Week 11 - 02 - L-Continual Learning 视图:双语并排 英文 中文 倍速:1x 1.5x 2x
空格=播放/暂停当前页 · Tab=切换 简短/详细/深入 · 红色「深入」为重点页的深度讲解
这一页讲的是持续学习(Continual Learning)和人工智能的可持续性,属于课程COMSPCI 713: AI Fundamentals的内容。
这一页讲的是持续学习(Continual Learning)和人工智能的可持续性(Sustainability of AI)。持续学习是指机器学习模型在不断接收新数据的同时,能够保持之前学习到的知识,而不会出现灾难性遗忘(Catastrophic Forgetting)。这一概念对于人工智能的可持续发展至关重要,因为它使得模型可以适应动态变化的环境和需求,而无需频繁重新训练。课程COMSPCI 713: AI Fundamentals可能会深入探讨持续学习的技术方法、挑战以及实际应用场景,例如在机器人、医疗诊断或自动驾驶领域。通过这种学习方式,可以减少计算资源的消耗,提高效率,从而促进人工智能的可持续性发展。
这一页讲的是致谢部分,提到幻灯片内容改编自 Yun Sing Koh 的持续学习(Continual Learning)课程。
这一页讲的是致谢部分,表达了对 Yun Sing Koh 的持续学习(Continual Learning)课程的引用和改编。这表明作者在制作幻灯片时参考了该课程的内容,体现了对原作者工作的尊重与认可。持续学习是人工智能领域的重要研究方向,旨在让模型能够在不断接收新数据的同时保持对旧知识的记忆,避免遗忘。这种能力对动态环境中的应用非常重要,例如机器人学习和在线推荐系统。致谢部分通常是为了明确引用来源,强调学术诚信,同时帮助观众了解内容的背景和来源。
这一页讲的是持续学习(Continual Learning, CL)的课程大纲和学习目标,包括定义、设置及三种技术方法的特点和实例。
这一页讲的是持续学习(Continual Learning, CL)的课程大纲和学习目标。课程内容包括:首先介绍持续学习的概述与定义(Overview & Definitions),然后讨论其设置(Settings),接着重点讲解深度持续学习(Deep Continual Learning)的技术方法。这些方法分为三类:基于重放(Replay-based)、基于正则化(Regularisation-based)和基于架构(Architecture-based)。最后以总结(Conclusions)结束。学习目标明确了三方面:第一,解释持续学习的基本原理和挑战;第二,识别并解释基于重放、正则化和架构的持续学习技术的特点;第三,举例说明这三种技术的具体应用。通过这些内容,学生将全面理解持续学习的核心概念及其在深度学习中的应用场景和解决方案。
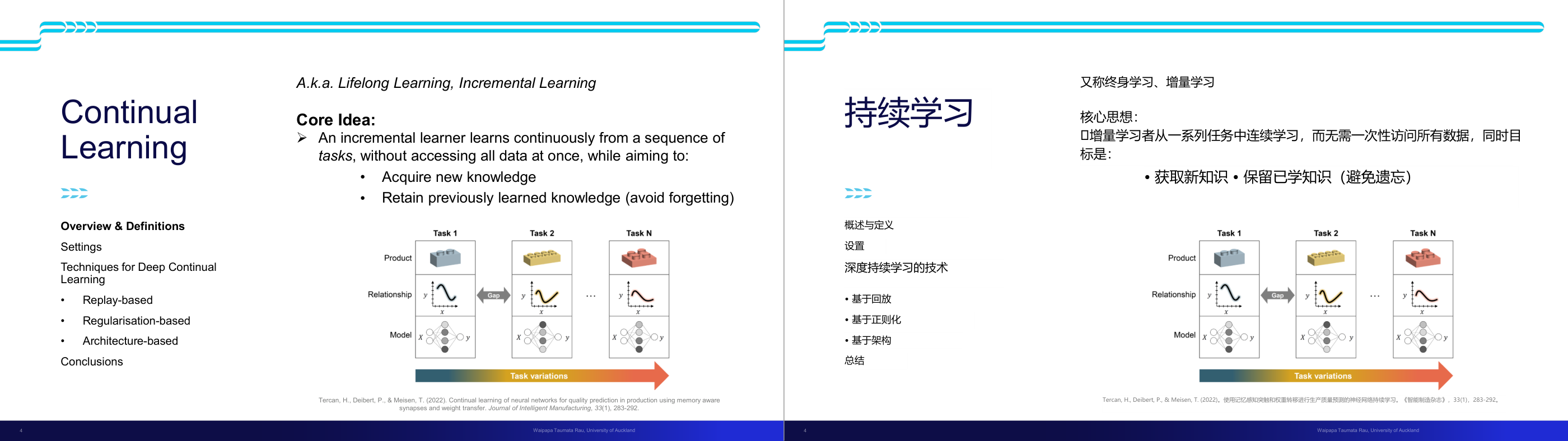
这一页讲的是持续学习(Continual Learning)的核心思想和方法。主要强调学习者连续处理任务,既能获取新知识又能保留旧知识。
这一页讲的是持续学习(Continual Learning),也称为终身学习(Lifelong Learning)或增量学习(Incremental Learning)。核心思想是学习者能够从一系列任务中连续学习,而无需同时访问所有数据。目标包括两个方面:一是获取新知识(Acquire new knowledge),二是保留先前学到的知识(Retain previously learned knowledge),避免遗忘(Avoid forgetting)。下方的图表展示了任务的变化(Task variations),从任务1到任务N,学习者需要处理不同的产品(Product)、关系(Relationship)和模型(Model)。图中强调了任务之间的差异(Gap),说明每个任务可能有独特的输入输出关系和模型结构。此外,页面还提到持续学习的技术包括基于回放(Replay-based)、基于正则化(Regularisation-based)以及基于架构(Architecture-based)的方法。这些方法旨在解决任务间的知识冲突与遗忘问题,是深度持续学习的重要研究方向。
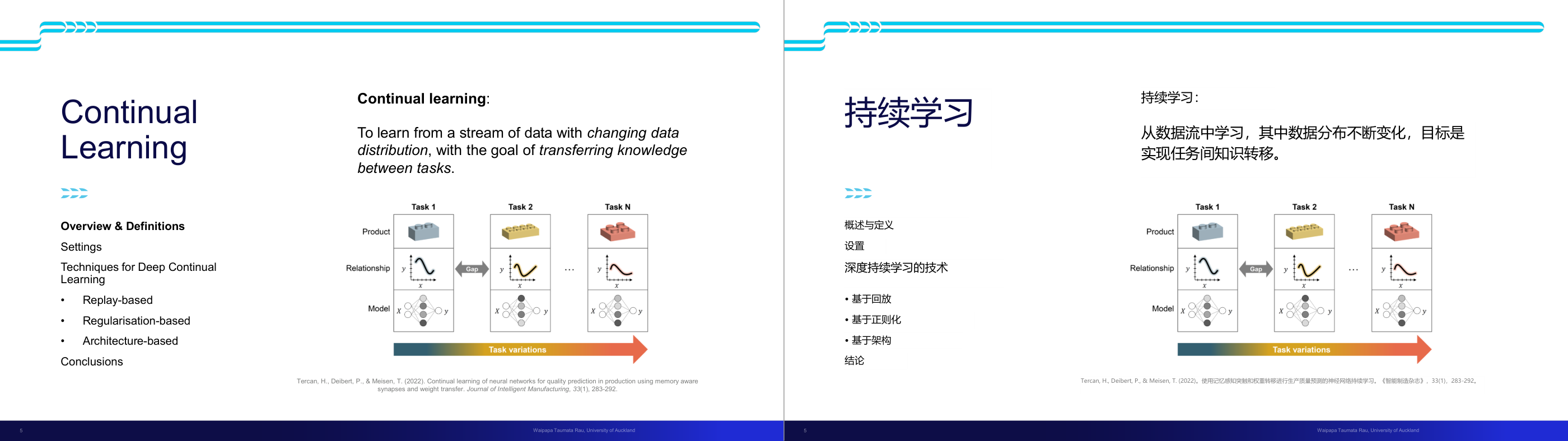
这一页讲的是 Continual Learning(持续学习)的定义和关键技术。主要内容包括数据分布变化中学习的目标,以及三种深度持续学习技术:Replay-based、Regularisation-based 和 Architecture-based。
这一页讲的是 Continual Learning(持续学习),它的目标是从数据流中学习,即使数据分布不断变化,也能在任务之间传递知识。右侧图表展示了任务的变化:从 Task 1 到 Task N,产品、关系和模型都在变化,数据分布的变化导致模型需要适应新的任务,同时保留之前任务的知识。持续学习的核心挑战是解决任务之间的知识转移问题,避免遗忘(Catastrophic Forgetting)。本页还提到三种深度持续学习技术:Replay-based(通过回放之前任务的数据来保持记忆)、Regularisation-based(通过正则化约束模型参数的变化)、Architecture-based(通过动态调整模型结构适应新任务)。这些技术对于处理数据流中任务变化非常重要,例如在生产质量预测中,随着产品种类的变化,模型需要不断更新以保持预测能力。
这一页讲的是持续学习(Continual Learning)的定义与关键概念,包括知识迁移和灾难性遗忘(Catastrophic Forgetting)。
这一页讲的是持续学习(Continual Learning)的定义与关键概念。持续学习是一种机器学习方法,旨在使模型能够在不断接收新任务时保持性能,同时避免遗忘之前的知识。这页重点介绍了两种知识迁移方式:前向迁移(Forward transfer)和后向迁移(Backward transfer)。前向迁移指一个任务中学到的知识可以帮助未来任务的学习,而后向迁移则是一个任务中学到的知识对之前任务的学习产生影响。灾难性遗忘(Catastrophic Forgetting)是负面的后向迁移现象,指模型在学习新任务时导致对旧任务的知识遗忘。此外,幻灯片提到持续学习的技术方法,包括基于回放(replay-based)、正则化(regularisation-based)和架构调整(architecture-based)的策略。这些方法旨在减轻灾难性遗忘并优化知识迁移。
这一页讲的是灾难性遗忘 (Catastrophic Forgetting),介绍其定义、优化目标及实践中的挑战。重点提到优化当前任务可能导致对旧任务的性能下降。
这一页讲的是灾难性遗忘 (Catastrophic Forgetting)。这一现象指的是在深度学习中,当模型学习新任务时,可能会忘记之前任务的知识。首先,理论上我们希望最小化所有已见任务的期望损失,公式中通过对所有任务的损失函数进行求和来表达这一目标。然而,实际中模型只能访问当前任务的数据,因此优化目标变为仅对当前任务的损失进行最小化。公式中展示了当前任务的平均损失的计算方式,即对当前任务数据的所有样本的损失求平均。最后指出,当我们专注于优化当前任务时,可能会导致模型对旧任务的性能下降,这是灾难性遗忘的核心问题。为解决这一问题,后续会介绍三种深度持续学习 (Deep Continual Learning) 技术:基于回放 (Replay-based)、基于正则化 (Regularisation-based) 和基于架构 (Architecture-based) 的方法。
