要性在于它能有效处理大规模数据,增强模型的泛化能力。
这一页讲的是 CLIP(Contrastive Language-Image Pre-Training)的对比训练机制,来自 Radford et al. ICML 2021。CLIP 是多模态 SSL 的代表方法,用 4 亿个(图像,文本)对从互联网上收集来训练,完全无需人工标注。训练机制:CLIP 有两个 Encoder,一个处理图像,一个处理文本,把图像和文本都映射到同一个共享表示空间(shared embedding space)中。训练目标使用对比损失(Contrastive Loss):对于一个 batch 内的 N 个(图像,文本)对,要让匹配的图文对在特征空间中距离更近,不匹配的对距离更远。具体来说,对于每张图像,模型要判断这 N 个文本描述中哪个才是它真正的配对——这形成一个 N 分类问题,同时对文本做相同操作,形成一个 N × N 的相似度矩阵,对角线元素是正样本,非对角线是负样本。数据优势:4 亿个网络图文对规模远超任何人工标注数据集,且文本描述天然丰富多样。下游迁移强大:CLIP 训练后的图像 Encoder 在各种视觉任务上表现出色,且随模型规模不断提升。考试怎么考:「解释 CLIP 的对比损失」——要答出:共享表示空间 + 正样本拉近 + 负样本推远 + 自动配对(互联网爬取)。易错点:CLIP 的对比损失不是逐像素重建,而是在高维语义特征空间中计算相似度。另外 CLIP 不是生成模型,不能直接生成图像。
这一页讲的是 CLIP 模型如何匹配图像和文本。重点包括对比损失 (Contrastive Loss)、共享表示空间和大规模训练数据的使用。
这一页讲的是 CLIP (Contrastive Language-Image Pretraining) 模型如何实现图像与文本的匹配。CLIP 的核心是对比损失 (Contrastive Loss),通过让匹配的图像和文本对在共享表示空间中更接近,同时将不匹配的对拉开距离,从而优化模型。图中的流程图展示了文本编码器和图像编码器分别处理文本和图像输入,并生成表示向量。随后,模型通过计算每个图像与所有文本的匹配程度来实现对比学习。表格部分表示图像和文本对之间的匹配关系,绿色部分是图像输入,紫色部分是文本输入,交叉点代表它们的匹配分数。CLIP 使用了来自互联网的 4 亿图像-文本对进行大规模训练,无需人工标注。这种方法结合了现代自监督学习 (SSL) 技术,特别是基于图像的预训练任务和先进的 SSL 方法,显著提升了模型的视觉和语言理解能力。例如,给定一张狗的图片和描述“pepper the aussie pup”,CLIP 可以准确地识别并匹配它们。
这一页讲的是 CLIP 模型如何将图像与文本匹配。重点包括其在下游视觉任务中的强大表现,以及随着模型规模增大性能持续提升的趋势。
这一页讲的是 CLIP (Contrastive Language–Image Pretraining) 模型,它通过对图像和文本进行对比学习来实现匹配。图表展示了不同模型在 27 个数据集上的线性探测平均分数 (Average Score) 与计算复杂度 (GFLOPs) 的关系。可以看到,CLIP 模型 (红色标记) 的表现显著优于其他方法,如 EfficientNet 和 ResNet,尤其是在较大的模型规模下 (例如 L/14@336px 和 RN50x64)。这说明 CLIP 能很好地处理下游视觉任务,并且其性能随着模型规模的增加而持续提升。这种趋势表明,扩展模型的容量可以显著提高其处理复杂任务的能力。此外,页面还提到了自监督学习 (SSL) 的技术,包括基于图像的预训练任务和现代 SSL 方法。CLIP 的成功展示了结合图像与文本信息进行训练的潜力,能够在多模态任务中取得强大的性能。例如,在图像搜索场景中,CLIP 可以通过自然语言描述快速找到相关图像。
这一页讲的是 CLIP 的零样本分类 (Zero-Shot Classification),重点包括语言与视觉模型结合的方式、利用文本标签生成分类器,以及无需特定任务训练即可分类图像的能力。
这一页讲的是 CLIP 的零样本分类 (Zero-Shot Classification)。它的核心思想是通过语言模型与视觉模型的结合,实现无需特定任务监督训练的图像分类能力。幻灯片中展示了 CLIP 的工作流程:首先,通过文本标签(如“plane”、“car”等)生成分类器,这些标签会被转化为描述性短语(如“A photo of a plane”),并输入到文本编码器 (Text Encoder)。同时,图像输入到图像编码器 (Image Encoder),生成图像特征向量。然后,文本特征与图像特征进行匹配,预测图像属于哪个类别。语言的引入使得模型可以直接利用自然语言描述进行分类,而不需要为每个分类任务单独标注数据或训练模型。这种方法属于现代的自监督学习 (SSL) 技术,结合了图像任务的预训练和语言模型的强大泛化能力。图中的流程图清晰地展示了文本和图像编码器的协作过程,以及最终分类结果的生成。一个简单的例子是,输入一张狗的图片,模型可以通过匹配文本描述 “A photo of a dog” 来正确分类。