这一页讲的是 Catastrophic Forgetting(灾难性遗忘)问题的数学本质。持续学习的理想目标是最小化所有已见任务上的期望损失之和——用求和符号表示就是:对所有 t 从 1 到大写 T,对每个任务的数据分布求期望,最小化模型 f(x;theta) 对标签 y 的损失。这是我们真正想优化的目标函数。但问题在于:在实际持续学习场景中,当我们训练第 t 个新任务时,手头只有当前任务的数据,于是我们实际只能优化当前任务的经验损失——即当前任务 N 个样本的平均损失。当我们对这个局部目标做梯度下降时,模型参数会朝着对当前任务有利的方向移动,而完全不受过去任务数据的约束,结果就是旧任务的性能急剧下降,这就是灾难性遗忘的根源。考试易错点:注意区分「理想优化目标」和「实际可优化目标」——前者对所有任务求和,后者只针对当前任务。灾难性遗忘本质上是这两个目标之间的差距造成的,而不是模型本身有缺陷。此外页面中还提到,Catastrophic Forgetting 是一种「负向 backward transfer(负向后向迁移)」——学新任务反而让旧任务变差。这个分类视角(forward transfer vs backward transfer)也是常见考点,要搞清楚方向。
这一页讲的是灾难性遗忘 (Catastrophic Forgetting),包括定义、场景及深度持续学习的技术方法。图表对比了灾难性遗忘与无遗忘的表现差异。
这一页讲的是灾难性遗忘 (Catastrophic Forgetting),即模型在学习新任务时对旧任务的性能急剧下降的问题。图表展示了两种情况:上方的图表显示灾难性遗忘的情况,模型在完成 Task1 后,学习 Task2 和 Task3 时对 Task1 的性能显著下降;而下方的图表则展示无遗忘的情况,模型对所有任务的性能保持稳定。幻灯片还提到深度持续学习中的三种技术方法:Replay-based(通过回放旧任务数据来缓解遗忘)、Regularisation-based(通过正则化约束模型参数变化)、Architecture-based(通过调整网络架构来适应新任务)。这些技术旨在解决灾难性遗忘问题,使模型能够在处理连续任务时保持对旧任务的记忆。灾难性遗忘是深度学习中的重要挑战,解决这一问题对于持续学习场景尤为关键,例如机器人学习或动态环境中的 AI 系统。
这一页讲的是稳定性-可塑性困境(Stability-Plasticity Dilemma)。主要介绍了两种目标:稳定性和可塑性,以及它们的平衡问题。
这一页讲的是稳定性-可塑性困境(Stability-Plasticity Dilemma)。这一困境是深度持续学习(Deep Continual Learning, CL)中的核心问题,涉及模型如何在学习新信息时保持对旧任务的性能。可塑性(Plasticity)指模型适应和整合新信息的能力;稳定性(Stability)则指模型保留已有内部表征并维持过去任务性能的能力。如果模型过于可塑(too plastic),会快速遗忘之前的任务;而如果模型过于稳定(too stable),则无法有效学习新任务。幻灯片还提到解决这一困境的技术,包括基于回放(Replay-based)、基于正则化(Regularisation-based)和基于架构(Architecture-based)的方法。这些方法旨在平衡模型的稳定性和可塑性,以实现更好的持续学习效果。
这一页讲的是持续学习的核心权衡:Stability-Plasticity Dilemma(稳定性与可塑性困境)。这是持续学习中最根本的张力,理解它有助于理解所有后续方法的设计动机。Plasticity(可塑性)指模型能够吸收和整合新信息的能力——如果可塑性高,模型能快速适应新任务;Stability(稳定性)指模型保留已有内部表征、维持对过去任务性能的能力——如果稳定性高,旧知识不会被覆盖。这两者天然对立:如果模型过于 plastic,每次学新任务都大幅改动参数,就会迅速遗忘旧任务(即 catastrophic forgetting);如果模型过于 stable,参数被锁死,就无法有效学习新任务。这和生物神经科学中的观察是一致的——大脑中海马体负责快速学习新信息(plastic),而新皮质负责长期稳定存储(stable),两者协同工作。考试时这道题经常以简答形式出现,要能准确说出两个词的定义并解释为什么它们对立。常见的错误是把「可塑性」理解成「模型参数数量」,实际上它描述的是适应新信息的能力。后续讲的 Replay、Regularisation、Architecture 三大方法,本质上都是在用不同策略去平衡这个困境。
这一页讲的是数据变化可以发生的地方,包括类别(Class)、领域(Domain)和任务(Task)。
这一页讲的是数据变化(shift)可以发生的地方,主要包括类别(Class)、领域(Domain)和任务(Task)。类别指数据点所属的明确分类,例如“猫”、“狗”、“快乐”等;领域是特征空间和边际概率密度函数,例如晴天的宠物照片、宠物的画作或宠物的音频记录;任务则涉及标签空间和条件概率密度函数,例如判断图片中是否有猫或狗,以及图片中有多少只狗。这些变化通常随着数据分阶段到达(任务)而发生,每个任务可能引入新的类别、领域或任务。这些定义为深度持续学习(Deep Continual Learning)的技术提供了基础,包括基于重放(Replay-based)、正则化(Regularisation-based)和架构(Architecture-based)的方法。
这一页讲的是模型中的三种可能发生的 shift 类型:Class shift、Domain shift 和 Task shift。
这一页讲的是模型在深度持续学习(Deep Continual Learning)中可能遇到的三种 shift 类型及其定义和例子。首先是 Class shift,指标签集合或标签频率随时间变化,例如一个分类模型最初用于识别猫和狗,但后来在包含兔子的环境中部署。其次是 Domain shift,指输入数据的表示发生变化,但任务和标签保持不变,例如模型在晴天的宠物照片上训练,但用于夜晚或室内照片,或者从照片切换到画作数据。最后是 Task shift,指任务目标或预测目标发生变化,但领域保持不变,例如模型最初用于判断图像中是否包含猫或狗,后来需要计算图像中狗的数量。这些 shift 的理解对于设计鲁棒的持续学习模型非常重要,因为它们直接影响模型的泛化能力和性能。
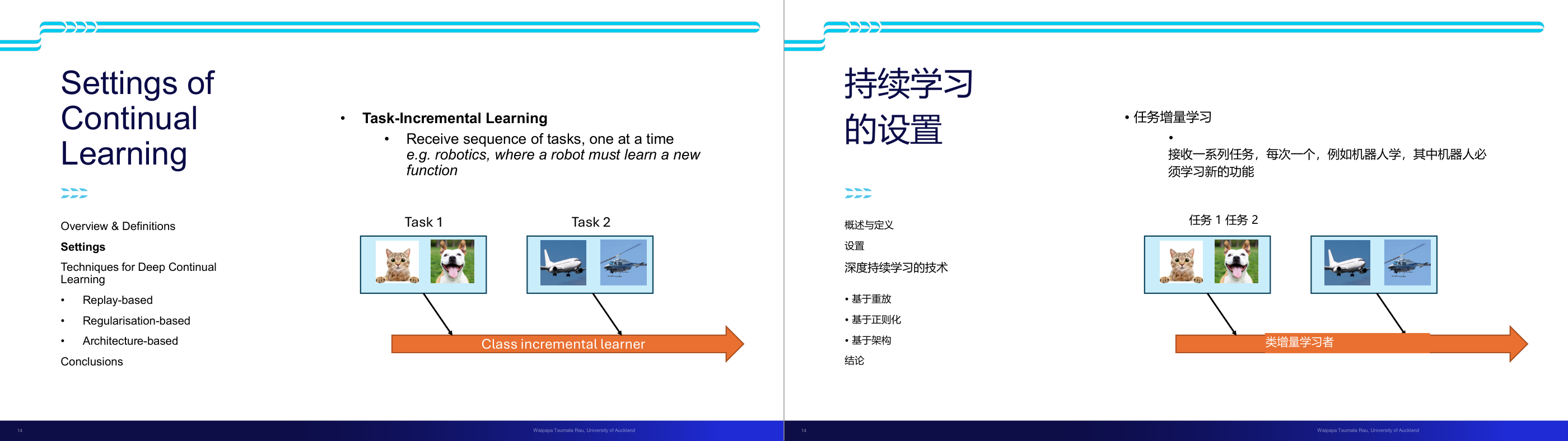
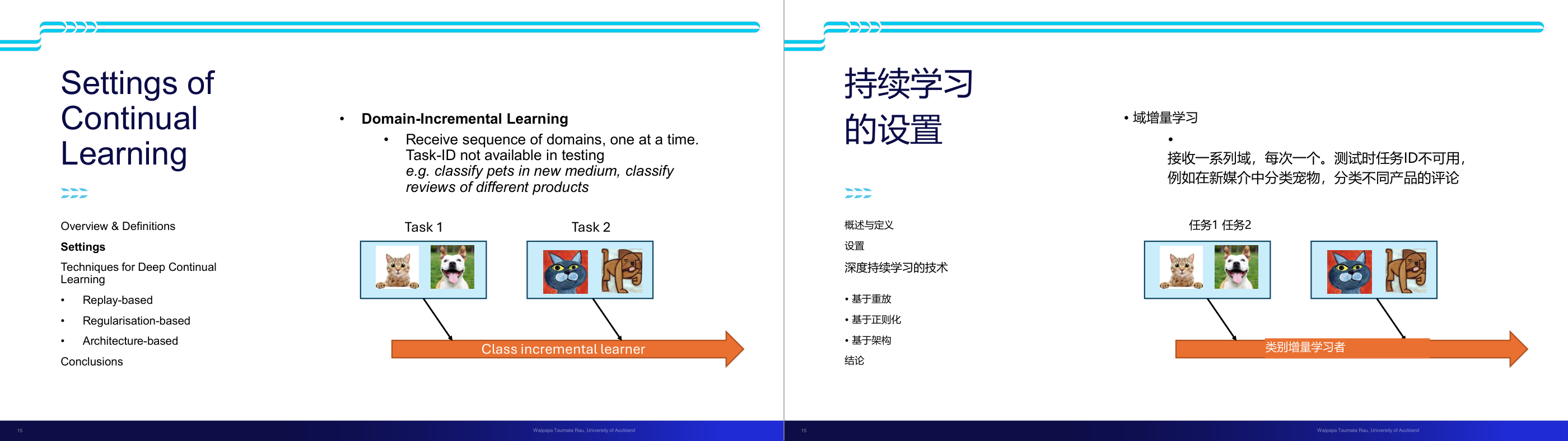
这一页讲的是持续学习 (Continual Learning) 的三种设置:类别增量学习、领域增量学习和任务增量学习。
这一页讲的是持续学习 (Continual Learning) 的三种主要设置。第一种是类别增量学习 (Class-Incremental Learning),模型需要随着时间接触新的类别,并最终能够区分所有已见类别。例如在医学图像分类中,随着新病理的发现,模型需要适应新的分类需求。第二种是领域增量学习 (Domain-Incremental Learning),任务本身保持不变,但输入的领域会随着时间发生变化,模型需要对这些变化保持鲁棒性,例如在不同环境下进行物体分类,如白天、雨天或暴风雪中的汽车检测。第三种是任务增量学习 (Task-Incremental Learning),模型会接触一系列独立的任务,每次学习一个任务,例如机器人需要学习新的功能。这三种设置反映了持续学习中模型适应性的重要性,能够帮助模型在动态环境中保持性能。
这一页讲的是持续学习中三种常见的「分布偏移」类型:Class Shift、Domain Shift 和 Task Shift。理解这三种偏移是掌握三类持续学习设置的前提。Class Shift 是标签集合或标签频率随时间改变——比如图像分类器原来只识别猫和狗,后来部署环境出现了兔子,新类别的加入就是 class shift。Domain Shift 是输入的表示形式发生变化,但任务和标签不变——比如同样是识别宠物,模型在白天晴天照片上训练,但要在夜晚或室内照片、甚至画作上使用,输入分布变了但目标不变。Task Shift 是预测目标或任务类型变化,即使输入域不变——比如同样是有猫狗的图片,任务从「判断是猫还是狗」变成「数这张图里有几只狗」,这是 task shift。考试时经常让你区分这三种 shift 并给出例子,要注意细节:domain shift 里 label space 不变只是输入分布变了;task shift 里 label space 本身的语义变了。还要注意它们与三种 CL 设置(Class-Incremental、Domain-Incremental、Task-Incremental)的对应关系,在下一页有详细说明。常见错题:把 domain shift 和 task shift 混淆——记住 domain 关注输入怎么变,task 关注输出目标怎么变。
这一页讲的是持续学习 (Continual Learning) 的设置,重点介绍类增量学习 (Class-Incremental Learning),它通过逐步接收新的训练类别来扩展模型能力。
这一页讲的是持续学习 (Continual Learning) 的设置,特别是类增量学习 (Class-Incremental Learning)。这种方法允许模型随着时间的推移接收更多的训练类别。例如,在医学图像分类中,随着新病理的发现,模型需要逐步学习新的分类任务。幻灯片中展示了一个流程图,图中有三个任务 (Task 1、Task 2、Task 3),分别对应不同的类别:猫、狗和仓鼠。这些任务逐步输入到一个类增量学习器 (Class Incremental Learner),模型通过这种方式不断扩展其知识范围。这种学习设置对于动态环境中的应用非常重要,例如医疗诊断和实时分类。页面还提到持续学习的技术分类,包括基于回放 (Replay-based)、基于正则化 (Regularisation-based) 和基于架构 (Architecture-based) 的方法,这些技术为实现高效的持续学习提供了不同的解决方案。
这一页讲的是持续学习 (Continual Learning) 的设置,尤其是任务增量学习 (Task-Incremental Learning)。主要内容包括任务序列的处理以及机器人学习新功能的应用场景。
这一页讲的是持续学习 (Continual Learning) 的设置,重点是任务增量学习 (Task-Incremental Learning)。任务增量学习指系统依次接收任务序列,例如机器人需要逐步学习新的功能。幻灯片下方的图示展示了两个任务:任务 1 包含猫和狗的分类,任务 2 包含飞机和直升机的分类。图中的箭头指向“类增量学习者 (Class Incremental Learner)”,说明系统需要不断适应新任务,同时保留对之前任务的学习能力。这种设置在机器人领域尤为重要,因为机器人需要在执行新任务时避免遗忘旧任务。持续学习的技术还包括基于重放 (Replay-based)、正则化 (Regularisation-based) 和架构调整 (Architecture-based) 的方法,这些技术帮助系统更高效地处理任务序列,减少遗忘效应,提升学习能力。
这一页讲的是持续学习 (Continual Learning) 的设置,重点介绍了领域增量学习 (Domain-Incremental Learning) 的特点和应用场景。
这一页讲的是持续学习 (Continual Learning) 的设置,其中重点介绍了领域增量学习 (Domain-Incremental Learning)。领域增量学习的特点是模型逐步接收来自不同领域的数据序列,每次处理一个领域,而在测试时任务标识 (Task-ID) 是不可用的。这种设置适用于分类任务,例如在不同媒介中识别宠物,或者分类不同产品的评论。幻灯片中的图示展示了两个任务:任务 1 包括猫和狗的图片,任务 2 包括卡通猫和卡通狗。通过领域增量学习,模型需要能够在不同领域中准确分类,而不依赖任务标识。这种方法对解决跨领域的分类问题非常重要,因为它能够提升模型的泛化能力。图中的箭头表示模型作为一个类增量学习者 (Class Incremental Learner),逐步学习并整合来自不同领域的信息。
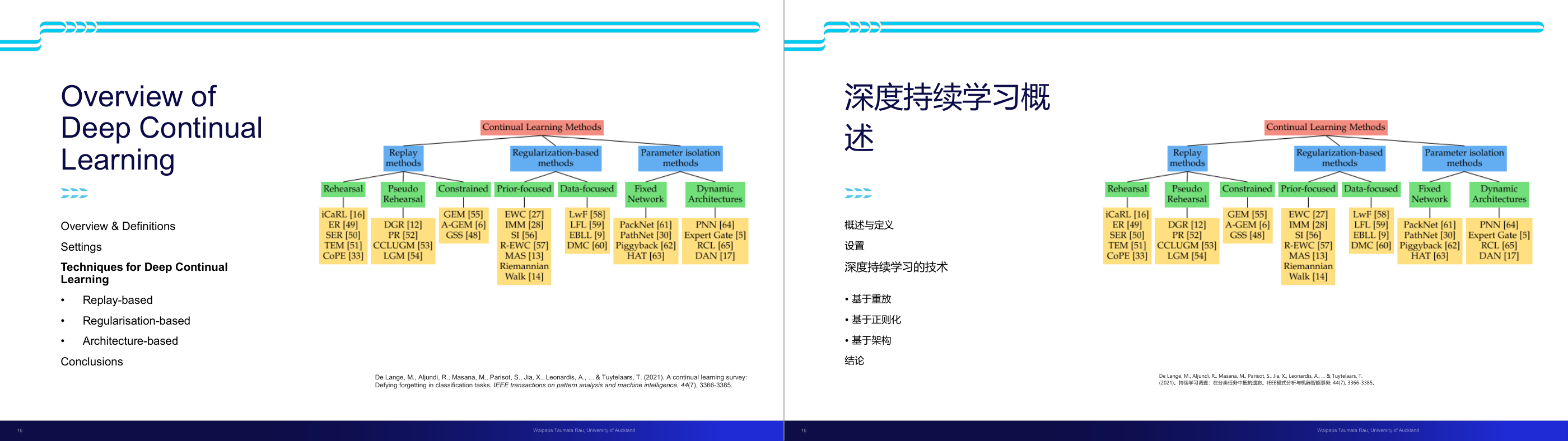
这一页讲的是深度持续学习(Deep Continual Learning)的概述和主要技术分类。重点包括三类技术:Replay-based、Regularisation-based 和 Architecture-based 方法。
这一页讲的是深度持续学习(Deep Continual Learning),主要探讨其定义、设置以及技术分类。深度持续学习旨在解决模型在面对连续任务时的遗忘问题。技术分类包括三大类:Replay-based 方法通过回放(Rehearsal)或伪回放(Pseudo Rehearsal)来保留旧任务信息;Regularisation-based 方法通过约束模型参数变化来减少遗忘,分为 Prior-focused 和 Data-focused 两种;Architecture-based 方法通过固定网络或动态架构来隔离参数,避免任务间干扰。图表展示了每种方法的具体技术及其代表性论文,例如 Replay 方法中的 iCaRL 和 DGR,以及 Regularisation 方法中的 EWC 和 SI。这些技术的选择取决于具体任务需求,例如 Replay 方法适合需要保留大量旧任务数据的场景,而 Architecture-based 方法更适合资源受限的情况。这种分类为研究者提供了清晰的技术框架,有助于设计适合特定应用的持续学习模型。
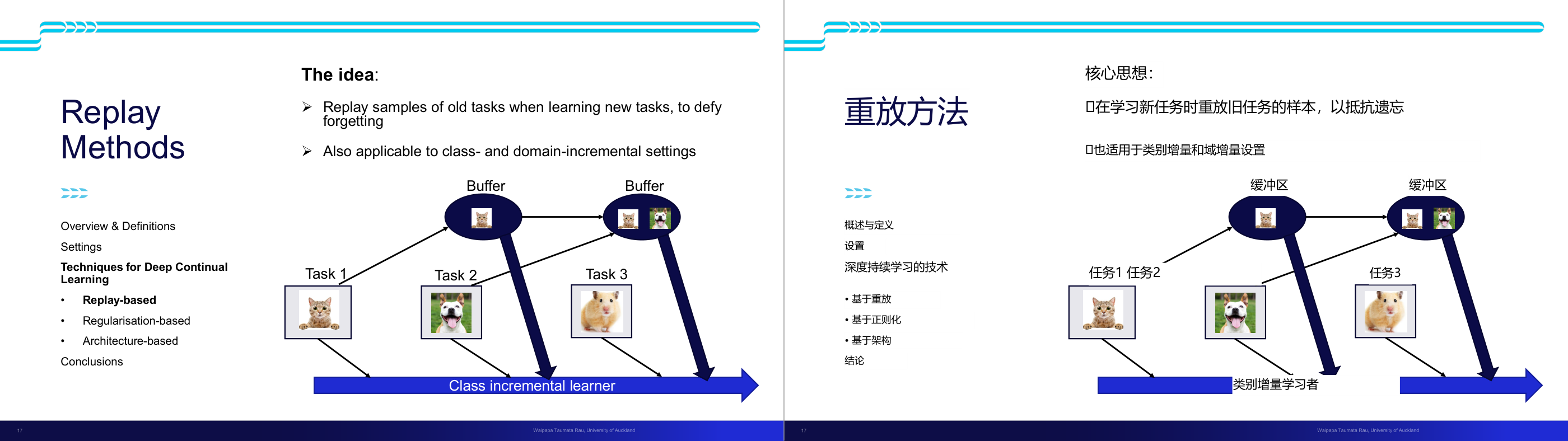
这一页讲的是 Replay Methods 的概念与应用。主要内容包括通过重放旧任务样本来避免遗忘,并适用于 class-incremental 和 domain-incremental 设置。
这一页讲的是 Replay Methods(重放方法)的核心思想及其在深度持续学习中的应用。Replay Methods 的主要目标是通过在学习新任务时重放旧任务的样本,来减少遗忘问题。这种方法适用于两种设置:class-incremental(类别增量学习)和 domain-incremental(领域增量学习)。页面中的图示展示了一个缓冲区(Buffer)的作用,它存储了旧任务的样本,比如 Task 1 的猫图片。在学习 Task 2 时,缓冲区会重放 Task 1 的样本,以帮助模型保留对之前任务的记忆。同样,在 Task 3 中,缓冲区包含了 Task 1 和 Task 2 的样本,继续为新任务提供支持。这种方法通过结合新任务和旧任务样本,帮助模型在多个任务间保持性能一致性。Replay Methods 是深度持续学习中的三种主要技术之一,另外两种是 Regularisation-based(正则化方法)和 Architecture-based(架构方法)。
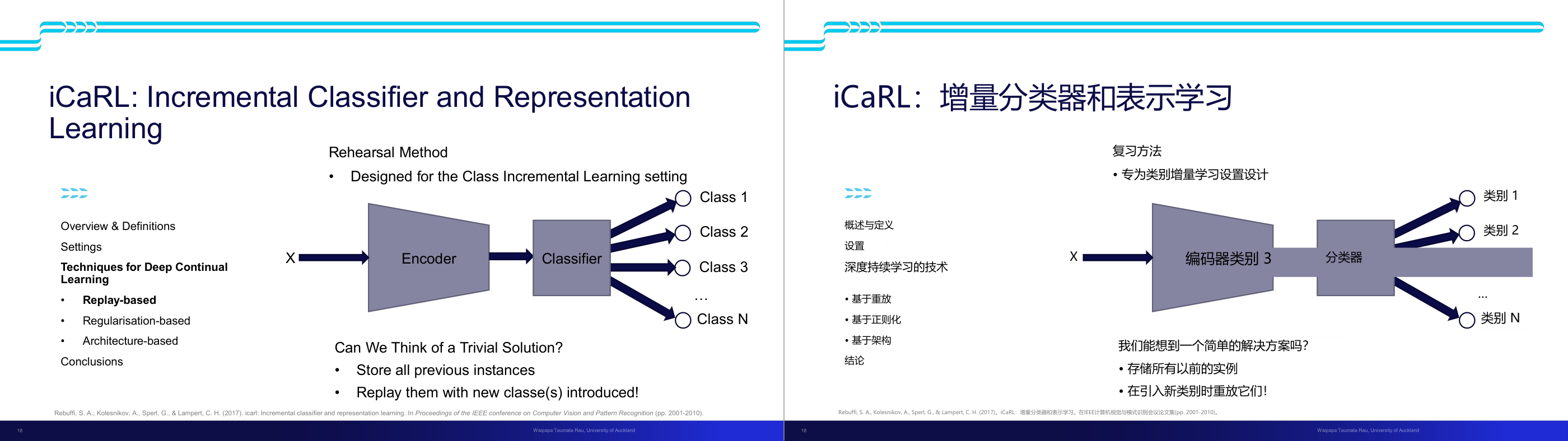
这一页讲的是 iCaRL 方法,它是一种增量学习(Incremental Learning)的分类器和表示学习方法。重点包括回放方法(Replay-based)的原理和作用。
这一页讲的是 iCaRL(Incremental Classifier and Representation Learning),它是一种专为类别增量学习(Class Incremental Learning)设计的技术。核心内容是回放方法(Rehearsal Method),该方法通过存储之前的实例并在引入新类别时进行回放来解决增量学习中的遗忘问题。幻灯片中展示了一个流程图,输入数据 X 经过编码器(Encoder)处理后进入分类器(Classifier),最终输出属于不同类别(Class 1, Class 2, Class 3, …, Class N)的预测结果。回放方法的一个简单解决方案是存储所有过去的实例,并在引入新类别时回放这些实例以保持模型对旧类别的记忆。除此之外,深度持续学习(Deep Continual Learning)的其他技术还包括基于正则化(Regularisation-based)和基于架构(Architecture-based)的方法。iCaRL 的重要性在于它能够有效应对增量学习中的知识遗忘问题,同时实现对新类别的学习。
这一页讲的是 iCaRL 方法的核心思想及其在持续学习中的技术特点。主要包括保持样本记忆、更新特征提取器,以及使用最近类别均值分类器。