这一页讲的是 CLIP 最独特的能力:Zero-Shot Classification(零样本分类)。传统分类模型训练时会把类别固化为「类别 0 = 狗,类别 1 = 猫」这种整数 ID,如果测试时遇到训练集没有的类别,就完全不知道怎么处理。CLIP 的做法根本不同:它不预测类别 ID,而是学习「视觉概念」和「文字描述」之间的关联。零样本分类的流程:想分类一张图片属于哪种动物,不需要任何标注样本,只需要把候选类别名称写成文本提示(prompt),比如「A photo of a dog」、「A photo of a cat」,分别送入文本 Encoder 得到文本特征;把图片送入图像 Encoder 得到图像特征;计算图像特征与所有文本特征的余弦相似度,选最高的那个作为预测类别。直觉理解:CLIP 在训练时见过无数「图片 + 文字描述」的配对,学会了「狗的样子」和「dog 这个词」应该在空间中靠近。所以即使测试时出现了新类别,只要能用自然语言描述,就能做分类。这也叫「prompt-based classification」,可以用自然语言描述任意概念,极度灵活。考试怎么考:「CLIP 怎么做零样本分类,为什么传统分类器做不到?」核心答案:CLIP 学的是视觉-语言对齐的通用表示而非固定类别标签,因此测试时可以用文本 prompt 描述任意类别。易错点:零样本不是说 CLIP 没有训练,而是对特定下游分类任务没有微调;CLIP 本身经过了大规模预训练。
这一页讲的是 CLIP 的 Zero-Shot Classification 方法。重点包括 CLIP 如何通过视觉概念与文本描述的关系进行分类,而不依赖固定的类别标签。
这一页讲的是 CLIP 的 Zero-Shot Classification 方法。CLIP 的核心直觉是它不通过学习固定类别标签(例如类别 0 是狗,类别 1 是猫等)进行预测,而是学习视觉概念与文本描述之间的关系。幻灯片中的流程图展示了 CLIP 的工作机制:首先,创建一个基于文本标签的分类器,例如“plane”、“car”、“dog”等,经过文本编码器(Text Encoder)处理后生成嵌入表示;然后,输入图像通过图像编码器(Image Encoder)生成图像嵌入,与文本嵌入进行匹配,最终实现零样本预测(Zero-Shot Prediction)。这种方法允许 CLIP 使用自然语言提示进行分类,而不仅仅局限于固定的类别 ID。此外,幻灯片提到 CLIP 的技术基础包括现代自监督学习(Modern SSL)方法和基于图像的预训练任务。这种方法的优势在于它能处理多样化的自然语言描述,适应不同的分类需求,例如“这是一张狗的照片”这样的提示。
这一页讲的是自监督学习 (Self-Supervised Learning) 的总结,包括其核心概念、任务分类、评估方法及现代技术的应用。重点强调了自监督学习如何通过预任务 (Pretext Tasks) 学习特征,以及评估方法和学习范式的对比。
这一页讲的是自监督学习 (Self-Supervised Learning) 的总结。首先,自监督学习是一种直接从数据中通过预任务 (Pretext Tasks) 学习表征的方法,不需要人工标签。预任务(如图像旋转、拼图、图像修复)旨在学习信息丰富的特征,而下游任务 (Downstream Tasks)(如分类、检测)则是最终目标。评估特征质量通常采用线性评估协议 (Linear Evaluation Protocol),即冻结编码器后在其上训练一个简单分类器。现代自监督学习技术(如 MAE 和 CLIP)显著提升了 AI 模型的扩展性和泛化能力,使得模型能够从大量未标记数据中学习丰富的表征。最后,学习范式分为三种:监督学习 (Supervised Learning) 使用数据和标签;无监督学习 (Unsupervised Learning) 仅使用数据;自监督学习 (Self-Supervised Learning) 则通过数据生成自己的标签。这些方法为现代 AI 的发展提供了强大的支持。
这一页讲的是整个 SSL 讲座的总结,把所有核心知识点串联起来,是考前最值得复习的一页。知识点一:SSL 的定义——通过 pretext task 从数据中直接学习表示,无需人工标签。知识点二:Pretext task 和 Downstream task 的区分——pretext 是手段(旋转预测、jigsaw、inpainting、MAE 重建等),目的是学习有用特征;downstream 是目的(分类、检测等),是最终评估的地方。这两个层次的任务绝对不能混淆。知识点三:评估方式——「线性评估协议」(linear evaluation protocol):冻结预训练好的 Encoder,在上面接一个简单线性分类器,用少量有标签数据训练这个分类器,看分类精度。这是检验特征质量的标准方法。如果简单的线性分类器就能取得好效果,说明 Encoder 学到的特征已经是线性可分的、语义清晰的。知识点四:现代 SSL 方法(MAE 和 CLIP)通过允许模型从海量无标注数据中学习丰富表示,显著推动了 AI 的规模化和泛化能力。MAE 是图像重建型(生成型),CLIP 是图文对比型(多模态判别型)。知识点五:三种学习范式对比——监督学习需要数据加标签;无监督学习只需数据;自监督学习数据自动生成标签。考试最常考的整合题:「比较 SSL 和监督学习,说明为什么 SSL 更具可扩展性」——答案核心:SSL 无需昂贵的人工标注(1B 图像标注需 4000 万美元),可以利用互联网级别的未标注数据,同时通过预训练加迁移在少量标签的下游任务上取得竞争性甚至超越监督基线的效果。