这一页讲的是 iCaRL (Incremental Classifier and Representation Learning) 方法在深度持续学习中的应用及其核心思想。iCaRL 的主要特点是通过在有限的内存中保存每个类别的样本(称为“exemplar”),实现对新任务的增量学习。研究重点在于如何高效地选择和存储这些样本。此外,每当引入新的类别时,iCaRL 会更新特征提取器或编码器,将新类别的数据与存储的样本结合起来进行训练。与传统的基于 softmax 的分类方法不同,iCaRL 避免了对新类别的偏向问题,因为新类别样本通常数量较多,而旧类别样本较少。它采用了一种“最近类别均值分类器”(nearest class mean classifier),通过计算每个任务中样本的特征均值来进行分类。这种方法有效地减少了旧类别遗忘问题,同时提高了新任务的学习效率,是一种典型的 replay-based 持续学习技术。
这一页讲的是 iCaRL(Incremental Classifier and Representation Learning),这是 Replay-based 方法中专门针对 Class-Incremental Learning 设定的经典算法。iCaRL 的核心思想有三点。第一,它不是存储全部旧数据(那样内存会爆),而是为每个已学过的类维护一个有限大小的「exemplar set(样本代表集)」,研究的重点就在于如何从大量样本中挑出最具代表性的那些 exemplar。第二,每次引入新类别时,模型的 feature extractor/encoder 会用「新类别的原始数据」加上「旧类别的 exemplar」共同训练更新,这样 encoder 能感受到旧类别的分布,减少遗忘。第三,最关键也最容易被考到的是分类器的设计:iCaRL 不用标准的 softmax 分类头,因为 softmax 会偏向新类别——新类别有大量训练数据而旧类别只有少量 exemplar,softmax 的激活值会被新类别主导。iCaRL 改用「Nearest Class Mean Classifier(最近类均值分类器)」:测试时把输入映射到特征空间,然后计算它与每个类别的 exemplar 特征均值之间的距离,选最近的类。简单例子:假设猫类的 10 个 exemplar 在特征空间中均值为向量 c_cat,狗类均值为 c_dog,新图片的特征向量离 c_cat 更近就预测为猫。考试中 iCaRL 的易错点就是这个 nearest class mean classifier 的动机,要能解释「为什么不用 softmax」。
这一页讲的是 iCaRL 方法及其在增量学习中的表现。重点包括深度持续学习的技术分类和实验结果对比。
这一页讲的是 iCaRL(Incremental Classifier and Representation Learning),一种用于增量学习的分类器方法。首先,幻灯片提到深度持续学习(Deep Continual Learning)的三种主要技术分类:基于重放(Replay-based)、基于正则化(Regularisation-based)以及基于架构(Architecture-based)。其中,iCaRL 属于基于重放的方法,通过保存部分旧类别样本来避免灾难性遗忘。右侧的图表展示了不同方法在处理增量学习任务时的准确率随类别数量增加的变化趋势。图中比较了四种方法:iCaRL、LwF.MC、固定表示(fixed repr.)和微调(finetuning)。可以看到,iCaRL 的准确率随类别数量增加下降较慢,表现优于其他方法,尤其是微调方法在类别增加时准确率迅速下降。这说明 iCaRL 在增量学习中能够更好地保持旧类别的知识,同时学习新类别。一个简单的例子是,在图像分类任务中,iCaRL 可以在逐步引入新类别时有效避免遗忘之前的类别知识。
这一页讲的是 Gradient Episodic Memory (GEM),用于任务增量学习(Task Incremental Learning)。重点包括 GEM 的设计目标、共享特征提取器和任务专属分类器的架构。
这一页讲的是 Gradient Episodic Memory (GEM),一种专为任务增量学习(Task Incremental Learning)设计的深度持续学习技术。GEM 的核心思想是通过共享特征提取器(Shared Feature Extractor)将输入 X 转换为特征表示,然后通过多个任务专属的分类器(Task-Specific Network Heads)完成分类任务。图中展示了一个典型的架构:输入数据 X 经过编码器(Encoder)提取特征后,被分配到不同的分类器,例如 Classifier 1, Classifier 2 等,每个分类器专注于特定任务的类别预测,例如 Class 1 和 Class 2。幻灯片还提到深度持续学习的三种技术:基于重放(Replay-based)、基于正则化(Regularisation-based)和基于架构(Architecture-based)。GEM 属于重放技术,通过保存过往任务的样本来避免遗忘问题。这种方法的重要性在于它能够在不访问旧任务数据的情况下,保持对旧任务的良好性能,同时适应新任务。
这一页讲的是 Gradient Episodic Memory (GEM) 方法,用于深度持续学习。主要内容包括 GEM 的核心思想、梯度干预机制,以及 Episodic Memory 的设计与作用。
这一页讲的是 Gradient Episodic Memory (GEM),一种用于深度持续学习的技术。其核心思想是避免在重新训练存储的旧任务数据时出现过拟合问题。GEM 将过去任务的数据视为约束条件,确保新参数更新时不破坏以前任务的性能。这种方法通过干预梯度优化过程,控制模型训练的方向。页面还介绍了 Episodic Memory 的设计,它是一个固定大小的内存缓冲区,拥有内存预算 M。如果任务总数 T 已知,M 会被均匀分配到每个任务,每个任务分配 m = M/T 样本。这些存储的样本作为参考点,用于保留过去任务的性能。通过这种机制,GEM 能够有效解决持续学习中的灾难性遗忘问题。例如,在图像分类中,GEM 可以通过存储少量样本来确保模型在新任务训练后仍能准确分类之前任务的图像。
这一页讲的是 GEM(Gradient Episodic Memory,梯度情节记忆),一种专为 Task-Incremental Learning 设计的 Replay-based 方法。与 iCaRL 不同,GEM 不是直接把旧数据混进训练集,而是在梯度层面做干预。GEM 的架构上有一个 Shared Feature Extractor(共享特征提取器)加上多个 Task-Specific Classifier Head(任务专用分类头),每个任务有自己的 head。核心机制分两步:首先,GEM 维护一个大小为 M 的 Episodic Memory Buffer(情节记忆缓冲区),如果知道总任务数 T,就把 M 平均分配,每个任务存 m = M/T 个样本。这些存储的样本不是用来重新训练的,而是用来定义约束。其次,学习新任务时,GEM 把过去每个任务的 episodic memory 当作约束:要求新参数更新后在旧任务记忆上的损失不能超过更新前的损失。这形成一个约束优化问题:最小化当前任务损失,约束条件是对所有 k 小于 t,新模型在记忆 M_k 上的损失不超过旧模型在同一记忆上的损失。如果当前任务的梯度方向会使旧任务损失增加,就把梯度投影到满足约束的可行域中。GEM 的优点是能防止负向 backward transfer,还观察到少量正向 backward transfer——学新任务有时还能改善旧任务性能。
这一页讲的是 Gradient Episodic Memory (GEM) 方法及其优化问题。重点包括约束优化公式、episodic memory 的定义,以及如何处理梯度以避免遗忘。
这一页讲的是 Gradient Episodic Memory (GEM) 方法,它是一种用于深度连续学习(Deep Continual Learning)的技术,旨在解决模型在学习新任务时遗忘旧任务的问题。核心是一个约束优化问题,目标是最小化当前任务的损失函数 ℓ(fθ(x,t),y),同时确保对旧任务的损失 ℓ(fθ,Mk) 不超过之前模型的损失 ℓ(ft−1θ,Mk)。其中 Mk 表示任务 k 的 episodic memory,ft−1θ 是完成任务 t−1 后的模型。由于标准的随机梯度下降(SGD)无法直接处理这种约束优化问题,GEM 提出了一种替代方案:首先计算当前任务和每个旧任务的梯度,然后如果当前梯度会增加旧任务的损失,就将梯度投影到旧任务梯度的可行区域。这种方法通过 replay-based 技术有效缓解遗忘问题,确保模型在处理新任务时仍能保持对旧任务的良好性能。
这一页讲的是 GEM 的约束优化公式与梯度投影机制的细节。GEM 的目标函数写成:最小化 theta 上的当前任务损失 l(f_theta(x, t), y),约束条件是对所有已学任务 k 小于 t,新参数在任务 k 的记忆 M_k 上的损失要小于等于旧参数 theta 上一个任务结束时对同一记忆的损失。这里 M_k 是任务 k 的 episodic memory,f_theta^(t-1) 是完成任务 t-1 训练后的模型。这个约束的意思是:学新任务可以,但不能让旧任务变得更差。由于普通 SGD 是无约束优化,不能直接用,GEM 的做法是:先计算当前任务的梯度 g,再计算每个旧任务记忆上的梯度 g_k。如果 g 与某个 g_k 的内积为负(说明当前梯度方向会使那个旧任务的损失增加),就把 g 投影到所有过去任务梯度定义的可行域上——即找一个最接近 g 但满足所有约束的梯度方向。直觉上,这就像在参数空间里走路时,每次要走的方向不能与任何旧任务的「禁止方向」冲突。考试易错点:要区分 GEM 和直接 replay——GEM 不是把旧数据加入训练集重新训练,而是在梯度层面施加约束,计算开销也因此更大,因为每步都要检查并可能修正梯度方向。
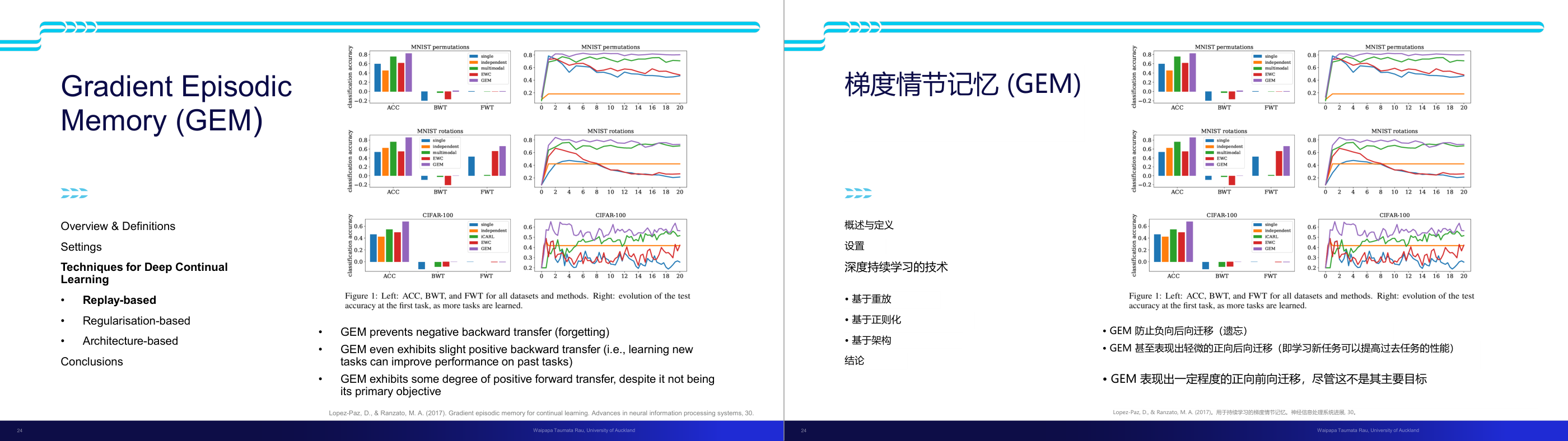
这一页讲的是 Gradient Episodic Memory (GEM) 方法,用于深度连续学习(Deep Continual Learning)。重点包括 GEM 的定义、特点以及其在不同数据集上的表现。
这一页讲的是 Gradient Episodic Memory (GEM),一种用于深度连续学习的技术。GEM 的主要目标是解决遗忘问题(negative backward transfer),即在学习新任务时避免对之前任务的性能产生负面影响。幻灯片中的图表展示了 GEM 在 MNIST permutations、MNIST rotations 和 CIFAR-100 数据集上的表现。左侧柱状图比较了不同方法在 ACC(准确性)、BWT(负向迁移)和 FWT(正向迁移)上的效果,右侧折线图显示了随着任务数量增加,测试准确性的变化趋势。结果表明,GEM 能有效防止负向迁移,同时还表现出一定程度的正向迁移(forward transfer),尽管这不是其主要目标。此外,GEM 还展示了轻微的正向回溯迁移(positive backward transfer),即学习新任务能够提升对过去任务的性能。这些特点使得 GEM 成为一种有效的连续学习方法。
这一页讲的是 Pseudo-Rehearsal 方法,用随机数据替代旧实例来保持模型对旧任务的表现,同时讨论其优点和问题。
这一页讲的是 Pseudo-Rehearsal(伪排练)方法,它是一种深度连续学习(Deep Continual Learning)的技术。其核心思想是:与其存储旧数据实例,不如将随机数据输入到模型中(包括旧模型和新模型),以保持模型在旧任务中的行为表现。具体步骤包括:1. 将随机输入喂给旧模型;2. 记录旧模型的输出;3. 训练新模型以匹配这些输出。这种方法可以被看作知识蒸馏(Knowledge Distillation),并作为一种功能正则化器(Functional Regulariser)来减少遗忘问题。然而,伪排练也存在一些问题,例如在高维特征空间中可能遇到维度诅咒(Curse of Dimensionality),尤其是对于大型神经网络(Large NN)和图像数据。此外,随机数据可能远离真实数据分布,从而在有意义的区域提供较弱的约束。这些问题限制了该方法在某些场景中的效果。
这一页讲的是 Pseudo-Rehearsal(伪排练)及其改进版 Generative Replay(生成式重演)。标准 Replay 方法需要存储真实的旧数据,而 Pseudo-Rehearsal 的思路是:不存原始数据,而是把随机噪声输入到旧模型,记录旧模型的输出,然后用这些「输入-输出对」来训练新模型,让新模型在随机输入上尽量模仿旧模型的行为。这本质上是一种知识蒸馏(knowledge distillation)——旧模型作为 teacher,新模型作为 student。但这个方法有明显缺陷:高维特征空间中随机输入往往远离真实数据分布(维度灾难),这些随机输入携带的约束信号很弱,对模型真正重要区域的覆盖很差。改进方案是 Generative Replay:用生成模型(GAN 做计算机视觉,Transformer 做 NLP)来生成真实感强的旧任务数据替代随机噪声,生成样本的质量远高于随机输入,对旧任务知识的保留效果也好很多。代价是:如果生成模型也要持续学习,训练成本很高;但如果能用预训练好的生成模型,则可以绕开这个问题。考试时要能对比 Pseudo-Rehearsal 和真实 Replay 的优缺点:前者避免了隐私问题,但在高维空间效果差;Generative Replay 是折中方案,质量更好但更复杂。
这一页讲的是伪复习(Pseudo-Rehearsal)技术及其改进——生成重播(Generative Replay)。重点包括使用生成模型生成旧任务数据、提升任务保留效果,以及使用预训练模型降低训练成本。
这一页讲的是伪复习(Pseudo-Rehearsal)技术,尤其是生成重播(Generative Replay)的改进方法。伪复习是一种深度持续学习(Deep Continual Learning)技术,旨在通过回放旧任务数据避免遗忘问题。生成重播的核心是利用生成模型生成逼真的旧数据以替代直接存储原始数据,这样可以更好地保留过去任务的知识。幻灯片提到两种生成模型:GANs(生成对抗网络)主要用于计算机视觉任务,而Transformer模型适合自然语言处理(NLP)任务。这种方法的优势包括生成高质量的旧数据和显著提升任务保留效果。然而,训练生成模型可能带来较高的计算成本,但可以通过使用预训练模型来降低这一负担。例如,使用已经训练好的GAN或Transformer模型,可以减少重新训练的需求,从而提升效率。这种技术在持续学习中非常重要,因为它平衡了存储效率与知识保留的需求,对解决遗忘问题具有显著意义。
这一页讲的是 Regularisation-based 方法在深度持续学习中的应用。重点包括通过正则化项保护过去任务的性能,并与 Replay-based 方法相比的优势。
这一页讲的是 Regularisation-based 方法在深度持续学习中的应用。其核心思想是通过限制对重要参数的更新,保护模型在过去任务中的性能。这种方法在损失函数中加入正则化项(regularisation term),即损失加上惩罚项(Loss + penalty term),以巩固之前的学习成果。与 Replay-based 方法相比,它的主要优势是无需存储过去任务的实例,从而更好地保护隐私。这种方法非常适合需要处理多任务学习,同时又对数据隐私有严格要求的场景。例如,在医疗数据分析中,Regularisation-based 方法可以避免直接存储患者数据,同时确保模型在不同任务间的性能稳定。
这一页讲的是 Learning without Forgetting (LwF) 的概念与知识蒸馏 (Knowledge Distillation) 的应用。主要内容包括如何通过知识蒸馏保留旧任务的知识、教师模型与学生模型的关系,以及蒸馏的优势。
这一页讲的是 Learning without Forgetting (LwF),即在深度学习中通过知识蒸馏 (Knowledge Distillation) 保留旧任务的知识。知识蒸馏是机器学习中的一个重要方法,它通过让一个较大的教师模型 (Teacher Model) 学习复杂任务,然后将其知识以 logits 的形式传递给较小的学生模型 (Student Model)。学生模型通过学习教师模型的 logits,可以获得比直接训练更丰富的信息,比如类别之间的相似性。幻灯片右侧的图展示了教师模型如何通过蒸馏过程将知识传递给学生模型,学生模型最终完成预测任务。这种方法的优势在于,logits 包含比标签更丰富的信息,有助于提高学生模型的性能。此外,幻灯片还提到深度持续学习 (Deep Continual Learning) 的技术分类,包括 Replay-based、Regularisation-based 和 Architecture-based 方法,这些技术旨在解决模型在持续学习过程中遗忘旧知识的问题。
这一页讲的是 Learning without Forgetting (LwF) 方法,它通过知识蒸馏实现跨任务学习,避免遗忘旧任务。主要过程包括数据处理、记录旧任务输出,以及损失函数的蒸馏增强。
这一页讲的是 Learning without Forgetting (LwF) 方法,它是一种用于深度持续学习(Deep Continual Learning)的技术,属于 regularisation-based 方法的一种。LwF 的核心是利用知识蒸馏(knowledge distillation)原理来跨任务学习,避免遗忘旧任务的知识。具体过程包括三个步骤:第一,在学习新任务之前,将新任务的数据输入到已经训练好的旧任务模型中;第二,记录旧任务模型的输出(即 soft targets);第三,在训练新任务时,损失函数中加入蒸馏损失项,用于惩罚新任务输出与旧任务输出的偏差。右侧的流程图展示了输入为新任务数据,输出包括旧任务的 soft targets 和新任务的 ground truth,模型通过蒸馏损失函数进行优化。公式描述了损失函数的组成,包括旧任务损失、当前任务损失以及正则化项。这种方法的意义在于,它能够在不需要存储旧任务数据的情况下,有效地保持旧任务的知识,同时学习新任务。
这一页讲的是 LwF(Learning without Forgetting,无遗忘学习),这是 Regularisation-based(正则化方法)中最具代表性的算法之一,核心机制是 Knowledge Distillation(知识蒸馏)。先理解知识蒸馏的一般思想:一个大 teacher 模型学会了分类任务后,它的输出 logits(未经 softmax 的原始预测值)包含了比标签更丰富的信息——比如模型认为「猫和豹子有 30% 相似」这种类间相似关系。小 student 模型不只学标签,而是学 teacher 的 logits(称为 soft targets),这样 student 能吸收 teacher 内化的知识,比直接从标签训练效果更好。LwF 把这个思想用到持续学习里:在开始学习新任务之前,先把新任务的数据送过旧模型,记录旧模型的输出 logits 作为 soft targets。然后在训练新任务时,损失函数由两部分构成:一是新任务的正常分类损失,二是蒸馏损失——惩罚新模型在新任务数据上的输出与旧模型之前记录的 soft targets 之间的偏差。这个蒸馏损失就相当于一个正则项,迫使模型在学新任务时不要让旧任务的输出变化太大。注意:LwF 完全不存储旧任务数据,只存旧模型对新任务数据的输出记录,非常节省空间。
这一页讲的是 Learning without Forgetting (LwF) 方法及其局限性。主要讨论 LwF 在任务之间数据分布变化时的失败原因,并通过图表展示不同方法的性能表现。
这一页讲的是 Learning without Forgetting (LwF) 方法及其在深度持续学习中的应用及局限性。LwF 的核心假设是新任务的输入能够提供足够信息来维持对旧任务的记忆。然而,当任务之间存在显著的领域偏移 (domain shift),即数据分布发生显著变化时,LwF 的效果会显著下降。这是因为新任务的输入无法有效提供关于旧任务的有用信息。页面右侧的图表展示了不同方法在处理旧任务性能时的表现,横轴表示新任务与旧任务的相似性逐渐降低,纵轴表示旧任务的性能变化。图中可以看到,Fine-tuning 方法的性能下降最严重,而 Joint Training 方法表现最好。LwF 方法(图中的蓝色叉号)在某些情况下性能优于 Fine-tuning,但在领域偏移较大的情况下仍然受到影响。这说明领域偏移是 LwF 的主要挑战之一。
这一页讲的是 LwF 的失效条件以及其局限性。LwF 的关键假设是:新任务的输入数据对保留旧任务知识是信息丰富的——也就是说,把新任务数据送过旧模型能得到有意义的 soft targets。但当 domain shift 很大时,这个假设就会崩溃。比如旧模型是在白天照片上训练的宠物分类器,新任务的数据是夜晚照片或声音录音——输入分布差别很大,旧模型对这些新任务输入的预测结果几乎是随机或无意义的,记录下来的 soft targets 就没有价值,蒸馏损失就失去了应有的约束力。结果就是 LwF 在 domain shift 大的情况下退化为普通训练,无法防止遗忘。这是 LwF 相对于 Replay-based 方法的一大弱点——Replay 存的是真实旧数据,而 LwF 存的只是旧模型对新数据的反应。考试中常见问答:「LwF 在什么情况下会失效?」答案要点是 domain shift 大导致新任务输入不能代表旧任务知识。还要注意 LwF 和 iCaRL 的对比:iCaRL 用 exemplar 存旧类别数据 + nearest class mean,LwF 用蒸馏不存旧数据但怕 domain shift。这是两个截然不同的设计取舍。
这一页讲的是权重先验正则化 (Weight Prior Regularisation),通过基于之前学习的权重进行正则化来保持一致性。介绍了 L2 正则化的公式及其问题。
这一页讲的是权重先验正则化 (Weight Prior Regularisation),其目的是通过基于之前学习任务的权重对网络参数进行约束,从而保持模型在持续学习中的一致性。页面提出了一种简单的正则化方法,即 L2 正则化,其公式为 L(θ) = L_B(θ) + Σ_i (θ_i - θ_A,i)²,其中 L_B(θ) 是任务 B 的损失函数,θ_A,i 是任务 A 中学习到的参数值。这个公式的作用是通过惩罚参数与之前学习任务的权重偏离过大的情况,来鼓励模型保持对过去任务的记忆。然而,这种方法存在一个问题,即它将所有参数视为同等重要,没有区分哪些参数对任务更关键。举例来说,如果某些参数对任务 A 的性能至关重要,而其他参数影响较小,这种方法无法有效区分它们的重要性。
这一页讲的是 Elastic Weight Consolidation (EWC) 方法的核心思想及其实现方式。主要内容包括识别重要参数的方法和深度持续学习的技术分类。
这一页讲的是 Elastic Weight Consolidation (EWC),一种用于深度持续学习的正则化方法。其核心思想是找到对之前任务表现重要的参数,并限制这些参数的改变幅度,以减少灾难性遗忘问题。EWC通过参数梯度来识别重要权重,这种逻辑也被应用于其他机器学习领域,例如网络剪枝。具体实现中,在完成一个任务后,通过数据计算平均梯度幅度来评估权重的重要性。此外,页面还提到深度持续学习的技术分类,包括 Replay-based(基于回放)、Regularisation-based(基于正则化)和 Architecture-based(基于架构)方法。EWC属于正则化方法,通过数学约束保护关键参数,从而在学习新任务时保持对旧任务的记忆。
这一页讲的是 Elastic Weight Consolidation (EWC) 方法,用于深度持续学习。重点包括 EWC 的定义、模型参数如何在任务间平衡,以及图示展示任务 A 和任务 B 的参数空间表现。
这一页讲的是 Elastic Weight Consolidation (EWC),一种用于深度持续学习的正则化方法。EWC 的目标是解决在连续学习多个任务时的遗忘问题。页面中的图表展示了模型在任务 A 的训练后,参数收敛到 θA 的过程。在参数空间中,灰色区域表示对任务 A 表现良好的参数范围,乳白色区域表示对任务 B 表现良好的参数范围。图中的箭头代表不同的优化策略:蓝色箭头表示无正则化时模型参数直接偏向任务 B,绿色箭头表示使用 L2 正则化,红色箭头表示使用 EWC 方法。EWC 通过增加一个基于任务 A 的重要性权重的正则项,使模型参数更倾向于保持任务 A 的性能,同时适应任务 B。这种方法在深度学习中非常重要,因为它能有效减少任务间的冲突和遗忘问题,从而提高模型的持续学习能力。例如,在图中可以看到,EWC 方法的优化路径更接近任务 A 和任务 B 的交集区域,说明它能够更好地平衡两个任务的性能。
这一页讲的是 Elastic Weight Consolidation (EWC),一种用于深度持续学习的正则化方法。重点包括 EWC 的原理、与 L2 正则化的区别,以及如何平衡任务 A 和任务 B 的误差。
这一页讲的是 Elastic Weight Consolidation (EWC),它是一种正则化技术,用于解决深度持续学习中的灾难性遗忘问题。页面中的图表展示了三种不同的优化策略对任务 A 和任务 B 的影响:蓝色箭头表示无正则化时的梯度更新,这种方法虽然能降低任务 B 的误差,但会显著增加任务 A 的误差;绿色箭头代表 L2 正则化,通过统一权重惩罚来限制参数变化,但这种方法会同时增加任务 A 和任务 B 的误差;红色箭头则体现了 EWC 的特点,它通过加权正则化,在降低任务 B 的误差的同时尽量保持任务 A 的误差较低。EWC 的核心思想是利用任务 A 的重要性权重来引导参数更新,从而在新任务学习时减少对旧任务的干扰。这种方法在深度持续学习中非常重要,因为它能有效缓解灾难性遗忘,同时提高模型的多任务学习能力。
这一页讲的是 Elastic Weight Consolidation (EWC),一种用于深度连续学习的正则化方法。重点包括通过惩罚参数变化来防止遗忘,以及公式中各项的含义。
这一页讲的是 Elastic Weight Consolidation (EWC),它是一种正则化方法,用于解决深度学习中的连续学习问题,特别是防止模型在学习新任务时遗忘旧任务。EWC 的核心思想是通过惩罚模型参数的变化,尤其是重要参数的变化,来实现这一目标。公式中,L(θ) 是总损失,由当前任务的损失 L_B(θ) 和正则化项构成。正则化项中,λ 控制正则化强度,F_i 是 Fisher 信息矩阵,用于衡量参数 i 的重要性;θ_A,i 是任务 A 中学习到的参数值;(θ_i - θ_A,i)^2 代表当前参数与任务 A 参数的偏离程度。通过这一机制,EWC 在学习新任务时,能够保留对旧任务的重要知识。例如,在图像分类中,模型在学习新类别时,不会遗忘对旧类别的分类能力。这种方法属于正则化技术,是深度连续学习的关键方法之一。
这一页讲的是 EWC(Elastic Weight Consolidation,弹性权重固化)的核心公式和 Fisher Information 的作用。EWC 的损失函数为:L(theta) 等于 L_B(theta) 加上对所有参数 i 的求和,每项为 lambda 除以 2 乘以 F_i 乘以 (theta_i 减去 theta_A,i 的平方)。其中 L_B(theta) 是当前新任务 B 的损失,theta_A,i 是学完任务 A 后的最优参数,F_i 是参数 i 对应的 Fisher Information,lambda 控制正则化强度。对比第 31 页的简单 L2 正则化,EWC 的关键改进就是用 F_i 作为每个参数的重要性权重——F_i 大的参数对任务 A 至关重要,惩罚系数大,这些参数被「弹性地锚定」在旧值附近;F_i 小的参数对任务 A 不重要,可以自由变化去学任务 B。Fisher Information F_i 是怎么计算的?训练完任务 A 后,把任务 A 的数据送过模型,计算模型输出对参数 i 的梯度的平方的期望——这个量衡量「输出对参数 i 的变化有多敏感」,可以直觉上理解为:敏感的参数说明它对模型行为影响大,应该被保护。EWC 的局限性包括:任务数增多时需要维护每个任务的 F_i,内存和计算量线性增长;惩罚是软约束,长任务序列中参数仍可能累积偏移。
这一页讲的是 Elastic Weight Consolidation (EWC) 方法的原理与应用。主要内容包括如何计算参数重要性 Fi、其对模型输出的影响,以及重要性如何影响参数调整难度。
这一页讲的是 Elastic Weight Consolidation (EWC),一种用于深度连续学习的正则化方法。EWC 的核心是通过计算参数的重要性 Fi 来减少遗忘效应。首先,模型在任务 A 上训练,得到参数 θA。然后,使用训练好的模型对任务 A 的数据进行处理,计算 Fi,公式中通过对 log 概率的偏导数平方来反映参数 i 对模型输出的敏感性。Fi 越大,表示该参数对任务 A 更重要,调整时会受到更大的正则化惩罚;Fi 越小,表示该参数更灵活,调整难度较低。最终的损失函数 L(θ) 包括任务 B 的损失 LB(θ) 和一个正则化项,后者由 Fi 和参数变化量共同决定。这种方法通过平衡任务间的参数调整,缓解了深度学习中的灾难性遗忘问题,是正则化方法中的代表性技术。
这一页讲的是 Elastic Weight Consolidation (EWC) 方法及其局限性。重点包括 EWC 的内存和计算扩展问题、软约束不足、累积漂移以及过参数化敏感性。
这一页讲的是 Elastic Weight Consolidation (EWC),一种用于深度连续学习 (Deep Continual Learning) 的正则化方法。EWC 的核心思想是通过对模型参数的重要性进行估计,限制重要参数的变化,从而减轻遗忘问题。然而,这种方法存在一些局限性:1. 可扩展性 (Scalability):随着任务数量增加,存储和计算需求显著增长,因为需要记录每个任务中参数的重要性。2. 软约束 (Soft constraints):对于较长的任务序列,EWC 的正则化惩罚可能不足以完全防止遗忘。3. 累积漂移 (Cumulative drift):即使是多个参数的小变化也可能累积,导致模型性能下降。4. 过参数化敏感性 (Over parameterisation sensitivity):在大型网络中,识别真正关键的权重变得更加困难。这些问题说明了在实际应用中,EWC 的效果可能受到限制,需要结合其他方法(如 Replay-based 和 Architecture-based 方法)来进一步优化连续学习的性能。
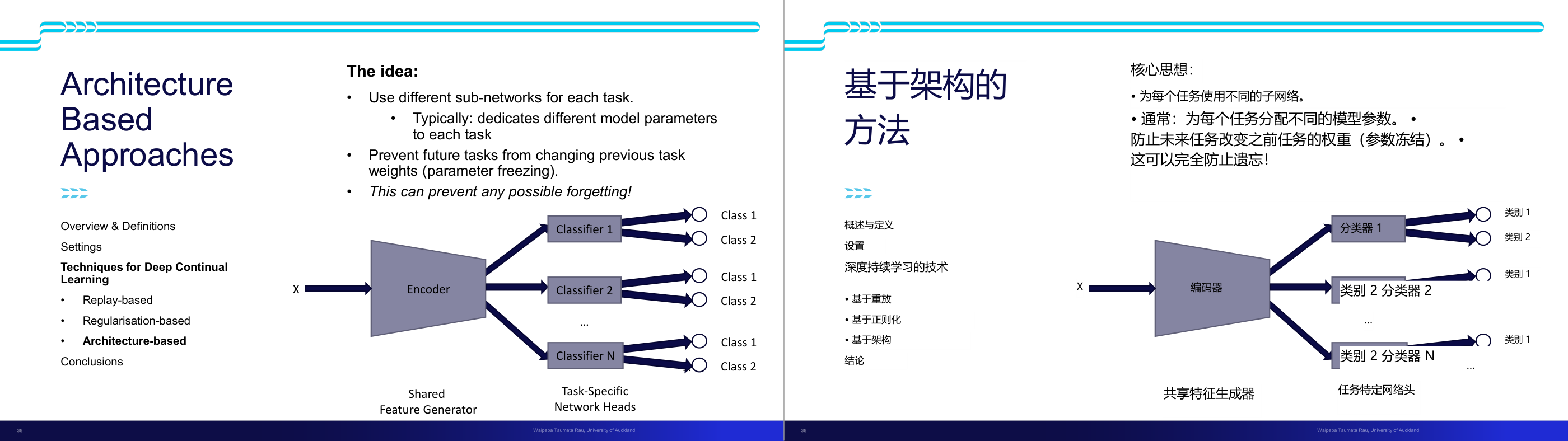
这一页讲的是 Architecture-Based Approaches,用不同的子网络处理不同任务,通过参数冻结避免遗忘问题。
这一页讲的是 Architecture-Based Approaches(基于架构的方法),其核心思想是为每个任务使用不同的子网络(sub-networks)。通常情况下,每个任务会分配独立的模型参数,这样可以防止后续任务改变之前任务的权重(参数冻结,parameter freezing)。这种方法可以有效避免遗忘问题(forgetting)。右侧的流程图展示了一个典型的架构:输入 X 经过共享的特征生成器(Shared Feature Generator)后,分配到不同的任务专属网络头(Task-Specific Network Heads),每个任务专属分类器(Classifier)分别处理自己的分类任务,例如 Classifier 1 负责分类任务 1 的 Class 1 和 Class 2。通过这种架构,每个任务的参数独立,避免了任务间的干扰。这种方法在深度持续学习(Deep Continual Learning)中非常重要,尤其适用于需要处理多个独立任务的场景,例如图像分类或自然语言处理。
这一页讲的是基于架构的深度持续学习方法,分为静态架构和动态架构两类。静态架构固定网络大小,动态架构通过添加新模块扩展网络。
这一页讲的是基于架构的深度持续学习方法(Architecture-based Approaches)。主要分为两类:静态架构(Static architectures)和动态架构(Dynamic architectures)。静态架构指网络大小固定,任务之间共享网络,通过内部机制(如 masking)控制参数的激活状态。动态架构则允许网络随着任务的增加动态扩展,通过添加新的参数、分支或模块支持每个任务。幻灯片中的图展示了一个典型动态架构的流程:输入 X 经过共享特征生成器(Shared Feature Generator)编码后,输出到多个任务专属的分类器(Classifier),每个分类器对应特定任务的网络头(Task-Specific Network Heads),以完成不同任务的分类。动态架构的优点是灵活性高,能够适应多任务学习的需求,同时避免任务间的干扰。举例来说,在图中,Classifier 1 可用于任务 1 的分类,而新增的 Classifier N 则可以支持任务 N 的分类。
这一页讲的是 Architecture-based(基于架构)的持续学习方法总体思路,以及静态架构和动态架构的区别。基于架构的方法核心思想是:给不同任务使用不同的子网络,通过参数隔离或冻结来彻底避免任务间的干扰——这是理论上最能防止遗忘的方案,因为冻结的参数根本不会被修改。典型架构是一个共享的 feature extractor(特征生成器)加上多个 task-specific network head(任务专用分类头),每个任务有自己的 head,共享底层特征提取。静态架构(Static)是固定大小的网络,用内部机制(如 masking,掩码)来决定哪些参数激活——代表方法是 PackNet,通过剪枝找出未使用的权重分配给新任务,然后冻结。动态架构(Dynamic)则是网络随任务增长,为每个新任务添加新的参数、分支或模块,理论上不受容量限制。两类方法各有缺陷:静态架构容量有限,任务一多就没有空余权重可分配;动态架构则会无限增长模型大小。考试中常考「Architecture-based 方法的优势和缺点」:优势是最大程度防止遗忘;缺点是静态容量有限,动态内存无界增长。另外要注意 Architecture-based 方法一般需要知道 task ID 才能选对 head,在没有 task ID 的 class-incremental 设定下效果有限。
这一页讲的是 PackNet 方法,它属于深度持续学习 (Deep Continual Learning) 的架构方法。主要内容包括权重剪枝与重新分配,以及冻结任务特定权重。
这一页讲的是 PackNet 方法,它是一种架构驱动的深度持续学习技术。其核心思想是识别固定网络中未使用或不重要的权重,将这些权重重新分配给新任务。具体步骤包括:对每个任务进行权重剪枝 (pruning),然后重新训练模型以适应新任务,最后冻结与该任务相关的权重。幻灯片中的图表展示了这一过程的具体操作:图 (a) 和 (b) 展示了任务 I 的初始权重分布和剪枝后重新训练的结果;图 (c) 和 (d) 展示了任务 II 的类似过程;图 (e) 则是任务 III 的初始权重分布。剪枝比例逐步减少,例如任务 I 的剪枝比例为 60%,任务 II 为 33%。这种方法通过优化网络权重的使用,避免了任务间的干扰(如遗忘问题),并有效提升了模型的持续学习能力。
这一页讲的是 PackNet 算法——静态架构方法中通过迭代剪枝在固定网络中「打包」多个任务的代表性方案。PackNet 的流程是:先在整个网络上训练任务 1,然后对网络做剪枝(pruning),识别出哪些权重对任务 1 不重要,把这些「可释放的权重」标记出来;再用任务 2 的数据重新训练那些被释放的权重(同时被任务 1 重要权重对应部分保持冻结不变);训练完后冻结任务 2 使用的权重;以此类推。这样一个固定大小的网络被划分成若干「分区」,每个分区只服务一个任务且冻结后不受干扰,实现了零遗忘。PackNet 的两个核心问题:第一,容量有限——网络的参数总量固定,随着任务增多可分配的空余权重越来越少,最终耗尽,这是所有静态架构方案的根本限制;第二,需要为每个参数存储一个任务归属掩码,内存开销大。聪明的解决方案是:不为每个任务存独立的二进制掩码,而是用一个整数编码该参数属于哪个任务,只需 log2(num_tasks) 比特每个参数——实验表明在 VGG-16 上额外内存开销约 6%。考试时 PackNet 的「掩码压缩方案」是可能出现的细节考点,要能说出为什么用整数编码比多个二进制掩码高效。
这一页讲的是 PackNet 方法中的问题与解决方案,重点是有限模型容量问题及其替代方案。
这一页讲的是 PackNet 方法中的核心问题——有限模型容量(Finite Model Capacity)。这个问题是静态架构(static architectures)固有的缺陷,会导致模型参数耗尽,无法继续学习新任务。为了解决这一问题,提出了一种替代方案:使用动态架构(dynamic architecture),通过分配新的参数(例如新增模块或分支)来扩展模型容量。然而,这种方法会引入模型无限增长的问题(unbounded model growth),需要权衡模型复杂性与性能。此外,页面还提到深度持续学习(Deep Continual Learning)的技术分类,包括基于重放(Replay-based)、正则化(Regularisation-based)和架构(Architecture-based)的方法。PackNet 属于架构驱动的解决方案,通过剪枝和动态扩展来应对持续学习中的挑战。
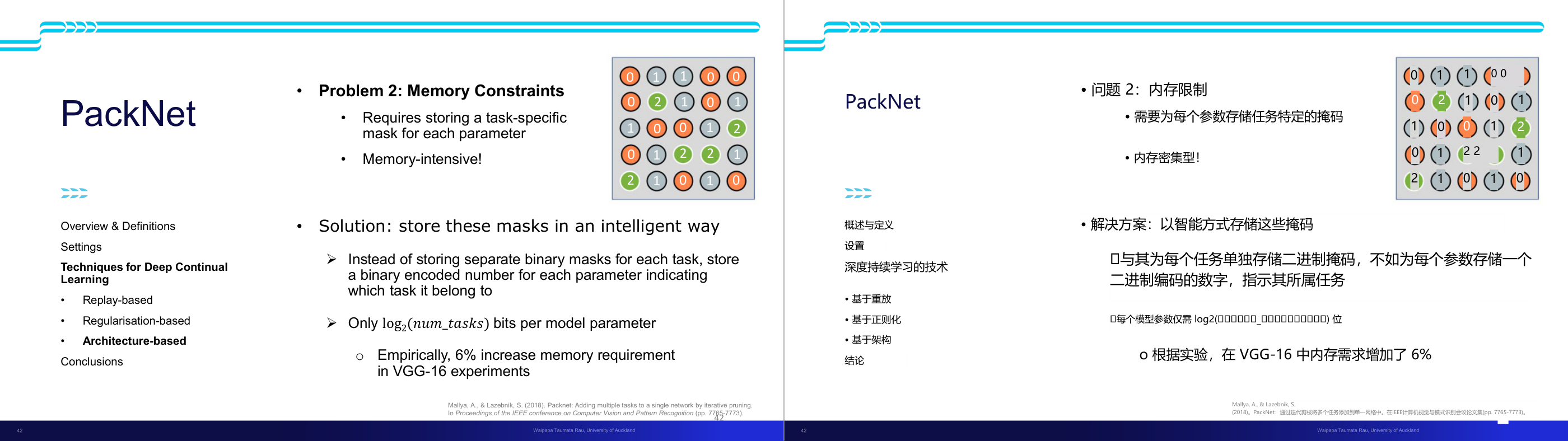
这一页讲的是 PackNet 方法中解决内存约束问题的方案。主要问题是任务专属掩码需要大量内存,解决方法是用二进制编码简化存储,显著降低内存需求。
这一页讲的是 PackNet 方法中的内存约束问题及其解决方案。问题在于每个任务需要存储专属的掩码(task-specific mask),这会导致内存占用过大。为了解决这一问题,提出了一种智能存储掩码的方式:将每个参数的任务归属信息用二进制编码存储,而不是为每个任务单独存储二进制掩码。这种方法显著减少了内存需求,仅需要 log2(num_tasks) 位来表示每个模型参数的任务归属。实验结果表明,在 VGG-16 的实验中,这种方法仅增加了 6% 的内存需求。右侧的图示表达了掩码编码的概念,用不同颜色和数字表示参数的任务归属。这种方法不仅优化了存储效率,还为深度持续学习(Deep Continual Learning)中的架构优化提供了重要支持。
这一页讲的是深度持续学习的总结,包括灾难性遗忘、知识迁移挑战以及下一代 AI 的目标。重点提到开放世界学习的重要性和自主学习代理的构建。
这一页讲的是深度持续学习的总结。首先,灾难性遗忘(Catastrophic forgetting)仍然是一个主要挑战,尤其是在类别增量学习(Class Incremental Learning, CIL)中。知识迁移的研究工作有限,如何确保知识的正确性和适用性是关键问题。其次,关于知识迁移的方向和方法,开放世界持续学习(Open world continual learning)被认为是更大的挑战,需要关注新颖性(Novelty)、特征化(Characterization)、适应性(Adaptation)以及增量学习(Incremental learning)。最后,这页强调了下一代 AI 的目标,即实现自主性(AI autonomy)。自主学习代理(Autonomous learning agents)将在受限环境中构建,并能够与人类、其他代理以及环境进行交互。这些内容概括了深度持续学习的关键技术,包括基于重放(Replay-based)、正则化(Regularisation-based)和架构(Architecture-based)的方法,并为未来的研究方向提供了启示。
这一页讲的是持续学习(Continual Learning)的关键概念,包括定义、常见方法及其优缺点,以及三种技术:基于回放、正则化和架构的方法。
这一页讲的是持续学习(Continual Learning),即机器学习模型在面对不断变化的数据分布时,能够持续地学习新知识,同时避免遗忘旧知识的能力。首先,介绍了持续学习的定义和背景,其核心目标是解决灾难性遗忘问题。其次,讨论了持续学习的常见方法,分析了每种方法的优缺点,例如某些方法可能更适合处理大规模数据,而另一些方法更擅长应对复杂任务。最后,重点讲解了三种技术:基于回放(Replay-based)方法通过存储和重放旧数据来强化记忆;基于正则化(Regularisation-based)方法通过添加约束来保护旧知识;基于架构(Architecture-based)方法通过动态调整模型结构来适应新任务。这些技术各有适用场景,例如回放方法适合数据量较小但任务多样的情况,而架构方法通常用于需要高灵活性的复杂任务。